Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Определение понятия «лингвистическое обеспечение»Содержание книги
Похожие статьи вашей тематики
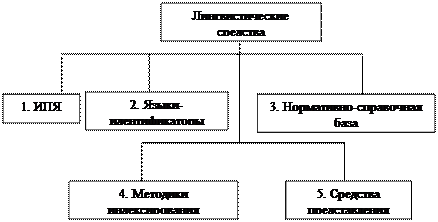
Поиск на нашем сайте В литературе по информатике накопилось значительное количество различных подходов к понятию «лингвистическое обеспечение» (далее ЛО) и, соответственно, различных определений этого понятия (или близких понятий «информационно-поисковые языки», «языковые средства АИС» и др.). Кратко рассмотрим основные подходы. Наиболее распространенным является классический подход, при котором лингвистическим обеспечением называют комплекс информационно-поисковых языков, прежде всего, классификационных и вербальных (дескрипторных). Этот подход ведет свое начало от классического труда «Основы информатики» и типичен для разработчиков систем, которые обычно относят к НТИ. С небольшими изменениями этот подход принят и в теории автоматизированных библиотечно-информационных систем (АБИС), в которой, однако, в понятие ЛО часто включают и языки библиографических данных. Существует подход, который можно назвать «лингвистическим», поскольку он органически вытекает из лингвистического взгляда на информационные системы и который развивают в основном специалисты по прикладной и компьютерной лингвистике. В соответствии с этим подходом лингвистическое обеспечение – это комплекс средств, используемых для автоматической обработки текстов на естественном языке (включая обработку запросов и поиск), т. е. прежде всего, языковых процессоров. Более общим является подход, который следует определить как «семиотический», поскольку он исходит из классических семиотических представлений о языке как системе знаков разного уровня, начиная, естественно, с алфавита. При этом подходе лингвистическое обеспечение АИС определяется как «средства представления информации в виде данных и интерпретации этих данных». При этом подходе в состав ЛО нужно, например, включать средства кодировки алфавитов или форматы представления данных, но не нужно включать инструментальные языки программирования, в частности процедурные средства разметки. Иногда в литературе можно встретить представление об языковых средствах, которое можно назвать «программистским». Сторонники такого подхода опираются на полисемию термина «язык», который, как известно, может обозначать в информационной литературе не только средства представления данных, но и средства манипулирования данными, включая инструментальные средства программирования и другие формальные системы. К тому же среди средств манипулирования данными, в результате развития в последние годы, появляются языки высокого уровня, которые все ближе к тому, что можно назвать формализованным естественным языком и все дальше от обычного представления от обычных инструментальных средств. Таковы, например, языки разметки типа SGML или XML. При «программистском» взгляде в составе ЛО могут оказаться вообще все языковые средства пользователя, причем несущественно, носят ли они характер языков описания данных, представления данных или манипулирования данными. Наконец, можно отметить подход, зафиксированный в нормативных документах по АСУ (группа ГОСТ 34), в которых разделяются информационное и лингвистическое обеспечение. При этом основной тип ИПЯ этих систем – классификаторы, а также форматы данных – эти нормативные документы относят к информационному обеспечению, а на долю лингвистического обеспечения остается только правила оформления естественно-языковых единиц этих классификаторов, т. е. чисто лексикографические аспекты. Изложенные различия в подходах во многом определяются разными характеристиками АИС и электронных библиотек (ЭБ), для которых создаются соответствующие языковые средства, включая их тип, характер обрабатываемой в ней информации, а также разделение функций между системой и пользователями. Несколько слов о терминологии в отношении собственно информации, вводимой в АИС и служащей объектом для использования языковых средств. Традиционно основным термином для обозначения информационных объектов АИС был термин «документ». В последнее время распространился термин «информационный ресурс» и даже «электронный ресурс». Однако слово «ресурс» в русском языке имеет явно выраженную коннотацию несчетности, поэтому использовать его для обозначения конкретных и идентифицируемых объектов стилистически неудобно. (Нельзя сказать по-русски «восемь ресурсов».) С другой стороны, далеко не всегда интересующие нас объекты являются документами в строгом смысле этого слова. Это могут быть, например, сервера, сайты, адреса, термины, имена, фрагменты документов и др. Наконец, нас интересуют только объекты, вводимые в АИС и, следовательно, представленные в электронном (цифровом) виде. Что же касается множеств цифровых объектов, собственно и образующих информационное наполнение ЭБ, то для него в принципе можно использовать термин «информационные ресурсы». Однако этот термин в соответствии с законом «Об информации, информатизации и защите информации» обозначает более общее понятие, включающее как отдельные документы, так и множества документов. Поэтому для организованных множеств цифровых объектов (таких как базы данных, файловые системы, сайты, электронные библиотеки и музеи, хранилища данных) будет использоваться термин «информационные массивы». Как уже отмечалось, наиболее строгое определение ЛО основано на семиотическом подходе и на представлении о ЛО как языке представления данных. Однако опыт показывает, что реальное распределение функций между постановщиками задач ЭБ, а также разработчиками программного и лингвистического обеспечения таково, что строгое семиотическое определение практически неудобно. С одной стороны, при строгом определении в понятие ЛО необходимо включать объекты, которыми традиционно занимаются программисты, такие как системы кодировок, формальные языки запросов или языки разметки. В современных ЭБ к средствам представления данных также относятся языки представления графики, картографии, аудиоинформации, трехмерных и движущихся объектов и других нетекстовых данных. Эти средства всегда были крайне далеки от интересов разработчиков ЛО ЭБ. С другой стороны, в область интересов информационных лингвистов (разработчиков ЛО ЭБ), всегда входили не только языковые средства представления данных, но также средства обработки текстов на естественном языке, то есть лингвистические процессоры. Поэтому если попытаться определить ЛО, как объект интересов именно этого класса специалистов, то в него следует включить, во-первых, только семантические средства представления данных, во-вторых, кроме них также лингвистические процессоры, применяемые в ЭБ. Лингвистические процессоры – это достаточно широкий класс продуктов. В него включают, например, спеллеры, текстовые редакторы, системы морфологического и синтаксического анализа и синтеза текстов, системы автоматического перевода, различные системы компьютерной лексикографии и др. Для наших целей мы будем рассматривать те процессоры, которые, во-первых, применяются в ЭБ, а во-вторых, ориентированы на обработку семантических языковых единиц (морфем, слов, словосочетаний), а также высших уровней языка (предложений, сверхфразовых единств). Данные, вводимые в ЭБ, могут быть формализованы, например, в виде таблиц, математических или химических формул или других специализированных подъязыков. За редкими исключениями, и мы не будем рассматривать средства представления данных этого типа, который относится к хорошо структурированной информации. Существует еще один класс АИС, средства представления данных для которых, безусловно, следует отнести к средствам ЛО. Это АИС, специализирующиеся на обработке, представлении, поиске и синтезе устной (звучащей) речи. Однако АИС этого типа в состав ЭБ в настоящее время не включаются. Поэтому предлагаемое ниже определение ЛО не претендует на теоретическую чистоту и рассчитано сугубо на практическое применение. Лингвистическое обеспечение ЭБ – комплекс языковых средств и процессоров, предназначенных для обработки, представления и поиска письменных текстов на естественном языке, в основном на семантическом уровне. Классификация средств ЛО Исходя из изложенного, средства, входящие в состав ЛО, целесообразно разделить на 2 класса. К одному классу относятся языки, предназначенные непосредственно для представления данных в ЭБ. Именно для этого класса языковых средств корректно применять широко распространенный термин «информационно-поисковые языки» (ИПЯ). Эти языки достаточно естественно классифицируются в зависимости от уровня отображения информации, представленной в цифровых объектах. Таких уровней можно выделить четыре: 1. Отображение цифрового объекта в целом, включая его формальные характеристики. 2. Отображение тематики или содержания цифрового объекта. 3. Отображение семантики единиц естественного языка, содержащихся в цифровом объекте. 4. Отображение фактов, содержащихся в цифровом объекте. Для цифровых объектов типа документов первому уровню отображения соответствуют языки описания документов, весьма детально разработанные в традиционных областях информационной деятельности: библиотековедении, архивном деле, делопроизводстве, картографии и др.Самый известный тип этих языков образуют языки библиографических данных, включающие правила библиографического описания и форматы библиографической записи. В настоящее время происходит активная интеграция языков библиографических данных с языками, применяющимися для описания других видов цифровых объектов. Особенно активно этот процесс развивается в Интернете. Общее название для языков, предназначенных для комплексного описания цифровых объектов – системы метаданных. На втором уровне отображения используются языки классификационного или предкоординатного типа, также имеющие большую историческую традицию. Принципиальным свойством этих языков является разбиение множества цифровых объектов на классы, описанные при помощи априорного связывания (предкоординации) поисковых признаков этих классов, чаще всего, в виде иерархического дерева. Судьбы языков этого типа с учетом перспектив глобальных информационных сетей вызывают оживленные дискуссии, в связи с их имманентными недостатками, главный из которых – необходимость интеллектуального индексирования. При этом классификационные языки обладают заметными преимуществами перед другими типами поисковых языков, прежде всего наглядностью, простотой для пользователя и независимостью от естественного языка. В настоящее время классификационные языки являются обязательным компонентом практически всех АИС рассматриваемого класса. Новым типом языковых средств, появившимся только в рамках автоматизированных систем в 1950-х гг. XX века, являются языки, ориентированные на использование в качестве лексики единиц естественного языка. Поэтому вполне адекватное название этой группы языков – вербальные языки.Однако наиболее распространенное название этих языков – дескрипторные, в соответствии с названием общепринятой формы представления лексических единиц этих языков (дескрипторов). Иногда эти языки также называют посткоординатными, подчеркивая противопоставление с классификационными языками по базовой функции – способу отражения информации текста. Если в классификационных языках используется априорное связывание поисковых признаков, то в дескрипторных языках признаки связываются непосредственно в цифровом объекте (посткоординация). Большое развитие, по крайней мере, в АИС НТИ получили языки, ориентированные на представление и поиск фактов, содержащихся в документах. Этот класс языков находится на стыке АИС типа «электронной библиотеки» и АИС типа «банк данных». Поскольку основной и чуть ли не единственный тип фактов, которые удается автоматически извлекать из плохо структурированной информации – это факты типа «объект – признак – значение», постольку языки данного класса принято именовать «объектно-признаковыми». Иногда их также называют фактографическими или объектографическими. Следует иметь в виду, что такая терминология принята почти исключительно среди специалистов электронных библиотек, иначе говоря, специалистов по поиску слабоструктурированной информации. В других направлениях информатики, прежде всего в теории систем управления базами данных, эти средства именуют «моделями данных», языками описания данных и др. Однако в теории СУБД принято иметь дело в основном с хорошо структурированной информацией. В настоящее время теоретики в этой сфере активно обсуждают проблему взаимодействия различных языков данного класса в рамках интегрированных электронных библиотек. Эта проблема получила название проблемы «интероперабельности». Кроме языковых средств для поиска используются другие средства как языковые, так и неязыковые. Сюда можно отнести весьма многочисленные, но не слишком успешные методы поиска, основанные на анализе статических свойств текста и запроса, методы поиска, использующие сведения о пользователе, поиск по аналогии и т. д. Весьма распространенным методом при поиске в Интернет в последние годы стало использование данных о распределении гипертекстовых ссылок. Рассмотренные выше языковые средства имеют некоторую общую часть, представленную в интерфейсе пользователя с АИС. Это операторы и синтаксические правила, которые непосредственно применяются при составлении запросов. Эти средства естественно рассматривать отдельно от конкретных типов языков, поскольку в любом сколько-нибудь дружественном интерфейсе пользователя язык запросов интегрирует средства различных ИПЯ – библиографических, классификационных и вербальных. Эти средства обычно называются языками запросов. Все перечисленные выше виды языковых средств можно с большей или меньшей степенью условности назвать языками. Однако, определив некоторый объект как язык, мы должны уметь выделять в его составе обязательные для любого языка компоненты. В любом языке выделяются знаковые единицы трех уровней: • алфавит – т. е. множество допустимых символов; • лексика – множество семантически интерпретированных знаков; • тексты (дискурс) – семантически интерпретированные знаковые единицы речи. В любом языке также выделяются два класса правил (грамматики): • морфология – правила образования и изменения лексических единиц; • синтаксис – правила образования текстов. Семантически интерпретированные знаковые единицы языка (лексика и тексты) согласно семиотическим представлениям обладают тремя типами отношений (свойств): • синтактика – отношения между знаками; • семантика – отношение знака к означаемому (денотату); • прагматика – отношение знака к участнику дискурса. В теории и практике ЛО ЭБ эта схема обычно модифицируется. Алфавиты в большинстве случаев определяются программно-технологическими возможностями ЭБ и объектом проектирования в составе ЛО не являются. Структура и особенности текстов на ИПЯ (поисковых образов документов и поисковых предписаний) обычно рассматривается как результат действий синтаксических правил, а не как самостоятельные знаки. Под грамматикой ИПЯ обычно имеют в виду только синтаксис, морфологию ИПЯ, если она и выделяется, рассматривают на уровне лексики. Отношения между знаками, в семиотике относимые к сфере синтактике, обычно разделяются на два типа – синтагматические (отношения знаков в тексте) и парадигматические (отношения знаков вне контекста). Поскольку парадигматические отношения в реальных языках устанавливаются на уровне лексики, конкретно в словарях или классификациях, то эти отношения рассматриваются как средство организации лексики. Таким образом, в составе ИПЯ реально выделяются два основных компонента – лексика (в том числе организованная в словари с исполь Что же касается прагматических свойств ИПЯ, связывающих текста на ИПЯ с участником коммуникации, в данном случае поиска, то эти свойства реализуются в виде методик и алгоритмов индексирования, а также непосредственно в процессе поиска, при проектировании интерфейса, диалога пользователя с ЭБ, критериев ранжирования и выдачи результатов поиска. Второй класс средств, входящих в состав ЛО ЭБ, не является языками. Выше мы назвали их лингвистическими процессорами. Как уже было отмечено, это достаточно широкий класс информационных и программных продуктов и технологий, но конкретно применительно к ЭБ к этим средствам мы будем относить два класса технологий: системы автоматической обработки текста и лингвистические банки данных. Под автоматической обработкой текста понимаются процессы автоматического формирования описания текста (документа) на одном или нескольких информационных языках, включая и автоматическое индексирование, аннотирование или реферирование. В основе этих процессоров лежат конкретные лингвистические алгоритмы, прежде всего, морфологического и синтаксического анализа. Лингвистические банки данных (ЛБД) – важный обеспечивающий компонент развитых ЛО АИС. Практически значительная доля затрат на создание и эксплуатацию ЛО – это затраты на создание и поддержание ЛБД. В этой части ЛО АИС смыкается с таким направлением информатики как компьютерная лексикография. Итак, ЛО включает следующие виды языков и лингвистических процессоров: 1. Информационно-поисковые языки. 1.1. Системы метаданных. 1.2. Классификационные языки. 1.3. Вербальные языки. 1.4. Фактографические (объектно-признаковые) языки. 2. Лингвистические процессоры. 2.1. Системы автоматической обработки текста. 2.2. Лингвистические банки данных. Классификационная схема лингвистических средств представлена на рисунке 21. 1. Информационно-поисковый язык (ИПЯ) – формализованный искусственный язык, предназначенный для индексирования документов, информационных запросов и описания фактов с целью последующего хранения и поиска. К ИПЯ относятся: · Классификационный ИПЯ. · Предметизационный ИПЯ. · ИПЯ координатного индексирования. · Объектно-признаковые ИПЯ.
Рис. 21. Классификация ЛС
Классификационные ИПЯ – средство формализованного представления содержания документа, данных и информационных запросов посредством кодов или описаний классов логически упорядоченного множества понятий: · десятичная классификация Дьюи (ДКД); · универсальная десятичная классификация (УДК); · библиотечно-библиографическая классификация (ББК); · государственный рубрикатор научно-технической информации (ГРНТИ); · международный классификатор изобретений (МКИ). Вербальный ИПЯ – информационно-поисковый язык, использующий для представления своих лексических единиц слова и выражения естественного языка в их орфографической форме. К вербальным ИПЯ относятся: · дескрипторный язык, информационно-поисковые тезаурусы; · язык предметных рубрик. Дескрипторный язык (от англ. слова descriptor – «описатель») – информационно-поисковый язык, предназначенный для координатного индексирования документов и информационных запросов посредством дескрипторов или ключевых слов. Информационно-поисковый тезаурус («тезаурус» в пер. с греч. «сокровищница», «запас», «клад») – нормативный словарь понятий и классификационных связей между ними (иерархических, т. е. родовидовых, и неиерархических). 2. Языки-идентификаторы Международные стандартные номера (книг – ISBN, сериальных изданий – ISSN, музыкальных произведений – ISMN и т. д.). Коды названий (языков, стран, физических величин и т. д.). Таблица авторских знаков. Штрих-коды (документов, читателей). 3. Нормативно-справочная база Справочные издания (энциклопедии, словари и справочники, которые помогут разобраться в незнакомых терминах, выявить связи предмета с другими предметами, уточнить сущность вопроса. Нормативные документы (государственные и отраслевые стандарты). Стандарты по информации, библиотечному и издательскому делу – СИБИД: ГОСТ 7.1 – 2003. Библиографическое описание документа. Общие требования и правила составления. ГОСТ 7.80 – 2000 Библиографическая запись. Заголовок. Общие требования и правила составления. ГОСТ 7. 82 – 2001 Библиографическая запись. Библиографическое описание электронных ресурсов. Общие требования и правила составления. 4. Методики индексирования (систематизации, предметизации). Основные принципы общей методики электронной предметизации: 1) структура предметной рубрики (ПР) и принципы ее построения; 2) заголовки и подзаголовки ПР; 3) принципы применения ПР. Конечный результат предметизации – предметные рубрики различного вида. По широте отражаемой тематики предметные рубрики подразделяются на адекватные и обобщающие. Адекватные – рубрики, формулировка которых выражает объем понятия, наиболее точно соответствующий объему понятия о предмете документа. Обобщающая – рубрика, формулировка которой выражает объем понятия, более широкий, чем объем понятия о предмете документа. Электронная предметизация, сохраняя основные принципы традиционной обработки документа, предоставляет более широкие возможности для раскрытия его содержания. Это связано с тем, что в электронной среде вопрос об объеме термина индексирования перестает быть актуальным. Появляется возможность адекватно отражать содержание документа, не сокращать слова. Если в карточных каталогах библиографические записи традиционно содержат 1–1,5 рубрики, то в машиночитаемых ИПС их число значительно увеличивается, что способствует более точному раскрытию содержания документа. Предметная рубрика может состоять: - из одного термина индексирования (одной лексической единицы) – Заголовка; - из нескольких терминов индексирования (нескольких ЛЕ), объединенных в цепочку в соответствии с правилами синтаксиса, принятыми в системе предметизации (Заголовок с подзаголовками). Заголовок ПР – это первая лексическая единица многочленной ПР, отделяемая от последующих разделительным знаком. По структуре различают два вида предметных рубрик: простые и сложные. 1. Простая предметная рубрика – это предметная рубрика, состоящая из одной лексической единицы – Заголовка ПР. Простая предметная рубрика всегда однозначна и отражает общее понятие о предмете каталогизируемого документа. Простая предметная рубрика присваивается каталогизируемому документу при предметизации так называемых общих работ, то есть документов, в каждом из которых предмет рассматривается в целом и всесторонне. Сложная ПР – это ПР, состоящая из нескольких лексических единиц (Заголовка и подзаголовка), отделенных друг от друга разделительными знаками. Сложная предметная рубрика применяется в нескольких формах: 1) многочленная ПР; 2) описательная ПР; 3) комбинированная ПР. Основная форма сложной ПР – многочленная ПР, состоящая из нескольких лексических единиц: заголовка ПР и подзаголовков, отделенных друг от друга разделительным знаком. Описательная ПР – сложная ПР, в которой комбинация лексических единиц, чаще всего отделенных друг от друга предлогами и союзами, представлена в виде единого словосочетания. По своей формулировке описательные ПР более близки к естественному языку, но использование их при автоматизированной обработки документов нежелательно. Описательные ПР используются в тех случаях, когда их формулировки являются устоявшимися терминами. Например: 1. Налог на имущество физических лиц. 2. Авангардизм в искусстве. 3. Машин и механизмов теория. 5. Средства представления данных. 5.1. Коммуникативный формат представления библиографических данных (RUSMARC, UNIMARC, MARC21). 5.2. Коммуникативный формат представления нормативных/авторитетных данных. Таким образом, лингвистические средства библиотечной технологии – совокупность компонентов, необходимые для обработки, систематизации, поиска и хранения информации. Реализация лингвистическими средствами библиотечной технологии одной из важнейших функций библиотеки – обеспечение доступа потребителей информации к информационным ресурсам за счет раскрытия смыслового содержания хранящихся в библиотеке документов средствами соответствующих ИПЯ и методов индексирования. Без адекватных лингвистических средств невозможно проведение ни одного из видов информационного поиска: от элементарного адресного (основанного на языке библиографического описания документа), широкотематического (базирующегося на классификационных ИПЯ), узкотематического, предметного (язык предметных рубрик или дескрипторный ИПЯ), фактографического (связанного с объектно-признаковыми языками, до самого сложного – комплексного, предполагающего использование всего многообразия существующих лингвистических средств.
Контрольные вопросы
1. Назовите группы средств технологического обеспечения информационных технологий. 2. Как классифицируются технические средства в разрезе информационных процессов? 3. Назовите базовые программные средства информационных технологий. 4. В чем заключаются основные тенденции развития программного обеспечения? 5. Назовите подходы к определению понятия «лингвистическое обеспечение». 6. Дайте характеристику лингвистическим средствам информационных технологий. Глава 7 РЕГЛАМЕНТИРУЮЩИЕ ДОКУМЕНТЫ
Неотъемлемым свойством любых технологий, включая информационные, является их регламентация (нормализация) – установление однозначных требований к процессам, обеспечивающим подсистемам, промежуточным и конечным результатам. Регламентация информационных технологий – это процесс создания, организации и использования информации, определяющей нормы, требования, правила и порядок осуществления информационных процессов, устанавливающей образцы и эталоны производимых продуктов и услуг. Нормализующая информация, актуальная для многократного использования при производстве информационных продуктов и услуг, находит отражение в регламентирующих документах. Потенциальными объектами регламентации могут быть: • информационные продукты и услуги (с точки зрения номенклатуры, потребительских свойств, количественных и качественных параметров); • основные методические решения (принципы, приемы и правила деятельности); • способы организации и производства (тип производства, его особенности); • технологические процессы (номенклатура, операционный состав, квалификационное разделение труда, оснащенность оборудованием и техническими средствами, нормативы длительности и др.); • ресурсы информационного производства (в аспекте предъявляемых к ним требований, состава и распределения в процессе производства); • орудия труда (номенклатура, параметрическая характеристика, распределение по технологическим процессам, структурным подразделениям, рабочим местам); • кадры исполнителей (штатная численность, профессиональный, должностной и квалификационный состав); • производственная структура информационного учреждения, службы (состав и распределение структурных подразделений, рабочих мест, распределение численности работающих по производственным участкам и др.); • методы контроля качества информационных продуктов и услуг; • эффективность информационного производства (показатели, методы измерения и расчета). Стандарты Системы менеджмента качества ISO 9000 придают особое значение разработке регламентирующей документации, утверждая, что ее применение способствует: удовлетворению потребительских требований;улучшениюкачества; обеспечению необходимой подготовки кадров; повторяемости и прослеживаемости процессов; организации надежного производственного контроля; объективной оценке качества продукции и услуг и эффективности деятельности. Для регламентации информационных технологий определяющее значение имеют следующие виды регламентирующих документов: • государственные нормативно-правовые акты; • стандарты; • нормы и нормативы; • организационная документация; • технологическая документация.
|
||
|
|
Последнее изменение этой страницы: 2017-02-22; просмотров: 1279; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.217.39 (0.027 с.) |

 зованием парадигматики) и грамматика, при помощи которой порождаются тексты на этих языках.
зованием парадигматики) и грамматика, при помощи которой порождаются тексты на этих языках.