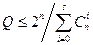Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Связь корректирующей способности кода с кодовым расстоянием.Содержание книги
Поиск на нашем сайте
При взаимно независимых ошибках наиболее вероятен переход в кодовую комбинацию, отличающуюся от данной в наименьшем числе символов. Степень отличия любых двух кодовых комбинаций характеризуется расстоянием между ними в смысле Хэмминга или просто кодовым расстоянием. Оно выражается числом символов, в которых комбинации отличаются одна от другой, и обозначается через d. Чтобы получить кодовое расстояние между двумя комбинациями двоичного кода, достаточно подсчитать число единиц в сумме этих комбинаций по модулю 2. Например:
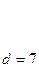
Минимальное расстояние, взятое по всем парам кодовых разрешенных комбинаций кода, называют минимальным кодовым расстоянием. Декодирование после приема может производиться таким образом, что принятая кодовая комбинация отождествляется с той разрешенной, которая находится от нее на наименьшем кодовом расстоянии. Такое декодирование называется декодированием по методу максимального правдоподобия. Очевидно, что при d= 1 все кодовые комбинации являются разрешенными. Например, при n =3 разрешенные комбинации образуют следующее множество: 000, 001, 010, 011, 100, 101, 110, 111. Любая одиночная ошибка трансформирует данную комбинацию в другую разрешенную комбинацию. Это случай безызбыточного кода, не обладающего корректирующей способностью. Если d= 2, то ни одна из разрешенных кодовых комбинаций при одиночной ошибке не переходит в другую разрешенную комбинацию. Например, подмножество разрешенных кодовых комбинаций может быть образовано по принципу четности в них числа единиц, как это приведено ниже для n = 3: 000, 011, 101, 110 разрешенные комбинации 001, 010, 100, 111 запрещенные комбинации
Код обнаруживает одиночные ошибки, а также другие ошибки нечетной кратности (при n=3 тройные). В общем случае при необходимости обнаруживать ошибки кратности до r включительно минимальное хэммингово расстояние между разрешенными кодовыми комбинациями должно быть по крайней мере на единицу больше r, т. е.
Действительно, в этом случае ошибка, кратность которой не превышает r, не в состоянии перевести одну разрешенную кодовую комбинацию в другую. Для исправления одиночной ошибки каждой разрешенной кодовой комбинации необходимо сопоставить подмножество запрещенных кодовых комбинаций. Чтобы эти подмножества не пересекались, хэммингово расстояние между разрешенными кодовыми комбинациями должно быть не менее трех. При n = 3 за разрешенные комбинации можно, например, принять 000 или 111. Тогда разрешенной комбинации 000 необходимо приписать подмножество запрещенных кодовых комбинаций 001, 010, 100, образующихся в результате возникновения единичной ошибки в комбинации 000. Подобным же образом разрешенной комбинации 111 необходимо приписать подмножество запрещенных кодовых комбинаций: 110, 011, 101, образующихся в результате возникновения единичной ошибки в комбинации 111:
В общем случае для обеспечения возможности исправления всех ошибок кратности до s включительно при декодировании по методу максимального правдоподобия каждая из ошибок должна приводить к запрещенной комбинации, относящейся к подмножеству исходной разрешенной кодовой комбинации. Подмножество каждой из разрешенных n-разрядных комбинаций Bi (рис. 2) складывается из запрещенных комбинаций, являющихся следствием воздействия: Ø единичных ошибок (они располагаются на сфере радиусом d =1, и их число равно С1 n); Ø двойных ошибок (они располагаются на сфере радиусом d =2, и их число равно C 2 n) и т. д.
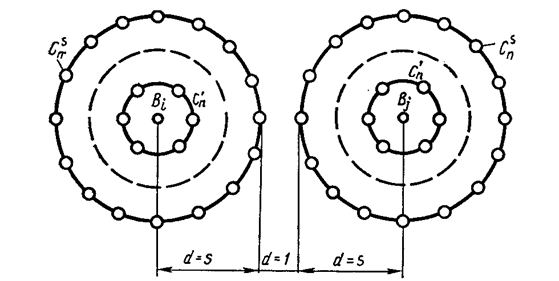
Внешняя сфера подмножества имеет радиус d=s и содержит Поскольку указанные подмножества не должны пересекаться, минимальное хэммингово расстояние между разрешенными комбинациями должно удовлетворять соотношению:
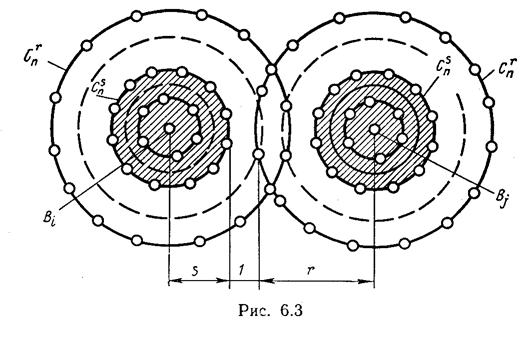
Нетрудно убедиться в том (рис.3), что для исправления всех ошибок кратности s и одновременного обнаружения всех ошибок кратности r (r ≥ s) минимальное хэммингово расстояние нужно выбирать из условия
Формулы, выведенные для случая взаимно независимых ошибок, дают завышенные значения минимального кодового расстояния при помехе, коррелированной с сигналом. В реальных каналах связи длительность импульсов помехи часто превышает длительность символа. При этом одновременно искажаются несколько расположенных рядом символов комбинации. Ошибки такого рода получили название пачек ошибок или пакетов ошибок. Длиной пачки ошибок называют число следующих друг за другом символов, начиная с первого искаженного символа и кончая искаженным символом, за которым следует не менее ρ неискаженных символов. Основой для выбора ρ служат статистические данные об ошибках. Если, например, кодовая комбинация 00000000000000000 трансформировалась в комбинацию 01001000010101000 и ρ принято равным трем, то в комбинации имеется два пакета длиной 4 и 5 символов. Описанный способ декодирования для этого случая не является наиболее эффективным. Для пачек ошибок и асимметричного канала при той же корректирующей способности минимальное хэммингово расстояние между разрешенными комбинациями может быть меньше. Подчеркнем еще раз, что каждый конкретный корректирующий код не гарантирует исправления любой комбинации ошибок. Коды предназначены для исправления комбинаций ошибок, наиболее вероятных для заданного канала и наиболее опасных по последствиям. Если характер и уровень помехи отличаются от предполагаемых, эффективность применения кода резко снизится. Применение корректирующего кода не может гарантировать безошибочного приема, но дает возможность повысить вероятность получения на выходе правильного результата. Одной из основных характеристик корректирующего кода является избыточность кода, указывающая степень удлинения кодовой комбинации для достижения определенной корректирующей способности. Если на каждые n символов выходной последовательности кодера канала приходится k информационных и n - k проверочных, то относительная избыточность кода может быть выражена соотношением
Величина Rk, изменяется от 0 до ∞. Коды, обеспечивающие заданную корректирующую способность при минимально возможной избыточности, называют оптимальными. Наибольшее возможное число Q разрешенных комбинаций n -значного двоичного кода, обладающего способностью исправлять взаимно независимые ошибки кратности до s включительно. Это равносильно отысканию числа комбинаций, кодовое расстояние между которыми не менее Общее число различных исправляемых ошибок для каждой разрешенной комбинации составляет Каждая из таких ошибок должна приводить к запрещенной комбинации, относящейся к подмножеству данной разрешенной комбинации. Совместно с этой комбинацией подмножество включает Как отмечалось, однозначное декодирование возможно только в том случае, когда названные подмножества не пересекаются. Так как общее число различных комбинаций n -значного двоичного кода составляет 2 n, число разрешенных комбинаций не может превышать
Эта верхняя оценка найдена Хэммингом. Для некоторых конкретных значений кодового расстояния d соответствующие Q указаны в табл.
Коды, для которых в приведенном соотношении достигается равенство, называют также плотноупакованными.
Блочные коды.
Построение конкретного корректирующего кода производят, исходя из требуемого объема кода Q, т. е. необходимого числа передаваемых команд или дискретных значений измеряемой величины и статистических данных о наиболее вероятных векторах ошибок в используемом канале связи. Вектором ошибки называют n -разрядную двоичную последовательность, имеющую единицы в разрядах, подвергшихся искажению, и нули во всех остальных разрядах. Любую искаженную кодовую комбинацию можно рассматривать теперь как сумму (или разность) по модулю 2 исходной разрешенной кодовой комбинации и вектора ошибки. Исходя из неравенства 2 k -1≥ Q (нулевая комбинация часто не используется, так как не меняет состояния канала связи), определяем число информационных разрядов k, необходимое для передачи заданного числа команд обычным двоичным кодом. Каждой из 2 k - 1 ненулевых комбинаций k -разрядного безызбыточного кода нам необходимо поставить в соответствие комбинацию из n символов. Значения символов в n -k проверочных разрядах такой комбинации устанавливаются в результате суммирования по модулю 2 значений символов в определенных информационных разрядах. Поскольку множество 2 k комбинаций информационных символов (включая нулевую) образует подгруппу группы всех n-разрядных комбинаций, то и множество 2 k n -разрядных комбинаций, полученных по указанному правилу, тоже является подгруппой группы n -разрядных кодовых комбинаций. Это множество разрешенных кодовых комбинаций и будет групповым кодом. Нам надлежит определить число проверочных разрядов и номера информационных разрядов, входящих в каждое из равенств для определения символов в проверочных разрядах. Разложим группу 2 n всех n -разрядных комбинаций на смежные классы по подгруппе 2 k разрешенных n-разрядных кодовых комбинаций, проверочные разряды в которых еще не заполнены. Помимо самой подгруппы кода в разложении насчитывается 2 n - k -1 смежных классов. Элементы каждого класса представляют собой суммы по модулю 2 комбинаций кода и образующих элементов данного класса. Если за образующие элементы каждого класса принять те наиболее вероятные для заданного канала связи вектора ошибок, которые должны быть исправлены, то в каждом смежном классе сгруппируются кодовые комбинации, получающиеся в результате воздействия на все разрешенные комбинации определенного вектора ошибки. Для исправления любой полученной на выходе канала связи кодовой комбинации теперь достаточно определить, к какому классу смежности она относится. Складывая ее затем (по модулю 2) с образующим элементом этого смежного класса, получаем истинную комбинацию кода. Ясно, что из общего числа 2 n -1 возможных ошибок групповой код может исправить всего 2 n - k -1 разновидностей ошибок по числу смежных классов. Чтобы иметь возможность получить информацию о том, к какому смежному классу относится полученная комбинация, каждому смежному классу должна быть поставлена в соответствие некоторая контрольная последовательность символов, называемая опознавателем (синдромом). Каждый символ опознавателя определяют в результате проверки на приемной стороне справедливости одного из равенств, которые мы составим для определения значений проверочных символов при кодировании. Ранее указывалось, что в двоичном линейном коде значения проверочных символов подбирают так, чтобы сумма по модулю 2 всех символов (включая проверочный), входящих в каждое из равенств, равнялась нулю. В таком случае число единиц среди этих символов четное. Поэтому операции определения символов опознавателя называют проверками на четность. При отсутствии ошибок в результате всех проверок на четность образуется опознаватель, состоящий из одних нулей. Если проверочное равенство не удовлетворяется, то в соответствующем разряде опознавателя появляется единица. Исправление ошибок возможно лишь при наличии взаимно однозначного соответствия между множеством опознавателей и множеством смежных классов, следовательно, и множеством подлежащих исправлению векторов ошибок. Таким образом, количество подлежащих исправлению ошибок является определяющим для выбора числа избыточных символов n - k. Их должно быть достаточно для того, чтобы обеспечить необходимое число опознавателей.
|
||||||||
|
|
Последнее изменение этой страницы: 2020-11-23; просмотров: 245; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.11 (0.01 с.) |

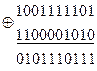 ,
,  (4)
(4)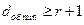 . (5)
. (5)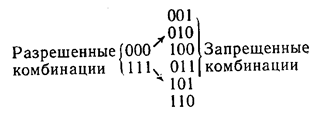
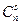 запрещенных кодовых комбинаций.
запрещенных кодовых комбинаций.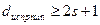 . (6)
. (6)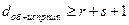 . (7)
. (7)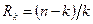 . (9)
. (9)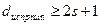 .
.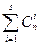 .
.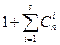 комбинаций.
комбинаций.