
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Построение регрессионной модели и её интерпретация
Будем использовать алгоритм пошагового регрессионного анализа с последовательным исключением незначимых регрессоров, пока все входящие в регрессионную модель факторы не будут иметь значимые коэффициенты. I ЭТАП РЕГРЕССИОННОГО АНАЛИЗА. В модель включены все факторные признаки (X6, X13, X14, Х15). Необходимо проверить значимость уравнения регрессии и полученных коэффициентов регрессии. F кр = 2,578739 Так как наблюдаемое значение F -статистики превосходит ее критическое значение 4,60955774 > 2,578739, то гипотеза о равенстве вектора коэффициентов отвергается с вероятностью ошибки, равной 0,05. Следовательно, хотя бы один элемент вектора β=(β1,β2,β3,β4)T значимо отличается от нуля. Проверим значимость отдельных коэффициентов уравнения регрессии, т.е. гипотезу Проверку значимости регрессионных коэффициентов проводят на основе t -статистики Получаем tкр = 2,014103 Для β0, β1, β2 и β3 наблюдаемое значение t -статистики больше критического по модулю. Следовательно, гипотеза о равенстве нулю этих коэффициентов отвергается с вероятностью ошибки, равной 0,05, т.е. соответствующие коэффициенты значимы. Для оставшегося значения наблюдаемое значение t -статистики меньше критического значения по модулю, следовательно, гипотеза H0 не отвергается, т.е. – β4 незначим. Значимость регрессионных коэффициентов проверяют и следующие столбцы результирующей таблицы: Столбец p -значение показывает значимость параметров модели граничным 5%-ым уровнем, т.е. если p ≤0,05, то соответствующий коэффициент считается значимым, если p >0,05, то незначимым. И последние столбцы – нижние 95% и верхние 95% и нижние 98% и верхние 98% -это интервальные оценки регрессионных коэффициентов с заданными уровнями надёжности для γ= 0,95 (выдаётся всегда) и γ= 0,98 (выдаётся при установке соответствующей дополнительной надёжности). Если нижние и верхние границы имеют одинаковый знак (ноль не входит в доверительный интервал), то соответствующий коэффициент регрессии считается значимым, в противном случае – незначимым.. Таким образом для коэффициентов β0, β1, β2 и β3 p- значение не превышает0,05 и доверительный интервал не включает ноль, т.е. по всем проверочным критериям эти коэффициенты являются значимыми.
В случае, когда при оценке регрессии выявлено несколько незначимых коэффициентов, первым из уравнения регрессии исключается регрессор, для которого t -статистика (
II ЭТАП РЕГРЕССИОННОГО АНАЛИЗА. В модель включены факторные признаки X6, X13, Х14, исключён X15. F кр = 2,806845 Так как наблюдаемое значение F -статистики превосходит ее критическое значение, то гипотеза о равенстве вектора коэффициентов отвергается с вероятностью ошибки, равной 0,05. Следовательно, хотя бы один элемент вектора β=(β1,β2,β3,β4)T значимо отличается от нуля. tкр = 2,012896 Для всех β наблюдаемое значение t -статистики больше критического по модулю, а также для всех коэффициентов p- значение не превышают0,05 и доверительный интервал не включает ноль, т.е. по всем проверочным критериям эти коэффициенты являются значимыми. III ЭТАП РЕГРЕССИОННОГО АНАЛИЗА. В модель включен факторный признак Y, Х6, X13,Х14, аисключён X15, F кр = 4,038392. tкр = 2,009575. Окончательная оценка регрессии со значимыми коэффициентами имеет вид: Для значимых коэффициентов регрессии можно найти с заданной доверительной вероятностью γ интервальные оценки. Как уже обсуждалось выше, доверительные интервалы для регрессионных коэффициентов выдаются Excel в последних столбцах таблицы результатов – нижние 95% и верхние 95% и нижние 98% и верхние 98% -с заданными уровнями надёжности для γ= 0,95 (выдаётся всегда) и γ= 0,98 (выдаётся при установке соответствующей дополнительной надёжности).
Интерпретация результатов
Величина R2 характеризует долю общей дисперсии зависимой переменной, обусловленную воздействием объясняющих переменных. Т.о. около 50,1% производительности труда (Y) объясняется вариацией факторов «удельный вес покупных изделий»(Х6), «среднегодовым фондом заработной платы»(Х13), «фондовооруженность труда» (Х14), а 49,9% вариации вызвано воздействием неучтенных в модели и случайных факторов. Таким образом, можно сделать вывод, что модель далеко не идеально отражает исследуемый процесс. Коэффициент регрессии показывает среднюю величину изменения зависимой переменной Y при изменении объясняющей переменной X на единицу собственного изменения. Знак при коэффициенте указывает направление этого изменения.
Коэффициент регрессии при X6 показывает, что при росте удельного веса покупных изделий на единицу производительность труда Y в среднем уменьшается на 35,3 единиц. Построенная выше интервальная оценка показывает, что с вероятностью 0,95 при росте удельного веса покупных изделий на единицу уменьшение производительность труда будет в пределах от 41,757до 133,68 единиц.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2017-02-09; просмотров: 645; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.21.100.34 (0.006 с.) |
 .
.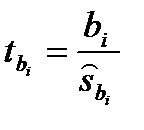 для уровня значимости
для уровня значимости 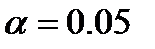 .
. ) минимальна по модулю.
) минимальна по модулю.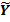 = 3,09685344436198+ 4,347427313х1+ 0,0000552011501518525х2+ 0,290599647270874х3
= 3,09685344436198+ 4,347427313х1+ 0,0000552011501518525х2+ 0,290599647270874х3


