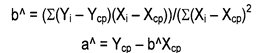Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Назначение простой линейной регрессииСтр 1 из 4Следующая ⇒
Содержание 5.1. Простая линейная регрессия. 1 5.1.1. Назначение простой линейной регрессии.. 1 5.1.2. Вызов процедуры.. 2 5.1.3. Установка параметров. 2 5.1.4. Вид результатов. 4 5.2. Простая множественная регрессия. 5 5.2.1. Назначение простой множественной регрессии.. 5 Наиболее распространенный метод решения - Метод наименьших квадратов (МНК) получения коэффициентов модели 5 5.2.2. Отбор переменных во множественной регрессии.. 5 5.2.2.1. Назначение отбора переменных. 5 5.2.2.2. Метод пошагового исключения (backward elimination) 5 5.2.2.3. Метод пошагового включения (forward selection) 5 5.2.2.4. Метод пошагового отбора (stepwise selection) 6 5.2.2.5. "Оптимальное" число независимых переменных. 6 5.2.3. Вид результатов расчета множественной линейной регрессии.. 7 5.3. Нелинейная регрессия. 9 5.3.1. Подгонка кривых. 9 5.3.2. Использование фиктивных переменных. 13 5.3.2.1. Модели нелинейные по переменным.. 13 5.3.2.2. Модели нелинейные по параметрам.. 13 5.4. Анализ остатков. 14 5.4.1. Назначение анализа остатков. 14 5.4.2. Понятие остатков. 14 5.4. 3. Проверка линейности.. 15 5.4.3.1. График остатков по экспериментальным значениям У.. 15 5.4.3.3. График остатков по независимой переменной. 15 5.4.4. Однородность дисперсий.. 15 5.4.5. Независимость ошибок.. 15 5.4.6. Нормальность остатков. 15 5.4.6.1. Построение гистограммы остатков. 16 5.4.6.2. Построения графика остатков на нормальной вероятностной бумаге. 16 5.4.7. Выявление выбросов. 16 5.4.7.1. Проверка на выбросы зависимой переменной. 16 5.4.7.2. Проверка на выбросы независимой переменной. 16 5.4.8. Выявление существенных наблюдений.. 16 5.4.8.1. Включение и исключение подозрительного наблюдения. 16 5.4.8.2. Вычисление расстояния Кука. 17 5.4.9. Некоррелированность независимых переменных. 17 5.4.9.1. Вычисление фактора "вздутия" вариации. 17 5.4.9.2. Вычисление собственных чисел. 17
Простая линейная регрессия
Вызов процедуры Для вызова процедуры линейной регрессии необходимо выполнить следующую последовательность действий: в командной строке окна ввода данных открыть меню Analyze, далее подменю Regression и затем Linear.
Установка параметров
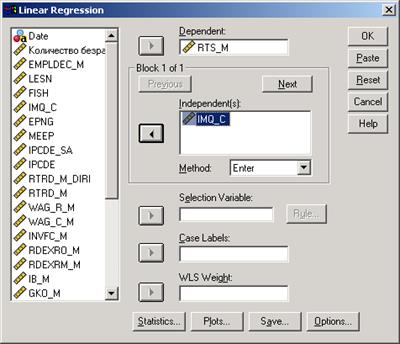
После вызова процедуры появится диалоговое окно Linear Regression (рис.5-2):
Рис.5- 2. Вид диалогового окна Linear Regression
1.В строку Dependent должна быть занесена зависимая переменная (yi) в строку Independent - независимая.
2. Независимые переменные могут задаваться двумя способами: блоками и путем выбора метода (меню Method) формирования группы. В списке Method имеются следующие возможности: · Enter - простейший способ - все данные формируются в единую группу. · Remove - это метод, который позволяет отбрасывать переменные в процессе определения конечной модели. · Stepwise - это метод, который позволяет добавлять и удалять отдельные переменные в соответствии с параметрами, установленными в окне Options. · Backward - данный метод позволяет последовательно удалять переменные из модели в соответствии с параметрами в окне Options, до того момента, пока это возможно (например по критерию значимости). · Forward - данный метод позволяет последовательно добавлять переменные в модель в соответствии с параметрами в окне Options, до того момента, пока это возможно.
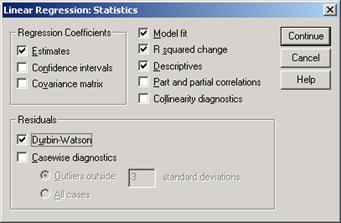
Рассмотрим другие клавиши диалогового окна: WLS - взвешенный метод наименьших квадратов - присваивает наблюдениям различные веса, чтобы компенсировать различную точность измерений. Statistics - параметры вывода (диалоговое окно представлено на рис 5-3).
Рис.5-3. Вид диалогового окна Statistics
В диалоговом окне Statistics имеются следующие возможности:
· Estimates - выводит непосредственно оценки коэффициентов. · Confidence intervals - доверительный интервал для коэффициентов (уровень значимости) · Covariance matrix - выводит ковариационную матрицу оценок коэффициентов. · Model fit - включает множественный R, R-квадрат, нормированный R-квадрат, стандартную ошибку оценки и таблицу анализа дисперсии (TSS, RSS). · R squared change - включает R, R-квадрат, F-статистику и их изменения при добавлении-удалении переменных. · Descriptives – выдается число наблюдений без пропущенных значений, среднее значение и стандартное отклонение для каждой анализируемой переменной. Также выводится корреляционная матрица с односторонним уровнем значимости и число наблюдений для каждой корреляции. · Part and partial correlations - выдаются корреляции нулевого порядка (те. Обычные парные), частные и частичные корреляции. · Collinearity diagnostics – выдаются собственные значения масштабированной и нецентрированной матрицы сумм перекрестных произведений, числа обусловленности, доли в разложении дисперсии, коэффициенты разбухания дисперсии (VIF – variance inflation factor), толерантности для отдельных переменных.
· Durbin- Watson - тест для выявления автокорреляции. Если DW больше 2 -отрицательная автокорреляция, меньше 2 - положительная.
Plots - графическая иллюстрация. При ее активизации выводится диалоговое окно (рис.5-4). В диалоговом окне Plots имеются возможности: Типы переменных: · DEPENDNT - зависимая переменная; · ZPRED - предсказываемые значения зависимой переменной (экстраполяция). Может быть стандартизирована с математическим ожиданием 0 и стандартным отклонением 1; · ZRESID - отклонение: е i=У i- Y^; · DRESID - исключенные остатки (разности); · ADJPRED - нормированные предсказанные значения; · SRESID - остатки, стандартизованные на оценку их стандартного отклонения. Produce all partial plots - строит точечную диаграмму остатков независимых переменных.
Рис.5-4. Вид диалогового окна Plots
Save - каждый пункт добавляет одну или более переменных в файл данных Predicted Values · Standardized - экстраполирование зависимой переменной; · Adjusted - экстраполирование для случая, который выбрасывается при вычислении коэффициентов регрессии; · S. E. of mean pred. value - оценка стандартного отклонения среднего значения зависимой переменной для случая, когда независимые переменные имеют такие же значения Residuals; · Unstandardized - отклонение: е i = Yi - Y^; · Deleted - исключенные остатки (разности).
Options - настройка для пошагового метода: · Use probability of F - уровень значимости (для ввода должен быть меньше, чнм для удаления); · Use P value - использование Р-значений; · Exclude cases listwise - использование только тех ячеек, которые содержат верные (корректные) значения; · Exclude cases painwise - рассчитывает каждый коэффициент корреляции, используя все ячейки с корректными значениями; · Replace with mean - замещает недостающее значение средним значением переменной.
Вид результатов
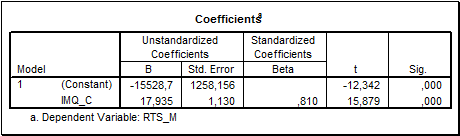
Результаты расчета линейной регрессии представлены большим количеством таблиц. Приведем самые основные из них. На рис. 5-5 представлена таблица суммарных характеристик. В ней нужно обратить внимание на R, R square, F Change, Sig. F Change, Durbin-Watson. Из рис.5-5 следует, что рассчитанная модель адекватна, коэффициент корреляции очень высок, в остатках сериальная составляющая (Durbin-Watson) отсутствует. На рис.5-6 проиллюстрирована таблица коэффициентов регрессии. Из нее следует, что полученные коэффициенты статистически значимы t- критерий и Sig. Показатель IMQ влияет на индекс РТС положительно.
Рис.5-5. Суммарные характеристики модели
Рис.5-6. Таблица коэффициентов регрессии
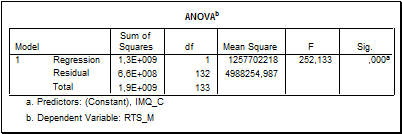
Таблица дисперсионного анализа (рис.5-7) показывает, что модель адекватна (F и Sig).
Рис.5-7. Дисперсионный анализ модели
Нелинейная регрессия
Регрессия, парная или множественная, совсем не обязательно должна быть линейной. Существует много других, нелинейных, форм для ее выражения. В SPSS для формирования нелинейной регрессии предусмотрены следующие технологии: · подгонка кривых; · использование фиктивных переменных, · собственно нелинейная регрессия. Кроме того, предусмотрены методы расчета специфических форм регрессии.
Подгонка кривых
Подгонка кривых предназначена, в первую очередь, для вычисления парной нелинейной регрессии. Косвенно, с некоторыми усложнениями, она может быть использована и для расчета множественной нелинейной регрессии. Эта процедура позволяет вычислять статистики и строить графики для различных типовых регрессионных моделей. Можно также сохранять предсказанные значения, остатки и интервалы прогнозирования в виде новых переменных. Предлагаемые модели соответствуют следующим типам (выражаемым посредством формул) - см. табл. 5.1. Таблица 5.1 Типы моделей
Требования к данным: · зависимые и независимые переменные должны быть количественными; · если в качестве независимой переменной выбрано Время, а не переменная из исходного файла данных, зависимая переменная должна представлять собой временной ряд. Исходные допущения: · остатки должны представлять собой случайные величины и распределяться по нормальному закону. При использовании линейной модели предъявляются такие же требования, как и для обычной линейной регрессии. Прежде чем запустить выполнение процедуры, полезно ознакомиться с расположением исходных точек на графике, чтобы определить наиболее подходящие кривые. Хотя, это не обязательно. Выполним последовательность команд Chart/ Legacy Dialogs (рис.5-14).Вокне Scatter/ Dot (рис. 5-15) установим флажок в ячейке Простая. Затем в следующем диалоговом окне Диаграмма рассеяния (рис. 5-16) укажем показатели для осей графика.
Рис.5-14. Выбор команд просмотр графика рассеяния
Рис.5-15. Уточнение типа графика
Рис.1-16. Установка параметров графика
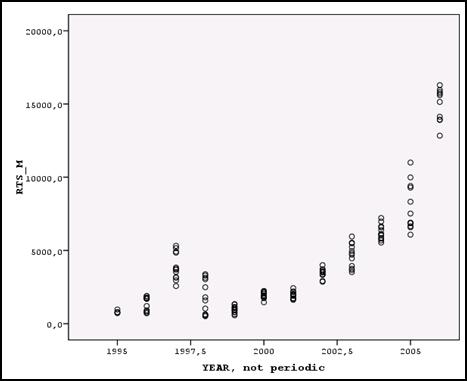
Рис.5-17. Облако исходных точек по годам
В результате получим облако рассеяния исходных точек (рис. 5-17). Предполагаем, что наилучшее приближение к этому облаку может обеспечить одна из следующих моделей: логарифмическая, квадратичная, кубическая, гиперболическая. Теперь обратимся к процедуре подгонка кривых, для чего выполним последовательность команд Анализ >• Регрессия >■ Подгонка кривых (рис.5-18).
Рис.5-18. Выбор команд по подбору кривых
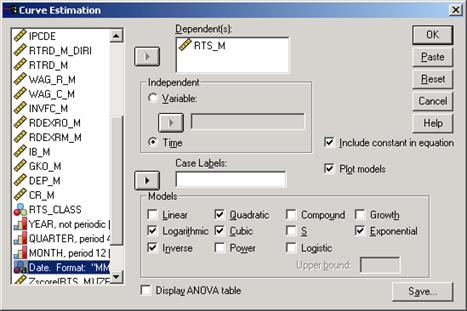
В окне Подгонка кривых (рис. 5-19) активизируем отобранные модели. Кроме того, установим флажки в ячейках Включать константу (в формуле для каждой модели), Графики моделей (для вывода графических зависимостей), Вывести таблицу дисперсионного анализа (для фиксации оценок качества регрессии). В результате получатся графики отобранных функций и, дополнительно, график аппроксимации наблюденных значений.
Рис. 5-19. Окно Подгонка кривых
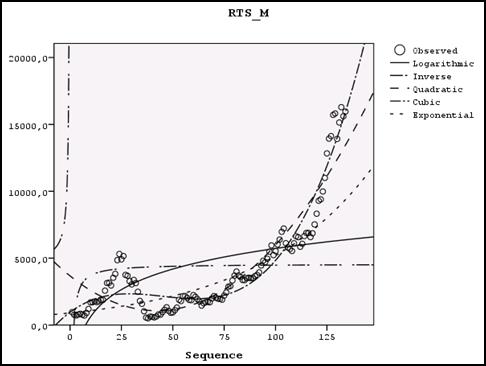
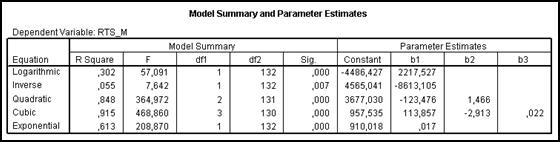
Сравнение всех этих кривых (рис.5-20) показывает, что наилучшее приближение к множеству исходных точек дает кубическая модель: Индекс РТС = b0+ b1(Время) + b2*(Время)^2 + b3*(Время)^3. Оснований для такого утверждения два: · это видно из подобия кривых кубической модели и реальных значений (рис. 5-20); · данный вывод подтверждается результатами дисперсионного анализа для кубической модели (рис. 5-21), согласно которым R2 = 0,915, F=468,860, что говорит о хорошем приближении. Данный анализ проводится для каждой из сравниваемых моделей, и для кубической модели значения являются наибольшими.
Параметры кубической модели: b0=957,535; b1=113,857; b2=-2,913; b3=0,022.
Рис.5-20. Графики подогнанных кривых и исходные точки
Рис.5-21. Суммарные характеристики моделей
Анализ остатков
Назначение анализа остатков
Как правило, заранее неизвестно удовлетворяют ли исходные данные предположениям, лежащим в условиях применения метода МНК для нахождения неизвестных коэффициентов модели. Следовательно, необходимо произвести дополнительные исследования, сосредоточившись на остатках, для поиска доказательств того, что необходимые предположения не нарушены.
Понятие остатков
Остатки - это разность между наблюденным значением и значением, предсказанным моделью: ei = Yi – b0 – b1 Xi = Yi - Y ` В регрессионном анализе предполагается, что истинные ошибки еi являются независимыми нормально распределенными случайными величинами со средним 0 и постоянной дисперсией σ2. Если в уравнение включен свободный член, среднее значение остатков всегда равно нулю, так что среднее остатков не дает никакой информации относительно истинного среднего ошибок. Поскольку сумма остатков должна равняться нулю, они не являются независимыми. Однако, если число остатков достаточно велико по сравнению с количеством независимых переменных, то на практике этой зависимостью можно пренебречь. Нормированные остатки. Об относительной величине остатков легче судить, когда они поделены на оценки своих стандартных отклонений. Рассчитанные в результатенормированные остатки, выражены в единицах стандартных отклонений в обе стороны от среднего значения. Например, то, что данный остаток равен -5198.1, не содержит достаточной информации. Однако, если вы знаете, что будучи пронормированным, он становится равным -3.1, то вам становится известным не только то, что наблюденное значение меньше предсказанного, но также и то, что данный остаток больше по абсолютной величине трех σ.
Имеются и другие способы корректировки остатков: · Нормированный остаток для j-того наблюдения — это остаток, деленный на выборочное стандартное отклонение. Нормированные остатки имеют нулевое среднее значение и единичное стандартное отклонение. · Стьюдентизированный остаток — это остаток, деленный на оценку своего стандартного отклонения, меняющегося от одного наблюдения к другому, в зависимости от расстояния между X i и средним значением X. Значения нормированных и стьюдентизированных остатков, как правило, близки, хотя это и не всегда так. Стьюдентизированные остатки точнее отражают различия в дисперсиях истинных ошибок для разных наблюдений.
Проверка линейности
Проверку линейности модели можно выполнить двумя способами. Однородность дисперсий Ранее описанные диаграммы можно использовать и для проверки предположения о равенстве дисперсий. Если разброс остатков увеличивается или уменьшается в зависимости от значений независимых переменных Х или значений У, то предположение о постоянстве дисперсии У для всех значений Х становится необоснованным.
Независимость ошибок
Если данные собирались и записывались последовательно (например, во времени), всегда необходимо вывести на график остатки по переменной, отражающей такую последовательность. Даже тогда, когда время не включено в рассматриваемую модель, оно может оказывать влияние на остатки. Если последовательность следования исходных данных и остатки будут независимы, мы не увидим на графике различимого криволинейного тренда. Кроме графика при построения модели вычисляется статистика критерия Дурбина-Уотсона, формулой которой для сериальной корреляции остатков имеет вид:
Значение этой статистики меняется от 0 до 4. Если остатки взаимно не коррелированны, значение d близко к 2. Вычисленное значение критерия сравнивают с табличным: · если d<dL, то делается вывод о наличии в остатках автокорреляции. В этом случае необходима корректировка модели путем введения в нее дополнительного члена, учитывающего автокорреляцию; · если d>dU, то ряд не содержит автокорреляции; · если dL<d>dU, то необходимы дальнейшие исследования; где dL и dU – нижняя и верхняя граница критерия (берется из таблиц).
Нормальность остатков Причинами ненормальности остатков могут послужить неверное задание параметров модели, непостоянная дисперсия (неоднородность дисперсии), небольшое число доступных для анализа остатков и т.д. Следовательно, необходимо изучать этот вопрос одновременно при помощи разных методов. Выявление выбросов
Нетипичными данными, появляющиеся по причине ошибок измерения или другим могут быть значения результирующей (зависимой) переменной У или независимой переменной Х. Вычисление расстояния Кука
Существует также общая мера, которая позволяет судить, как изменятся все расчетные значения зависимой переменной при исключении одного наблюдения. Эта мера называется расстоянием Кука (Cook's distance) и рассчитывается как нормированная сумма исключенных остатков:
где в числителе суммируются квадраты стандартизованных исключенных остатков, если исключено наблюдение i, а в знаменателе число степеней свободы умножается на стандартную ошибку уравнения.
Содержание 5.1. Простая линейная регрессия. 1 5.1.1. Назначение простой линейной регрессии.. 1 5.1.2. Вызов процедуры.. 2 5.1.3. Установка параметров. 2 5.1.4. Вид результатов. 4 5.2. Простая множественная регрессия. 5 5.2.1. Назначение простой множественной регрессии.. 5 Наиболее распространенный метод решения - Метод наименьших квадратов (МНК) получения коэффициентов модели 5 5.2.2. Отбор переменных во множественной регрессии.. 5 5.2.2.1. Назначение отбора переменных. 5 5.2.2.2. Метод пошагового исключения (backward elimination) 5 5.2.2.3. Метод пошагового включения (forward selection) 5 5.2.2.4. Метод пошагового отбора (stepwise selection) 6 5.2.2.5. "Оптимальное" число независимых переменных. 6 5.2.3. Вид результатов расчета множественной линейной регрессии.. 7 5.3. Нелинейная регрессия. 9 5.3.1. Подгонка кривых. 9 5.3.2. Использование фиктивных переменных. 13 5.3.2.1. Модели нелинейные по переменным.. 13 5.3.2.2. Модели нелинейные по параметрам.. 13 5.4. Анализ остатков. 14 5.4.1. Назначение анализа остатков. 14 5.4.2. Понятие остатков. 14 5.4. 3. Проверка линейности.. 15 5.4.3.1. График остатков по экспериментальным значениям У.. 15 5.4.3.3. График остатков по независимой переменной. 15 5.4.4. Однородность дисперсий.. 15 5.4.5. Независимость ошибок.. 15 5.4.6. Нормальность остатков. 15 5.4.6.1. Построение гистограммы остатков. 16 5.4.6.2. Построения графика остатков на нормальной вероятностной бумаге. 16 5.4.7. Выявление выбросов. 16 5.4.7.1. Проверка на выбросы зависимой переменной. 16 5.4.7.2. Проверка на выбросы независимой переменной. 16 5.4.8. Выявление существенных наблюдений.. 16 5.4.8.1. Включение и исключение подозрительного наблюдения. 16 5.4.8.2. Вычисление расстояния Кука. 17 5.4.9. Некоррелированность независимых переменных. 17 5.4.9.1. Вычисление фактора "вздутия" вариации. 17 5.4.9.2. Вычисление собственных чисел. 17
Простая линейная регрессия
Назначение простой линейной регрессии
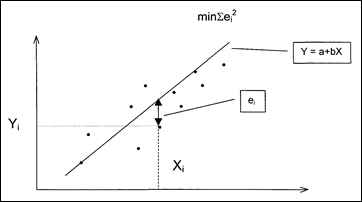
Основная цель построения регрессии - это стремление, используя некий набор «наблюдений», получить количественные и качественные зависимости для различных соотношений. Очевидно, что мы не можем просчитать влияние абсолютно всех факторов - мы осознанно упрощаем действительность, строя модель. Таким образом, мы работаем уже с некоторой эконометрической моделью, которая выражается в достаточно простой математической форме. Отличительной особенностью эконометрической модели будет являться наличие случайной (стохастической) составляющей (ei), учитывающей возможные ошибки при сборе данных, построении выборки и ее обработки. Простейшей эконометрической моделью является простая линейная регрессия, имеющая вид: Yj = а + bXi + ei, где Yj - является зависимой переменной; Xi - регрессором (объясняющей переменной); а и b – коэффициенты; е i - случайная составляющая. Для нахождения неизвестных коэффициентов SPSS использует метод наименьших квадратов (МНК). Введем основные предпосылки: 1. Yj = а + bXi + е i - спецификация модели. 2. X i -детерминированная величина. 3. ∑(е i)=0 4. Var(ei)= cr 2 5. ∑ (еi, ej) = 0, при i≠j - некоррелированность ошибок для разных наблюдений.
Суть метода заключается в следующем. У нас есть набор наблюдений Yi, Xi и требуется подобрать функцию Y = f(X), наилучшим образом описывающую зависимость у от х (рис.5-1). Фактически задача сводится к наилучшему подбору коэффициентов с тем, чтобы сумма квадратов отклонений была минимальной.
Рис.5-1. Графическая интерпретация простой линейной регрессии Решая стандартную задачу минимизации, получаем, что
Вызов процедуры Для вызова процедуры линейной регрессии необходимо выполнить следующую последовательность действий: в командной строке окна ввода данных открыть меню Analyze, далее подменю Regression и затем Linear.
Установка параметров
После вызова процедуры появится диалоговое окно Linear Regression (рис.5-2):
Рис.5- 2. Вид диалогового окна Linear Regression
1.В строку Dependent должна быть занесена зависимая переменная (yi) в строку Independent - независимая. 2. Независимые переменные могут задаваться двумя способами: блоками и путем выбора метода (меню Method) формирования группы. В списке Method имеются следующие возможности: · Enter - простейший способ - все данные формируются в единую группу. · Remove - это метод, который позволяет отбрасывать переменные в процессе определения конечной модели. · Stepwise - это метод, который позволяет добавлять и удалять отдельные переменные в соответствии с параметрами, установленными в окне Options. · Backward - данный метод позволяет последовательно удалять переменные из модели в соответствии с параметрами в окне Options, до того момента, пока это возможно (например по критерию значимости). · Forward - данный метод позволяет последовательно добавлять переменные в модель в соответствии с параметрами в окне Options, до того момента, пока это возможно.
Рассмотрим другие клавиши диалогового окна: WLS - взвешенный метод наименьших квадратов - присваивает наблюдениям различные веса, чтобы компенсировать различную точность измерений. Statistics - параметры вывода (диалоговое окно представлено на рис 5-3).
Рис.5-3. Вид диалогового окна Statistics
В диалоговом окне Statistics имеются следующие возможности:
· Estimates - выводит непосредственно оценки коэффициентов. · Confidence intervals - доверительный интервал для коэффициентов (уровень значимости) · Covariance matrix - выводит ковариационную матрицу оценок коэффициентов. · Model fit - включает множественный R, R-квадрат, нормированный R-квадрат, стандартную ошибку оценки и таблицу анализа дисперсии (TSS, RSS). · R squared change - включает R, R-квадрат, F-статистику и их изменения при добавлении-удалении переменных. · Descriptives – выдается число наблюдений без пропущенных значений, среднее значение и стандартное отклонение для каждой анализируемой переменной. Также выводится корреляционная матрица с односторонним уровнем значимости и число наблюдений для каждой корреляции. · Part and partial correlations - выдаются корреляции нулевого порядка (те. Обычные парные), частные и частичные корреляции. · Collinearity diagnostics – выдаются собственные значения масштабированной и нецентрированной матрицы сумм перекрестных произведений, числа обусловленности, доли в разложении дисперсии, коэффициенты разбухания дисперсии (VIF – variance inflation factor), толерантности для отдельных переменных. · Durbin- Watson - тест для выявления автокорреляции. Если DW больше 2 -отрицательная автокорреляция, меньше 2 - положительная.
Plots - графическая иллюстрация. При ее активизации выводится диалоговое окно (рис.5-4). В диалоговом окне Plots имеются возможности: Типы переменных: · DEPENDNT - зависимая переменная; · ZPRED - предсказываемые значения зависимой переменной (экстраполяция). Может быть стандартизирована с математическим ожиданием 0 и стандартным отклонением 1; · ZRESID - отклонение: е i=У i- Y^; · DRESID - исключенные остатки (разности); · ADJPRED - нормированные предсказанные значения; · SRESID - остатки, стандартизованные на оценку их стандартного отклонения. Produce all partial plots - строит точечную диаграмму остатков независимых переменных.
Рис.5-4. Вид диалогового окна Plots
Save - каждый пункт добавляет одну или более переменных в файл данных Predicted Values · Standardized - экстраполирование зависимой переменной; · Adjusted - экстраполирование для случая, который выбрасывается при вычислении коэффициентов регрессии; · S. E. of mean pred. value - оценка стандартного отклонения среднего значения зависимой переменной для случая, когда независимые переменные имеют такие же значения Residuals; · Unstandardized - отклонение: е i = Yi - Y^; · Deleted - исключенные остатки (разности).
Options - настройка для пошагового метода: · Use probability of F - уровень значимости (для ввода должен быть меньше, чнм для удаления); · Use P value - использование Р-значений; · Exclude cases listwise - использование только тех ячеек, которые содержат верные (корректные) значения; · Exclude cases painwise - рассчитывает каждый коэффициент корреляции, используя все ячейки с корректными значениями; · Replace with mean - замещает недостающее значение средним значением переменной.
Вид результатов
Результаты расчета линейной регрессии представлены большим количеством таблиц. Приведем самые основные из них. На рис. 5-5 представлена таблица суммарных характеристик. В ней нужно обратить внимание на R, R square, F Change, Sig. F Change, Durbin-Watson. Из рис.5-5 следует, что рассчитанная модель адекватна, коэффициент корреляции очень высок, в остатках сериальная составляющая (Durbin-Watson) отсутствует. На рис.5-6 проиллюстрирована таблица коэффициентов регрессии. Из нее следует, что полученные коэффициенты статистически значимы t- критерий и Sig. Показатель IMQ влияет на индекс РТС положительно.
Рис.5-5. Суммарные характеристики модели
Рис.5-6. Таблица коэффициентов регрессии
Таблица дисперсионного анализа (рис.5-7) показывает, что модель адекватна (F и Sig).
Рис.5-7. Дисперсионный анализ модели
|
|||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2021-01-08; просмотров: 183; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.219.14.63 (0.187 с.) |



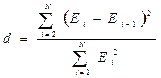
 ,
,