Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Что такое оптимальное решение
Если вы недавно посещали Нидерланды, то последний раздел вас мог удивить. Железнодорожное движение далеко от совершенства. Мелкие (и крупные) задержки случаются сплошь и рядом. Пересадки порой очень короткие, их легко пропустить при малейшем опоздании. Поезда часто переполнены, особенно вагоны наиболее популярного 2‑го класса. Далеко не все обрадовались новому расписанию. Влиятельная голландская газета NRC Handelsblad писала:
Это единственная форма высшей математики, которая вызвала в обществе такую бурю эмоций.
Александр Схрейвер, знаменитый голландский математик, один из лучших в мире специалистов по оптимизации, играл ведущую роль в составлении нового расписания. Критика журналистов его не очень взволновала. В одной из статей, рассчитанной на широкую публику, он пишет:
Что определяет оптимальность? Комфорт пассажиров? Общий доход? Расписание персонала? Циркуляция материалов? Или пунктуальность? Каждый из этих аспектов сам по себе уже трудно оценить. Но даже если удастся, как взвесить эти факторы по отношению друг к другу?
Очень важно понимать, что оптимальное решение вовсе не означает решение идеальное. Оптимизация происходит с массой ограничений, и пожелания к решению противоречат друг другу. Например, максимальное количество пассажиров и дешевизна перевозок противоречат максимальному комфорту. Оптимальное решение – это лучшее, что мы можем сделать при заданных ограничениях и приоритетах. В реальных задачах необходимо, чтобы математики и менеджеры сотрудничали и прислушивались друг к другу. Менеджеры должны уметь расставить приоритеты и обозначить ограничения. Математики должны уметь не только запустить в ход свои многогранники, но и вникнуть в особенности данной задачи. И тогда мы получим новые красивые результаты, которые воплотятся в значительных проектах. Как написал авторам сам Схрейвер: «Это был масштабный проект, но за ним стояла очень интересная, чистая математика». А свою статью он закончил словами: «Математика железных дорог пока далека от совершенства». Приложения для подготовленного читателя к главе 2
Глава 3 Мир нулей и единиц
Перевод текста в килобайты
Как передаются тексты с одного компьютера на другой? Например, мы хотим переслать текст «Мама мыла раму» или «Над всей Испанией безоблачное небо». Как это сделать? Разумеется, по проводам нельзя передать напечатанные слова «мама», «небо» и другие. Можно передать только сигналы. Значит, каждой букве или слову нужно подобрать свой сигнал.
Как перевести слова в сигналы? Если подумать, то на ум приходит нечто вроде азбуки Морзе, когда все буквы и слова передаются в виде точек и тире. Совершенно аналогично компьютеры пользуются всего двумя сигналами. Поэтому вся информация в компьютере записывается посредством двух символов: 0 и 1. Понятно, что мы только для примера написали фразы по‑русски. А вдруг завтра нам понадобится передать сообщение на английском или французском, где совсем другие (латинские) буквы, не говоря уже о разных «акцентах», характерных для французского языка? А еще есть арабские буквы, несколько витиеватых алфавитов Индии и тысячи, если не десятки тысяч, китайских и японских иероглифов! Обучить компьютер отличать один язык от другого – не проблема, такие программы уже есть. Но для хранения и передачи информации это совершенно бесперспективно. Гораздо проще для каждого символа, будь то буквы, иероглифы или знаки препинания, составить свою, уникальную, последовательность из нулей и единиц. К этому можно добавить отдельные последовательности для часто употребляемых слов, особенно если их не слишком много. Конечно, можно построить компьютеры, которые будут различать три разных сигнала или больше. Но двоичная система (два сигнала, два символа) гораздо удобнее. Ток либо есть (1), либо нет (0) здесь машина не может ошибиться. Поэтому устройства с двоичной системой проще в изготовлении и надежнее. Все наши компьютеры устроены именно так. Мы печатаем тексты на всех языках мира, рисуем таблички и сохраняем фотографии, а в памяти компьютера нет ничего, кроме нулей и единиц. На самом деле это поразительно! Соответственно, объем информации в компьютере определяется тем, сколько нулей и единиц нам понадобилось. Каждый ноль или единица представляют собой минимальный объем информации, так называемый один бит. Восемь битов, то есть последовательность из восьми нулей и единиц, называется один байт. Всем известный килобайт (Кбайт), та самая единица измерения объема наших имейлов и документов, равен 1024 байта, или 8192 нуля и единицы. Аналогично мегабайт – это 1024 килобайта.
Почему 1024, а не просто 1000? Потому что в двоичной системе, где всего две цифры, проще всего пользоваться степенями двойки: 2, 4, 8, 16, 32 и так далее. Вполне логично, что в привычной нам десятичной системе, где у нас 10 цифр от 0 до 9, удобно пользоваться степенями десятки: 10, 100, 1000 и так далее. Число 1024 – это два в десятой степени:
1024=210=2×2×2×2×2×2×2×2×2×2
Многие считают, что килобайт – это тысяча байтов. Строго говоря, это не так, но приблизительно верно и больше соответствует нашей привычке считать десятками, сотнями и тысячами. Сколько килобайтов в вашем сообщении, зависит не только от самого текста, но и от того, каким образом ваши слова были переведены в нули и единицы. Как сделать сообщение компактным? Где гарантия, что замена нескольких нулей на единицы из‑за помех в каналах связи не изменит смысл на полностью противоположный? Проблемы передачи информации послужили толчком для развития целой области современной математики – теории кодирования.
Что такое кодирование
Итак, наша цель – закодировать каждый символ или каждое слово текста с помощью нулей и единиц. Фактически код – это словарь, состоящий из кодовых слов. Каждое кодовое слово представляет собой последовательность нулей и единиц (желательно небольшой длины), которая что‑то означает (буква, цифра, знак препинания или целое слово). Построить код можно множеством разных способов, а значит, эта задача очень интересная. Давайте, к примеру, закодируем отдельно каждую букву русского алфавита. Забавно, кстати, что, когда ставишь эту задачу студентам, почти всегда кто‑нибудь спрашивает, сколько букв надо учитывать: 32 или 33. По‑видимому, они считают букву «ё» не вполне самостоятельной, потому что в текстах ее обычно меняют на «е». Будем все‑таки считать, что букв у нас 33. Сколько байтов (нулей и единиц) нам понадобится, чтобы закодировать 33 буквы? Совершенно ясно, что тридцати трех байтов вполне достаточно, потому что мы можем каждую букву обозначить кодом из 32 нулей и одной единицы – на той позиции, которую занимает эта буква в алфавите. Такой наивный код будет выглядеть так:
а: 100000000000000000000000000000000 б: 010000000000000000000000000000000 в: 001000000000000000000000000000000 г: 000100000000000000000000000000000
и так далее
я: 000000000000000000000000000000001
Сразу видно, что подобное кодирование неприменимо на практике. Слишком много драгоценных байтов уходит на нули, которые несут очень мало информации. Какая минимальная длина кода нам понадобится, чтобы закодировать русский алфавит? Скажем, хватит ли нам кодов длины 5? Это зависит от того, сколько разных последовательностей из нулей и единиц длины 5 мы можем составить: 00000, 00001, 00010, 00011 и далее до 11111. Всего 32 такие последовательности. Получить данный ответ довольно просто: это 2 в степени 5, то есть 2 × 2 × 2 × 2 × 2[5]. Оказывается, последовательностей длины 5 не хватает, так что вопрос студентов попал в самую точку! Всего из‑за одной «лишней» буквы нам понадобится как минимум 6 нулей и единиц в каждом «кодовом слове».
Интересно, что добавление всего одной позиции кода очень сильно меняет дело. Для русского алфавита нам нужны последовательности длины 6, а их уже 64. Значит, нам их хватит не только на русский алфавит, но и, например, на латинский из 26 букв, и в запасе еще останется пять свободных последовательностей для знаков препинания. Ключевой вывод: добавление всего одной позиции кода увеличивает количество разных последовательностей вдвое. Потому что лишнюю позицию можно заполнить двумя способами – либо нулем, либо единицей. В результате количество букв, слов или сообщений, которые мы можем закодировать, возрастает с длиной кода по так называемому экспоненциальному закону, как степень двойки. «Растет по экспоненциальному закону» на общедоступном языке означает «растет очень быстро»! Помните легенду о том, как король хотел наградить изобретателя шахмат? Умный изобретатель попросил короля положить на первую клетку доски одно зернышко, на вторую – два, на третью – четыре и далее в том же порядке: в два раза больше на каждую следующую клетку. Король согласился и был потрясен, когда зерна в его амбарах не хватило и на половину доски. Точно так же и количество возможных последовательностей из нулей и единиц возрастает очень быстро с их длиной: 2, 4, 8, 16, 32, 64, 128, 256, 512, 1024… Экспоненциальная зависимость между количеством разных кодовых слов и их длиной – абсолютно фундаментальная концепция в информатике и вопросах передачи информации. Заметим, что количество информации зависит не только от длины кода в килобайтах, но и от того, насколько информативны кодируемые слова. Естественная иллюстрация – это отправка сообщения по телеграфу. Там каждое слово стоит денег, и люди стараются не использовать лишних слов, избегая союзов и предлогов, потому что они менее информативны, чем глаголы и существительные. Основные концепции о том, как измерить количество информации, изложены в фундаментальной работе Клода Шэннона, опубликованной в 1949 году {5}. Эти концепции во многих отношениях положили начало развитию информатики и строятся все на той же основополагающей экспоненциальной зависимости. Однако мы не будем углубляться в теорию информации, а вернемся к вопросу о том, как составить надежные и эффективные коды.
Коды, исправляющие ошибки
Как вы уже поняли, код – это просто любой набор последовательностей из нулей и единиц. Но не все коды одинаково хороши. Разумеется, неплохо, если каждое кодовое слово достаточно короткое. Об этом мы как раз говорили в прошлом разделе. Однако есть куда более интересные характеристики кода, нежели длина кодовых слов. Представим, что мы начали передавать кодовые слова по каналу связи, но в нем иногда возникают помехи. Из‑за каждой такой помехи передаваемый символ меняется на противоположный: ноль – на единицу, единица – на ноль. Можно ли подобрать кодовые слова так, чтобы все передаваемые символы, несмотря на ошибки, удалось однозначно восстановить? Звучит как научная фантастика! Но оказывается, можно! Достаточно лишь правильно сформулировать соответствующую математическую задачу. Допустим, наши кодовые слова длины 6 и на каждое кодовое слово приходится не более одной ошибки. Поскольку это простой пример, представим, что наш словарный запас беднее, чем у Эллочки‑людоедки из «Двенадцати стульев», и состоит всего из трех слов, которые мы закодировали тремя кодовыми словами:
111000, 001110, 100011.
Конечно, много таким кодом не передашь, но для примера вполне достаточно. Еще важно, что получатель знает наш «словарь», то есть ожидает от нас либо 111000, либо 001110, либо 100011 и ничего другого. Предположим, мы сначала передаем слово 111000. В результате не более чем одной ошибки (ошибки мы выделили жирным шрифтом) оно может превратиться в одно из слов:
111000, 011000, 101000, 110000, 111100, 111010, 111001, (3.1)
включая, как видите, само себя. Аналогично при передаче слова 001110 может получиться любое из слов:
001110, 101110, 011110, 000110, 001010, 001100, 001111. (3.2)
Наконец, для 100011 у нас выйдет:
100011, 000011, 110011, 101011, 100111, 100001, 100010. (3.3)
Замечательно то, что списки (3.1) (3.3) попарно не пересекаются. Иными словами, если на другом конце канала связи появляется любое слово из списка (3.1), получатель точно знает, что ему передавали именно слово 111000, а если появляется любое слово из списка (3.2) слово 001110; то же самое касается и списка (3.3). В этом случае говорят, что наш код исправил одну ошибку. За счет чего произошло исправление? За счет двух факторов. Во‑первых, получатель знал весь «словарь». Когда код передавался всего с одной ошибкой, выходило слово, которого в словаре не было. Во‑вторых, слова в словаре были подобраны особенным образом. Даже при возникновении ошибки получатель не мог перепутать одно слово с другим. Например, если словарь состоит из слов «дочка», «точка», «кочка» и при передаче получалось «вочка», то получатель, зная, что такого слова не бывает, исправить ошибку не смог бы – любое из трех слов может оказаться правильным. Если же в словарь входят «точка», «галка», «ветка» и нам известно, что допускается не больше одной ошибки, то «вочка» это заведомо «точка», а не «галка». В кодах, исправляющих ошибки, слова выбираются именно так, чтобы они были «узнаваемы» даже после ошибки. Разница лишь в том, что в кодовом «алфавите» всего две буквы – ноль и единица.
Совершенно ясно, что наугад такие коды составить невозможно. За этим стоит целый математический аппарат. Нам нужно научиться измерять расстояния между словами и даже работать с шарами из слов. Что это такое и как это делается, может понять практически любой человек. Ниже мы попробуем объяснить, как создаются коды, исправляющие ошибки, и какие при этом возникают проблемы.
Шары Хэмминга
Математики уже давно договорились, что такое шар. Шар состоит из всех точек, которые удалены от центра не больше чем на какое‑то заданное расстояние, обозначаемое буквой r, – радиус. В нашем привычном трехмерном пространстве, где расстояния измеряются в метрах, это обычный шар, как на рис. 3.1.
Рис. 3.1. Шар радиуса r в трехмерном пространстве. Все точки удалены от центра не больше чем на расстояние r
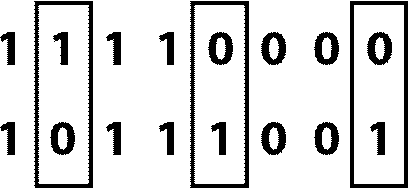
Зато понятия точка и расстояние в математике абсолютно абстрактные. Есть несколько простых правил, которых следует строго придерживаться, но в рамках этих правил – полная свобода. Точками могут быть сигналы, а могут – кривые и даже результаты случайных экспериментов. И расстояния между ними можно определить самыми разными способами. В итоге получаются «шары», не поддающиеся воображению. Тем не менее эти абстрактные шары играют в математике очень большую роль. В теории кодирования точка – это кодовое слово, то есть последовательность нулей и единиц заданной длины. А расстоянием принято считать так называемое расстояние Хэмминга. Расстояние Хэмминга между двумя кодовыми словами – это всего‑навсего число позиций, на которых у этих слов стоят разные символы: у одного 0, а у другого 1. Например, на рис. 3.2 расстояние Хэмминга между двумя кодовыми словами равно трем. Мы заключили в рамки те позиции, где эти два кодовых слова отличаются друг от друга.
Рис. 3.2. Расстояние Хэмминга между двумя кодовыми словами – число позиций, на которых у этих слов стоят разные символы. На рисунке это расстояние равно трем. Позиции, где два кодовых слова отличаются друг от друга, заключены в рамки
Что происходит, если при передаче, скажем, слова 111000 произошла одна ошибка? Получится другое слово, которое будет отличаться от 111000 всего на одной позиции. Иначе говоря, если у нас при передаче происходит не больше одной ошибки, расстояние Хэмминга между отправленным и полученным кодовым словом будет не больше единицы. Давайте снова посмотрим на перечень (3.1) предыдущего раздела:
111000, 011000, 101000, 110000, 111100, 111010, 111001.
Расстояние Хэмминга между словом 111000 и любым другим словом из перечня не превосходит 1. Значит, этот список – не что иное, как шар радиуса 1 с центром 111000! Кстати, подобное определение можно ввести и для обычных слов русского языка одинаковой длины. Например, расстояние Хэмминга между словами «дочка» и «точка» равно единице, а между словами «точка» и «галка» – трем. Если слово «точка» – это центр шара Хэмминга радиуса 1, то слово «дочка» входит в этот шар, а слово «галка» – нет. Шары Хэмминга очень трудно себе представить даже для маленьких кодов. На рис. 3.3 мы изобразили расстояния Хэмминга между кодовыми словами длины 3. Расстояния Хэмминга могут быть 0, 1, 2 или 3. На рисунке чем темнее цвет, тем больше расстояние. Если взять, например, колонку 000, то шар Хэмминга радиуса 1 – это все белые и светло‑серые квадратики в этой колонке: 000, 001, 010, 100. Сразу видно, что расположение белых и, скажем, самых темных квадратиков в колонках неодинаковое, хотя, конечно, в рисунке много закономерностей. Например, рисунок из самых светлых тонов (белый и светло‑серый) абсолютно симметричен рисунку из двух оставшихся более темных тонов.
Рис. 3.3. Расстояние Хэмминга между кодовыми словами длины 3. Справа изображен цветовой код. Расстояния: 0, 1, 2, 3. Чем темнее цвет, тем больше расстояние
Кодовые слова длины 3 – очень простой пример, их всего восемь. Стоит чуть увеличить длину кодового слова, и из‑за уже знакомого нам экспоненциального закона слов станет так много, что картинка нам не поможет. Профессор Джон Слэни из Австралийского национального университета сделал замечательный рисунок, на котором изображены расстояния Хэмминга между кодовыми словами длины 8, а это всего один байт. Таких слов 256. Советуем заглянуть на веб‑страницу Слэни http://users.cecs.anu.edu.au/~jks/Hamming.html и посмотреть на этот рисунок. Вам сразу станет понятно, что он никак не поможет найти хороший код. Картинка скорее напоминает красивый коврик. Нам нужен другой математический аппарат, и, к счастью, такой аппарат есть. Теория кодирования тесно связана с комбинаторикой – наукой о комбинациях тех или иных объектов. Возможно, вы уже заметили связь между шарами Хэмминга и кодами, исправляющими ошибки. Допустим, мы передаем кодовые слова длины 10 и хотим, чтобы код исправлял две ошибки. Тогда надо построить код, в котором шары с центрами в кодовых словах и радиусами 2 попарно не пересекались бы. Все последовательности нулей и единиц в таком шаре будут означать одно и то же кодовое слово. Иначе говоря, кодовые слова должны отличаться друг от друга настолько, чтобы при наличии двух ошибок их невозможно было перепутать. На языке математики это значит, что расстояния Хэмминга между кодовыми словами должны быть как минимум равны 5. При создании кодов возникает немало интересных вопросов. Например, очень важно, чтобы количество кодовых слов было как можно б о льшим, так как это позволит передать по каналу связи больше информации, исправляя при этом заданное наперед количество ошибок (характерное для данного канала связи). Отыскание максимальных кодов при заданной длине кодового слова и количестве ошибок – крайне трудная и не до конца решенная математическая задача. По сути, это задача комбинаторики, хотя и мотивированная совершенно практическими вопросами кодирования информации.
|
|||||||||
|
|
Последнее изменение этой страницы: 2021-01-14; просмотров: 86; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.145.47.253 (0.056 с.) |