
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Практическое занятие Расчет ошибки выборки, показателей генеральной совокупности, объема выборкиСтр 1 из 8Следующая ⇒
Практическое занятие Расчет ошибки выборки, показателей генеральной совокупности, объема выборки Генеральная совокупность Суммарная численность объектов наблюдения (люди, домохозяйства, предприятия, населенные пункты и т.д.), обладающих определенным набором признаков (пол, возраст, доход, численность, оборот и т.д.), ограниченная в пространстве и времени. Примеры генеральных совокупностей · Все жители Москвы (10,6 млн. человек по данным переписи 2002 года) · Мужчины-Москвичи (4,9 млн. человек по данным переписи 2002 года) · Юридические лица России (2,2 млн. на начало 2005 года) · Розничные торговые точки, осуществляющие продажу продуктов питания (20 тысяч на начало 2008 года) и т.д. Выборка (Выборочная совокупность) Часть объектов из генеральной совокупности, отобранных для изучения, с тем чтобы сделать заключение обо всей генеральной совокупности. Для того чтобы заключение, полученное путем изучения выборки, можно было распространить на всю генеральную совокупность, выборка должна обладать свойством репрезентативности. Репрезентативность выборки Свойство выборки корректно отражать генеральную совокупность. Одна и та же выборка может быть репрезентативной и нерепрезентативной для разных генеральных совокупностей. · Выборка, целиком состоящая из москвичей, владеющих автомобилем, не репрезентирует все население Москвы. · Выборка из российских предприятий численностью до 100 человек не репрезентирует все предприятия России. · Выборка из москвичей, совершающих покупки на рынке, не репрезентирует покупательское поведение всех москвичей. В то же время, указанные выборки (при соблюдении прочих условий) могут отлично репрезентировать москвичей-автовладельцев, небольшие и средние российские предприятия и покупателей, совершающих покупки на рынках соответственно. Ошибка выборки (доверительный интервал) Отклонение результатов, полученных с помощью выборочного наблюдения от истинных данных генеральной совокупности.
· Использование любых вероятностных выборок занижает долю людей с высоким доходом, ведущих активный образ жизни. Происходит это в силу того, что таких людей гораздо сложней застать в каком-либо определенном месте (например, дома). · Проблема респондентов, отказывающихся отвечать на вопросы анкеты (доля «отказников» в Москве, для разных опросов, колеблется от 50% до 80%) В некоторых случаях, когда известны истинные распределения, систематическую ошибку можно нивелировать введением квот или перевзвешиванием данных, но в большинстве реальных исследований даже оценить ее бывает достаточно проблематично. Типы выборок Выборки делятся на два типа: · вероятностные · невероятностные 1. Вероятностные выборки
2.Невероятностные выборки Вычисление ошибки репрезентативности для собственно случайной выборки. Пусть нам необходимо оценить средний возраст некоторой группы людей по ограниченному числу наблюдений n. Оценкой среднего значения непрерывной случайной величины является математическое ожидание:
Естественной оценкой математического ожидания является среднее арифметическое:
От оценки необходимо потребовать следующие свойства: 1. состоятельность – оценка называется состоятельное, если при увеличении числа опытов оценка сходится по вероятности с искомым параметром, 2. несмещенность – оценка называется несмещенной, если выполнялось условие
3. эффективность – оценка называется эффективной, если ее дисперсия минимальна по сравнению с другими. Среднее арифметическое обладает этими свойствами[1]. Оценка параметра является функцией от случайных величин
и дисперсией
где Тогда можно рассчитать вероятность того, что
Рисунок 1. Распределение выборочной оценки среднего. Приведем это распределение к стандартному виду.
Произведем замену переменной:
Справа получили функцию Лапласа, которая табулирована (см. Приложение):
Нам не известно значение
где При больших объемах выборки вид распределения Стьюдента приближается к виду нормального распределения, поэтому для больших выборок также можно использовать функцию Лапласа. Для повторной выборки
Для бесповторной выборки необходимо внести поправку на конечность ГС
Для большой ГС (объем ВС составляет менее 5% от ГС) поправкой на конечность совокупности можно пренебречь. Про коэффициент доверия Пример 1. Пусть была произведена выборка 1600 человек. Средний возраст по выборке – 30 лет, среднеквадратическое отклонение – 10 лет. Необходимо найти доверительный интервал. Прежде всего, необходимо задать надежность оценки. Возьмем 95% надежность. Поскольку выборка большая, воспользуемся таблицей значений функции Лапласа и найдем коэффициент доверия Тогда
С вероятностью 95% истинное средний возраст по ГС находится в интервале от 29,51 лет до 30,49 лет. Для биномиального распределения
где Тогда для повторной выборки из (1)
для бесповторной выборки из (2)
Пример 2. Из 200 опрошенных 55% - женщины. Действуем аналогично примеру 1. Выборку также можно считать большой. Тогда
С вероятностью 95% доля женщин в ГС находится в интервале от 48% до 62%. Механическая выборка. Наиболее близкой к собственно случайной выборке является механическая выборка. Однако даже она может приводить к систематическим ошибкам. Практическая реализация. Проведение механической выборки требует список характеристик респондентов (фамилии, адреса, телефоны и т.д.). Из этого списка через равные промежутки люди отбираются в выборку. Этот промежуток называется шагом выборки.
N – объем генеральной совокупности n – объем выборочной совокупности. Начало отбора выбирается случайным образом в пределах шага выборки. Например, если шаг выборки равен 20, то начинать отбор надо с любого числа от 1 до 20. Вычисление ошибки выборки. При определении ошибки репрезентативности используются те же формулы, что и при случайной выборке. Определение объема выборки. Как следствие, при определении объема выборки так же используются те же формулы, что и при случайной выборке. Плюсы и минусы механического отбора. Процедура проведения механической выборки менее громоздка, чем проведение случайной выборки. Хотя применение компьютеров практически нивелирует это преимущество. Механическая выборка может быть как более точной, так и менее точной по сравнению со случайной выборкой. Это продемонстрирует следующий пример. Пример: [6, 51-52].Воспользуемся данными таблицы 1. Из всех респондентов проведем механическую выборку путем отбора каждого четвертого респондента, начиная с первого. В таблице 5 представлены четыре возможные выборки. Факторы, Выборку от респондента: | не зависит | А | С | E | ||||||
| зависит | В | D | X |
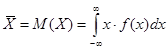 .
. .
. ,
, ,
, 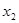 , …,
, …,  , поэтому сама является случайной величиной. Другими словами, мы можем сделать множество выборок, для каждой из которых значение оценки будет различно. По закону больший чисел распределение оценки является нормальным с математическим ожиданием
, поэтому сама является случайной величиной. Другими словами, мы можем сделать множество выборок, для каждой из которых значение оценки будет различно. По закону больший чисел распределение оценки является нормальным с математическим ожиданием
 [2],
[2], - генеральная дисперсия.
- генеральная дисперсия.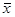 попадет в интервал
попадет в интервал 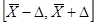 . Поскольку нам неизвестна величина
. Поскольку нам неизвестна величина 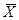 , то мы будем говорить о вероятности, с которой интервал
, то мы будем говорить о вероятности, с которой интервал 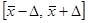 накроет
накроет  .
.
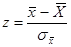


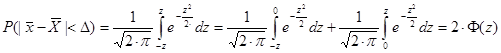 .
.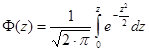 .
.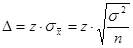
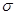 , поэтому заменим его на
, поэтому заменим его на 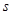 . Но в этом случае нужно использовать не нормальное распределение, а распределение Стьюдента.
. Но в этом случае нужно использовать не нормальное распределение, а распределение Стьюдента. ,
,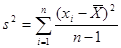
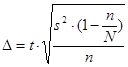 (2).
(2).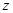 следует сказать отдельно. Этот коэффициент исследователь выбирает сам. Чем меньше
следует сказать отдельно. Этот коэффициент исследователь выбирает сам. Чем меньше  .
.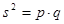 ,
,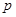 – доля признака,
– доля признака, 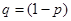 .
.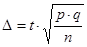 (3),
(3), (4).
(4). .
.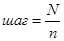 , где
, гдеРассмотрим подробнее каждый из типов неслучайного отбора.
Доступная выборка
Как следует из названия, в этом случае проводится отбор доступных единиц. Одним из плюсов этого метода являются сравнительно низкие издержки на поиск респондентов.
А: доступные респонденты выделены заранее;
В: респонденты выявляются в процессе опроса, поэтому действительное число доступных объектов определяется апостериори.
Сферы применения доступной выборки:
1) тестирование анкет
2) отработка процедур опроса
3) изучение интимных сторон жизни людей
4) изучение здоровья населения на основе данных об обращениях в больничные учреждения
5) монографические обследования.
Метод типичных единиц.
При использовании данного метода отбираются единицы генеральной совокупности, обладающие средним (или типичным) значением признака. Однако в таком случае встает проблема выбора признака и определения его типичного значения. Субъективный характер оценки вполне может привести к систематической ошибке. Данный метод целесообразно применять для изучения таких объектов, о которых мы уже обладаем некоторой информацией, например, территориальных общностей, предприятий, учреждений и т.п.
Целевая выборка.
Сферы применения целевой выборки:
1) формирование состава участников эксперимента (например, формирование контрольных групп точечным методом, когда для каждого участника основной группы подбирается участник контрольной группы, обладающий сходными признаками). Это один из тех редких случаев, когда нет необходимости в проведении случайного отбора.
|
|
2) отбор экспертов, который может проводиться на основе следующих критериев:
· объективные характеристики экспертов, содержащиеся в документах
· тестирование кандидатов в эксперты
· взаимный отбор
· самооценка кандидатов в эксперты.
Квотный отбор.
Остановимся на описании этого метода более подробно, т.к. это один из самых распространенных методов неслучайного отбора.
При использовании данного метода отбирают один или несколько признаков, по которым будет контролироваться выборка. Количество единиц в выборке, обладающих определенными характеристиками, должно быть пропорционально количеству таких единиц в генеральной совокупности.
Виды квотного отбора.
Можно выделить две разновидности метода квот:
1) априорный отбор
2) апостериорный отбор.
Априорный отбор осуществляется интервьюером на стадии сбора первичной информации.
Апостериорный отбор проводится для корректировки выборки. Например, когда в газету приходят письма с заполненными читателями анкетами, часто среди ответивших имеется перекос по некоторым важным параметрам (возраст, пол и т.п.). В таком случае можно взвесить полученные результаты, а можно провести выборку из выборки квотным методом.
Выбор признаков.
Во-первых, выбранные признаки должны быть тесно связаны с изучаемыми характеристиками, иначе полученные результаты могут оказаться сильно искаженными.
Во-вторых, признаки должны быть независимыми, иначе расход средств на их контроль будет нерациональным.
Требования к выборке могут быть жесткими и пониженными. Жесткие требования означают совпадение пропорций генеральной и выборочной совокупностей по сочетаниям признаков. В этом случае структура выборочной и генеральной совокупностей по заданным параметрам точно совпадают. При использовании пониженных требований контролируют лишь совпадение пропорций по каждому параметру отдельно.
Например, если исследователи решили контролировать выборку по четырем параметрам: пол (2 градации), возраст (7 градаций), образование (6 градаций) и род занятий (12 градаций), то при предъявлении пониженных требований они получат 2+6+7+12=27 групп, а при предъявлении жестких требований они получат 2*6*7*12=1008 групп.
Обычно к выборке предъявляют пониженные требования, так как в обратном случае теряется основное преимущество квотного отбора – малый объем выборки, и увеличиваются затраты на поиск респондентов, обладающих определенными характеристиками.
Чаще всего используются социально – демографические признаки, так как:
· они часто носят ключевой характер
· легко получить информацию о распределении по этим признакам единиц в генеральной совокупности.
Обычно используют не более трех – четырех признаков, так как при увеличении их числа растет число ограничений и, соответственно, растут затраты на поиск респондентов.
Трудности, возникающие при применении метода квот.
1. Необходимо предварительное изучение объекта для выявления в нем пропорций единиц с различными характеристиками и связей между характеристиками.
2. Необходима свежая информация о генеральной совокупности. Например. Если активно происходят какие-то демографические процессы, например, миграция, то применение данных переписи населения, проведенной несколько лет назад, может дать большую систематическую ошибку.
3. Некоторые проблемы могут возникнуть на полевом этапе проведения исследования:
3.1 Интервьюер, скорее всего, будет проводить отбор среди наиболее доступных ему лиц, поэтому выборка имеет тенденцию превращаться в доступную. При этом проблема «крепких орешков» не решается, а обходится, так как даже в группе труднодоступных, «дефицитных» респондентов будет происходить смещение в сторону тех, кто наиболее охотно идет на контакт с интервьюером.
3.2 Ближе к концу полевого этапа часто возникает группа «дефицитных» признаков, поэтому повышается соблазн для интервьюера сфальсифицировать результаты.
Практическое занятие Расчет ошибки выборки, показателей генеральной совокупности, объема выборки
Генеральная совокупность
Суммарная численность объектов наблюдения (люди, домохозяйства, предприятия, населенные пункты и т.д.), обладающих определенным набором признаков (пол, возраст, доход, численность, оборот и т.д.), ограниченная в пространстве и времени. Примеры генеральных совокупностей
· Все жители Москвы (10,6 млн. человек по данным переписи 2002 года)
· Мужчины-Москвичи (4,9 млн. человек по данным переписи 2002 года)
· Юридические лица России (2,2 млн. на начало 2005 года)
· Розничные торговые точки, осуществляющие продажу продуктов питания (20 тысяч на начало 2008 года) и т.д.



