Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Часть 1. Общая теория статистикиСтр 1 из 21Следующая ⇒
ВВЕДЕНИЕ
Курс «Статистика» имеет целью дать представление о содержании статистики как научной дисциплины, познакомить с ее основными понятиями, методологией и методикой расчета важнейших статистических аналитических показателей. В результате изучения дисциплины «Статистика» вы будете Ø знать: методы обработки результатов статистического наблюдения; обобщающие статистические показатели – абсолютные и относительные статистические величины; средние (простые и взвешенные средние; арифметические, гармонические и другие степенные средние; структурные средние); показатели вариации; методы обработки и анализа динамических рядов данных, взаимосвязи, основы анализа статистических данных; Ø уметь: строить статистические таблицы и графики (диаграммы, гистограммы, линейные графики), вычислять различные статистические показатели (абсолютные и относительные статистические величины; степенные средние; структурные средние; показатели вариации); анализировать статистические данные и формулировать выводы, вытекающие из анализа данных. Для закрепления теоретических знаний курса в методическом пособии приведены практические задания в объеме одной контрольной работы и пример ее выполнения.
ЧАСТЬ 1. ОБЩАЯ ТЕОРИЯ СТАТИСТИКИ СТАТИСТИКА КАК НАУКА: ПРЕДМЕТ, МЕТОДОЛОГИЯ, ЗАДАЧИ
Структура статистической науки
Задача общей теории статистики – разработка общих принципов и методов статистического исследования. Задача экономической статистики – разработка и анализ показателей, отражающих состояние экономики в целом, взаимосвязь отраслей, наличие и особенности размещения материальных, трудовых и финансовых ресурсов, достигнутый уровень их использования. Задача отраслевой экономической статистики (статистики промышленности, сельского хозяйства, строительства, транспорта, связи, труда, природных ресурсов и др.) – разработка и анализ статистических показателей развития соответствующей отрасли экономики. Задача социальной статистики – формирование системы показателей для характеристики образа жизни населения и различных аспектов социальных отношений, статистика народонаселения, политики, культуры, здравоохранения, права и т.д.).
Отраслевые статистики формируются на базе показателей экономической и социальной статистики, которые основываются на категориях и методах анализа, разработанных общей теории статистики.
СТАТИСТИЧЕСКОЕ НАБЛЮДЕНИЕ
ГРУППИРОВКА СТАТИСТИЧЕСКИХ ДАННЫХ
Виды и задачи группировок
Одним из основных и наиболее распространенных методов обработки и анализа первичной статистической информации является группировка. Группировкой называют разбиение совокупности на группы, однородные по какому-либо признаку. В процессе исследования метод группировок позволяет по отдельным признакам и комбинациям признаков выявить закономерности и взаимосвязи явлений, проследить взаимоотношение различных факторов и определить силу их влияния на результативные показатели. Метод группировки основывается на двух категориях – группировочном признаке и интервале. Группировочный признак – это признак, по которому происходит объединение отдельных единиц совокупности в однородные группы. Интервал очерчивает количественные границы групп. Интервалы бывают: равные (разность между максимальным и минимальным значениями в каждом из интервалов одинакова) и неравные, открытые (имеется только либо верхняя, либо нижняя граница) и закрытые (имеется и верхняя, и нижняя границы). Классифицировать группировки можно следующим образом: 1. В зависимости от цели: Ø типологическая - для выделения качественно однородных совокупностей; Ø структурная - для изучения структуры совокупности; Ø аналитическая (факторная) - для исследования существующих зависимостей. 2. В зависимости от числа положенных в основание группировок признаков: Ø простые - группировка по одному признаку; Ø сложные -группировка по нескольким признакам. Сложные группировки подразделяются на многомерные (группировка осуществляется одновременно по комплексу признаков) и комбинационные (группы, выделенные по одному из признаков, затем подразделяются на подгруппы по другому признаку). 3. По отношению между признаками:
Ø иерархические - выполняются по двум и более признакам, при этом значения второго признака определяются областью значений первого (например, классификация отраслей промышленности по подотраслям); Ø неиерархические строятся когда строгой зависимости значений второго признака от первого не существует. 4. По виду признака: Ø количественные – признак выражается числом; Ø качественные – признак отражает определенные свойства и записывается в виде текста. Эти группировки, в свою очередь, можно разделить на атрибутивные (отдельные единицы совокупности различаются своим содержанием, например, профессии) и альтернативные (существует два противоположных по значению варианта признака, например, да и нет, или годная и бракованная продукция).
Статистические таблицы Результаты группировок представляются в статистических таблицах. Значение таблиц определяется тем, что они позволяют изолированные статистические данные рассматривать совместно, достаточно полно и точно охватывая сложную природу явлений.
По построению подлежащего таблицы можно разделить на: 1. простые – таблицы, в подлежащем которых нет группировок. Простые таблицы бывают: перечневые (подлежащее – перечень единиц, составляющих объект изучения). Ø территориальные (дается перечень территорий, стран, областей и т.д.); Ø хронологические (подлежащем приводятся периоды или даты); Простая таблица может выглядеть следующим образом:
2. групповые – таблицы, в подлежащем которых изучаемых объект разделен на группы по какому-либо признаку. Например:
3. комбинационные – таблицы, в которых совокупность разделяется на группы не по одному, а по нескольким признакам. Например:
По построению сказуемого таблицы также можно разделить на простые и сложные. Простая разработка сказуемого предусматривает параллельное расположение показателей, а сложная – комбинированное. Практикой выработаны определенные требования к составлению и оформлению таблиц: 1. Таблица по возможности должна быть краткой. Не следует загружать ее излишними подробностями, затрудняющими анализ явлений. 2. Каждая таблица должна иметь название, из которого становится известно: Ø Какой круг вопросов излагает и иллюстрирует таблица; Ø Каковы географические границы статистической совокупности, представленной таблицей; Ø Каковы единицы измерения (если они одинаковы для всех табличных клеток). Если единицы измерения неодинаковы, то в заголовках обязательно следует указывать, в каких единицах приводятся статистические даны.
3. В таблице желательно давать нумерацию граф. Это облегчает пользование таблицей, дает возможность лучше ориентироваться, показывает способ расчета цифр в графах. Заглавия строк подлежащего и сказуемого должны быть сформулированы точно, кратко и ясно. 4. Приводимые в подлежащем и сказуемом признаки должны быть расположены в логическом порядке с учетом необходимости рассматривать их совместно. 5. Таблица может сопровождаться примечаниями, в которых указывают источники данных и даются необходимые пояснения. 6. При оформлении таблиц обычно применяют следующие условные обозначения: Ø Знак тире (-) – когда явление отсутствует; Ø X – если явление не имеет осмысленного содержания; Ø Многоточие (…) – когда отсутствуют сведения о его размере (или делается запись «нет сведений»). 7. Округленные числа приводятся в таблице с одинаковой степенью точности.
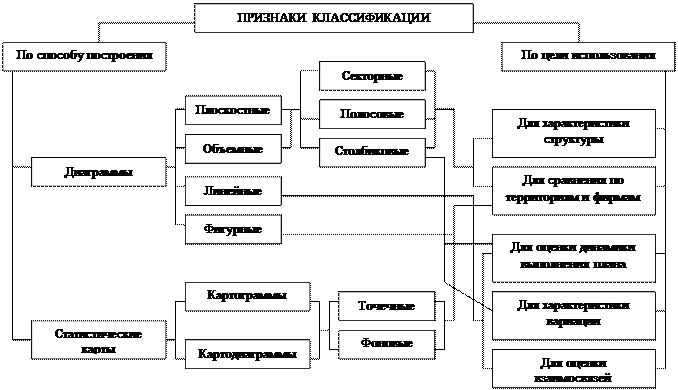
Статистические графики Графиками в статистике называют условные изображения числовых величин и их соотношений в виде различных геометрических образов – точек, линий, плоских фигур и т.д. Использование графиков для изложения статистических показателей позволяет придать последним наглядность и выразительность, облегчает их восприятие, а во многих случаях позволяет уяснить сущность изучаемого явления. Каждый график включает графический образ (т.е. вида графического изображения); пол графика (пространства, в котором размещаются геометрические знаки), масштабные ориентиры (придают геометрическим знакам количественную определенность) и систему координат. Классификация графиков по признакам представлена на рис.2.
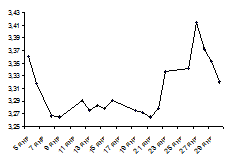
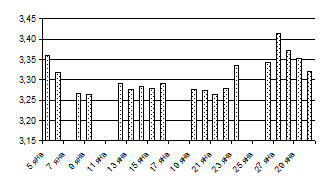
Линейные диаграммы применяются для характеристик динамики; для характеристик вариации в рядах распределения. Строятся в прямоугольной системе координат. На рисунке приведена линейная диаграмма курса немецкой марки за январь 1998 года.
Рис.2. Классификация графиков
Для тех же целей могут использоваться столбиковые диаграммы. Столбики располагаются вплотную или на одинаковом расстоянии, имеют одинаковое основание, а их высота пропорциональна числовым значениям уровня признака. На рисунке приведена столбиковая диаграмма немецкой марки за январь 1998 года.
Полосовая диаграмма является разновидностью столбиковой. Для нее характерна горизонтальная ориентация столбиков и вертикальное расположение базовой линии.
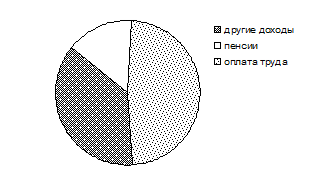
Секторная диаграмма служит для характеристики структуры явления. Для построения этой диаграммы круг следует разделить на секторы пропорционально удельному весу частей в целом. 1% соответствует 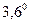 . Для того, чтобы секторы были более наглядны, следует пользоваться штриховкой. Секторная диаграмма, изображенная на рисунке, характеризует денежные доходы населения в 1994 году. . Для того, чтобы секторы были более наглядны, следует пользоваться штриховкой. Секторная диаграмма, изображенная на рисунке, характеризует денежные доходы населения в 1994 году.
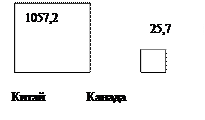
Фигурные диаграммы отражают размер изучаемого объекта в соответствии с размером своей площади. Недостатком их следует считать некоторую неточность, связанную с необходимостью округления изображаемых показателей. Например, квадратные и круговые диаграммы. Для построения квадратной диаграммы следует извлечь корни из сравниваемы величин статистических показателей, а затем построить квадраты со сторонами, пропорциональными полученным результатам. При построении круговой диаграммы значения показателей вначале делят на 3,14, а затем из полученных величин извлекают квадратные корни. На рисунке при помощи квадратной диаграммы отображена численность населения Китая и Канады в 1986 году.
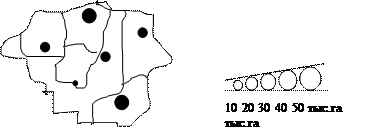
различных территориях. На точечной диаграмме каждой точке соответствует одно и то же принятое числовое значение. Нанося на контур каждого района соответствующее количество точек, получаем точечную картограмму. Картодиаграмма представляет собой сочетание диаграммы с географической картой.
СТАТИЧЕСКИЕ ВЕЛИЧИНЫ Средние величины Средняя величина – это обобщающий показатель, характеризующий типический уровень явления. Он выражает величину признака, отнесенную к единице совокупности. Средняя всегда обобщает количественную вариацию признака, т. е. в средних величинах погашаются индивидуальные различия единиц совокупности, обусловленные случайными обстоятельствами. В отличии от средней абсолютная величина, характеризующая уровень признака отдельной единицы совокупности, не позволяет сравнивать значения признака у единиц, относящихся к разным совокупностям. Средняя, рассчитанная по совокупности в целом, называется общей средней; средние, исчисленные для каждой группы – групповыми средними. Общие принципы применения средних величин: 1. При определении средней величины в каждом конкретном случае нужно исходить из качественного содержания усредняемого признака, учитывать взаимосвязь изучаемых признаков, а также имеющиеся для расчета данные.
2. Средняя величина должна прежде всего рассчитываться по однородной совокупности. Качественно однородные совокупности позволяет получить метод группировок, который всегда предполагает расчет системы обобщающих показателей. 3. Общие средние должны подкрепляться групповыми средними. Например, допустим, что анализ динамики урожайности отдельной культуры показывает, что общая урожайность снижается. Однако, сгруппировав районы по признакам различия и проанализировав динамику групповых средних, можно обнаружить, что в отдельных группах районов средняя урожайность не изменилась, либо возрастает, а снижение общей средней в целом обусловлено ростом удельного веса районов с низкой урожайностью в общем производстве этой культуры. 4. Необходим обоснованный выбор единицы совокупности, для которой рассчитывается средняя.
простые взвешенные мода медиана
.
Остановимся на степенных средних. Простая средняя считается по несгруппированным данным и имеет следующий общий вид:
где m — показатель степени средней; n — число вариант. Взвешенная средняя считается по сгруппированным данным и имеет общий вид;
где m — показатель степени средней;
Общие формулы расчета степенных средних имеют показатель степени (m). В зависимости от того, какое значение он принимает, различают следующие виды степенных средних:
Если рассчитать все виды средних для одних и тех же исходных данных, то значения их окажутся неодинаковыми. Здесь действует правило мажорантности средних: с увеличением показателя степени m увеличивается и соответствующая средняя величина:
В статистической практике чаще, чем остальные виды средних взвешенных, используются средние арифметические и средние гармонические взвешенные.
Рассмотрим для примера расчет средней арифметической и средней арифметической взвешенной для ряда:
Простая средняя арифметическая:
Сгруппировав данные, получаем:
Теперь можно определить взвешенную среднюю арифметическую:
Средняя арифметическая величина обладает рядом свойств, которые определяют ее широкое применение в экономических расчетах и практике статистического исследования: 1. Средняя арифметическая постоянной величины равна этой постоянной: 2. Сумма положительных отклонений от средней равна сумме отрицательных отклонений. 3. Сумма квадратов отклонений индивидуальных значений признака каждой единицы совокупности от средней арифметической есть число минимальное:
Структурные средние Особый вид средних величин – структурные средние – применяется для изучения внутреннего строения рядов распределения значений признака, а также для оценки средней величины (степенного типа), если по имеющимся статическим данным ее расчет не может быть выполнен. Медиана – значение признака, которое делит единицы ранжированного ряда на две части. В итоге у одной половины единиц совокупности значение признака не превышает медианного, а у другой – не меньше его.
Расчет медианы по несгруппированным данным рассмотрим на примере ряда: 4500, 4560, 4540, 4535, 4550, 4500, 4560, 4570, 4560, 4560, 4570,4500. Для определения значения медианы: 1.расположим индивидуальные значения признака в возрастающем порядке: 4500, 4500, 4500, 4535, 4540, 4550, 4560, 4560, 4560, 4560, 4570, 4570. 2.определим порядковый номер медианы по формуле: При нечетном числе индивидуальных значений медиана вычисляется аналогичным образом. Например, при числе данных, равным 15, Мода – наиболее часто встречающееся значение признака у единиц данной совокупности. Для рассмотренного выше ряда мода равна 4560, так как это значение повторяется четыре раза, чаще, чем другие. Методология расчета моды и медианы по сгруппированным данным будет рассмотрена в главе 5.
Показатели вариации Для измерения вариации используют абсолютные и относительные показатели. Абсолютные показатели: 1. Размах вариации (размах колебаний) – разность между максимальным и минимальным значениями признака в совокупности:
2. Среднее линейное отклонение: Ø Для несгруппированных данных: Ø Для сгруппированных данных (вариационного ряда):
3. Дисперсия Ø Для несгруппированных данных: Ø Для сгруппированных данных:
4. Среднее квадратическое отклонение равен квадратному корню из дисперсии, т.е.
5. Квартильное отклонение: Квартили – это значения признака в ранжированном ряду распределения, выбранные таким образом, что 25% единиц совокупности будут меньше по величине
Размах вариации, среднее линейное и средне квадратичное отклонение являются величинами именованными, они имеют те же единицы измерения, что и индивидуальные значения признака. Расчет показателей вариации для банков, сгруппированных по размеру прибыли, показан табл.3
Таблица 3
Для этой вариации:
При сравнении колеблемости различных признаков в одной и той же совокупности или же при сравнении одного и того же признака в нескольких совокупностях с различной величиной средней арифметической пользуются относительными показателями вариации: 1. Коэффициент осцилляции 2. Относительное линейное отклонение 3. Коэффициент вариации 4. Относительный показатель квартильной вариации
Для таблицы 2 относительные показатели вариации получились следующими:
ВЫБОРОЧНОЕ НАБЛЮДЕНИЕ Ошибка выборки После отбора единиц проводится расчет обобщающих выборочных характеристик: выборочной средней ( Разность между показателями выборочной и генеральной совокупности называется ошибкой выборки. Ошибки выборки подразделяются на: Ø Ошибки регистрации, которые возникают из-за неправильных или неточных сведений. Среди ошибок регистрации выделяют систематические (обусловленные причинами, действующими в одном направлении и искажающими результаты работы) и случайные (проявляющиеся в различных направлениях, уравновешивающие друг друга и лишь изредка дающие заметный суммарный эффект). Ø Ошибки репрезентативности также бывают случайные (означают, что, несмотря на принцип случайности отбора единиц, все же имеются расхождения между характеристиками выборочной и генеральной совокупности) и систематическими (возникающие из-за неправильного отбора единиц, при котором нарушается принцип случайности).
Рассмотрим на примере, насколько отличаются выборочные и генеральные показатели по данным об успеваемости студентов (две 10%-е выборки):
Средний балл рассчитаем как среднюю арифметическую взвешенную. по генеральной совокупности:
для первой выборки: для второй: Доля студентов, получивших оценки «4» и «5»: по генеральной совокупности:
по первой выборке: по второй выборке: Разность между показателями выборочной и генеральной совокупности и будет случайной ошибкой репрезентативности. Ошибки репрезентативности:
Как видно из расчетов, ошибки выборки также являются случайными величинами и могут принимать различные значения. Средняя ошибка выборки Таблица 4
Условные обозначения: N –объем генеральной совокупности; n - объем выборки;
W – выборочная доля.
Величину
Так, если t=1, то с вероятностью 0,683 можно утверждать, что разность между выборочными и генеральными показателями не превысит одной средней ошибки. После исчисления предельных ошибок выборки находят доверительные интервалы для генеральных показателей. Для
Выборки, содержащие менее 30 единиц, называются малыми. При изучении таких выборок методы оценки результатов выборочного наблюдения видоизменяются в сравнении с применяемыми в теории больших выборок. Для оценки возможных пределов ошибки в этом случае используется метод Стьюдента. Он заключается в следующем: Ø определяется выборочная средняя Ø определяется выборочная дисперсия Ø рассчитывается средняя квадратическая ошибка выборки
Ø с требуемой вероятностью P, зная число степеней свободы k=n- 1, определяют величину отношения Стьюдента t по таблице. Краткая выдержка из таблицы выглядит следующим образом:
Ø полученную величину соотношения t умножают на среднюю квадратическую ошибку выборки Ø результат представляется в виде
Рассмотрим этот алгоритм нахождения на примере ряда 10,2; 7,6; 6,1; 8,4; 6,0; 5,7; 13,7; 6,9; 5,2; 6,1; 5,0; 3,7; 4,7; 3,6; 3,2. Выборочная средняя составляет 6,41 ( выборочная дисперсия равна: Следовательно, средняя квадратическая ошибка выборки:
Оценим с вероятностью 0,99 предел возможных расхождений выборочной средней и генеральной средней. Так как число степеней свободы равно 14 (k = n -1=15-1=14), то по таблице, приведенной выше, находим, что значение t, соответствующее вероятности 0,99, равно 2,977. Тогда с вероятностью 0,99 можно предполагать, что ошибка выборочной средней не больше 2,114 (2,977*0,71). Результат выглядит как:
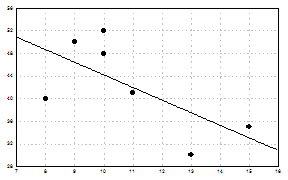
Уравнение регрессии Задачи регрессионного анализа лежат в сфере установления формы зависимости, определения функции регрессии, использования уравнения для оценки неизвестных значений зависимой переменной. Приблизительное представление о линии связи можно получить на основе эмпирической линии регрессии. Эта линия строится по групповым средним. Она обычно является ломаной линией. Эмпирическая линия связи служит для выбора и обоснования типа теоретической линии регрессии. Теоретической линией регрессии называется та линия, вокруг которой группируются точки корреляционного поля и которая указывает основное направление, основную тенденцию связи. В случае парной линейной зависимости уравнение регрессии записывается так:
где Параметры
т.е. сумма квадратов отклонений эмпирических значений зависимой переменной от вычисленных по уравнению должна быть минимальной. Ее минимизация осуществляется решением системы уравнений:
Смысл параметров заключается в следующем: Параметр
Для нашего примера (таблица 6) уравнение регрессии имеет вид: Y=66,492-2,23X. Коэффициент
На рисунке представлены корреляционное поле по данным таблицы 6 и теоретическая линия регрессии:
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2020-12-17; просмотров: 66; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.138.137.127 (0.181 с.) |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||




 Средние величины
Средние величины


 степенные структурные
степенные структурные
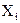 — варианта (значение) усредняемого признака;
— варианта (значение) усредняемого признака;
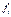 — частота, показывающая, сколько раз встречается i -е значение усредняемого признака.
— частота, показывающая, сколько раз встречается i -е значение усредняемого признака.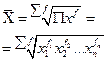
 m=x f
m=x f
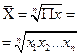


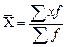
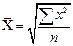
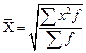

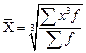
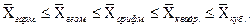
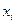 - 3,4; 5,6; 5,6; 4,5; 3,4; 7,9; 5,6; 7,5; 4,5; 6,3.
- 3,4; 5,6; 5,6; 4,5; 3,4; 7,9; 5,6; 7,5; 4,5; 6,3.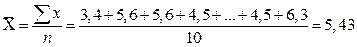
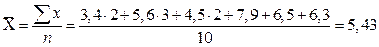
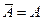 при А =const.
при А =const.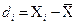 - линейные (индивидуальные) отклонения от средней. Алгебраическая сумма линейных отклонений (разностей) индивидуальных значений признака от средней арифметической равна нулю:
- линейные (индивидуальные) отклонения от средней. Алгебраическая сумма линейных отклонений (разностей) индивидуальных значений признака от средней арифметической равна нулю:  для первичного ряда и
для первичного ряда и 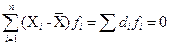 для сгруппированных данных.
для сгруппированных данных.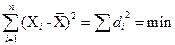 .
. . В нашем случае
. В нашем случае 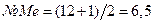 . Это означает, что медиана расположена в данном случае между шестым и седьмым значениями в ранжированном ряду. Следовательно, Ме=(4550+4560)/2=4555.
. Это означает, что медиана расположена в данном случае между шестым и седьмым значениями в ранжированном ряду. Следовательно, Ме=(4550+4560)/2=4555.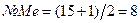 .
.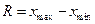 . Размах вариации зависит только от крайних значений признака, поэтому область его применения ограничена однородными совокупностями.
. Размах вариации зависит только от крайних значений признака, поэтому область его применения ограничена однородными совокупностями.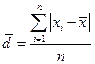 ;
;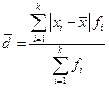 .
.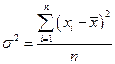 ;
;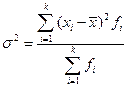 .
.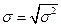 .
.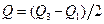 .
.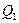 ; 25% будут заключены между
; 25% будут заключены между 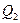 ; 25%- между
; 25%- между 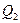 и
и 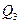 ; остальные 25% превосходят
; остальные 25% превосходят 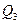 . Квартили определяются:
. Квартили определяются: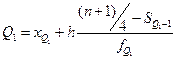 и
и 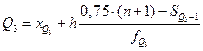 .
.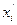
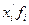
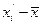
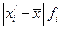
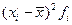
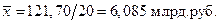 ;
;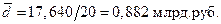 ;
; ;
;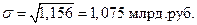
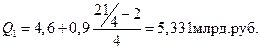 ;
;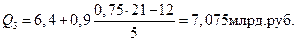
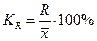 ;
;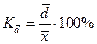 ;
;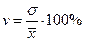 . Совокупность считается однородной, если коэффициент вариации не превышает 33%.
. Совокупность считается однородной, если коэффициент вариации не превышает 33%. или
или 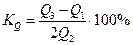 .
.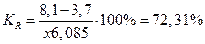
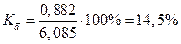
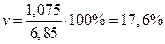
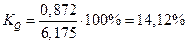
 ) и выборочной доли (W) единиц, обладающих каким-либо интересующим нас признаком, в общей доли их численности.
) и выборочной доли (W) единиц, обладающих каким-либо интересующим нас признаком, в общей доли их численности.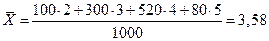 ;
;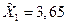 ;
; .
. ;
;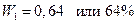 ;
;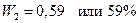 .
.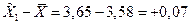 ;
;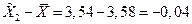 ;
;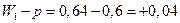 ;
;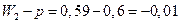 .
.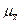 определяется по формулам таблицы 4.
определяется по формулам таблицы 4.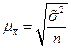
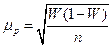
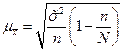
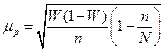
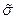 - дисперсия выборочной совокупности;
- дисперсия выборочной совокупности;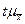 называют предельной ошибкой выборки. Обозначив предельную ошибку выборки
называют предельной ошибкой выборки. Обозначив предельную ошибку выборки 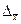 , получим:
, получим: 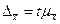 , т.е. предельная ошибка выборки равна t -кратному числу средних ошибок выборки. Аналогично определяется предельная ошибка доли:
, т.е. предельная ошибка выборки равна t -кратному числу средних ошибок выборки. Аналогично определяется предельная ошибка доли: 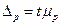 .величина нормированного отклонения. Значения t даются в таблицах нормального распределения вероятностей. Чаще всего используются следующие сочетания:
.величина нормированного отклонения. Значения t даются в таблицах нормального распределения вероятностей. Чаще всего используются следующие сочетания: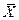 это
это 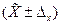 , для P это
, для P это 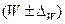 .
.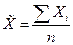 ;
;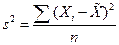 ;
; ;
; P
K
P
K
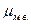 , в результате чего получают ошибку выборочной средней
, в результате чего получают ошибку выборочной средней 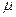 .
.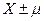 .
. );
);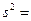 7,061.
7,061. .
.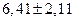
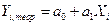 ,
,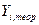 -рассчитанное выровненное значение результативного признака после подстановки в уравнение X.
-рассчитанное выровненное значение результативного признака после подстановки в уравнение X.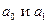 оцениваются с помощью процедур, наибольшее распространение из которых получил метод наименьших квадратов. Его суть заключается в том, что наилучшие оценки
оцениваются с помощью процедур, наибольшее распространение из которых получил метод наименьших квадратов. Его суть заключается в том, что наилучшие оценки 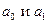 получаются, когда:
получаются, когда: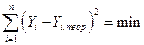 ,
,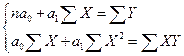
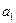 - коэффициент регрессии. При наличии прямой корреляционной связи он имеет положительное значение, при наличии обратной связи он имеет отрицательное значение.
- коэффициент регрессии. При наличии прямой корреляционной связи он имеет положительное значение, при наличии обратной связи он имеет отрицательное значение. 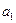 показывает, насколько единиц в среднем изменится Y при изменении X на одну единицу.
показывает, насколько единиц в среднем изменится Y при изменении X на одну единицу. -постоянная величина, экономического смысла не имеет.
-постоянная величина, экономического смысла не имеет.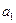 =-2,23 означает, что изменение X на единицу приведет к уменьшению Y в среднем на 2,23 единиц.
=-2,23 означает, что изменение X на единицу приведет к уменьшению Y в среднем на 2,23 единиц.