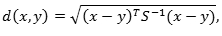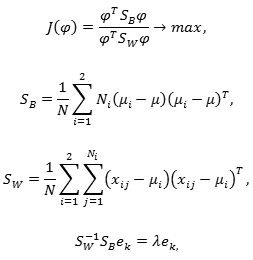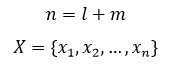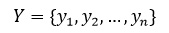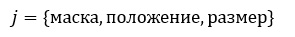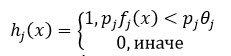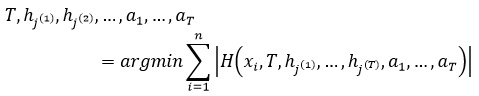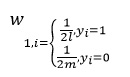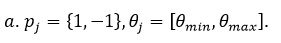Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Построение решающего правилаСтр 1 из 4Следующая ⇒
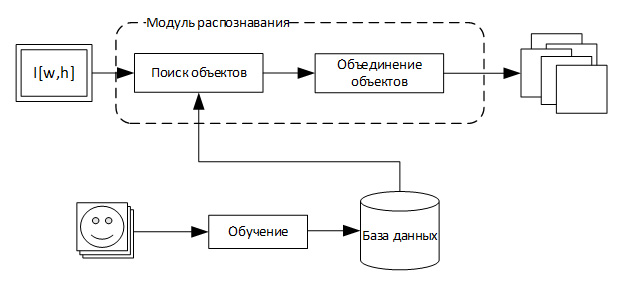
Введение. Сегодня существует большое количество приложений, в которых используются методы распознавания лиц, таких как: идентификация личности, контроль удостоверений личности, использование интерфейса „человек-компьютер” и т. п. Главные сложности при распознавании лиц – множество изменений при представлении лиц, таких как: различное освещение, выражение лица, поворот головы, возрастные изменения и т. п. Поэтому проблема автоматического распознавания лиц полностью не решена до сих пор. Процесс идентификации личности, который базируется на распознавании по изображению лица, состоит в том, что изображение лица неизвестной личности подается на вход системы распознавания, в которой сравнивается с изображениями лиц известных личностей, находящихся в базе изображений. Процесс идентификации можно разделить на три основных этапа: – регистрация и нормализация изображения лица; – выделение признаков; – классификация. В последнее время особенное внимание исследователей для выделения признаков из изображения лица привлекают методы, которые используют локальные бинарные шаблоны (ЛБШ). ЛБШ впервые были предложены в 1996 году для анализа текстур полутоновых изображений. Методы распознавания лиц, которые используют для выделения признаков ЛБШ и их модификации, демонстрируют высокие результаты как по скорости, так и по точности распознавания. Такие методы робастны при использовании изображений лиц с различной мимикой, различным освещением, поворотами головы. Целью данной работы является модификация ЛБШ, которая бы позволила повысить точность распознавания изображений лиц по сравнению с использованием классических ЛБШ и их модификаций, а также классических методов распознавания лиц (анализ главных компонент, сравнение эластичных графов).
Как правило, система распознавания лиц представляет собой программно-аппаратный комплекс для автоматической верификации или идентификации личности по цифровому изображению (фотографии или кадру видеопоследовательности). Задача распознавания лиц решается при разработке систем контроля и управления доступом, систем пограничного контроля, проведении оперативно-розыскных мероприятий и т.д. При использовании биометрических систем, особенно системы распознавания по лицу, даже при введении корректных биометрических характеристик не всегда решение об аутентификации верно. Это связано с рядом особенностей и, в первую очередь, с тем, что многие биометрические характеристики могут изменяться. Существует определенная степень вероятности ошибки системы. Причем при использовании различных технологий ошибка может существенно различаться. Для систем контроля доступа при использовании биометрических технологий необходимо определить, что важнее не ошибиться в состоянии человека и не позволить ему использовать ЭВМ в не адекватном состоянии.
Важным фактором для пользователей биометрических технологий в системах безопасности является простота использования. Человек, характеристики которого сканируются, не должен при этом испытывать никаких неудобств. Несмотря на очевидные преимущества, существует ряд негативных предубеждений против биометрии, которые часто вызывают вопросы о том, не будут ли биометрические данные использоваться для слежки за людьми и нарушения их права на частную жизнь. Из-за сенсационных заявлений восприятие биометрических технологий резко отличается от реального положения дел. В процессе распознавания лиц возникает ряд сложностей, связанных с изменением условий освещения, вращением головы, возрастными изменениями и проч. Можно выделить следующие основные этапы процесса верификации и идентификации:
Основными целями данной работы являлись разработка и анализ алгоритма распознавания лиц на основе локальных бинарных шаблонов (ЛБШ). Укажем основные этапы решения поставленной задачи:
Локальные бинарные шаблоны.
Локальный бинарный шаблон – это определенный вид признака, используемый для классификации в компьютерном зрении, и представляющий собой простой оператор. Локальные бинарные шаблоны впервые были предложены в 1996 году для анализа текстуры полутоновых изображений. При этом дальнейшие исследования показали, что ЛБШ инвариантны к небольшим изменениям в условиях освещения и небольшим поворотам изображения.
Изображения лиц могут рассматриваться как набор всевозможных локальных особенностей, которые хорошо описываются с помощью ЛБШ, однако гистограмма, построенная для всего изображения в целом, кодирует лишь наличие тех или иных локальных особенностей, но при этом не содержит никакой информации об их расположении на изображении. Для учёта такого рода информации изображение разбивается на подобласти, в каждой из которых вычисляется своя гистограмма ЛБШ. Путём конкатенации этих гистограмм получается общая гистограмма, учитывающая как локальные, так и глобальные особенности изображения.
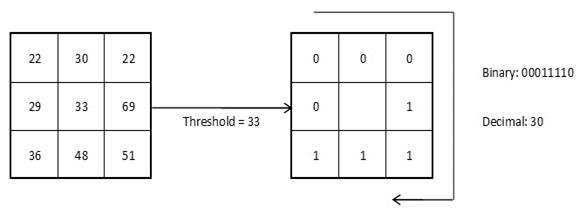
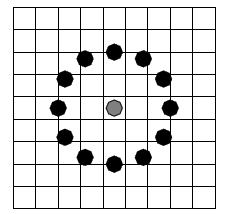
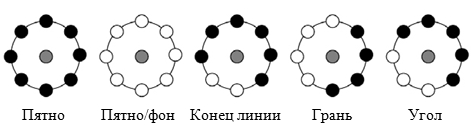
Главной сложностью применения данного признакового описания изображений является очень большая размерность пространства признаков. Так, при разбиении изображения лица на 5 х 7 = 35 областей эта размерность составляет 256 х 35 = 8960. Не все бинарные шаблоны одинаково информативны. Некоторые бинарные коды несут в себе больше информации, чем остальные. Так, локальный бинарный шаблон называется равномерным, если он содержит не более трех серий «0» и «1» (например, 00000000, 001110000 и 11100001). Во-первых, равномерные ЛБШ определяют только важные локальные особенности изображения, такие как концы линий, грани, углы и пятна (рисунок 2.3). Во-вторых, они обеспечивают существенную экономию памяти (P (P -1)+2 различных шаблонов вместо 2 P).
Гистограмма ЛБШ
Изображения лиц могут рассматриваться как набор всевозможных локальных особенностей, которые хорошо описываются с помощью локальных бинарных шаблонов. Однако гистограмма, построенная для всего изображения в целом, кодирует лишь наличие тех или иных локальных особенностей, но при этом не содержит никакой информации об их расположении на изображении. Для учета такого рода информации изображение разбивается на подобласти, в каждой из которых вычисляется своя гистограмма ЛБШ (рисунок 3.1). Путем конкатенации этих гистограмм может быть получена общая гистограмма, учитывающая как локальные, так и глобальные особенности изображения.
Расстояние Махаланобиса
Корреляционная матрица S может быть получена с использованием обучающей выборки изображений. Определяя расстояние Кульбака-Лейблера (4.1) для каждой из подобластей изображений, мы можем получить вектор различий двух изображений. Вычисляя такие вектора для каждой пары изображений обучающей выборки, мы получим два набора векторов различий изображений, соответствующих двум классам – классу «своих» и классу «чужих». После этого мы можем вычислить средние значения векторов, представляющих каждый из классов, а также две корреляционные матрицы. На практике, для любых двух изображений мы можем вычислить их вектор различий, а затем определить расстояния Махаланобиса d 1 и d 2 между этим вектором и средними векторами классов «свой» и «чужой» соответственно. Идентификация и верификация могут быть произведены путем сравнения двух полученных расстояний либо с использованием дискриминирующей функции f (d 1, d 2) = d 2⁄(d 1+ d 2) и некоторого порогового значения.
4.3. Применение линейного дискриминанта Фишера
Пусть имеется два набора векторов, соответствующих двум классам. Собственный вектор, соответствующий наибольшему собственному значению матрицы Sw -1 Sb задает преобразование в пространство размерности 1. Задача идентификации и верификации может быть решена способом, аналогичным предыдущему (путем построения векторов различий изображений с использованием расстояния Кульбака-Лейблера). При этом вместо расстояния Махаланобиса используется отображение вектора в одномерное пространство.
Предобработка изображений
Метод Виолы-Джонса Метод был разработан и представлен в 2001 году Полом Виолой и Майклом Джонсом, он до сих пор является основополагающим для поиска объектов на изображении в реальном времени. Метод использует технологию скользящего окна. То есть рамка, размером, меньшим, чем исходное изображение, двигается с некоторым шагом по изображению, и с помощью каскада слабых классификаторов определяет, есть ли в рассматриваемом окне лицо. Метод скользящего окно эффективно используется в различных задачах компьютерного зрения и распознавания объектов. Метод состоит из 2-х под алгоритмов: алгоритм обучения и алгоритм распознавания. На практике скорость работы алгоритма обучения не важна. Крайне важна скорость работы алгоритма распознавания. По введенной ранее классификации можно отнести к структурным, статистическим и нейронным методам. Метод имеет следующие преимущества:
Основные принципы, на которых основан метод, таковы:
Принцип сканирующего окна
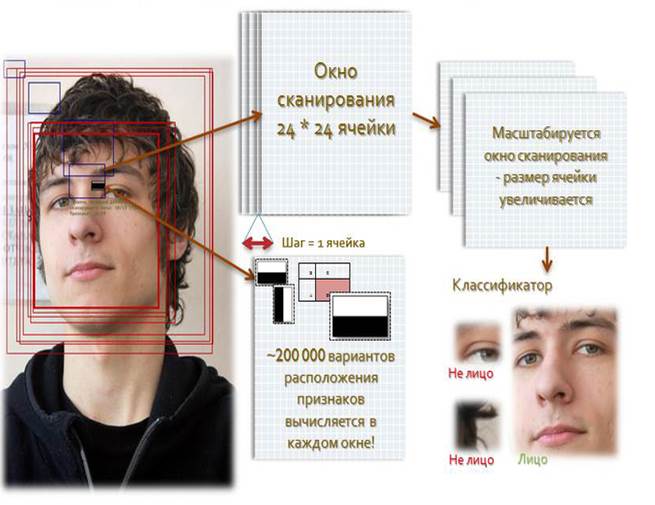
Схема распознавания Обобщенная схема распознавания в алгоритме Виолы-Джонса показана на рисунке ниже.
Обобщенная схема алгоритма выгляди следующим образом: перед началом распознавания алгоритм обучения на основе тестовых изображений обучает базу данных, состоящую из признаков, их паритета и границы. Подробнее о паритете, признаке и границе будет рассказано в следующих пунктах. Далее алгоритм распознавания ищет объекты на разных масштабах изображения, используя созданную базы данных. Алгоритм Виолы-Джонса на выходе дает всё множество найденных необъединенных объектов на разных масштабах. Следующая задача – принять решение о том, какие из найденных объектов действительно присутствуют в кадре, а какие – дубли. Признаки класса В качестве признаков для алгоритма распознавания авторами были предложены признаки Хаара, на основе вейвлетов Хаара. Они были предложен венгерским математиком Альфредом Хааром в 1909 году. Признак — отображение f: X => Df, где Df — множество допустимых значений признака. Если заданы признаки f1,…,fn, то вектор признаков x = (f1(x),…,fn(x)) называется признаковым описанием объекта x ∈ X. Признаковые описания допустимо отождествлять с самими объектами. При этом множество X = Df1* …* Dfn называют признаковым пространством [1].
В расширенном методе Виолы – Джонса, использующемся в библиотеке OpenCV используются дополнительные признаки. Вычисляемым значением такого признака будет
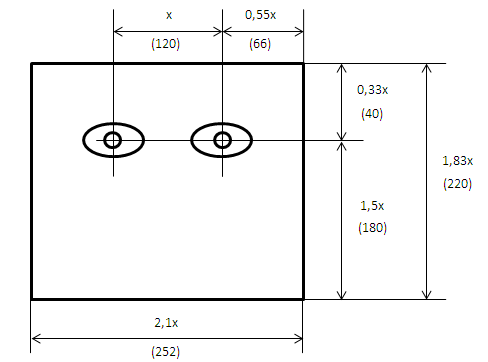
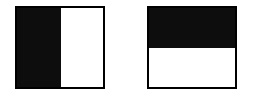
В задаче распознавания лиц, общее наблюдение, что среди всех лиц области глаз темнее области щек. Рассмотрим маски, состоящие из светлых и темных областей.
Каждая маска характеризируется размером светлой и темной областей, пропорциями, а также минимальным размером. Совместно с другими наблюдениями были предложены следующие признаки Хаара, как пространство признаков в задаче распознавания для класса лиц.
Признаки Хаара дают точечное значение перепада яркости по оси X и Y соответственно. Поэтому общий признак Хаара для распознавания лиц представляет набор двух смежных прямоугольников, которые лежат выше глаз и на щеках. Значение признака вычисляется по формуле: F=X-Y где X – сумма значений яркостей точек закрываемых светлой частью признака, а Y – сумма значений яркостей точек закрываемых темной частью признака. Видно, что если считать суммы значений интенсивностей для каждого признака это потребует значительных вычислительных ресурсов. Виолой и Джонсом было предложено использовать интегральное представление изображения, подробнее о нем будет далее. Такое представление стало довольно удобным способом вычисления признаков и применяется также и в других алгоритмах компьютерного зрения, например SURF. Сканирование окна
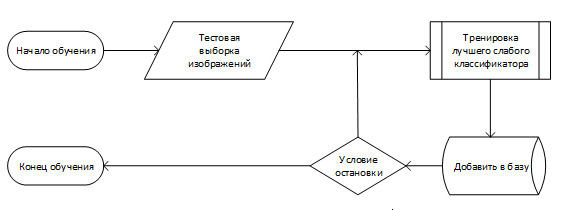
Схема обучения Обобщенная схема алгоритма обучения выглядит следующим образом. Имеется тестовая выборка изображений. Размер тестовой выборки около 10 000 изображений. На рисунке показан пример обучающих изображений лиц. Алгоритм обучения работает с изображениями в оттенках серого.
При размере тестового изображения 24 на 24 пикселя количество конфигураций одного признака около 40 000 (зависит от минимального размера маски). Современная реализация алгоритма использует порядка 20 масок. Для каждой маски, каждой конфигурации тренируется такой слабый классификатор, который дает наименьшую ошибку на всей тренировочной базе. Он добавляется в базу данных. Таким образом алгоритм обучается. И на выходе алгоритма получается база данных из T слабых классификаторов. Обобщённая схема алгоритма обучения показана на рисунке.
Обучение алгоритма Виола-Джонса – это обучение алгоритма с учителем. Для него возможно такая проблема как переобучение. Показано, что AdaBoost может использоваться для различных проблем, в том числе к теории игр, прогнозировании. В данной работе условие остановки является достижение заранее заданного количества слабых классификаторов в базе. Для алгоритма необходимо заранее подготовить тестовую выборку из l изображений, содержащих искомый объект и n не содержащих. Тогда количество всех тестовых изображений будет
где X – множество всех тестовых изображений, где для каждого заранее известно присутствует ли искомый объект или нет и отражено во множестве Y.
где
Под признаком j будем понимать структуру вида
Тогда откликом признака будет f_j (x), который вычисляется как разность интенсивностей пикселей в светлой и темной областях. Слабый классификатор имеет вид:
Задача слабого классификатора – угадывать присутствие объекта в больше чем 50% случаев. Используя процедуру обучения AdaBoost создается очень сильный классификатор состоящий из T слабых классификаторов и имеющий вид:
Целевая функция обучения имеет следующий вид:
Обучение Перед началом обучения инициализируются веса w_(q,i), где q – номер итерации, i-номер изображения.
После процедуры обучения получится T слабых классификаторов и T значений.
На каждой итерации цикла происходит обновление весов так, что их сумма будет равна 1. Далее для всех возможных признаков происходит подбор таких значений p,θ,j что значение ошибки e_j будет минимально на этой итерации. Полученный признак J(t) (на шаге t) сохраняется в базу слабых классификаторов, обновляются веса и вычисляется коэффициент a_t. В предложенном в 2001 году оригинальном алгоритме не была описана процедура получения оптимального признака на каждой итерации. Предполагается использование алгоритма AdaBoost и полный перебор возможных параметров границы и паритета. Распознавание После обучения на тестовой выборке имеется обученная база знаний из T слабых классификаторов. Для каждого классификатора известны: признак Хаара, использующийся в этом классификаторе, его положение внутри окна размером 24х24 пикселя и значение порога E. На вход алгоритму поступает изображение I(r,c) размером W х H, где I(r,c) – яркостная составляющая изображения. Результатом работы алгоритма служит множество прямоугольников R(x,y,w,h), определяющих положение лиц в исходном изображении I. Алгоритм сканирует изображение I на нескольких масштабах, начиная с базовой шкалы: размер окна 24х24 пикселя и 11 масштабов, при этом каждый следующий уровень в 1.25 раза больше предыдущего, по рекомендации авторов. Алгоритм распознавания выглядит следующим образом:
Введение. Сегодня существует большое количество приложений, в которых используются методы распознавания лиц, таких как: идентификация личности, контроль удостоверений личности, использование интерфейса „человек-компьютер” и т. п. Главные сложности при распознавании лиц – множество изменений при представлении лиц, таких как: различное освещение, выражение лица, поворот головы, возрастные изменения и т. п. Поэтому проблема автоматического распознавания лиц полностью не решена до сих пор. Процесс идентификации личности, который базируется на распознавании по изображению лица, состоит в том, что изображение лица неизвестной личности подается на вход системы распознавания, в которой сравнивается с изображениями лиц известных личностей, находящихся в базе изображений. Процесс идентификации можно разделить на три основных этапа: – регистрация и нормализация изображения лица; – выделение признаков; – классификация. В последнее время особенное внимание исследователей для выделения признаков из изображения лица привлекают методы, которые используют локальные бинарные шаблоны (ЛБШ). ЛБШ впервые были предложены в 1996 году для анализа текстур полутоновых изображений. Методы распознавания лиц, которые используют для выделения признаков ЛБШ и их модификации, демонстрируют высокие результаты как по скорости, так и по точности распознавания. Такие методы робастны при использовании изображений лиц с различной мимикой, различным освещением, поворотами головы. Целью данной работы является модификация ЛБШ, которая бы позволила повысить точность распознавания изображений лиц по сравнению с использованием классических ЛБШ и их модификаций, а также классических методов распознавания лиц (анализ главных компонент, сравнение эластичных графов).
Как правило, система распознавания лиц представляет собой программно-аппаратный комплекс для автоматической верификации или идентификации личности по цифровому изображению (фотографии или кадру видеопоследовательности). Задача распознавания лиц решается при разработке систем контроля и управления доступом, систем пограничного контроля, проведении оперативно-розыскных мероприятий и т.д. При использовании биометрических систем, особенно системы распознавания по лицу, даже при введении корректных биометрических характеристик не всегда решение об аутентификации верно. Это связано с рядом особенностей и, в первую очередь, с тем, что многие биометрические характеристики могут изменяться. Существует определенная степень вероятности ошибки системы. Причем при использовании различных технологий ошибка может существенно различаться. Для систем контроля доступа при использовании биометрических технологий необходимо определить, что важнее не ошибиться в состоянии человека и не позволить ему использовать ЭВМ в не адекватном состоянии. Важным фактором для пользователей биометрических технологий в системах безопасности является простота использования. Человек, характеристики которого сканируются, не должен при этом испытывать никаких неудобств. Несмотря на очевидные преимущества, существует ряд негативных предубеждений против биометрии, которые часто вызывают вопросы о том, не будут ли биометрические данные использоваться для слежки за людьми и нарушения их права на частную жизнь. Из-за сенсационных заявлений восприятие биометрических технологий резко отличается от реального положения дел. В процессе распознавания лиц возникает ряд сложностей, связанных с изменением условий освещения, вращением головы, возрастными изменениями и проч. Можно выделить следующие основные этапы процесса верификации и идентификации:
Основными целями данной работы являлись разработка и анализ алгоритма распознавания лиц на основе локальных бинарных шаблонов (ЛБШ). Укажем основные этапы решения поставленной задачи:
Локальные бинарные шаблоны.
Локальный бинарный шаблон – это определенный вид признака, используемый для классификации в компьютерном зрении, и представляющий собой простой оператор. Локальные бинарные шаблоны впервые были предложены в 1996 году для анализа текстуры полутоновых изображений. При этом дальнейшие исследования показали, что ЛБШ инвариантны к небольшим изменениям в условиях освещения и небольшим поворотам изображения. Изображения лиц могут рассматриваться как набор всевозможных локальных особенностей, которые хорошо описываются с помощью ЛБШ, однако гистограмма, построенная для всего изображения в целом, кодирует лишь наличие тех или иных локальных особенностей, но при этом не содержит никакой информации об их расположении на изображении. Для учёта такого рода информации изображение разбивается на подобласти, в каждой из которых вычисляется своя гистограмма ЛБШ. Путём конкатенации этих гистограмм получается общая гистограмма, учитывающая как локальные, так и глобальные особенности изображения.
Главной сложностью применения данного признакового описания изображений является очень большая размерность пространства признаков. Так, при разбиении изображения лица на 5 х 7 = 35 областей эта размерность составляет 256 х 35 = 8960. Не все бинарные шаблоны одинаково информативны. Некоторые бинарные коды несут в себе больше информации, чем остальные. Так, локальный бинарный шаблон называется равномерным, если он содержит не более трех серий «0» и «1» (например, 00000000, 001110000 и 11100001). Во-первых, равномерные ЛБШ определяют только важные локальные особенности изображения, такие как концы линий, грани, углы и пятна (рисунок 2.3). Во-вторых, они обеспечивают существенную экономию памяти (P (P -1)+2 различных шаблонов вместо 2 P).
Гистограмма ЛБШ
Изображения лиц могут рассматриваться как набор всевозможных локальных особенностей, которые хорошо описываются с помощью локальных бинарных шаблонов. Однако гистограмма, построенная для всего изображения в целом, кодирует лишь наличие тех или иных локальных особенностей, но при этом не содержит никакой информации об их расположении на изображении. Для учета такого рода информации изображение разбивается на подобласти, в каждой из которых вычисляется своя гистограмма ЛБШ (рисунок 3.1). Путем конкатенации этих гистограмм может быть получена общая гистограмма, учитывающая как локальные, так и глобальные особенности изображения.
Построение решающего правила
|
|||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-07-16; просмотров: 1381; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.134.102.182 (0.077 с.) |