
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Этап 2. Первичная обработка данных.
1) Исключение ложных данных. При больших выборках лучше всего использовать таблицу распределения Стьюдента. Критерием проверки служат неравенства:
, где
При выполнении неравенства (1) рассматриваем значение выборка никогда не исключают. При выполнении неравенства (2) рассматриваемые значения можно исключить, если для исключения есть дополнительные доводы экспериментатора. При выполнения неравенства (3) рассматриваемые значения исключают всегда как ложные. Для больших выборок процедуру исключения нужно повторять до невыполнения неравенств (2) или (3), каждый раз пересчитывая статистики Проделывая данный алгоритм для нашей выборки, исключаем 6 значений: 19,93; 20,18; 20,76; 20,93; 21,84; 21,91. Следовательно, объем выборки стал m=194. 2) Делаем статистическую проверку случайности и независимости результатов наблюдения с помощью критерия серий и критерия «восходящих» и «нисходящих» серий. а) Критерий серий, основанный на медиане выборки. В качестве выборочного значения медианы
Затем возвращаемся к первоначальной неупорядоченной выборке с исключенными ложными значениями и вместо каждого xiставим знак «+», если Выдвинем гипотезы H0 – исходные результаты наблюдения являются стохастически независимыми, H1 - исходные результаты наблюдения не являются стохастически независимыми. Примем уровень значимости
После проделывания данной процедуры, получили Следовательно, гипотеза H0отвергается, H1 принимается. б) Критерий «восходящих» и «нисходящих» серий. Так же, как и в предыдущем критерии, исследуется последовательность знаков – плюсов и минусов, о правило построения этой последовательности другое: исходным пунктом является последовательность результатов наблюдения с исключенными ложными значениями x1, x2,…, xm. На i-м месте этой последовательности ставится знак плюс, если xi+1-xi> 0, и минус, если xi+1-xi< 0. Критерий основан на соображении, что если выборка случайна, то в построении последовательности знаков общее число серий не может быть слишком малым, а их длина слишком большой.
Выдвинем гипотезы H0 – исходные результаты наблюдения являются стохастически независимыми, H1 - исходные результаты наблюдения не являются стохастически независимыми. Примем уровень значимости
После проделывания данной процедуры, получили Следовательно, гипотеза H0отвергается, H1 принимается. 3) Построение интервального ряда. Для определения длины интервала воспользуемся формулой Стерджеса:
Сделаем отступ слева по формуле
4) Нахождение точечных и интервальных оценок мат. ожидания и дисперсии. а) Точечную оценку мат. ожидания и дисперсии найдем по формулам:
б) Интервальную оценку мат. ожидания найдем по формуле:
- Интервальную оценку дисперсии найдем по формуле:
5) Рассчитаем эмпирическую частоту и найдем эмпирическую функцию распределения, результаты приведены в Таблице 1:
Таблица 1 ni– эмпирическая частота; nx– накопленная эмпирическая частота;
6) Построение гистограммы.
По виду гистограммы выдвинем гипотезы о законе распределения: H0 – данные подчиняются нормальному закону распределения; H1 – данные не подчиняются нормальному закону распределения. 7)Для дальнейших рассуждений объединим интервалы, у которых частота n<5, получим:
8) Рассчитаем теоретическую частоту и найдем теоретическую функцию распределения, результаты приведены в Таблице 2:
Таблица 2
nx`– накопленная теоретическая частота;
Этап 3. Проверка гипотезы по критерию 1. Вычисляем выборочное значение статистики критерия:
2. Выберем уровень значимости 3. По таблице 4.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2021-06-14; просмотров: 96; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.191.103.143 (0.014 с.) |
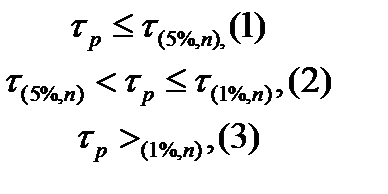
 вычисляют по формулам (4) или (5), а
вычисляют по формулам (4) или (5), а  по формуле (6):
по формуле (6):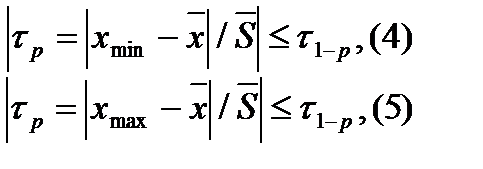 , где
, где 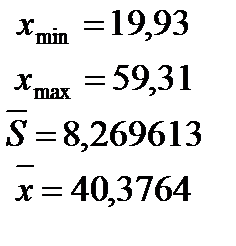
 , где
, где 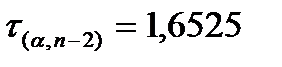 для n=200 -критическое значение распределения Стьюдента.
для n=200 -критическое значение распределения Стьюдента.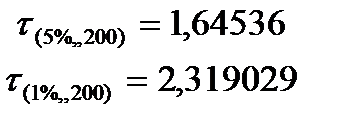
 и
и 
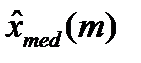 берем средний по расположению элемент упорядоченной выборки. Воспользуемся формулой (7) для m=194 – четного:
берем средний по расположению элемент упорядоченной выборки. Воспользуемся формулой (7) для m=194 – четного: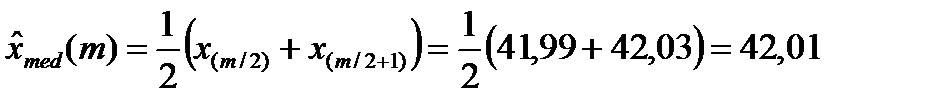 .
.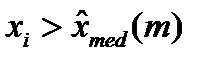 , и «-», если
, и «-», если 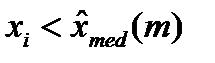 . Полученная последовательно плюсов и минусов характеризуется числом серий
. Полученная последовательно плюсов и минусов характеризуется числом серий 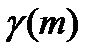 и диной самой длинной серии
и диной самой длинной серии 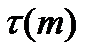 , где под серией понимают последовательность подряд идущих плюсов или подряд идущих минусов.
, где под серией понимают последовательность подряд идущих плюсов или подряд идущих минусов.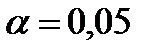 , тогда решение вопроса о стохастической независимости результатов наблюдения основываем на следующих неравенствах:
, тогда решение вопроса о стохастической независимости результатов наблюдения основываем на следующих неравенствах: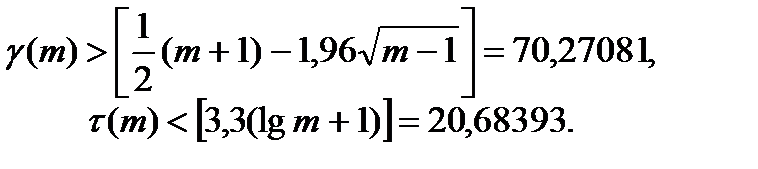
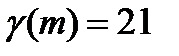 ,
, 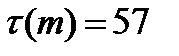 .
.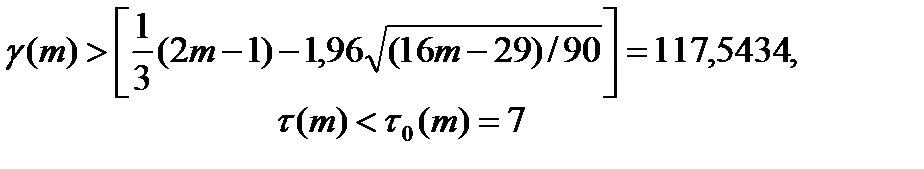
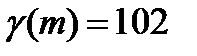 ,
, 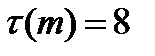 .
.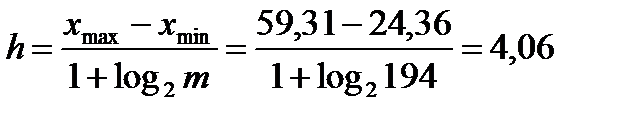
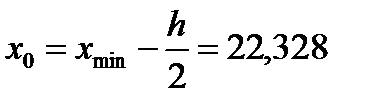 , тогда получим ряд:
, тогда получим ряд: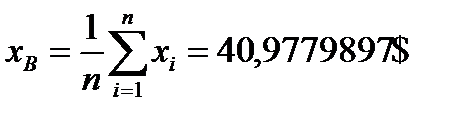 - несмещенная и состоятельная оценка мат. ожидания;
- несмещенная и состоятельная оценка мат. ожидания;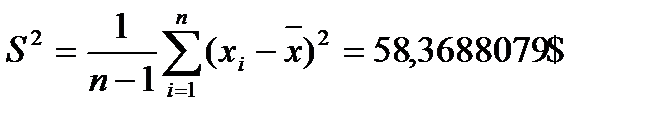 - несмещенная и состоятельная оценка дисперсии
- несмещенная и состоятельная оценка дисперсии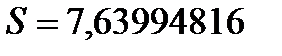 $- среднеквадратичное отклонение.
$- среднеквадратичное отклонение.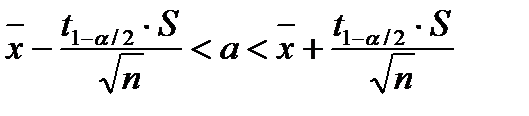 , где
, где 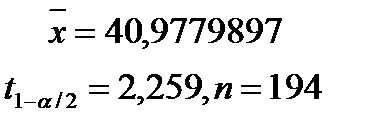 , тогда
, тогда - интервальная оценка мат. ожидания
- интервальная оценка мат. ожидания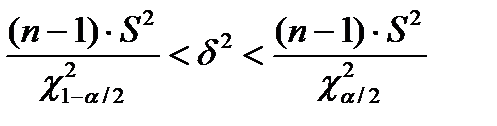 , где
, где 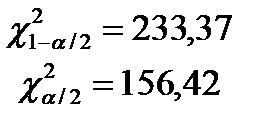 , n=194, тогда
, n=194, тогда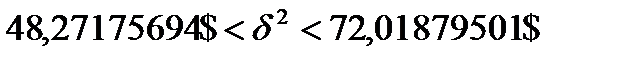 .
.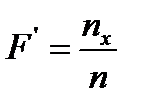 - эмпирическая функция распределения;
- эмпирическая функция распределения;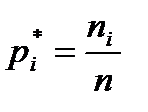 - относительная эмпирическая частота.
- относительная эмпирическая частота.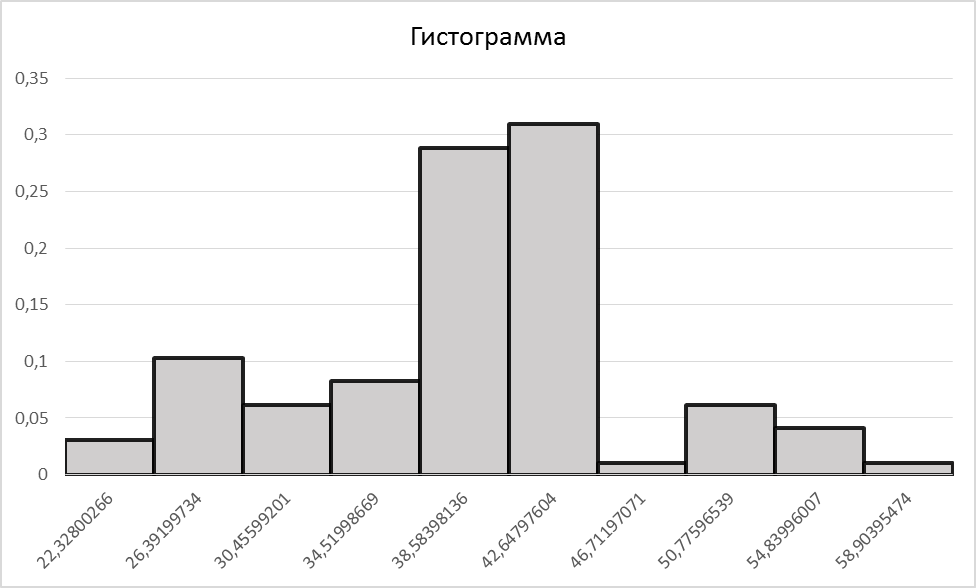
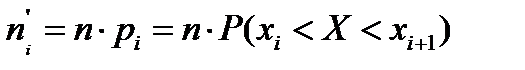 - теоретическая частота, где
- теоретическая частота, где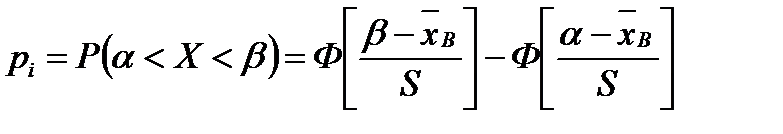
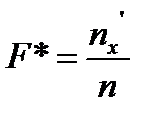 - теоретическая функция распределения.
- теоретическая функция распределения.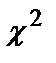
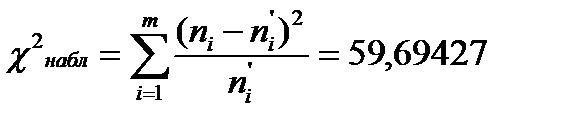 .
.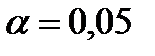 .
.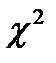 - распределения находим критическую точку
- распределения находим критическую точку 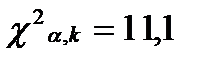 , где
, где 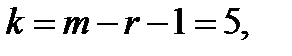 m=8 – число интервалов выборки, r=2 – число параметров, предполагаемого распределения.
m=8 – число интервалов выборки, r=2 – число параметров, предполагаемого распределения.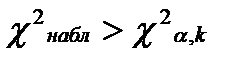 , следовательно, гипотеза H0 отвергается.
, следовательно, гипотеза H0 отвергается.


