Лабораторна робота 3
Тема роботи: Регулярні вираження й команда grep
| Ціль роботи: ознайомлення з мовою базових регулярних виражень і командою grep.
Хід роботи
|
Регулярні вираження являють собою одне з найцікавіших і корисних властивостей операційної системи Unix. Регулярні вираження є мовою опису текстових шаблонів, який використовується в багатьох системних утилітах для виконання операцій пошуку й відбору при різноманітних обробках текстових рядків. Ми починаємо вивчати регулярні вираження із застосування їх в утиліті пошуку grep.
У каталозі /home/metod є п'ять текстових файлів з іменами query1, query2, query3, query4 і query5. Файли містять структурований текст. Структура й склад файлів представлений у наступних довідках:
- структура файлу query1; склад файлу query1
- структура файлу query2; склад файлу query2
- структура файлу query3; склад файлу query3
- структура файлу query4; склад файлу query4
- структура файлу query5; склад файлу query5
Використовуючи команду grep, виконаєте пошук у файлах рядків, відповідних до певних критеріїв. Імена вихідних файлів і критерії пошуку приводяться у Вашому варіанті індивідуального завдання.
Довідка
Структура та склад файлу query1
 7369 JOHN Q SMITH CLERK RESEARCH DALLAS 800
7499 KEVIN J ALLEN SALESPERSON SALES CHICAGO 1600
7505 JEAN K DOYLE MANAGER SALES NEW-YORK 2850
7506 LYNN S DENNIS MANAGER SALES DALLAS 2750
7507 LESLIE D BAKER MANAGER OPERATIONS NEW-YORK 2200
7521 CYNTHIA D WARD SALESPERSON SALES CHICAGO 1250
7555 DANIEL T PETERS SALESPERSON SALES NEW-YORK 1250
7557 KAREN P SHAW SALESPERSON SALES NEW-YORK 1250
7560 SARAH S DUNCAN SALESPERSON SALES DALLAS 1250
7564 GREGORY J LANGE SALESPERSON SALES DALLAS 1250
7566 TERRY M JONES MANAGER RESEARCH DALLAS 2975
7569 CHRIS L ALBERTS MANAGER RESEARCH NEW-YORK 3000
7600 RAYMOND Y PORTER SALESPERSON SALES NEW-YORK 1250
7609 RICHARD M LEWIS STAFF OPERATIONS DALLAS 1800
7654 KENNETH J MARTIN SALESPERSON SALES CHICAGO 1250
7676 DENISE D SOMMERS STAFF OPERATIONS CHICAGO 1850
7698 MARION S BLAKE MANAGER SALES CHICAGO 2850
7782 CAROL F CLARK MANAGER ACCOUNTING NEW-YORK 2450
7788 DONALD T SCOTT ANALYST RESEARCH DALLAS 3000
7789 LIVIA N WEST SALESPERSON SALES DALLAS 1500
7799 MATTHEW G FISHER ANALYST RESEARCH NEW-YORK 3000
7820 PAUL S ROSS SALESPERSON SALES BOSTON 1300
7839 FRANCIS A KING PRESIDENT ACCOUNTING NEW-YORK 5000
7876 DIANE G ADAMS CLERK RESEARCH DALLAS 1100
7900 FRED S JAMES CLERK SALES CHICAGO 950
7902 JENNIFER D FORD ANALYST RESEARCH DALLAS 3000
7916 GRACE M ROBERTS ANALYST RESEARCH NEW-YORK 2875
7919 MICHAEL A DOUGLAS CLERK RESEARCH NEW-YORK 800
7934 BARBARA M MILLER CLERK ACCOUNTING NEW-YORK 1300
7950 ALICE B JENSEN CLERK SALES NEW-YORK 750
7954 JAMES T MURRAY CLERK SALES DALLAS 750
Структура та склад файлу query2
7369 JOHN Q SMITH CLERK RESEARCH DALLAS 800
7499 KEVIN J ALLEN SALESPERSON SALES CHICAGO 1600
7505 JEAN K DOYLE MANAGER SALES NEW-YORK 2850
7506 LYNN S DENNIS MANAGER SALES DALLAS 2750
7507 LESLIE D BAKER MANAGER OPERATIONS NEW-YORK 2200
7521 CYNTHIA D WARD SALESPERSON SALES CHICAGO 1250
7555 DANIEL T PETERS SALESPERSON SALES NEW-YORK 1250
7557 KAREN P SHAW SALESPERSON SALES NEW-YORK 1250
7560 SARAH S DUNCAN SALESPERSON SALES DALLAS 1250
7564 GREGORY J LANGE SALESPERSON SALES DALLAS 1250
7566 TERRY M JONES MANAGER RESEARCH DALLAS 2975
7569 CHRIS L ALBERTS MANAGER RESEARCH NEW-YORK 3000
7600 RAYMOND Y PORTER SALESPERSON SALES NEW-YORK 1250
7609 RICHARD M LEWIS STAFF OPERATIONS DALLAS 1800
7654 KENNETH J MARTIN SALESPERSON SALES CHICAGO 1250
7676 DENISE D SOMMERS STAFF OPERATIONS CHICAGO 1850
7698 MARION S BLAKE MANAGER SALES CHICAGO 2850
7782 CAROL F CLARK MANAGER ACCOUNTING NEW-YORK 2450
7788 DONALD T SCOTT ANALYST RESEARCH DALLAS 3000
7789 LIVIA N WEST SALESPERSON SALES DALLAS 1500
7799 MATTHEW G FISHER ANALYST RESEARCH NEW-YORK 3000
7820 PAUL S ROSS SALESPERSON SALES BOSTON 1300
7839 FRANCIS A KING PRESIDENT ACCOUNTING NEW-YORK 5000
7876 DIANE G ADAMS CLERK RESEARCH DALLAS 1100
7900 FRED S JAMES CLERK SALES CHICAGO 950
7902 JENNIFER D FORD ANALYST RESEARCH DALLAS 3000
7916 GRACE M ROBERTS ANALYST RESEARCH NEW-YORK 2875
7919 MICHAEL A DOUGLAS CLERK RESEARCH NEW-YORK 800
7934 BARBARA M MILLER CLERK ACCOUNTING NEW-YORK 1300
7950 ALICE B JENSEN CLERK SALES NEW-YORK 750
7954 JAMES T MURRAY CLERK SALES DALLAS 750
Структура та склад файлу query2
 7369 JOHN Q SMITH CLERK RESEARCH DALLAS 800
7499 KEVIN J ALLEN SALESPERSON SALES CHICAGO 1600
7505 JEAN K DOYLE MANAGER SALES NEW-YORK 2850
7506 LYNN S DENNIS MANAGER SALES DALLAS 2750
7507 LESLIE D BAKER MANAGER OPERATIONS NEW-YORK 2200
7521 CYNTHIA D WARD SALESPERSON SALES CHICAGO 1250
7555 DANIEL T PETERS SALESPERSON SALES NEW-YORK 1250
7557 KAREN P SHAW SALESPERSON SALES NEW-YORK 1250
7560 SARAH S DUNCAN SALESPERSON SALES DALLAS 1250
7564 GREGORY J LANGE SALESPERSON SALES DALLAS 1250
7566 TERRY M JONES MANAGER RESEARCH DALLAS 2975
7569 CHRIS L ALBERTS MANAGER RESEARCH NEW-YORK 3000
7600 RAYMOND Y PORTER SALESPERSON SALES NEW-YORK 1250
7609 RICHARD M LEWIS STAFF OPERATIONS DALLAS 1800
7654 KENNETH J MARTIN SALESPERSON SALES CHICAGO 1250
7676 DENISE D SOMMERS STAFF OPERATIONS CHICAGO 1850
7698 MARION S BLAKE MANAGER SALES CHICAGO 2850
7782 CAROL F CLARK MANAGER ACCOUNTING NEW-YORK 2450
7788 DONALD T SCOTT ANALYST RESEARCH DALLAS 3000
7789 LIVIA N WEST SALESPERSON SALES DALLAS 1500
7799 MATTHEW G FISHER ANALYST RESEARCH NEW-YORK 3000
7820 PAUL S ROSS SALESPERSON SALES BOSTON 1300
7839 FRANCIS A KING PRESIDENT ACCOUNTING NEW-YORK 5000
7876 DIANE G ADAMS CLERK RESEARCH DALLAS 1100
7900 FRED S JAMES CLERK SALES CHICAGO 950
7902 JENNIFER D FORD ANALYST RESEARCH DALLAS 3000
7916 GRACE M ROBERTS ANALYST RESEARCH NEW-YORK 2875
7919 MICHAEL A DOUGLAS CLERK RESEARCH NEW-YORK 800
7934 BARBARA M MILLER CLERK ACCOUNTING NEW-YORK 1300
7950 ALICE B JENSEN CLERK SALES NEW-YORK 750
7954 JAMES T MURRAY CLERK SALES DALLAS 750
Структура та склад файлу query3
7369 JOHN Q SMITH CLERK RESEARCH DALLAS 800
7499 KEVIN J ALLEN SALESPERSON SALES CHICAGO 1600
7505 JEAN K DOYLE MANAGER SALES NEW-YORK 2850
7506 LYNN S DENNIS MANAGER SALES DALLAS 2750
7507 LESLIE D BAKER MANAGER OPERATIONS NEW-YORK 2200
7521 CYNTHIA D WARD SALESPERSON SALES CHICAGO 1250
7555 DANIEL T PETERS SALESPERSON SALES NEW-YORK 1250
7557 KAREN P SHAW SALESPERSON SALES NEW-YORK 1250
7560 SARAH S DUNCAN SALESPERSON SALES DALLAS 1250
7564 GREGORY J LANGE SALESPERSON SALES DALLAS 1250
7566 TERRY M JONES MANAGER RESEARCH DALLAS 2975
7569 CHRIS L ALBERTS MANAGER RESEARCH NEW-YORK 3000
7600 RAYMOND Y PORTER SALESPERSON SALES NEW-YORK 1250
7609 RICHARD M LEWIS STAFF OPERATIONS DALLAS 1800
7654 KENNETH J MARTIN SALESPERSON SALES CHICAGO 1250
7676 DENISE D SOMMERS STAFF OPERATIONS CHICAGO 1850
7698 MARION S BLAKE MANAGER SALES CHICAGO 2850
7782 CAROL F CLARK MANAGER ACCOUNTING NEW-YORK 2450
7788 DONALD T SCOTT ANALYST RESEARCH DALLAS 3000
7789 LIVIA N WEST SALESPERSON SALES DALLAS 1500
7799 MATTHEW G FISHER ANALYST RESEARCH NEW-YORK 3000
7820 PAUL S ROSS SALESPERSON SALES BOSTON 1300
7839 FRANCIS A KING PRESIDENT ACCOUNTING NEW-YORK 5000
7876 DIANE G ADAMS CLERK RESEARCH DALLAS 1100
7900 FRED S JAMES CLERK SALES CHICAGO 950
7902 JENNIFER D FORD ANALYST RESEARCH DALLAS 3000
7916 GRACE M ROBERTS ANALYST RESEARCH NEW-YORK 2875
7919 MICHAEL A DOUGLAS CLERK RESEARCH NEW-YORK 800
7934 BARBARA M MILLER CLERK ACCOUNTING NEW-YORK 1300
7950 ALICE B JENSEN CLERK SALES NEW-YORK 750
7954 JAMES T MURRAY CLERK SALES DALLAS 750
Структура та склад файлу query3
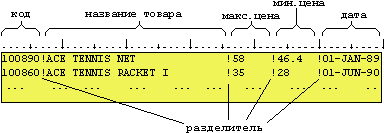 7369 JOHN Q SMITH CLERK RESEARCH DALLAS 800
7499 KEVIN J ALLEN SALESPERSON SALES CHICAGO 1600
7505 JEAN K DOYLE MANAGER SALES NEW-YORK 2850
7506 LYNN S DENNIS MANAGER SALES DALLAS 2750
7507 LESLIE D BAKER MANAGER OPERATIONS NEW-YORK 2200
7521 CYNTHIA D WARD SALESPERSON SALES CHICAGO 1250
7555 DANIEL T PETERS SALESPERSON SALES NEW-YORK 1250
7557 KAREN P SHAW SALESPERSON SALES NEW-YORK 1250
7560 SARAH S DUNCAN SALESPERSON SALES DALLAS 1250
7564 GREGORY J LANGE SALESPERSON SALES DALLAS 1250
7566 TERRY M JONES MANAGER RESEARCH DALLAS 2975
7569 CHRIS L ALBERTS MANAGER RESEARCH NEW-YORK 3000
7600 RAYMOND Y PORTER SALESPERSON SALES NEW-YORK 1250
7609 RICHARD M LEWIS STAFF OPERATIONS DALLAS 1800
7654 KENNETH J MARTIN SALESPERSON SALES CHICAGO 1250
7676 DENISE D SOMMERS STAFF OPERATIONS CHICAGO 1850
7698 MARION S BLAKE MANAGER SALES CHICAGO 2850
7782 CAROL F CLARK MANAGER ACCOUNTING NEW-YORK 2450
7788 DONALD T SCOTT ANALYST RESEARCH DALLAS 3000
7789 LIVIA N WEST SALESPERSON SALES DALLAS 1500
7799 MATTHEW G FISHER ANALYST RESEARCH NEW-YORK 3000
7820 PAUL S ROSS SALESPERSON SALES BOSTON 1300
7839 FRANCIS A KING PRESIDENT ACCOUNTING NEW-YORK 5000
7876 DIANE G ADAMS CLERK RESEARCH DALLAS 1100
7900 FRED S JAMES CLERK SALES CHICAGO 950
7902 JENNIFER D FORD ANALYST RESEARCH DALLAS 3000
7916 GRACE M ROBERTS ANALYST RESEARCH NEW-YORK 2875
7919 MICHAEL A DOUGLAS CLERK RESEARCH NEW-YORK 800
7934 BARBARA M MILLER CLERK ACCOUNTING NEW-YORK 1300
7950 ALICE B JENSEN CLERK SALES NEW-YORK 750
7954 JAMES T MURRAY CLERK SALES DALLAS 750
Структура та склад файлу query4
7369 JOHN Q SMITH CLERK RESEARCH DALLAS 800
7499 KEVIN J ALLEN SALESPERSON SALES CHICAGO 1600
7505 JEAN K DOYLE MANAGER SALES NEW-YORK 2850
7506 LYNN S DENNIS MANAGER SALES DALLAS 2750
7507 LESLIE D BAKER MANAGER OPERATIONS NEW-YORK 2200
7521 CYNTHIA D WARD SALESPERSON SALES CHICAGO 1250
7555 DANIEL T PETERS SALESPERSON SALES NEW-YORK 1250
7557 KAREN P SHAW SALESPERSON SALES NEW-YORK 1250
7560 SARAH S DUNCAN SALESPERSON SALES DALLAS 1250
7564 GREGORY J LANGE SALESPERSON SALES DALLAS 1250
7566 TERRY M JONES MANAGER RESEARCH DALLAS 2975
7569 CHRIS L ALBERTS MANAGER RESEARCH NEW-YORK 3000
7600 RAYMOND Y PORTER SALESPERSON SALES NEW-YORK 1250
7609 RICHARD M LEWIS STAFF OPERATIONS DALLAS 1800
7654 KENNETH J MARTIN SALESPERSON SALES CHICAGO 1250
7676 DENISE D SOMMERS STAFF OPERATIONS CHICAGO 1850
7698 MARION S BLAKE MANAGER SALES CHICAGO 2850
7782 CAROL F CLARK MANAGER ACCOUNTING NEW-YORK 2450
7788 DONALD T SCOTT ANALYST RESEARCH DALLAS 3000
7789 LIVIA N WEST SALESPERSON SALES DALLAS 1500
7799 MATTHEW G FISHER ANALYST RESEARCH NEW-YORK 3000
7820 PAUL S ROSS SALESPERSON SALES BOSTON 1300
7839 FRANCIS A KING PRESIDENT ACCOUNTING NEW-YORK 5000
7876 DIANE G ADAMS CLERK RESEARCH DALLAS 1100
7900 FRED S JAMES CLERK SALES CHICAGO 950
7902 JENNIFER D FORD ANALYST RESEARCH DALLAS 3000
7916 GRACE M ROBERTS ANALYST RESEARCH NEW-YORK 2875
7919 MICHAEL A DOUGLAS CLERK RESEARCH NEW-YORK 800
7934 BARBARA M MILLER CLERK ACCOUNTING NEW-YORK 1300
7950 ALICE B JENSEN CLERK SALES NEW-YORK 750
7954 JAMES T MURRAY CLERK SALES DALLAS 750
Структура та склад файлу query4
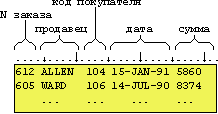 7369 JOHN Q SMITH CLERK RESEARCH DALLAS 800
7499 KEVIN J ALLEN SALESPERSON SALES CHICAGO 1600
7505 JEAN K DOYLE MANAGER SALES NEW-YORK 2850
7506 LYNN S DENNIS MANAGER SALES DALLAS 2750
7507 LESLIE D BAKER MANAGER OPERATIONS NEW-YORK 2200
7521 CYNTHIA D WARD SALESPERSON SALES CHICAGO 1250
7555 DANIEL T PETERS SALESPERSON SALES NEW-YORK 1250
7557 KAREN P SHAW SALESPERSON SALES NEW-YORK 1250
7560 SARAH S DUNCAN SALESPERSON SALES DALLAS 1250
7564 GREGORY J LANGE SALESPERSON SALES DALLAS 1250
7566 TERRY M JONES MANAGER RESEARCH DALLAS 2975
7569 CHRIS L ALBERTS MANAGER RESEARCH NEW-YORK 3000
7600 RAYMOND Y PORTER SALESPERSON SALES NEW-YORK 1250
7609 RICHARD M LEWIS STAFF OPERATIONS DALLAS 1800
7654 KENNETH J MARTIN SALESPERSON SALES CHICAGO 1250
7676 DENISE D SOMMERS STAFF OPERATIONS CHICAGO 1850
7698 MARION S BLAKE MANAGER SALES CHICAGO 2850
7782 CAROL F CLARK MANAGER ACCOUNTING NEW-YORK 2450
7788 DONALD T SCOTT ANALYST RESEARCH DALLAS 3000
7789 LIVIA N WEST SALESPERSON SALES DALLAS 1500
7799 MATTHEW G FISHER ANALYST RESEARCH NEW-YORK 3000
7820 PAUL S ROSS SALESPERSON SALES BOSTON 1300
7839 FRANCIS A KING PRESIDENT ACCOUNTING NEW-YORK 5000
7876 DIANE G ADAMS CLERK RESEARCH DALLAS 1100
7900 FRED S JAMES CLERK SALES CHICAGO 950
7902 JENNIFER D FORD ANALYST RESEARCH DALLAS 3000
7916 GRACE M ROBERTS ANALYST RESEARCH NEW-YORK 2875
7919 MICHAEL A DOUGLAS CLERK RESEARCH NEW-YORK 800
7934 BARBARA M MILLER CLERK ACCOUNTING NEW-YORK 1300
7950 ALICE B JENSEN CLERK SALES NEW-YORK 750
7954 JAMES T MURRAY CLERK SALES DALLAS 750
Структура та склад файлу query5
7369 JOHN Q SMITH CLERK RESEARCH DALLAS 800
7499 KEVIN J ALLEN SALESPERSON SALES CHICAGO 1600
7505 JEAN K DOYLE MANAGER SALES NEW-YORK 2850
7506 LYNN S DENNIS MANAGER SALES DALLAS 2750
7507 LESLIE D BAKER MANAGER OPERATIONS NEW-YORK 2200
7521 CYNTHIA D WARD SALESPERSON SALES CHICAGO 1250
7555 DANIEL T PETERS SALESPERSON SALES NEW-YORK 1250
7557 KAREN P SHAW SALESPERSON SALES NEW-YORK 1250
7560 SARAH S DUNCAN SALESPERSON SALES DALLAS 1250
7564 GREGORY J LANGE SALESPERSON SALES DALLAS 1250
7566 TERRY M JONES MANAGER RESEARCH DALLAS 2975
7569 CHRIS L ALBERTS MANAGER RESEARCH NEW-YORK 3000
7600 RAYMOND Y PORTER SALESPERSON SALES NEW-YORK 1250
7609 RICHARD M LEWIS STAFF OPERATIONS DALLAS 1800
7654 KENNETH J MARTIN SALESPERSON SALES CHICAGO 1250
7676 DENISE D SOMMERS STAFF OPERATIONS CHICAGO 1850
7698 MARION S BLAKE MANAGER SALES CHICAGO 2850
7782 CAROL F CLARK MANAGER ACCOUNTING NEW-YORK 2450
7788 DONALD T SCOTT ANALYST RESEARCH DALLAS 3000
7789 LIVIA N WEST SALESPERSON SALES DALLAS 1500
7799 MATTHEW G FISHER ANALYST RESEARCH NEW-YORK 3000
7820 PAUL S ROSS SALESPERSON SALES BOSTON 1300
7839 FRANCIS A KING PRESIDENT ACCOUNTING NEW-YORK 5000
7876 DIANE G ADAMS CLERK RESEARCH DALLAS 1100
7900 FRED S JAMES CLERK SALES CHICAGO 950
7902 JENNIFER D FORD ANALYST RESEARCH DALLAS 3000
7916 GRACE M ROBERTS ANALYST RESEARCH NEW-YORK 2875
7919 MICHAEL A DOUGLAS CLERK RESEARCH NEW-YORK 800
7934 BARBARA M MILLER CLERK ACCOUNTING NEW-YORK 1300
7950 ALICE B JENSEN CLERK SALES NEW-YORK 750
7954 JAMES T MURRAY CLERK SALES DALLAS 750
Структура та склад файлу query5
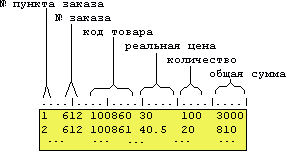 7369 JOHN Q SMITH CLERK RESEARCH DALLAS 800
7499 KEVIN J ALLEN SALESPERSON SALES CHICAGO 1600
7505 JEAN K DOYLE MANAGER SALES NEW-YORK 2850
7506 LYNN S DENNIS MANAGER SALES DALLAS 2750
7507 LESLIE D BAKER MANAGER OPERATIONS NEW-YORK 2200
7521 CYNTHIA D WARD SALESPERSON SALES CHICAGO 1250
7555 DANIEL T PETERS SALESPERSON SALES NEW-YORK 1250
7557 KAREN P SHAW SALESPERSON SALES NEW-YORK 1250
7560 SARAH S DUNCAN SALESPERSON SALES DALLAS 1250
7564 GREGORY J LANGE SALESPERSON SALES DALLAS 1250
7566 TERRY M JONES MANAGER RESEARCH DALLAS 2975
7569 CHRIS L ALBERTS MANAGER RESEARCH NEW-YORK 3000
7600 RAYMOND Y PORTER SALESPERSON SALES NEW-YORK 1250
7609 RICHARD M LEWIS STAFF OPERATIONS DALLAS 1800
7654 KENNETH J MARTIN SALESPERSON SALES CHICAGO 1250
7676 DENISE D SOMMERS STAFF OPERATIONS CHICAGO 1850
7698 MARION S BLAKE MANAGER SALES CHICAGO 2850
7782 CAROL F CLARK MANAGER ACCOUNTING NEW-YORK 2450
7788 DONALD T SCOTT ANALYST RESEARCH DALLAS 3000
7789 LIVIA N WEST SALESPERSON SALES DALLAS 1500
7799 MATTHEW G FISHER ANALYST RESEARCH NEW-YORK 3000
7820 PAUL S ROSS SALESPERSON SALES BOSTON 1300
7839 FRANCIS A KING PRESIDENT ACCOUNTING NEW-YORK 5000
7876 DIANE G ADAMS CLERK RESEARCH DALLAS 1100
7900 FRED S JAMES CLERK SALES CHICAGO 950
7902 JENNIFER D FORD ANALYST RESEARCH DALLAS 3000
7916 GRACE M ROBERTS ANALYST RESEARCH NEW-YORK 2875
7919 MICHAEL A DOUGLAS CLERK RESEARCH NEW-YORK 800
7934 BARBARA M MILLER CLERK ACCOUNTING NEW-YORK 1300
7950 ALICE B JENSEN CLERK SALES NEW-YORK 750
7954 JAMES T MURRAY CLERK SALES DALLAS 750
Команда grep
7369 JOHN Q SMITH CLERK RESEARCH DALLAS 800
7499 KEVIN J ALLEN SALESPERSON SALES CHICAGO 1600
7505 JEAN K DOYLE MANAGER SALES NEW-YORK 2850
7506 LYNN S DENNIS MANAGER SALES DALLAS 2750
7507 LESLIE D BAKER MANAGER OPERATIONS NEW-YORK 2200
7521 CYNTHIA D WARD SALESPERSON SALES CHICAGO 1250
7555 DANIEL T PETERS SALESPERSON SALES NEW-YORK 1250
7557 KAREN P SHAW SALESPERSON SALES NEW-YORK 1250
7560 SARAH S DUNCAN SALESPERSON SALES DALLAS 1250
7564 GREGORY J LANGE SALESPERSON SALES DALLAS 1250
7566 TERRY M JONES MANAGER RESEARCH DALLAS 2975
7569 CHRIS L ALBERTS MANAGER RESEARCH NEW-YORK 3000
7600 RAYMOND Y PORTER SALESPERSON SALES NEW-YORK 1250
7609 RICHARD M LEWIS STAFF OPERATIONS DALLAS 1800
7654 KENNETH J MARTIN SALESPERSON SALES CHICAGO 1250
7676 DENISE D SOMMERS STAFF OPERATIONS CHICAGO 1850
7698 MARION S BLAKE MANAGER SALES CHICAGO 2850
7782 CAROL F CLARK MANAGER ACCOUNTING NEW-YORK 2450
7788 DONALD T SCOTT ANALYST RESEARCH DALLAS 3000
7789 LIVIA N WEST SALESPERSON SALES DALLAS 1500
7799 MATTHEW G FISHER ANALYST RESEARCH NEW-YORK 3000
7820 PAUL S ROSS SALESPERSON SALES BOSTON 1300
7839 FRANCIS A KING PRESIDENT ACCOUNTING NEW-YORK 5000
7876 DIANE G ADAMS CLERK RESEARCH DALLAS 1100
7900 FRED S JAMES CLERK SALES CHICAGO 950
7902 JENNIFER D FORD ANALYST RESEARCH DALLAS 3000
7916 GRACE M ROBERTS ANALYST RESEARCH NEW-YORK 2875
7919 MICHAEL A DOUGLAS CLERK RESEARCH NEW-YORK 800
7934 BARBARA M MILLER CLERK ACCOUNTING NEW-YORK 1300
7950 ALICE B JENSEN CLERK SALES NEW-YORK 750
7954 JAMES T MURRAY CLERK SALES DALLAS 750
Команда grep
| Синтаксис:
| grep [опції] [шаблон] [файл...]
| Опис:
|
| Команда grep виконує пошук рядків, відповідних до шаблону, заданого регулярным_выражением, у файлах або у вхідному потоці. Якщо команда задана без опцій, виводяться всі знайдені рядки. Якщо ім'я файлу не задане, команда виконує пошук у вхідному потоці. Якщо задано кілька імен файлів або в складі імені файлу використаний символ '*', grep перед рядком виводить ім'я файлу, якому цей рядок належить.
| Опції:
|
| | -c
| виводиться тільки число рядків файлу, відповідних до шаблону
| | -f файл
| читання шаблону з файлу
| | -h
| не виводяться імена файлів, у яких знайдені рядки, відповідні до шаблону
| | -i
| ігнорування верхнього/нижнього регістрів
| | -l
| виводяться тільки імена файлів, у яких знайдені рядки, відповідні до шаблону
| | -n
| перед кожним виведеним рядком виводиться її номер у файлі
| | -v
| шукаються рядки, не відповідні до заданого шаблону
| | -w
| шукаються слова, повністю відповідні до шаблону
| | -x
| шукаються рядки, повністю відповідні до шаблону
| | |
Базові регулярні вираження
Регулярні вираження являють собою мову опису текстових шаблонів. Регулярні вираження містять зразки символів, що входять у шукане текстове вираження, і конструкції, обумовлені спеціальними символами (метасимволами).
Завдання 1
У файлі query2 вибрати всі рядки, у яких в адресі є вулиця (" ST. ").
Розв'язок:
- Адреса у файлі query2 починається з 31-й позиції (див. структуру файлу). Тому потрібно насамперед пропустити 30 позицій від початку файлу, що можна зробити таким підвиразом: ".\{30\}" - 30 будь-яких символів від початку файлу.
- Вулиця позначається в адресі скороченням "ST.", і ця підстрока може стояти в адресі на будь-якому місці, тобто перед нею можуть бути й інші символи. Оскільки загальна довжина адреси - не більш 20 символів, перед підстрокой, яку ми шукаємо, може бути не більш 17 будь-яких символів, що визначається підвиразом: ".*\{0,17\}".
- Нарешті, слід указати підстрочкуу, яку ми шукаємо: "ST.". Оскільки в підстроку входить метасимвол "." (крапка), підвираз для пошуку входження буде мати вигляд: "ST\.".
- Підсумкове регулярне вираження:
5. ".\{31\}.*\{0,17\}ST\."
- Протокол виконання:
| Script started on Thu Sep 5 07:42:02 2002bash2-2.05$ grep ".\{31\}.*\{0,17\}ST\."../metod/query2203:REBOUND SPORTS :2 E. 14TH ST. :NEW-YORK :NY:10009:5555989:10000205:POINT GUARD :20 THURSTON ST.:YONKERS :NY:10956:5554766:3000211:AT BAT :234 BEACHEM ST.:BROOKLINE:MA:02146:5557385:8000212:ALL SPORT :1000 38TH ST. :BROOKLYN :NY:11210:5551739:6000213:GOOD SPORT :400 46TH ST. :SUNNYSIDE:NY:11104:5553771:5000214:AL'S PRO SHOP :45 SPRUCE ST. :SPRING :TX:77388:5555172:8000223:VELO SPORTS :23 WHITE ST. :MALDEN :MA:02148:5554983:5000228:FITNESS FIRST :5000 85TH ST. :JACKSON-HEIGHTS:NY:11372:5558710:4000bash2-2.05$ Script done on Thu Sep 5 07:42:18 2002 |
Завдання 2
У файлі query1 вибрати всі рядки, у яких зарплата становить ціле число тисяч.
Розв'язок 1:
- Згідно зі стуктурою файлу, стовпець зарплати починається з позиції 60, тому - підвираз: ".\{59\}".
- Якщо зарплата становить ціле число тисяч, то в ній утримується одна або кілька цифр, за якими іде три нулі - підвираз: "[0-9]\{1,\}000".
- Однак можлива (теоретично) зарплата, наприклад "10001", тому варто подбати про те, щоб наступні за трьома нулями символи були відмінні від значущих цифр. Таких символів може бути скільки завгодно, і ця умова можна забезпечити підвиразом: "[0-9]*".
- Підсумкове регулярне вираження:
5. ".\{59\}[0-9]\{1,\}000[0-9]*"
- Протокол виконання:
| Script started on Thu Sep 5 07:44:14 2002bash2-2.05$ grep ".\{59\}[0-9]\{1,\}000[0-9]*"../metod/query17569 CHRIS L ALBERTS MANAGER RESEARCH NEW-YORK 30007788 DONALD T SCOTT ANALYST RESEARCH DALLAS 30007799 MATTHEW G FISHER ANALYST RESEARCH NEW-YORK 30007839 FRANCIS A KING PRESIDENT ACCOUNTING NEW-YORK 50007902 JENNIFER D FORD ANALYST RESEARCH DALLAS 3000bash2-2.05$ Script done on Thu Sep 5 07:44:19 2002 |
Розв'язок 2:
- Оскільки зарплата є останнім полем рядка файлу query1, можливо, можна просто зажадати, щоб три нулі були останніми символами рядка й сформулювати регулярне вираження в такий спосіб: "000$". Однак, такий розв'язок може наткнутися на неочевидну перешкоду. Усе залежить від того, якими засобами був підготовлений вихідний файл query1 (особливо, якщо він був перенесений з іншої системи).
Справа в тому, що різні програми й редактори використовують різні способи перекладу рядка, і наприкінці рядка можуть виявитися деякі додаткові (невидимі "неозброєним оком" символи. Таким чином, останній 0 у зарплаті може ще не бути останнім символом рядка. Як правило, побачити ці додаткові символи можна, виконавши команду cat з опцією -v. У цьому випадку на видачі команди cat можна побачити недрукований символ, показуваний, наприклад, як: "M". - Наступні протокол ілюструє цей випадок:
| Script started on Thu Sep 5 07:45:53 2002bash2-2.05$ grep "000$"../metod/query1bash2-2.05$ cat -v../metod/query17369 JOHN Q SMITH CLERK RESEARCH DALLAS 800M7499 KEVIN J ALLEN SALESPERSON SALES CHICAGO 1600M7505 JEAN K DOYLE MANAGER SALES NEW-YORK 2850M7506 LYNN S DENNIS MANAGER SALES DALLAS 2750M7507 LESLIE D BAKER MANAGER OPERATIONS NEW-YORK 2200M7521 CYNTHIA D WARD SALESPERSON SALES CHICAGO 1250M7555 DANIEL T PETERS SALESPERSON SALES NEW-YORK 1250M7557 KAREN P SHAW SALESPERSON SALES NEW-YORK 1250M7560 SARAH S DUNCAN SALESPERSON SALES DALLAS 1250M7564 GREGORY J LANGE SALESPERSON SALES DALLAS 1250M7566 TERRY M JONES MANAGER RESEARCH DALLAS 2975M7569 CHRIS L ALBERTS MANAGER RESEARCH NEW-YORK 3000M7600 RAYMOND Y PORTER SALESPERSON SALES NEW-YORK 1250M7609 RICHARD M LEWIS STAFF OPERATIONS DALLAS 1800M7654 KENNETH J MARTIN SALESPERSON SALES CHICAGO 1250M7676 DENISE D SOMMERS STAFF OPERATIONS CHICAGO 1850M7698 MARION S BLAKE MANAGER SALES CHICAGO 2850M7782 CAROL F CLARK MANAGER ACCOUNTING NEW-YORK 2450M7788 DONALD T SCOTT ANALYST RESEARCH DALLAS 3000M7789 LIVIA N WEST SALESPERSON SALES DALLAS 1500M7799 MATTHEW G FISHER ANALYST RESEARCH NEW-YORK 3000M7820 PAUL S ROSS SALESPERSON SALES BOSTON 1300M7839 FRANCIS A KING PRESIDENT ACCOUNTING NEW-YORK 5000M7876 DIANE G ADAMS CLERK RESEARCH DALLAS 1100M7900 FRED S JAMES CLERK SALES CHICAGO 950M7902 JENNIFER D FORD ANALYST RESEARCH DALLAS 3000M7916 GRACE M ROBERTS ANALYST RESEARCH NEW-YORK 2875M7919 MICHAEL A DOUGLAS CLERK RESEARCH NEW-YORK 800M7934 BARBARA M MILLER CLERK ACCOUNTING NEW-YORK 1300M7950 ALICE B JENSEN CLERK SALES NEW-YORK 750M7954 JAMES T MURRAY CLERK SALES DALLAS 750Mbash2-2.05$ Script done on Thu Sep 5 07:46:12 2002 |
Розв'язок 3:
- Уточнимо логікові попереднього розв'язку, оказавшегося неправильним. За трьома нулями перед кінцем рядка може випливати (а може й не випливати) ще один символ, відмінний від значущої цифри:
2. "000[0-9]\{0,1\}"
- Протокол виконання:
| Script started on Thu Sep 5 07:48:12 2002bash2-2.05$ grep "000[0-9]\{0,1\}"../metod/query17569 CHRIS L ALBERTS MANAGER RESEARCH NEW-YORK 30007788 DONALD T SCOTT ANALYST RESEARCH DALLAS 30007799 MATTHEW G FISHER ANALYST RESEARCH NEW-YORK 30007839 FRANCIS A KING PRESIDENT ACCOUNTING NEW-YORK 50007902 JENNIFER D FORD ANALYST RESEARCH DALLAS 3000bash2-2.05$ Script done on Thu Sep 5 07:48:15 2002 |
Завдання 3
У файлі query4 вибрати всі рядки, у яких дата продажу - весна 1990 р.
Розв'язок:
- За структурою файлу query4 видне, що дата представляється досить легко розпізнаваним способом: рік-місяць- число, таким чином, при пошуку дати, що задовольняє нашим вимогам можна не привязываться до певних позицій у рядку, а просто шукати вираження виду: "[0-9]- весняний_місяць -[0-9]".
- Як розпізнати весняний_місяць? Весняні місяці - "MAR", "APR", "MAY". Перша буква весняного місяця повинна бути "M" або "A", друга - "A" або "P", третя - "R" або "Y". Із цих букв можна скласти буквосполучення, що позначають весняні місяці, а всі інші можливі буквосполучення не є позначеннями місяців взагалі. Таким чином, шаблон для розпізнавання весняного місяця буде: "[MA][AP][RY]".
- Підсумкове регулярне вираження:
4. "[0-9]-[MA][AP][RY]-[0-9]"
- Протокол виконання:
| bash2-2.05$ grep "[0-9]-[MA][AP][RY]-[0-9]"../metod/query4620 TURNER 100 12-MAR-91 4450526 WEST 221 04-MAR-90 7700555 WEST 221 04-MAR-91 8540528 WEST 224 24-MAR-90 3770558 WEST 224 31-MAR-91 1700503 SHAW 201 25-MAR-89 1876562 SHAW 203 04-MAY-91 2044.5536 SHAW 206 21-MAY-90 2135.6561 ROSS 207 20-APR-91 2558.3506 DUNCAN 208 27-APR-89 2600.4530 DUNCAN 208 03-APR-90 3026.5557 DUNCAN 208 08-MAR-91 2461.8bash2-2.05$ Script done on Thu Sep 5 07:51:47 2002 |
Хід роботи
У складі операційної системи Unix є велика кількість системних утиліт, призначених для обробки текстів. Утиліти cat і grep, з якими Ви вже повинні були познайомитися, належать до них. Інші утиліти такого роду: cmp - порівняння файлів, cut - "вирізання" полів з тексту й paste - зчеплення рядків файлів, head - роздруківка початку файлу й tail - роздруківка останніх рядків файлу, sort - сортування, join - об'єднання, sed - потоковий текстовий редактор і багато інші.
Кожна з таких утиліт виконує в принципі просту обробку текстового файлу, але послідовно застосовуючи одну утиліту за інший, можна скомбінувати їхньої дії в таким чином, що підсумкове перетворення тексту буде досить складним. Обробка тексту за допомогою послідовних викликів системних утиліт називається в Unix "фільтрацією" тексту, а самі утиліти називаються фільтрами. Такі назви походять від метафоричної вистави проходження потоку даних через ряд фільтрів, кожний з яких робить відбір якихось необхідних складових, у результаті чого ми одержуємо ті дані, які нам потрібні - "відфільтровані" дані.
У ланцюжки фільтрації можуть включатися й інші команди операційної системи, наприклад, команди файлової системи. Параметри й результати роботи цих команд представляються у вигляді символьних рядків, тому вони теж можуть бути оброблені текстовими фільтрами.
За замовчуванням більшість команд Unix читає вхідні дані з потоку стандартного введення (клавіатура) і направляє вихідні дані в потік стандартного виводу (екран). Як правило, одним з параметрів команди є ім'я (імена) файлу (файлів), який (які) вона обробляє. Якщо таке ім'я не задане, команда читає вхідні дані зі стандартного введення. Якщо в команді може задаватися кілька файлів, то звичайно стандартне введення позначається серед імен файлів символом '-'.
Є, однак, можливість перенаправляти стандартні потоки. Запис виду:
команда [аргументи] < файл
означає перенапрямок стандартного введення, тобто те, що те дані, які команда звичайно читає із клавіатури, при цьому запуску будуть прочитані нею з файлу з іменем 'файл'.
Записи виду:
команда [аргументи] > файл
і
команда [аргументи] >> файл
означають перенапрямок стандартного виводу, тобто те, що те дані, які команда звичайно виводить на екран, тепер записані нею у файл із іменем файл. Різниця між '>' і '>>' полягає в тому, що в першому випадку файл буде створюватися заново, а в другому, якщо файл із таким іменем уже існує, вивід команди буде доданий у кінець файлу.
Запис виду:
команда1 [аргументи] | команда2 [аргументи]
визначає конвеєр або програмний канал. У цьому випадку стандартний вивід команди1 буде переспрямований у стандартне введення команди2. Програмний канал є найбільш популярним засобам при побудові ланцюжків фільтрації.
У даній лабораторній роботі Вам пропонується розробити послідовності команд для розв'язку трьох завдань обробки текстових файлів. Основним інструментом для розв'язку цих завдань для Вас будуть, очевидно (але не обов'язково), буде редактор sed і утиліта з'єднання join. Інші засоби Ви виберете самі. Ми, однак, забороняємо використовувати в цій роботі утиліту awk - їй буде присвячена окрема робота.
Завдання 1
Виконати відповідно до Вашого варіанта індивідуального завдання перетворення одного з текстових файлів, створених Вами в роботі N1. Результат зберегти в новому файлі, вихідний файл повинен залишитися без зміни.
Завдання 2
Виконати відповідно до Вашого варіанта індивідуального завдання вибірку даних з файлів../metod/query*:
- структура файлу query1; склад файлу query1
- структура файлу query2; склад файлу query2
- структура файлу query3; склад файлу query3
- структура файлу query4; склад файлу query4
- структура файлу query5; склад файлу query5
с якими Ви працювали в роботі N3. Результат зберегти в новому файлі.
Таблиці, що втримуються в цих файлах, утворюють " базу даних", концептуальна схема якої показана здесь.
Завдання 3
Вибрати й вивести на екран у зручному для сприйняття форматі інформацію, певну у Вашому варіанті індивідуального завдання.
Довідка
Вибрані команди Unix. Короткий опис:
Інформаційні команди: info, man.
Введення й редагування текстів: tee, ed, sed, vi
Вивід текстів: cat, more, pr, pg
Команди файлової системи: cd, chgrp, chmod, chown, cp, file, find, ln, ls, mkdir, mv, pwd, rm, rmdir
Обробка [текстових] файлів: awk, cmp, comm, cut, diff, diff3, grep, head, join, paste, sort, split, tali, uniq, wc
Пошта, процеси, час, etc.: cal, date, echo, env, export, kill, mail, mesg, nice, ps, script, sh, who, write
Команди інтерпретатора shell: basename, expr, read, shift, test
Завдання 1
Робота всіх варіантів демонструється на обробці файлу з іменем Hum-Dum.txt, вихідний уміст якого показано в наступному протоколі:
| Script started on Thu Sep 5 07:56:10 2002bash2-2.05$ cat Hum-DumHumpty-DumptySet on the wall.Humpty-DumptyHad a greate fall.And all the king's horses,And all the king's man.Can not Humpty,Can not Dumpty,Humpty-Dumpty,Dumpty-Humpty,Set on this wallAgain.bash2-2.05$Script done on Thu Sep 5 07:56:21 2002 |
Нижче приводяться деякі загальні міркування за рішенням завдань 1-го завдання.
У більшості випадків ми можемо легко сформулювати оператори потокового редактора, необхідні для виконання заданого перетворення, за винятком одного компонента - адреси рядка, до якого це перетворення повинне бути застосоване. У деяких випадках нам також заздалегідь невідомий і текст, який необхідно вставити в цільовий рядок. Тому типова схема розв'язку наступна:
- Визначаються номери рядків, до яких повинні бути застосовані перетворення, а при необхідності - також і текст, який повинен вставлятися в цільовий файл. Для визначення застосовуються статичні (заздалегідь відомі й закладені в текст команд) команди потокового редактора. Результати цього кроку зберігаються у файлі.
- Шляхом редагування результатів 1-го кроку динамічно формуються команди sed для виконання перетворення тексти, що містять адреси й, певні на 1-м кроці. Ці команди зберігаються у файлі.
- Виконується редагування вихідного тексту командами, збереженими на 2-м кроці.
Можливі два підходи до одержання номерів рядків, що підлягають перетворенню:
- виконати нумерування всіх рядків вихідного файлу (це можна зробити командою pr або командою cat з опцією -n), а потім із пронумерованої послідовності рядків вибрати рядок, призначену для обробки з її номером; таке приймання застосоване в розв'язках для варіантів 1 і 2;
- вибрати номер рядка, призначеної для обробки, за допомогою команди sed "="; таке приймання застосовано для варіанта 3.
Оскільки Unix має велика кількість утиліт для обробки текстів, причому функції багатьох утиліт перекриваються, кожна із запропонованих завдань може бути вирішена безліччю різних способів.
Завдання 1, варіант 1
Кожне друге слово кожного рядка вивести в окремий наступний рядок. Якщо в рядку тільки одне слово, нічого не робити.
Розв'язок:
| pr -n' ' -T Hum-Dum.txt | | Вивести файл без заголовка й зайвих рядків, але з номерами рядків.
|
| sed -n 's/ *//p' | | Вилучити головні пробіли.
|
| cut -f1,3 -d' ' | | Вирізати номер і 2-е слово.
|
| sed -n '/[0-9]/p' >temp01 | Вилучити рядка, що містять тільки номер, результат зберегти в 1-м тимчасовому файлі.
|
| cut -f1 -d' ' temp01 | | Вибрати з 1-го тимчасового файлу номера рядків.
|
| sed -n 's/$/a\\/p' >temp02 | Додати до них 'a\' і зберегти в 2-м тимчасовому файлі.
|
| cut -f2 -d' ' temp01 >temp03 | Вибрати з 1-го тимчасового файлу слова й зберегти в 3-м тимчасовому файлі.
|
| paste -d'\n' temp02 temp03 >temp01 | Зкріпити построково 2-й і 3-й тимчасові файли, вставивши між рядками, що зчіплюються, переклад рядка. Результат зберегти в 1-м тимчасовому файлі. Результат - набір команд sed на вставку.
|
| sed -f temp01 Hum-Dum.txt >result | Виконати команди з 1-го тимчасового файлу, зберегти результат.
|
| rm -f temp* | Вилучити тимчасові файли.
|
Протокол виконання:
| Script started on Thu Sep 5 08:00:29 2002bash2-2.05$ pr -n' ' -T Hum-Dum.txt |> sed -n 's/ *//p' |> cut -f1,3 -d' ' |> sed -n '/[0-9]/p' >temp01bash2-2.05$ cut -f1 -d' ' temp01 |> sed -n 's/$/a\\/p' >temp02bash2-2.05$ cut -f2 -d' ' temp01 >temp03bash2-2.05$ paste -d'\n' temp02 temp03 >temp01bash2-2.05$ sed -f temp01 Hum-Dum.txt >resultbash2-2.05$ rm -f temp*bash2-2.05$ cat resultHumpty-DumptySet on the wall.onHumpty-DumptyHad a greate fall.aAnd all the king's horses,allAnd all the king's man.allCan not Humpty,notCan not Dumpty,notHumpty-Dumpty,Dumpty-Humpty,Set on this wallonAgain.bash2-2.05$Script done on Thu Sep 5 08:00:47 2002 |
Зверніть увагу на те, що у вищенаведеному протоколі деякі запрошення системи виглядають як "$", а деякі - як ">". Система друкує запрошення ">" (вторинне запрошення), якщо попередня команда закінчується ознакою конвеєра "|" і, отже, обов'язково очікується введення наступної команди. А якщо ні, то друкується первинне запрошення - "$". Символи первинного й вторинного запрошення визначаються змінними оточення PS1 і PS2 відповідно.
Завдання 1, варіант 2
Перший символ кожного рядка замінити на перший символ наступного рядка. Останній рядок залишається без змін.
Розв'язок:
| pr -n' ' -T Hum-Dum.txt | | Вивід з нумерацією рядків.
|
| cut -c7 | | Виділення 1-го символу.
|
| sed -n '2,$p' >temp01 | Видалення 1-й рядка, символ з неї нікуди не підставляється.1-е символи рядків зберігаються в тимчасовому файлі.
|
| pr -n' ' -T Hum-Dum.txt | | Вивід з нумерацією рядків.
|
| sed -n 's/[ ]*//p' | | Видалення головних пробілів.
|
| cut -f1 -d' ' | | Вивід тільки стовпця номерів.
|
| paste -d' ' - temp01 | | Зчеплення номера рядка (вхідний потік) з 1-м символом наступного рядка (тимчасовий файл). Виходить, наприклад: '3 H'.
|
| sed '$d' | | Видалення останнього рядка - у неї нічого не підставляється.
|
| sed -n 's/ /s\/\\.\//p' | | Заміна пробілу між номером і символом на службові символи. Виходить: '3s/./H'.
|
| sed -n 's/$/\//p' >temp01 | Додавання службових символів у кінець рядка. Виходить: '3s/./H/' - команда sed на зміну 1-го символу рядка. (Зверніть увагу: ця команда не закінчується прапором 'p'.) Команди зберігаються в тимчасовому файлі.
|
| sed -f temp01 Hum-Dum.txt >result | Тимчасовий файл використовується як командний скрипт sed. (Зверніть увагу: якби в командах скрипта не було б прапора 'p', а в даній команді не було б опції -n, не вивівся б останній рядок, для якого немає підстановки в скрипті). Результат зберігається.
|
| rm -f temp* | Видалення тимчасового файлу.
|
Протокол виконання:
| Script started on Thu Sep 5 08:05:45 2002bash2-2.05$ pr -n' ' -T Hum-Dum.txt |> cut -c7 |> sed -n '2,$p' >temp01bash2-2.05$ pr -n' ' -T Hum-Dum.txt |> sed -n 's/[ ]*//p' |> cut -f1 -d' ' |> paste -d' ' - temp01 |> sed '$d' |> sed -n 's/ /s\/\\.\//p' |> sed -n 's/$/\//p' >temp01bash2-2.05$ sed -f temp01 Hum-Dum.txt >resultbash2-2.05$ rm -f temp*bash2-2.05$ cat resultSumpty-DumptyHet on the wall.Humpty-DumptyAad a greate fall.And all the king's horses,Cnd all the king's man.Can not Humpty,Han not Dumpty,Dumpty-Dumpty,Sumpty-Humpty,Aet on this wallAgain.bash2-2.05$Script done on Thu Sep 5 08:06:12 2002 |
Завдання 1, варіант 3
У передостанньому рядку, який закінчується крапкою, поміняти місцями перше слово з останнім.
Розв'язок:
| sed -n '/\.$/=' Hum-Dum.txt | | Вивід номерів усіх рядків, які закінчуються крапкою.
|
| tail -2 | | Вивід двох останні із цих номерів.
|
| head -n1 > temp01 | Вивід першого із двох останніх номерів. Збереження в temp01.
|
| sed -n 's/$/s\/ \.\*\/\/p/p' temp01 >temp02 | Формування команди sed на вивід 1-го слова рядка з номером, збереженим в temp01. Команда зберігається в temp02.
|
| sed -n -f temp02 Hum-Dum.txt >temp03 | Виконання команди з temp02, запис 1-го слова в temp03.
|
| sed -n 's/$/s\/\[\ \]\* \/\/gp/p' temp01 >temp02 | Формування команди sed на вивід останнього слова рядка з номером, збереженим в temp01. Команда зберігається в temp02.
|
| sed -n -f temp02 Hum-Dum.txt >temp04 | Виконання команди з temp02, запис останнього слова в temp04.
|
| paste -d' ' temp01 temp03 | | Зчеплення через пробіл номера рядка й останнього слова рядка.
|
| sed -n 's/ /s\/\ [\ \]\*$\/ /p' | | Формування команди sed на заміну в рядку з номером, обраним з temp01, 1-го слова на текст, обраний з temp03.
|
| sed -n 's/$/\//p' >temp03 | Завершення формування команди й збереження її в temp03.
|
| paste -d' ' temp01 temp04 | | Зчеплення через пробіл номера рядка й 1-го слова рядка.
|
| sed -n 's/ /s\/\\[\ \]\* \//p' | | Формування команди sed на заміну в рядку з номером, обраним з temp01, останнього слова на текст, обраний з temp04.
|
| sed -n 's/$/ \//p' >temp04 | Завершення формування команди й збереження її в temp04.
|
| sed -f temp03 Hum-Dum.txt | | Виконання для вихідного файлу команди з temp03.
|
| sed -f temp04 >result | Виконання для того, що вийшло, команди з temp04.
|
| rm -f temp* | Видалення тимчасових файлів.
|
Протокол виконання:
| Script started on Thu Sep 5 08:10:13 2002bash2-2.05$ sed -n '/\.$/=' Hum-Dum.txt |> tail -2 |> head -n1 > temp01bash2-2.05$ sed -n 's/$/s\/ \.\*\/\/p/p' temp01 >temp02bash2-2.05$ sed -n -f temp02 Hum-Dum.txt >temp03bash2-2.05$ sed -n 's/$/s\/\[\ \]\* \/\/gp/p' temp01 >temp02bash2-2.05$ sed -n -f temp02 Hum-Dum.txt >temp04bash2-2.05$ paste -d' ' temp01 temp03 |> sed -n 's/ /s\/\ [\ \]\*$\/ /p' |> sed -n 's/$/\//p' >temp03bash2-2.05$ paste -d' ' temp01 temp04 |> sed -n 's/ /s\/\\[\ \]\* \//p' |> sed -n 's/$/ \//p' >temp04bash2-2.05$ sed -f temp03 Hum-Dum.txt |> sed -f temp04 >result> bash2-2.05$ rm -f temp*bash2-2.05$ cat resultHumpty-DumptySet on the wall.Humpty-DumptyHad a greate fall.And all the king's horses,man. all the king's AndCan not Humpty,Can not Dumpty,Humpty-Dumpty,Dumpty-Humpty,Set on this wallAgain.bash2-2.05$Script done on Thu Sep 5 08:10:46 2002 |
Завдання 2
Робота всіх варіантів цього завдання відбувається на наборі файлів:../metod/query*., query1, query2, query3, query4, query5. Ті, хто не приклав ще досить зусиль для того, щоб забути наш курс "Організація баз даних", без праці довідаються в цих файлах результати виконання запитів до бази даних "Корпорація Кинга". Ці результати являють собою таблиці (реляційні таблиці) і становлять як би базу даних, схема якої показана нижче:
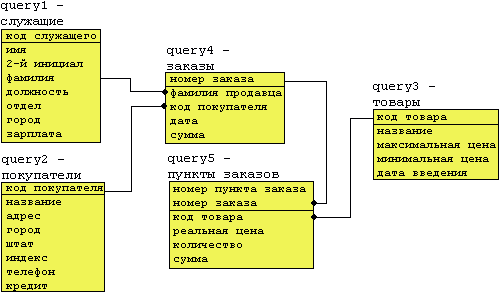
Варіанти завдання 2 являють собою завдання на вибірку даних з "таблиць" цієї " бази даних". Утиліти Unix надають у наше розпорядження наступні засоби, які тією чи іншою мірою можуть служити аналогом реляційних операцій:
- Операція проекції може бути здійснена вирізанням певних полів рядка - командою cut.
- Операція обмеження може бути здійснена який-небудь із утиліт, що здійснюють пошук рядка по шаблонові - grep або sed.
- Операція природнього з'єднання може бути здійснена утилітою join. Випливає однак пам'ятати, що для застосування утиліти join таблиці повинні бути відсортовані по тому стовпцю, по якому відбувається з'єднання, це можна зробити за допомогою утиліти sort.
- Дублікати у файлах-таблицях можуть бути усунуті за допомогою утиліти uniq або утиліти sort з опцією -u. Слід мати у виді, що в першому випадку дублікатами вважаються збіги повних рядків, а в другому - тільки тих полів, по яких виконується сортування.
- Розглянуті нами утиліти не надають тих можливостей, які надають агрегатні функції SQL, однак функції MAX() і MIN() можна промоделювати, виконавши сортування таблиці й вибравши потім першу (утиліта head) або останню (утиліта tail) рядок.
У поясненнях до наших прикладів виконання ми часто використовуємо термінологію реляційних операцій.
Більшість утиліт, що працюють із полями форматированного тексту, за замовчуванням припускають символом-роздільником полів символ табуляції. Однак працювати із символом табуляції незручно, оскільки він за замовчуванням явно не відображається. Тому ми рекомендуємо призначати роздільником який-небудь відображуваний символ. Зверніть увагу на те, що в наших файлах-таблицях використовуються різні роздільники полів. Для виконання операції з'єднання необхідно встановити загальний роздільник для обох таблиць, що з'єднуються.
Ми завжди виконували проекцію (відбір необхідних стовпців) перш, ніж з'єднання. Можливо виконувати проекцію й після з'єднання. У другому випадку може навіть бути зекономлено кілька команд, але, що попереджає відбір тільки необхідних стовпців зменшує обсяг проміжних результатів, чому суттєво полегшує налагодження.
Завдання 2 варіант 1
Визначити прізвища продавців, які виконували замовлення, що полягають із більш ніж 5 пунктів.
Розв'язок:
| sed 's/ \{1,\}/\:/g'../metod/query5 | | Установка у файлі query5 роздільника ":".
|
| cut -f1,2 -d':' | | Проекція по номеру пункту й номеру замовлення.
|
| sort +0 -1 -t':' -n | | Числова (опція -n) - сортування по номеру пункту.
|
| sed '/[1-4]:/d' >temp01 | Видалення тих рядків, у яких номер пункту 1-4.
|
| sort +1 -2 -t':' >temp01 | Сортування по номеру замовлення. Результат зберігається в temp01.
|
| sed 's/ \{1,\}/\:/g'../metod/query4 | | Установка у файлі query4 роздільника ":".
|
| cut -f1,2 -d':' | | Проекція по номеру замовлення й прізвища продавця.
|
| sort +0 -1 -t':' | | Сортування по номеру замовлення.
|
| join -j1 1 -j2 2 -t':' - temp01 | | З'єднання зі збереженим в temp01.
|
| cut -f2 -d':' | | Проекція на прізвище продавця.
|
| sort +0 -1 -t':' -u >result | Сортування на прізвище продавця з усуненням дублікатів.
|
| rm -f temp* | Видалення тимчасового файлу.
|
Протокол виконання:
| Script started on Thu Sep 5 08:13:56 2002bash2-2.05$ sed 's/ \{1,\}/\:/g'../metod/query5 |> cut -f1,2 -d':' |> sort +0 -1 -t':' -n |> sed '/[1-4]:/d' |> sort +1 -2 -t':' >temp01bash2-2.05$ sed 's/ \{1,\}/\:/g'../metod/query4 |> cut -f1,2 -d':' |> sort +0 -1 -t':' |> join -j1 1 -j2 2 -t':' - temp01 |> cut -f2 -d':' |> sort +0 -1 -t':' -u >resultbash2-2.05$ rm -f temp*bash2-2.05$ cat resultDUNCANROSSSHAWTURNERWARDbash2-2.05$Script done on Thu Sep 5 08:14:14 2002 |
Завдання 2, варіант 2
Визначити покупців, які нічого не купували в лютому 1990 р.
Розв'язок:
| cut -f1,2 -d':'../metod/query2 | | Проекція по коду й імені покупця.
|
| sort +0 -1 -t':' >temp01 | Сортування по коду, збереження.
|
| sed 's/ \{1,\}/\:/g'../metod/query4 | | Установка роздільника ':'.
|
| cut -f3,4 -d':' | | Виділення коду покупця й дати.
|
| sed -n '/-FEB-91/p' | | Обмеження по даті.
|
| sort +0 -1 -t':' -u | | Сортування по коду покупця, ліквідація дублікатів кодів.
|
| join -j1 1 -j2 1 -t':' -a2 - temp01 | | З'єднання по коду покупця (праве зовнішнє).
|
| sed -n '/[:]*:[:]*$/'p | | Вибірка тих рядків, у яких тільки один раз зустрічається роздільник полів, тобто, немає дати.
|
| cut -f2 -d':' | | Проекція по імені покупця.
|
| sort +0 -1 >result | Сортування по імені.
|
| rm -f temp* | Видалення тимчасових файлів.
|
Протокол виконання:
| Script started on Thu Sep 5 08:16:50 2002bash2-2.05$ cut -f1,2 -d':'../metod/query2 |> sort +0 -1 -t':' >temp01bash2-2.05$ sed 's/ \{1,\}/\:/g'../metod/query4 |> cut -f3,4 -d':' |> sed -n '/-FEB-91/p' |> sort +0 -1 -t':' -u |> join -j1 1 -j2 1 -t':' -a2 - temp01 |> sed -n '/[:]*:[:]*$/'p |> cut -f2 -d':' |> sort +0 -1 >resultbash2-2.05$ rm -f temp*bash2-2.05$ cat resultAL AND BOB'S SPORTSAL'S PRO SHOPALL SPORTAT BATBOB'S FAMILY SPORTSBOB'S SWIM, CYCLE, AND RUNCENTURY SHOPEVERY MOUNTAINFAST BREAKGOOD SPORTHIT, THROW, AND RUNHOOPSJOCKSPORTSJOE'S BIKE SHOPJUST BIKESJUST TENNISPOINT GUARDREBOUND SPORTSSHAPE UPSTADIUM SPORTSTHE ALL AMERICANTHE COLISEUMTHE OUTFIELDTHE POWER FORWARDTHE TOURTKB SPORT SHOPVELO SPORTSWHEELS AND DEALSWOMENS SPORTSbash2-2.05$Script done on Thu Sep 5 08:17:08 2002 |
Завдання 2, варіант 3
Визначити імена й прізвища всіх, що служать фірми, які працюють в одному місті із президентом.
У принципі, це завдання можна розв'язати, і не прибігаючи до реляційних операцій, але ми розв'яжемо її саме таким чином, тому що серед не розглянутих нами є варіанти, які вимагають саме такого підходу.
Хоча всі обирані дані перебувають в одній таблиці, нам необхідно буде застосувати тут автосоединение - з'єднання таблиці із самої собою.
Розв'язок:
| sed 's/ \{1,\}/\:/g'../metod/query1 >temp01 | Установка роздільника ':' у файлі query1 (просто для зручності). Збереження в temp01.
|
| sed -n '/:PRESIDENT:/p' temp01 >temp02 | Виділення рядка президента. Збереження в temp02.
|
| sed '/:PRESIDENT:/d' temp01 | | Видалення рядка президента.
|
| cut -f4,6,7 -d':' temp01 >temp03 | Виділення полів прізвища, назви відділу, міста. Збереження в temp03.
|
| cut -f6 -d':' temp02 >temp01 | Виділення назви відділу в рядку президента. Збереження в temp01.
|
| sort +1 -2 -t':' temp03 | | Сортування інших службовців по полю назви відділу.
|
| join -j1 2 -j2 1 -t':' - temp01 | | З'єднання з назвою відділу президента, збереженим в temp01.
|
| cut -f2 -d':' | | Виділення з результату прізвищ службовців.
|
| sort +0 -1 -t':' >temp04 | Сортування прізвищ і збереження їх в temp04.
|
| cut -f7 -d':' temp02 >temp01 | Виділення міста в рядку президента. Збереження в temp01.
|
| sort +2 -3 -t':' temp03 | | Сортування інших службовців по полю міста.
|
| join -j1 3 -j2 1 -t':' - temp01 | | З'єднання з містом президента, збереженим в temp01.
|
| cut -f2 -d':' | | Виділення з результату прізвищ службовців.
|
| sort +0 -1 -t':' | | Сортування прізвищ.
|
| join -j1 1 -j2 1 - temp04 >result | З'єднання тих, у кого збігається відділ, з тими, у кого збігається місто. Результат зберігається.
|
| rm -f temp* | Видалення тимчасових файлів.
|
Протокол виконання:
| Script started on Thu Sep 5 08:20:36 2002bash2-2.05$ sed 's/ \{1,\}/\:/g'../metod/query1 >temp01bash2-2.05$ sed -n '/:PRESIDENT:/p' temp01 >temp02bash2-2.05$ sed '/:PRESIDENT:/d' temp01 |> cut -f4,6,7 -d':' temp01 >temp03bash2-2.05$ cut -f6 -d':' temp02 >temp01bash2-2.05$ sort +1 -2 -t':' temp03 |> join -j1 2 -j2 1 -t':' - temp01 |> cut -f2 -d':' |> sort +0 -1 -t':' >temp04bash2-2.05$ cut -f7 -d':' temp02 >temp01bash2-2.05$ sort +2 -3 -t':' temp03 |> join -j1 3 -j2 1 -t':' - temp01 |> cut -f2 -d':' |> sort +0 -1 -t':' |> join -j1 1 -j2 1 - temp04 >resultbash2-2.05$ rm -f temp*bash2-2.05$ cat resultCLARKKINGMILLERbash2-2.05$Script done on Thu Sep 5 08:20:56 2002 |
Завдання 3
Джерелом вхідних даних для всіх варіантів цього завдання може бути команда печатки вмісту каталогів ls або команда пошуку файлів find. Вихідний потік першої команди направляється в конвеєр, де він може послідовно оброблятися командами обробки текстів: grep, sed, cut, sort і т.п. Якщо в завданні потрібно підрахувати число елементів, в останній ланці конвеєра може бути застосована команда wc.
При виконанні завдання слід мати у виді, що користувацькі групи в системі збігаються з кодами студентських груп (наприклад: "ap109", "ap070b" і т.д.), усе коди починаються з букв "ap"; а імена користувачів формуються як: ім'я_группы nn, де nn - порядковий номер у групі.
Завдання 3 варіант 1
Визначити загальна кількість студентських груп.
Розв'язок:





