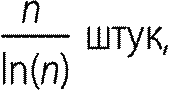Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Несколько интересных свойств простых чисел
Простых чисел, которые не превосходят п, примерно
где ln(n) это натуральный логарифм. Заметим, что ln(n) растет гораздо медленнее, чем п. Получается, что простые числа попадаются довольно часто. По этой оценке, их количество от одного до миллиарда равно примерно 48 254 942. На самом деле таких чисел 50 847 534[15], то есть оценка вполне точная. Первым, кто добился серьезных продвижений в получении подобных оценок, был наш замечательный математик Пафнутий Львович Чебышев (1821–1894). Есть и такой забавный результат: между х и 2 х всегда находится простое число. Это так называемый постулат Бертрана. Однако проблема его уточнения очень сложна, а именно: верно ли, что между х и 1,1 х есть простые числа (хотя бы при больших x)? Верно ли, что они есть между х и x + √ x? Первое верно, а о втором никто не знает. Все верят в бесконечность числа «простых близнецов»: 11 и 13, 17 и 19, 29 и 31 и так далее. Но пока никто не может это доказать.
Важно понимать, что никаких формул для поиска простых чисел не существует в принципе! Простые числа распределены очень хитро. Как мы скоро увидим, они крайне важны на практике, особенно сверхбольшие простые числа. Целая индустрия, привлекающая как математиков, так и программистов, занимается построением все новых и новых простых чисел. Так, в январе 2016 года было найдено очередное простое число, равное 274207281−1. В нем 22 338 618 знаков! Нечто запредельное…
Открытый обмен ключами
В настоящее время особенно популярны так называемые схемы шифрования с открытым ключом. Мы расскажем о схеме Диффи – Хеллмана, которая датируется 1970‑ми годами и активно используется на практике. Эта схема основана на глубокой математике, но саму идею понять совсем несложно. Возьмем простое число р. В реальности оно должно быть огромным, но для примера выберем маленькое простое число 19. Теперь выберем еще одно число g, тоже целое, но необязательно простое и меньше р. Например, g = 2. Числа р и g знают все: и Алиса, и Боб, и даже Ева. Теперь Алиса выбирает число х, например x = 6, и хранит его в тайне. Боб выбирает число у, скажем y = 8, и тоже никому его не сообщает. Дальше начинается шифрование. Алиса находит остаток от деления на р числа g х:
26 = 64, 64÷19 = 3 и 7 в остатке.
Боб делает то же самое со своим задуманным числом:
28 = 256, 256÷19 = 13 и 9 в остатке.
Итак, наше преобразование выглядит следующим образом: возвести 2 в степень х и взять остаток от деления на 19. Мы изобразили это преобразование в общем виде на рис. 6.3. Напомним, что числа g и р известны, а число х выбрала Алиса.
Рис. 6.3. Преобразование по схеме Диффи – Хеллмана x → f (x). Числа g и р известны, а число х выбрала Алиса
Здесь принципиально важно, что р простое число, а g меньше р, потому что в этом случае gх на р не делится, то есть остаток от деления не может быть нулем. Есть и более глубокие причины, почему р должно быть простым. Кроме того, для заданного р есть набор «подходящих» g [16]. Получив остаток от Боба, Алиса возводит его в степень х и снова берет остаток от деления на р. В нашем маленьком примере Алиса получила от Боба число 9, а Боб от Алисы число 7. Тогда у Алисы получается:
[остаток от деления 96 на 19] = 11.
Боб действует аналогично. Он получил остаток от Алисы, и у него есть известный ему одному у (даже Алиса его не знает!). Он возводит полученный от Алисы остаток в степень у и снова берет остаток от деления на р:
[остаток от деления 78 на 19] = 11.
Это то же самое число 11, что и у Алисы! Естественно, это неслучайно. Математически нетрудно показать, что Алиса и Боб получат одинаковое число при любых р, g, x, и у [17].
Зашифровать можно. Расшифровать нельзя!
Вычисление f(x) по схеме Диффи – Хеллмана – сравнительно быстрая операция, которую можно осуществить и на домашнем компьютере, даже если р огромное, скажем стозначное число. Тем не менее лучшие математики мира вот уже несколько десятилетий бьются над построением алгоритма, который, наоборот, по остатку от деления на р выдавал бы значение х. И ничего не получается! Самые быстрые алгоритмы работают месяцы, даже будучи параллельно запущенными на тысячах мощных компьютеров по всему миру. Ниже мы расскажем о совсем недавней наиболее успешной попытке решения. Но, как мы увидим, этот метод тоже не «быстрый», а скорее «в принципе выполнимый» и сильно опирается на конкретную имплементацию шифра.
Конечно, это не значит, что по‑настоящему быстрого алгоритма не существует. Но задача оказалась настолько сложной, что схема очень активно используется на практике, и если выбрать число р по‑настоящему большим, то можно не бояться взлома шифра. В нашем маленьком примере у Алисы и Боба после открытого обмена сообщениями появился общий секретный ключ, число 11. С его помощью Алиса и Боб могут спокойно зашифровывать и расшифровывать сообщения и передавать их друг другу. Но Еве этот ключ не заполучить, потому что она не сможет вычислить ни x, ни у. Красота схемы в том, что Алиса и Боб обмениваются ключами через открытый канал. Ева может перехватить все сообщения до одного, но ей это ничего не даст! Именно поэтому подобные схемы называются «открытым обменом ключами». Нет никакого секрета в том, как работают эти схемы. При этом несанкционированная расшифровка ваших сообщений – проблема посложнее «Энигмы». Секретность без секретов. На практике часто используется еще одна схема открытого обмена ключами – алгоритм RSA, названный так по первым буквам имен своих авторов: Ривеста, Шамира, Адлемана (Rivest, Shamir, Adleman). Для интересующегося читателя ниже во врезке мы кратко объясняем основной принцип его работы. Если вы не хотите вдаваться в детали, можете пропустить этот текст.
Алгоритм RSA Алиса может выбрать не одно число, а сразу пару чисел р, q. Можно считать, что p и q – простые. Возьмем очень простое преобразование
n = p × q.
Это довольно быстрая операция – обычное умножение. Однако если вам дано натуральное число n и даже известно, что n = p × q с некоторыми простыми р и q, которых вы не знаете, то восстановить эти простые числа вам не удастся! Вернее, на это уйдут годы, коль скоро п достаточно велико. Вот такие чудеса! Принцип здесь тот же самый. Для вычисления п используется простое умножение, это очень быстрая операция. А вот обратный процесс, операция разложения на множители, носит в математике красивое имя факторизация (от англ. factor – сомножитель) и представляет собой большую проблему с точки зрения вычислений. Добавим, что операцию разложения на множители легко выполнить на квантовом компьютере. Но пока у таких компьютеров очень ограниченный регистр, то есть они могут работать только с относительно маленькими числами. Для шифрования на практике используются очень большие числа. Поэтому на данный момент квантовые компьютеры особой угрозы не представляют.
Практика шифрования
Схемы типа Диффи – Хеллмана и RSA работают довольно медленно, в отличие от так называемых симметричных криптосистем, которые гораздо быстрее. Но они пользуются ключом, который нужно хранить в тайне. В определенном смысле это аналоги «Энигмы». Они шифруют с помощью ключа и большого количества сложных преобразований, и знание ключа необходимо для расшифровки. Итак, у нас есть быстрые схемы, для которых нужен ключ, и медленные – для обмена ключами. Поэтому обычно сессия безопасного соединения через интернет состоит из двух этапов. Сначала происходит так называемое рукопожатие, то есть обмен сообщениями, во время которого, в частности, устанавливаются ключи. Именно на этом этапе применяются схемы с открытыми ключами, Диффи – Хеллмана или RSA. У «рукопожатия» есть еще несколько целей – например, часто используется аутентификация: сервер хочет убедиться, что он общается с тем, с кем думает, а клиент – что он общается с правильным сервером.
После того как ключи установлены, в течение всей оставшейся сессии сообщения зашифровываются с помощью симметричных криптосистем. В духе эпохи интернета всем хорошо известно, как эти системы работают. Если у Евы есть ключ от вашей сессии, то все ваши секреты у нее в кармане! В предыдущих разделах мы говорили, что за ваши ключи можно не волноваться. На страже стоят сложные математические операции, которые никто не умеет выполнять. И это правда. Тем не менее качество шифрования зависит не только от математики, но и от имплементации. Хорошо известно, что для надежного шифрования нужно пользоваться очень большими простыми числами. Стандартная величина 1024 бита, то есть 21024. Речь идет о 308‑значных числах! Таких простых чисел очень много, выбор большой. Но, к сожалению, многие протоколы пользуются одними и теми же числами, снова и снова. Просто потому, что так легче. Насколько это угрожает нашей безопасности? В 2015 году вышла статья {18}, которая сильно всколыхнула мир криптографии. Авторы впервые назвали цену взлома наиболее распространенной имплементации схемы Диффи – Хеллмана: 100 миллионов долларов!
Миллионов долларов за число
Помните, как Алан Тьюринг взломал шифр «Энигмы»? Он построил большую машину, которая смогла быстро вычислить ключ. У этой истории две принципиальные составляющие: «машина» и «быстро». По сути, до сих пор так все и осталось. Можно сказать, что подход Тьюринга – это прообраз современного подхода к взламыванию шифров. Нужно наличие машины и способ быстрого подсчета ключа. Машину строить необязательно, можно купить суперкомпьютер, были бы средства. Основная загвоздка, как вы уже поняли, именно в быстром способе подсчета. И вот тут авторы статьи {19} совершили прорыв. На основной конференции по компьютерной безопасности в 2015 году они представили новую атаку Logjam. Фактически это метод вычисления ключа в схеме Диффи – Хеллмана, при котором сами сообщения нужны лишь на последнем этапе. Эти последние шаги можно совершить очень быстро. Для основной части вычислений необходимо знать только простое число р. Поэтому основные – колоссальные – вычисления можно сделать заранее и держать ответы наготове. А дальше, как только начнется обмен сообщениями по открытому каналу, остается всего лишь их перехватить и с их помощью быстро завершить вычисление ключа.
Насколько колоссальны предварительные вычисления? Авторы просчитали, что если закупить оборудование стоимостью в пару сотен миллионов долларов, то за год можно взломать одно 308‑значное простое число! Только одно. Предлагаем на секунду остановиться и еще раз оценить сложность задачи. Реальна ли эта угроза? Скажем так: Logjam не для домашнего применения. Но, например, Агентству национальной безопасности США пара сотен миллионов вполне по карману. И если верить авторам, эта сумма примерно соответствует бюджету агентства на компьютерную криптографию. Стоит ли оно того? Да. По крайней мере если большинство протоколов пользуются одними и теми же 308‑значными числами, что и происходит на практике. Авторы утверждают[18], что взломав одно наиболее распространенное 308‑значное простое число, можно пассивно прослушивать примерно две трети трафика VPN и примерно четверть SSH‑серверов. А если взломать еще и второе по популярности число, то можно добраться приблизительно до 20 % от топ‑миллиона HTTPS‑сайтов. По предположениям авторов, Агентство национальной безопасности в самом деле применяет подобные методы для прослушивания зашифрованного трафика. И многие верят, что так оно и есть. Вполне вероятно, что службы государственной безопасности продвинулись в криптографии гораздо дальше ученых. Криптография окружена секретностью. Например, в 1996 году адвокат посоветовал американскому профессору не допускать к занятиям по криптографии иностранных студентов, потому что, оказывается, есть закон, запрещающий делиться алгоритмами криптографии с иностранцами, даже если эти алгоритмы описаны в учебниках и любой студент в состоянии их запрограммировать![19] А аспиранту Университета Беркли, который хотел опубликовать новые результаты по криптографии, пришлось четыре года судиться с американским правительством, пока очередной суд не признал, что запрет публикации противоречит Первой поправке к Конституции США, которая не позволяет создавать законы, противоречащие свободе слова[20]. На самом деле трудно понять, где заканчивается свободная наука и начинается государственная тайна. На конференции французский профессор криптографии Роберт Эрра с улыбкой сказал: «Один профессор, звезда в нашей области, утверждал, что редко встречал криптографа, который не пытался бы взломать RSA. Но, честно, если бы мне это удалось, я не отправил бы статью прямиком в журнал, а сначала позвонил бы министру обороны!» Интересно, кстати, что ученые‑криптографы изо всех сил пытаются взломать шифры. Зачем? Чтобы найти слабинку и придумать новые более надежные способы шифрования. Например, авторы Logjam рекомендуют пользоваться еще большими, 616‑значными, простыми числами. А если это технически невозможно, то советуют по крайней мере выбирать разные простые числа. Сразу после появления статьи многие браузеры обновили протоколы, в том числе Chrome и Firefox[21]. Наши секреты должны оставаться в безопасности, даже если они транслируются по открытым каналам по всему миру.
Приложения для подготовленного читателя к главе 6
Глава 7 Счетчики с короткой памятью
Большие данные
Вы, наверное, слышали о понятии большие данные. Существуют самые разные определения, но, по сути, термин «большие данные» означает, что нам ничего не стоит получить огромное количество разной информации. И сразу возникает вопрос, как ее обработать. Например, банковские платежи совершаются через интернет или по электронным картам. Современный банк может без особых усилий собрать и сохранить данные о каждой трансакции. Казалось бы, теперь мы можем ответить на любые вопросы. Какие продукты наращивают популярность? Насколько широко используются наши услуги, карты, банкоматы? Но, оказывается, разобраться в миллионах электронных записей не так уж просто, даже при наличии самых мощных компьютеров. Особенно если ответы нужны прямо сейчас! Большие данные сами по себе не дают ответа на все наши вопросы. Их анализ влечет за собой множество проблем. В этой главе мы расскажем только об одной такой проблеме. Звучит она совершенно элементарно, но для ее решения понадобилась новая и далеко не тривиальная математическая теория. Почему? Потому что, как и во многих других задачах с большими данными, ее наивное решение приводит к абсолютно невыполнимым требованиям к компьютерной памяти. Чтобы было понятно, мы расскажем о самой проблеме чуть позже, в разделе «Раз, два, три, четыре, пять…». А сначала вкратце объясним, как устроена компьютерная память и почему, несмотря на ее мощь и колоссальный объем, она все‑таки не всесильна.
Компьютерная память
Мы уже рассказали в главе 3, что вся информация в компьютере записывается в виде нулей и единиц. Каждый ноль и единица физически занимают крошечную ячейку памяти. Чтобы сохранить одну цветную фотографию на 3 мегабайта, понадобится
3×8×220=25 165 824,
то есть больше 25 миллионов таких ячеек. Обычно память работает на полупроводниках. Но мы будем просто считать (для нашего рассказа этого достаточно), что компьютерная память – это физическое устройство, где каждый символ (0 или 1) занимает место. Такие устройства могут быть самыми разными, например CD, DVD или флешка. В любом компьютере информация записывается на жесткий диск. Качество устройств памяти непрерывно улучшается. На жестком диске современных ноутбуков может умещаться, скажем, 320, а то и больше гигабайтов. Этого хватит, чтобы сохранить более ста тысяч цветных фотографий! Если вам нужно еще больше памяти, можно хранить данные на удаленном сервере. Многие компании, в том числе Google и Amazon, предлагают подобные услуги. Это очень популярный сервис. Возможно, вы тоже что‑то храните «в облаке». У таких информационных гигантов, как Google и «Яндекс», есть свои дата‑центры. Если вы хотите получить представление о том, как выглядят дата‑центры «Яндекса», можете зайти, например, на сайт https://yandex.ru/company/technologies/datacenter. Фактически дата‑центры – это целые комплексы, которые занимают большие территории, где каждое строение либо заполнено серверами, либо предназначено для их энергоснабжения, охлаждения и обслуживания. Компьютерная память сама по себе пока еще не является ограниченным ресурсом. Дисков и серверов мы можем построить достаточно. Вопрос в том, как воспользоваться всей этой информацией. И вот здесь возникают проблемы, потому что диск не в состоянии «сообразить» или «вспомнить». Чтобы извлечь информацию, компьютер должен найти нужную ячейку памяти. На доступ к информации на жестком диске или сервере уходит какое‑то время. Это можно представить себе примерно так. Предположим, вы читаете дома книгу на английском языке со словарем. Только словарь лежит в библиотеке! И вы бегаете в библиотеку и обратно за каждым словом, причем каждый раз аккуратно ставите словарь обратно на полку и в следующий раз заново ищете его по каталогу. Конечно, компьютер найдет информацию на диске быстрее, чем вы добежите до библиотеки. Но и операций он выполняет гораздо больше, поэтому сравнение вполне уместное. Без сомнения, намного удобнее, когда словарь лежит рядом с вами на диване. Для этого у компьютера есть так называемая оперативная память. Информация считывается с диска, обрабатывается в оперативной памяти, после чего результаты снова сохраняются на диске, а оперативная память освобождается для следующей задачи. Доступ к оперативной памяти происходит очень быстро, несравнимо с жестким диском. Но именно поэтому ее объем существенно ограничен. На вашем диване не поместится полбиблиотеки. Обычный ноутбук может предложить, например, 2 гигабайта оперативной памяти. Кстати, как раз из‑за этого компьютер начинает «тормозить», если у вас открыто слишком много программ и документов. Получается, что могущество компьютерной памяти сильно ограничено. У памяти на диске или сервере практически бесконечный объем, зато ограничена скорость доступа. А у оперативной памяти скорость феноменальная, зато объем очень маленький. Какие последствия все это имеет для обработки больших данных? Оказывается, это фундаментальная и серьезная проблема даже для самых незамысловатых операций.
Раз, два, три, четыре, пять…
Рассмотрим небольшой пример. Допустим, банк выпустил пятьдесят кредитных карт с номерами 01, 02… 50. Всего было проведено 30 трансакций по картам с номерами:
Спрашивается: сколько клиентов воспользовалось кредитными картами? Попробуйте сами ответить на этот вопрос. Каковы ваши действия? Поначалу все просто: 15 – это раз, 48 – два, 32 – три, 31 – четыре. Дальше снова 48, но эта та же карточка, поэтому мы ее не считаем. 27 – пять. В первом ряду всего 8 разных номеров. А вот во втором ряду уже начинаются затруднения. Попадался нам номер 02 до этого или нет? А 29? Или 45? Наша память не в состоянии это удержать! В результате до конца третьего ряда можно добраться только одним способом – сравнивать каждый номер со всеми предыдущими и ставить пометку, если он раньше не встречался. Ответ: 22 карты. Ниже мы выделили разные номера жирным шрифтом.
Теперь представьте, что эту задачу выполняет компьютер. Каким образом можно сравнить номер каждой карты со всеми предыдущими? Особенно если трансакций не тридцать, а три миллиона? И вот тут возникает проблема с памятью. Считывать все номера заново с жесткого диска – непозволительно долго. А оперативная память переполнится гораздо раньше, чем мы дойдем до середины. Что же получается? При наличии полных данных и самых мощных компьютеров мы не в состоянии подсчитать, сколько человек воспользовалось кредитными картами?! В принципе да, не в состоянии. И конечно, кредитные карты – это всего лишь пример. На самом деле мы вообще не в состоянии ничего посчитать! У вас на сайте есть счетчик уникальных посещений? Скорее всего, он считает приблизительно. Это и есть принципиальный подход к решению задачи о подсчете. Если точный ответ нам физически недоступен, нужно найти как можно более точный приблизительный ответ, который при этом использует минимальное количество памяти. Общее количество заходов на сайт, кстати, можно сосчитать и точно, потому что в этом случае не нужно запоминать каждое посещение, достаточно помнить, сколько их было. Число друзей на «Фейсбуке» тоже подсчитывается точно, потому что они не повторяются. Приблизительное решение понадобится для подсчета количества разных объектов, когда один и тот же объект может появиться несколько раз. Оговоримся, что в примере с кредитными картами проблему можно решить и по‑другому, с абсолютной точностью. Например, если выстроить все номера в порядке возрастания, то сосчитать разные номера будет гораздо проще. Очевидный недостаток состоит в том, что обычно к нам поступают неупорядоченные данные и их сортировка представляет собой отдельную, непростую задачу, которой посвящена масса математической литературы. Еще можно заранее создать такую структуру данных, где на каждого клиента было бы заведено электронное досье. Тогда совсем нетрудно пройтись по всем досье и посчитать, сколько из них содержит трансакции по кредитным картам. К каждому досье понадобится обратиться всего раз, и это много времени не займет. Но данный способ тоже работает не всегда. Например, как посчитать количество магазинов, в которых клиенты воспользовались кредитной картой? Наверняка у банка нет досье на каждый магазин. Проблема подсчета очень актуальна, особенно в контексте больших данных. Сколько посетителей заходит на наш сайт из разных регионов России? Сколько школьников в этом году подали заявления в вузы? Сколько людей обсуждают в социальных сетях нашу партию? Сотрудники Google в своей статье {20} пишут, что в их систему хранения и обработки данных поступает свыше пяти миллионов подобных запросов в день! Регулярно встречаются запросы, предполагающие подсчет более миллиарда объектов. В этой статье также приводится цифра: в среднем около ста таких запросов в день. Из‑за ограничений памяти получить точный ответ на подобный запрос абсолютно нереально. Как найти хорошее приближение, практически ничего не запоминая? У задачи подсчета есть несколько решений. Сходу такое решение нельзя придумать, но понять основные идеи не так уж сложно.
|
|||||||||
|
|
Последнее изменение этой страницы: 2021-01-14; просмотров: 111; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.191.44.23 (0.069 с.) |