Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
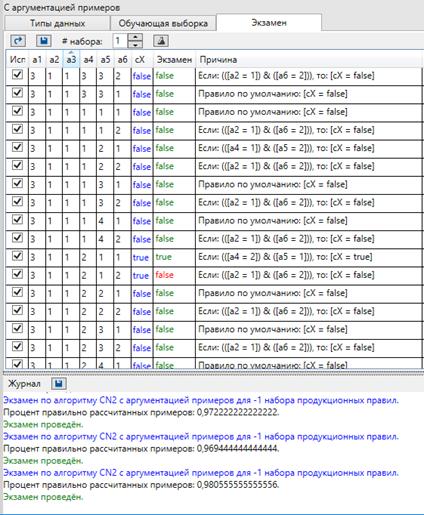
Результат классификации в задаче MONK1(ABCN2) ⇐ ПредыдущаяСтр 6 из 6
Рис.4.8 Набор аргументационных правил для задачи MONK1.
Рис.4.9 Результат классификации в задаче MONK1. Эксперт тщательно аргументировал примеры, на основании сводки правил из алгоритма CN2(Пример сводки правил - Рис.3.5). То есть, анализировались самые часто встречаемые правила, полученные при работе алгоритма CN2, и на основе них эксперт отдавал предпочтение или исключал тот или иной атрибут при аргументации. Были заданы аргументы «[cX= false] потому что [ x2 = 1]» и «[cX=false] потому что [ x 4 = x 5]». С помощью задания данных аргументов удалось увеличить процент классификации на 3-5% для каждого эксперимента, что говорит о том, что аргументация позволяет исключать противоречия, возникающие в ходе обычного обучения на зашумленных выборках и более эффективно проводить классификацию новых выборок.
Ниже представлены аналогичные результаты тестирования для задачи MONK3.
Результат классификации в задаче MONK3(ABCN2)
Рис.4.10 Набор аргументационных правил.
Рис.4.11 Результат классификации в задаче MONK3 Путем добавления аргументирования атрибутов [Сх= true] потому что [a5 = 3] и [Сх= true] потому что [a4 = 1] мы также смогли увеличить процент правильно классифицированных правил примерно на 5%. Выводы В данной главе доказана актуальность и конкурентоспособность алгоритма CN2 и ABCN2 относительно аналогичных алгоритмов обучения «с учителем». Представлен результат тестирования на известных наборах данных задач MONK1, MONK2, MONK3. По результатам тестирования алгоритма ABCN2 можно сделать следующий вывод: применение аргументации для задачи обобщения в условиях зашумленных обучающих выборок является эффективных методом. Точность классификации при наличии шума для приведенных тестовых наборов данных удалось в среднем увеличить на и 5—7%. Такие результаты объясняются прежде всего тем, что наличие неверно классифицированных объектов в обучающих выборках приводит к формированию неверных классификационных решающих правил. Такие правила приводят к появлению противоречий, находимых и решаемых методами аргументации. Таким образом применение методов аргументации позволяет уменьшить влияние некорректных правил вывода, и приводить к увеличению точности классификации тестовых наборов данных
Заключение
В результате выполненной работы были изучены базовые модели и методы интеллектуального анализа данных, основанного на построении решающих правил, дан обзор наиболее известных алгоритмов обучения «с учителем». Выбран алгоритм для программной реализации и исследования, позволяющий достаточно быстро формировать обобщения исходных данных и представлять их в компактной форме, удобной для восприятия и для дальнейшего использования в решении задачи распознавания. Работа выбранного алгоритма была успешно реализована и отлажена, а также протестирована с помощью специальных тестовых наборов данных из хранилища UCI Machine Learning Repository, традиционно используемых для построения решающих правил. Таким образом, было создано приложение, позволяющее получить набор аргументированных продукционных правил для различных множеств данных, а так же проводить классификацию набора примеров. Основные особенности рассматриваемого алгоритма следующие: · Алгоритм обеспечивает высокое качество классификации, а учет статических закономерностей позволяет ему работать с зашумленными данными. · Реализованный алгоритм позволяет эксперту отдать предпочтение тем или иным атрибутам при построении решающих правил несмотря на то, насколько точно полученные правила будут классифицировать новые примеры. · Алгоритм ABCN2 эффективнее в условиях зашумленных обучающих выборок.
Список литературы
1) Бонгард М.М. Проблема узнавания. – М.: Наука, 1967. 320 с. 2) Вагин В.Н. Дедукция и обобщение в системах принятия решений. – М.: Наука. Гл. ред. физ.-мат. лит., 1988. 3) Хант Э., Мартин Д., Стоун Ф. Моделирование процесса формирования понятий на вычислительной машине. М.: Мир, 1970. 302с. 4) Quinlan J.R. Induction of Decision Trees. – Machine Learning, №1, 1986. 5) Clark, P. and Niblett, T (1989) The CN2 induction algorithm. Machine Learning 3(4):261-283. 6) Martin Mozina, Jure Zabkar, and Ivan Bratko. Argument based rule learning. In Proceedings of 17th European Conference on Artificial Intelligence (ECAI 2006), Riva Del Garda, Italy, 2006. IOS Press 7) Вагин В.Н., Викторова Н.П. Обобщение и классификация знаний // Искусственный интеллект. Кн.2. Модели и методы. Справ. / Под ред. Д.А.Поспелова – М.: Радио и связь, 1990. Р.304-307.
8) Quinlan J.R. Generating production rules from Decision Trees // Proc. Of IJCAI 87. Milan. 1987. P.304-307. 9) Hutchinson A. Algoritmic Learning. – Oxford: Claredon Press, 1994. 434p. 10) Герберд Шилдт C#4.0 Полное руководство –«Вильямс» (2011) 11) Вагин В.Н., Головина Е.Ю., Загорянская А.А., Фомина М.В. Достоверный и правдоподобный вывод в интеллектуальных системах. – М.: ФИЗМАТЛИТ, 2004. 12) P. M. Murphy and D. W. Aha. UCI Repository of machine learning databases [http://archive.ics.uci.edu/ml/datasets.html] Irvine, CA: University of California, Department of Information and Computer Science, 1994
Приложения. Диаграмма классов
Рис.1 Диаграмма классов(1 из 2)
Рис.2 Диаграмма классов (2 из 2) Проект CN2 Пространство имён Core
|
||||||
|
|
Последнее изменение этой страницы: 2017-02-05; просмотров: 193; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.144.33.41 (0.006 с.) |