

Мы поможем в написании ваших работ!
ЗНАЕТЕ ЛИ ВЫ?
|
Приклад виконання лабораторної роботи N4
Завдання 1
Робота всіх варіантів демонструється на обробці файлу з іменем Hum-Dum.txt, вихідний уміст якого показано в наступному протоколі:
| Script started on Thu Sep 5 07:56:10 2002bash2-2.05$ cat Hum-DumHumpty-DumptySet on the wall.Humpty-DumptyHad a greate fall.And all the king's horses,And all the king's man.Can not Humpty,Can not Dumpty,Humpty-Dumpty,Dumpty-Humpty,Set on this wallAgain.bash2-2.05$Script done on Thu Sep 5 07:56:21 2002 | Нижче приводяться деякі загальні міркування за рішенням завдань 1-го завдання.
У більшості випадків ми можемо легко сформулювати оператори потокового редактора, необхідні для виконання заданого перетворення, за винятком одного компонента - адреси рядка, до якого це перетворення повинне бути застосоване. У деяких випадках нам також заздалегідь невідомий і текст, який необхідно вставити в цільовий рядок. Тому типова схема розв'язку наступна:
- Визначаються номери рядків, до яких повинні бути застосовані перетворення, а при необхідності - також і текст, який повинен вставлятися в цільовий файл. Для визначення застосовуються статичні (заздалегідь відомі й закладені в текст команд) команди потокового редактора. Результати цього кроку зберігаються у файлі.
- Шляхом редагування результатів 1-го кроку динамічно формуються команди sed для виконання перетворення тексти, що містять адреси й, певні на 1-м кроці. Ці команди зберігаються у файлі.
- Виконується редагування вихідного тексту командами, збереженими на 2-м кроці.
Можливі два підходи до одержання номерів рядків, що підлягають перетворенню:
- виконати нумерування всіх рядків вихідного файлу (це можна зробити командою pr або командою cat з опцією -n), а потім із пронумерованої послідовності рядків вибрати рядок, призначену для обробки з її номером; таке приймання застосоване в розв'язках для варіантів 1 і 2;
- вибрати номер рядка, призначеної для обробки, за допомогою команди sed "="; таке приймання застосовано для варіанта 3.
Оскільки Unix має велика кількість утиліт для обробки текстів, причому функції багатьох утиліт перекриваються, кожна із запропонованих завдань може бути вирішена безліччю різних способів.
Завдання 1, варіант 1
Кожне друге слово кожного рядка вивести в окремий наступний рядок. Якщо в рядку тільки одне слово, нічого не робити.
Розв'язок:
| pr -n' ' -T Hum-Dum.txt | | Вивести файл без заголовка й зайвих рядків, але з номерами рядків.
| | sed -n 's/ *//p' | | Вилучити головні пробіли.
| | cut -f1,3 -d' ' | | Вирізати номер і 2-е слово.
| | sed -n '/[0-9]/p' >temp01 | Вилучити рядка, що містять тільки номер, результат зберегти в 1-м тимчасовому файлі.
| | cut -f1 -d' ' temp01 | | Вибрати з 1-го тимчасового файлу номера рядків.
| | sed -n 's/$/a\\/p' >temp02 | Додати до них 'a\' і зберегти в 2-м тимчасовому файлі.
| | cut -f2 -d' ' temp01 >temp03 | Вибрати з 1-го тимчасового файлу слова й зберегти в 3-м тимчасовому файлі.
| | paste -d'\n' temp02 temp03 >temp01 | Зкріпити построково 2-й і 3-й тимчасові файли, вставивши між рядками, що зчіплюються, переклад рядка. Результат зберегти в 1-м тимчасовому файлі. Результат - набір команд sed на вставку.
| | sed -f temp01 Hum-Dum.txt >result | Виконати команди з 1-го тимчасового файлу, зберегти результат.
| | rm -f temp* | Вилучити тимчасові файли.
| Протокол виконання:
| Script started on Thu Sep 5 08:00:29 2002bash2-2.05$ pr -n' ' -T Hum-Dum.txt |> sed -n 's/ *//p' |> cut -f1,3 -d' ' |> sed -n '/[0-9]/p' >temp01bash2-2.05$ cut -f1 -d' ' temp01 |> sed -n 's/$/a\\/p' >temp02bash2-2.05$ cut -f2 -d' ' temp01 >temp03bash2-2.05$ paste -d'\n' temp02 temp03 >temp01bash2-2.05$ sed -f temp01 Hum-Dum.txt >resultbash2-2.05$ rm -f temp*bash2-2.05$ cat resultHumpty-DumptySet on the wall.onHumpty-DumptyHad a greate fall.aAnd all the king's horses,allAnd all the king's man.allCan not Humpty,notCan not Dumpty,notHumpty-Dumpty,Dumpty-Humpty,Set on this wallonAgain.bash2-2.05$Script done on Thu Sep 5 08:00:47 2002 | Зверніть увагу на те, що у вищенаведеному протоколі деякі запрошення системи виглядають як "$", а деякі - як ">". Система друкує запрошення ">" (вторинне запрошення), якщо попередня команда закінчується ознакою конвеєра "|" і, отже, обов'язково очікується введення наступної команди. А якщо ні, то друкується первинне запрошення - "$". Символи первинного й вторинного запрошення визначаються змінними оточення PS1 і PS2 відповідно.
Завдання 1, варіант 2
Перший символ кожного рядка замінити на перший символ наступного рядка. Останній рядок залишається без змін.
Розв'язок:
| pr -n' ' -T Hum-Dum.txt | | Вивід з нумерацією рядків.
| | cut -c7 | | Виділення 1-го символу.
| | sed -n '2,$p' >temp01 | Видалення 1-й рядка, символ з неї нікуди не підставляється.1-е символи рядків зберігаються в тимчасовому файлі.
| | pr -n' ' -T Hum-Dum.txt | | Вивід з нумерацією рядків.
| | sed -n 's/[ ]*//p' | | Видалення головних пробілів.
| | cut -f1 -d' ' | | Вивід тільки стовпця номерів.
| | paste -d' ' - temp01 | | Зчеплення номера рядка (вхідний потік) з 1-м символом наступного рядка (тимчасовий файл). Виходить, наприклад: '3 H'.
| | sed '$d' | | Видалення останнього рядка - у неї нічого не підставляється.
| | sed -n 's/ /s\/\\.\//p' | | Заміна пробілу між номером і символом на службові символи. Виходить: '3s/./H'.
| | sed -n 's/$/\//p' >temp01 | Додавання службових символів у кінець рядка. Виходить: '3s/./H/' - команда sed на зміну 1-го символу рядка. (Зверніть увагу: ця команда не закінчується прапором 'p'.) Команди зберігаються в тимчасовому файлі.
| | sed -f temp01 Hum-Dum.txt >result | Тимчасовий файл використовується як командний скрипт sed. (Зверніть увагу: якби в командах скрипта не було б прапора 'p', а в даній команді не було б опції -n, не вивівся б останній рядок, для якого немає підстановки в скрипті). Результат зберігається.
| | rm -f temp* | Видалення тимчасового файлу.
| Протокол виконання:
| Script started on Thu Sep 5 08:05:45 2002bash2-2.05$ pr -n' ' -T Hum-Dum.txt |> cut -c7 |> sed -n '2,$p' >temp01bash2-2.05$ pr -n' ' -T Hum-Dum.txt |> sed -n 's/[ ]*//p' |> cut -f1 -d' ' |> paste -d' ' - temp01 |> sed '$d' |> sed -n 's/ /s\/\\.\//p' |> sed -n 's/$/\//p' >temp01bash2-2.05$ sed -f temp01 Hum-Dum.txt >resultbash2-2.05$ rm -f temp*bash2-2.05$ cat resultSumpty-DumptyHet on the wall.Humpty-DumptyAad a greate fall.And all the king's horses,Cnd all the king's man.Can not Humpty,Han not Dumpty,Dumpty-Dumpty,Sumpty-Humpty,Aet on this wallAgain.bash2-2.05$Script done on Thu Sep 5 08:06:12 2002 |
Завдання 1, варіант 3
У передостанньому рядку, який закінчується крапкою, поміняти місцями перше слово з останнім.
Розв'язок:
| sed -n '/\.$/=' Hum-Dum.txt | | Вивід номерів усіх рядків, які закінчуються крапкою.
| | tail -2 | | Вивід двох останні із цих номерів.
| | head -n1 > temp01 | Вивід першого із двох останніх номерів. Збереження в temp01.
| | sed -n 's/$/s\/ \.\*\/\/p/p' temp01 >temp02 | Формування команди sed на вивід 1-го слова рядка з номером, збереженим в temp01. Команда зберігається в temp02.
| | sed -n -f temp02 Hum-Dum.txt >temp03 | Виконання команди з temp02, запис 1-го слова в temp03.
| | sed -n 's/$/s\/\[\ \]\* \/\/gp/p' temp01 >temp02 | Формування команди sed на вивід останнього слова рядка з номером, збереженим в temp01. Команда зберігається в temp02.
| | sed -n -f temp02 Hum-Dum.txt >temp04 | Виконання команди з temp02, запис останнього слова в temp04.
| | paste -d' ' temp01 temp03 | | Зчеплення через пробіл номера рядка й останнього слова рядка.
| | sed -n 's/ /s\/\ [\ \]\*$\/ /p' | | Формування команди sed на заміну в рядку з номером, обраним з temp01, 1-го слова на текст, обраний з temp03.
| | sed -n 's/$/\//p' >temp03 | Завершення формування команди й збереження її в temp03.
| | paste -d' ' temp01 temp04 | | Зчеплення через пробіл номера рядка й 1-го слова рядка.
| | sed -n 's/ /s\/\\[\ \]\* \//p' | | Формування команди sed на заміну в рядку з номером, обраним з temp01, останнього слова на текст, обраний з temp04.
| | sed -n 's/$/ \//p' >temp04 | Завершення формування команди й збереження її в temp04.
| | sed -f temp03 Hum-Dum.txt | | Виконання для вихідного файлу команди з temp03.
| | sed -f temp04 >result | Виконання для того, що вийшло, команди з temp04.
| | rm -f temp* | Видалення тимчасових файлів.
| Протокол виконання:
| Script started on Thu Sep 5 08:10:13 2002bash2-2.05$ sed -n '/\.$/=' Hum-Dum.txt |> tail -2 |> head -n1 > temp01bash2-2.05$ sed -n 's/$/s\/ \.\*\/\/p/p' temp01 >temp02bash2-2.05$ sed -n -f temp02 Hum-Dum.txt >temp03bash2-2.05$ sed -n 's/$/s\/\[\ \]\* \/\/gp/p' temp01 >temp02bash2-2.05$ sed -n -f temp02 Hum-Dum.txt >temp04bash2-2.05$ paste -d' ' temp01 temp03 |> sed -n 's/ /s\/\ [\ \]\*$\/ /p' |> sed -n 's/$/\//p' >temp03bash2-2.05$ paste -d' ' temp01 temp04 |> sed -n 's/ /s\/\\[\ \]\* \//p' |> sed -n 's/$/ \//p' >temp04bash2-2.05$ sed -f temp03 Hum-Dum.txt |> sed -f temp04 >result> bash2-2.05$ rm -f temp*bash2-2.05$ cat resultHumpty-DumptySet on the wall.Humpty-DumptyHad a greate fall.And all the king's horses,man. all the king's AndCan not Humpty,Can not Dumpty,Humpty-Dumpty,Dumpty-Humpty,Set on this wallAgain.bash2-2.05$Script done on Thu Sep 5 08:10:46 2002 |
Завдання 2
Робота всіх варіантів цього завдання відбувається на наборі файлів:../metod/query*., query1, query2, query3, query4, query5. Ті, хто не приклав ще досить зусиль для того, щоб забути наш курс "Організація баз даних", без праці довідаються в цих файлах результати виконання запитів до бази даних "Корпорація Кинга". Ці результати являють собою таблиці (реляційні таблиці) і становлять як би базу даних, схема якої показана нижче:
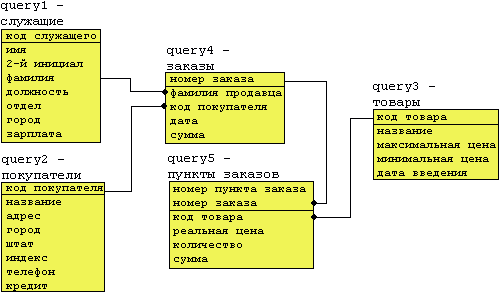
Варіанти завдання 2 являють собою завдання на вибірку даних з "таблиць" цієї " бази даних". Утиліти Unix надають у наше розпорядження наступні засоби, які тією чи іншою мірою можуть служити аналогом реляційних операцій:
- Операція проекції може бути здійснена вирізанням певних полів рядка - командою cut.
- Операція обмеження може бути здійснена який-небудь із утиліт, що здійснюють пошук рядка по шаблонові - grep або sed.
- Операція природнього з'єднання може бути здійснена утилітою join. Випливає однак пам'ятати, що для застосування утиліти join таблиці повинні бути відсортовані по тому стовпцю, по якому відбувається з'єднання, це можна зробити за допомогою утиліти sort.
- Дублікати у файлах-таблицях можуть бути усунуті за допомогою утиліти uniq або утиліти sort з опцією -u. Слід мати у виді, що в першому випадку дублікатами вважаються збіги повних рядків, а в другому - тільки тих полів, по яких виконується сортування.
- Розглянуті нами утиліти не надають тих можливостей, які надають агрегатні функції SQL, однак функції MAX() і MIN() можна промоделювати, виконавши сортування таблиці й вибравши потім першу (утиліта head) або останню (утиліта tail) рядок.
У поясненнях до наших прикладів виконання ми часто використовуємо термінологію реляційних операцій.
Більшість утиліт, що працюють із полями форматированного тексту, за замовчуванням припускають символом-роздільником полів символ табуляції. Однак працювати із символом табуляції незручно, оскільки він за замовчуванням явно не відображається. Тому ми рекомендуємо призначати роздільником який-небудь відображуваний символ. Зверніть увагу на те, що в наших файлах-таблицях використовуються різні роздільники полів. Для виконання операції з'єднання необхідно встановити загальний роздільник для обох таблиць, що з'єднуються.
Ми завжди виконували проекцію (відбір необхідних стовпців) перш, ніж з'єднання. Можливо виконувати проекцію й після з'єднання. У другому випадку може навіть бути зекономлено кілька команд, але, що попереджає відбір тільки необхідних стовпців зменшує обсяг проміжних результатів, чому суттєво полегшує налагодження.
Завдання 2 варіант 1
Визначити прізвища продавців, які виконували замовлення, що полягають із більш ніж 5 пунктів.
Розв'язок:
| sed 's/ \{1,\}/\:/g'../metod/query5 | | Установка у файлі query5 роздільника ":".
| | cut -f1,2 -d':' | | Проекція по номеру пункту й номеру замовлення.
| | sort +0 -1 -t':' -n | | Числова (опція -n) - сортування по номеру пункту.
| | sed '/[1-4]:/d' >temp01 | Видалення тих рядків, у яких номер пункту 1-4.
| | sort +1 -2 -t':' >temp01 | Сортування по номеру замовлення. Результат зберігається в temp01.
| | sed 's/ \{1,\}/\:/g'../metod/query4 | | Установка у файлі query4 роздільника ":".
| | cut -f1,2 -d':' | | Проекція по номеру замовлення й прізвища продавця.
| | sort +0 -1 -t':' | | Сортування по номеру замовлення.
| | join -j1 1 -j2 2 -t':' - temp01 | | З'єднання зі збереженим в temp01.
| | cut -f2 -d':' | | Проекція на прізвище продавця.
| | sort +0 -1 -t':' -u >result | Сортування на прізвище продавця з усуненням дублікатів.
| | rm -f temp* | Видалення тимчасового файлу.
| Протокол виконання:
| Script started on Thu Sep 5 08:13:56 2002bash2-2.05$ sed 's/ \{1,\}/\:/g'../metod/query5 |> cut -f1,2 -d':' |> sort +0 -1 -t':' -n |> sed '/[1-4]:/d' |> sort +1 -2 -t':' >temp01bash2-2.05$ sed 's/ \{1,\}/\:/g'../metod/query4 |> cut -f1,2 -d':' |> sort +0 -1 -t':' |> join -j1 1 -j2 2 -t':' - temp01 |> cut -f2 -d':' |> sort +0 -1 -t':' -u >resultbash2-2.05$ rm -f temp*bash2-2.05$ cat resultDUNCANROSSSHAWTURNERWARDbash2-2.05$Script done on Thu Sep 5 08:14:14 2002 |
Завдання 2, варіант 2
Визначити покупців, які нічого не купували в лютому 1990 р.
Розв'язок:
| cut -f1,2 -d':'../metod/query2 | | Проекція по коду й імені покупця.
| | sort +0 -1 -t':' >temp01 | Сортування по коду, збереження.
| | sed 's/ \{1,\}/\:/g'../metod/query4 | | Установка роздільника ':'.
| | cut -f3,4 -d':' | | Виділення коду покупця й дати.
| | sed -n '/-FEB-91/p' | | Обмеження по даті.
| | sort +0 -1 -t':' -u | | Сортування по коду покупця, ліквідація дублікатів кодів.
| | join -j1 1 -j2 1 -t':' -a2 - temp01 | | З'єднання по коду покупця (праве зовнішнє).
| | sed -n '/[:]*:[:]*$/'p | | Вибірка тих рядків, у яких тільки один раз зустрічається роздільник полів, тобто, немає дати.
| | cut -f2 -d':' | | Проекція по імені покупця.
| | sort +0 -1 >result | Сортування по імені.
| | rm -f temp* | Видалення тимчасових файлів.
| Протокол виконання:
| Script started on Thu Sep 5 08:16:50 2002bash2-2.05$ cut -f1,2 -d':'../metod/query2 |> sort +0 -1 -t':' >temp01bash2-2.05$ sed 's/ \{1,\}/\:/g'../metod/query4 |> cut -f3,4 -d':' |> sed -n '/-FEB-91/p' |> sort +0 -1 -t':' -u |> join -j1 1 -j2 1 -t':' -a2 - temp01 |> sed -n '/[:]*:[:]*$/'p |> cut -f2 -d':' |> sort +0 -1 >resultbash2-2.05$ rm -f temp*bash2-2.05$ cat resultAL AND BOB'S SPORTSAL'S PRO SHOPALL SPORTAT BATBOB'S FAMILY SPORTSBOB'S SWIM, CYCLE, AND RUNCENTURY SHOPEVERY MOUNTAINFAST BREAKGOOD SPORTHIT, THROW, AND RUNHOOPSJOCKSPORTSJOE'S BIKE SHOPJUST BIKESJUST TENNISPOINT GUARDREBOUND SPORTSSHAPE UPSTADIUM SPORTSTHE ALL AMERICANTHE COLISEUMTHE OUTFIELDTHE POWER FORWARDTHE TOURTKB SPORT SHOPVELO SPORTSWHEELS AND DEALSWOMENS SPORTSbash2-2.05$Script done on Thu Sep 5 08:17:08 2002 |
Завдання 2, варіант 3
Визначити імена й прізвища всіх, що служать фірми, які працюють в одному місті із президентом.
У принципі, це завдання можна розв'язати, і не прибігаючи до реляційних операцій, але ми розв'яжемо її саме таким чином, тому що серед не розглянутих нами є варіанти, які вимагають саме такого підходу.
Хоча всі обирані дані перебувають в одній таблиці, нам необхідно буде застосувати тут автосоединение - з'єднання таблиці із самої собою.
Розв'язок:
| sed 's/ \{1,\}/\:/g'../metod/query1 >temp01 | Установка роздільника ':' у файлі query1 (просто для зручності). Збереження в temp01.
| | sed -n '/:PRESIDENT:/p' temp01 >temp02 | Виділення рядка президента. Збереження в temp02.
| | sed '/:PRESIDENT:/d' temp01 | | Видалення рядка президента.
| | cut -f4,6,7 -d':' temp01 >temp03 | Виділення полів прізвища, назви відділу, міста. Збереження в temp03.
| | cut -f6 -d':' temp02 >temp01 | Виділення назви відділу в рядку президента. Збереження в temp01.
| | sort +1 -2 -t':' temp03 | | Сортування інших службовців по полю назви відділу.
| | join -j1 2 -j2 1 -t':' - temp01 | | З'єднання з назвою відділу президента, збереженим в temp01.
| | cut -f2 -d':' | | Виділення з результату прізвищ службовців.
| | sort +0 -1 -t':' >temp04 | Сортування прізвищ і збереження їх в temp04.
| | cut -f7 -d':' temp02 >temp01 | Виділення міста в рядку президента. Збереження в temp01.
| | sort +2 -3 -t':' temp03 | | Сортування інших службовців по полю міста.
| | join -j1 3 -j2 1 -t':' - temp01 | | З'єднання з містом президента, збереженим в temp01.
| | cut -f2 -d':' | | Виділення з результату прізвищ службовців.
| | sort +0 -1 -t':' | | Сортування прізвищ.
| | join -j1 1 -j2 1 - temp04 >result | З'єднання тих, у кого збігається відділ, з тими, у кого збігається місто. Результат зберігається.
| | rm -f temp* | Видалення тимчасових файлів.
| Протокол виконання:
| Script started on Thu Sep 5 08:20:36 2002bash2-2.05$ sed 's/ \{1,\}/\:/g'../metod/query1 >temp01bash2-2.05$ sed -n '/:PRESIDENT:/p' temp01 >temp02bash2-2.05$ sed '/:PRESIDENT:/d' temp01 |> cut -f4,6,7 -d':' temp01 >temp03bash2-2.05$ cut -f6 -d':' temp02 >temp01bash2-2.05$ sort +1 -2 -t':' temp03 |> join -j1 2 -j2 1 -t':' - temp01 |> cut -f2 -d':' |> sort +0 -1 -t':' >temp04bash2-2.05$ cut -f7 -d':' temp02 >temp01bash2-2.05$ sort +2 -3 -t':' temp03 |> join -j1 3 -j2 1 -t':' - temp01 |> cut -f2 -d':' |> sort +0 -1 -t':' |> join -j1 1 -j2 1 - temp04 >resultbash2-2.05$ rm -f temp*bash2-2.05$ cat resultCLARKKINGMILLERbash2-2.05$Script done on Thu Sep 5 08:20:56 2002 |
Завдання 3
Джерелом вхідних даних для всіх варіантів цього завдання може бути команда печатки вмісту каталогів ls або команда пошуку файлів find. Вихідний потік першої команди направляється в конвеєр, де він може послідовно оброблятися командами обробки текстів: grep, sed, cut, sort і т.п. Якщо в завданні потрібно підрахувати число елементів, в останній ланці конвеєра може бути застосована команда wc.
При виконанні завдання слід мати у виді, що користувацькі групи в системі збігаються з кодами студентських груп (наприклад: "ap109", "ap070b" і т.д.), усе коди починаються з букв "ap"; а імена користувачів формуються як: ім'я_группы nn, де nn - порядковий номер у групі.
Завдання 3 варіант 1
Визначити загальна кількість студентських груп.
Розв'язок:
| ls -ld../* | | Команди виконуються з домашнього каталогу користувача - /home/ ім'я_користувача, а інформацію про створених для груп каталогах можна одержати з каталогу /home/, який може адресуватися з поточного каталогу як:../. Виводимо інформацію про вміст цього каталогу. Опція -l вказується, щоб одержати повну інформацію, включаючи групу, опція -d запобігає обходу підкаталогів. Печатка команди ls перенаправляється в потік.
| | grep "d.\{24\}ap" | | Ознака підкаталогу - буква "-d" у першій позиції видачі команди ls, а імена груп починаються c 25-й позиції видачі. Команді grep задається шаблон, який визначає ознака каталогу в 1-й позиції й ім'я групи, що починається з букв "ap".
| | sed -n 's/[ ]\{2,\}/ /gp' | | Оскільки далі буде потрібно виділяти поля, позбудемося множинних пробілів за допомогою команди sed.
| | cut -f4 -d ' ' | | Виділяється 4-е поле, що містить ім'я групи.
| | sort | | Результат сортується, це знадобиться для наступної команди. Оскільки зараз у тексті залишився тільки один стовпець, ніяких опцій для сортування ми не вказуємо.
| | uniq | | Та сама група повторюється для багатьох каталогів, тому слід позбутися від повторюваних рядків.
| | wc -l | Команда wc підраховує число рядків, що залишилися, результат виводиться на печатку.
| Протокол виконання:
| Script started on Thu Sep 5 08:20:56 2002bash2-2.05$ ls -lad../* | grep "d.\{24\}ap" | sed -n 's/[ ]\{2,\}/ /gp' | cut -f4 -d ' ' |> sort +0 -1 | uniq | wc -l 7bash2-2.05$Script done on Thu Sep 5 08:21:03 2002 |
Завдання 3 варіант 2
Визначити файли в каталозі /etc, які є символічними посиланнями. Вивести імена файлів і імена тих файлів, на які вони посилаються, упорядкувавши список по першому імені.
Розв'язок:
| ls -ld /etc/* | | Виводиться інформація про вміст каталогу, що цікавить нас. Печатка команди ls перенаправляється в потік.
| | grep "[l]" | | Виділяються ті рядки, які мають в 1-й позиції букву "l" - ознака м'якого посилання.
| | sort +8 -9 | | Виконується сортування по 9-му стовпцю - імені файлу
| | sed -n 's/[ ]\{2,\}/ /gp' | | Множинні пробіли заміняються одним пробілом.
| | cut -f9-100 -d' ' | Виділяються поля, починаючи з 9-го - і до кінця.
| Протокол виконання:
|



