Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Многоуровневый анализ документа ( MDA )
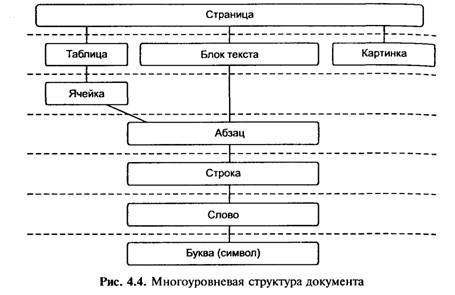
Подлежащий распознаванию документ часто выглядит заметно сложнее, чем белая страница с черным текстом. Иллюстрации, таблицы, колонтитулы, фоновые изображения — эти элементы, все чаще применяемые для оформления, усложняют структуру страницы. Для того чтобы корректно воспроизводить в электронном виде такие документы, все современные OCR-программы начинают распознавание именно с анализа структуры. Как правило, при этом выделяют несколько иерархически организованных логических уровней. Объект наивысшего Уровня только один — собственно страница, на следующей ступени иерархии располагаются таблица и текстовый блок, и так далее (рис. 4.4). Любой высокоуровневый объект может быть представлен как объектов более низкого уровня: буквы образуют слово, слова — строки и т. д. Поэтому анализ всегда начинается в направлении сверху вниз. Программа делит страницу на объекты, их, в свою очередь, — на объекты низших уровней, и так далее, вплоть до символов. Когда символы выделены и распознаны, начинается обратный процесс — «сборка» объектов высших уровней, который завершается формированием целой страницы. Такая процедура называется многоуровневым анализом документа, или MDA (multilevel document analysis).
Очевидно, что программа, допустившая ошибку при распознавании объекта высокого уровня (например, перепутавшая абзац текста с иллюстрацией), почти не имеет шансов корректно завершить процедуру — итоговый электронный документ будет искажен. Риск столкнуться с подобной ситуацией существовал бы и для FineReader, однако он ведет анализ документа несколько иначе. Во-первых, объекты любого уровня FineReader распознает в соответствии с принципами IPА. В первую очередь выдвигаются гипотезы относительно типов обнаруженных объектов, затем они целенаправленно проверяются. При этом система учитывает найденные ранее особенности данного документа, а также сохраняет вновь поступающую информацию (обучается). Допустим, все объекты текущего уровня распознаны. FineReader переходит к детальному анализу одного из них, определенного, к примеру, как текстовый блок. Предположим, вдруг оказывается, что результаты анализа этого блока крайне неубедительны; не удается выделить ни абзацы, ни строки. Повторный анализ позволяет внести коррективы: да, это текст, но наложенный на фоновое изображение. После дополнительной обработки распознавание будет продолжено — и уже без ошибок.
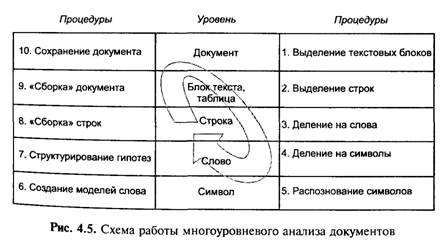
Описанная ситуация наглядно иллюстрирует вторую важную особенность используемого в системе FineReader алгоритма MDA: на всех этапах многоуровневого анализа существует возможность обратной связи — результаты анализа на одном из нижних уровней всегда могут повлиять на действия с объектами более высоких уровней. Наличие обратной связи в процедуре MDA дает возможность резко понизить вероятность грубых ошибок, связанных с неверным распознаванием объектов более высоких уровней. Распознавание любого документа производится поэтапно, с помощью процедуры многоуровневого анализа документа (MDA). Деление страницы на объекты низших уровней, вплоть до отдельных символов, распознавание этих символов и «сборку» электронного документа FineReader проводит, опираясь на принципы целостности, целенаправленности и адаптивности (IPA) (рис. 4.5).
|
|||||
|
|
Последнее изменение этой страницы: 2021-04-05; просмотров: 155; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 52.14.121.242 (0.004 с.) |