Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Gigabit Ethernet на витой паре категории 5
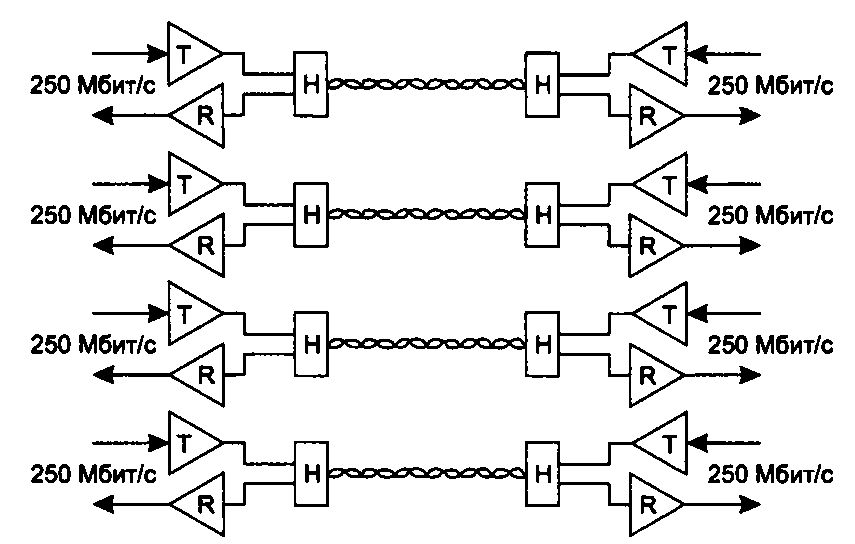
Как известно, каждая пара кабеля категории 5 имеет гарантированную полосу пропускания до 100 МГц. Для передачи по такому кабелю данных со скоростью 1000 Мбит/с было решено организовать параллельную передачу одновременно по всем четырем парам кабеля. Это сразу снизило скорость передачи данных по каждой паре до 250 Мбит/с. Однако и для такой скорости необходимо было придумать метод кодирования со спектром, не превышающим 100 МГц. Например, код 4В/5В не позволяет решить поставленную задачу, так как основной вклад в спектр сигнала на такой скорости у него вносит частота 155 МГц. Кроме того, не нужно убывать, что каждая новая версия должна поддерживать не только классический полудуплексный режим, но и дуплексный режим. На первый взгляд кажется, что одновременное использование четырех пар лишает сеть возможности работы в дуплексном режиме, так как не остается свободных пар для одновременной передачи данных в двух направлениях — от узла и к узлу Тем не менее проблемная группа 802.3ab нашла решения обеих проблем. Для кодирования данных был применен код РАМ5 с пятью уровнями потенциала: -2, -1, 0, +1, +2. В этом случае за один такт по одной паре передается 2,322 бит информации (log25). Следовательно, для достижения скорости 250 Мбит/с тактовую частоту 250 МГц можно уменьшить в 2,322 раза. Разработчики стандарта решили использовать несколько более высокую частоту, а именно 125 МГц. При этой тактовой частоте код РАМ5 имеет спектр уже, чем 100 МГц, то есть он может быть передан без искажений по кабелю категории 5. В каждом такте передается не 2,322 х 4 = 9,288 бит информации, а 8. Это и дает искомую суммарную скорость 1000 Мбит/с. Передача ровно восьми битов в каждом такте достигается за счет того, что при кодировании информации используются не все 625 (54 = 625) комбинаций кода РАМ5, а только 256 (28 = 256). Оставшиеся комбинации приемник задействует для контроля принимаемой информации и выделения правильных комбинаций на фоне шума. Для организации дуплексного режима разработчики спецификации 802.3ab применили технику выделения принимаемого сигнала из суммарного. Два передатчика работают навстречу друг другу по каждой из четырех пар в одном и том же диапазоне частот (рис. 13.20). Н-образная схема гибридной развязки позволяет приемнику и передатчику одного и того же узла использовать одновременно витую пару и для приема, и для передачи (так же, как и в трансиверах Ethernet на коаксиале).
Рис. 13.20. Двунаправленная передача по четырем парам UTP категории 5
Для отделения принимаемого сигнала от собственного приемник вычитает из результирующего сигнала известный ему свой сигнал. Естественно, что это не простая операция и для ее выполнения используются специальные процессоры цифровой обработки сигнала (Digital Signal Processor, DSP). Вариант технологии Gigabit Ethernet на витой паре расширил процедуру автопереговоров, введенную стандартом 100Base-T, за счет включения туда дуплексного и полудуплексного режимов работы на скорости 1000 Мбит/с. Поэтому порты многих коммутаторов Ethernet на витой паре являются универсальными в том смысле, что могут работать на любой из трех скоростей (10,100 или 1000 Мбит/с). Характеристики производительности Gigabit Ethernet зависят от того, использует ли коммутатор режим передачи кадров с расширением или же передает их в режиме пульсаций. В режиме пульсаций на периоде пульсации мы получаем характеристики, в 10 раз отличающиеся от характеристик Fast Ethernet: § максимальная скорость протокола в кадрах в секунду (для кадров минимальной длины с полем данных 46 байт) составляет 1 488 000; § полезная пропускная способность для кадров минимальной длины равна 548 Мбит/с; § полезная пропускная способность для кадров максимальной длины (поле данных 1500 байт) равна 976 Мбит/с. G Ethernet Стандарт 10G Ethernet определяет только дуплексный режим работы, поэтому он используется исключительно в коммутируемых линиях. Формально этот стандарт имеет обозначение IEEE 802.3ае и является поправкой к основному тексту стандарта 802.3. Формат кадра остался неизменным, при этом расширение кадра, введенное в стандарте Gigabit Ethernet, не используется, так как нет необходимости обеспечивать распознавание коллизий. Стандарт 802.3ае описывает несколько новых спецификаций физического уровня, которые взаимодействуют с уровнем MAC с помощью нового варианта подуровня согласования. Этот подуровень обеспечивает для всех вариантов физического уровня 10G Ethernet единый интерфейс XGMII (extended Gigabit Medium Independent Interface — расширенный интерфейс независимого доступа к гигабитной среде), который предусматривает параллельный обмен четырьмя байтами, образующими четыре потока данных.
На рис. 13.21 показана структура интерфейсов 10G Ethernet для физического уровня, использующего оптическое волокно. Как видно из рисунка, существуют три группы таких физических интерфейсов: 10GBase-X, 10Gbase-R и 10GBase-W. Они отличаются способом кодирования данных: в варианте 10Base-X применяется код 8В/10В, в остальных двух — код 64В/66В. Все они для передачи данных задействуют оптическую среду. Группа 10GBase-X в настоящее время состоит из одного интерфейса подуровня PMD — 10GBase-LX4. Буква L говорит о том, что информация передается с помощью волн второго диапазона прозрачности, то есть 1310 нм. Информация в каждом направлении передается одновременно с помощью четырех волн (что отражает цифра 4 в названии интерфейса), которые мультиплексируются на основе техники WDM (рис. 13.22). Каждый из четырех потоков интерфейса XGMII передается в оптическом волокне со скоростью 2,5 Гбит/с. Максимальное расстояние между передатчиком и приемником стандарта 10GBase-LX4 на многомодовом волокне равно 200-300 м (в зависимости от полосы пропускания волокна), на одномодовом — 10 км. В каждой из групп 10GBase-W и 10GBase-R может быть три варианта подуровня PMD: S, L и Е в зависимости от используемого для передачи информации диапазона волн — 850, 1310 или 1550 нм соответственно. Таким образом, существуют интерфейсы 10GBase-WS, 10GBase-WL, 10GBase-WE и 10GBase-RS, 10GBase-RL и l0GBase-RE. Каждый из них передает информацию с помощью одной волны соответствующего диапазона.
Рис. 13.21. Три группы физических интерфейсов 10G Ethernet
Рис. 13.22. В интерфейсе 10GBase-LX4 используется техника WDM
В отличие от 10GBase-R физические интерфейсы группы 10GBase-W обеспечивают скорость передачи и формат данных, совместимые с интерфейсом SONET STS-192/SDH ГГМ-64. Пропускная способность интерфейсов группы W равна 9,95328 Гбит/с, а эффективная скорость передачи данных — 9,58464 Гбит/с (часть пропускной способности тратится на заголовки кадров STS/STM). Из-за того что скорость передачи информации у этой группы интерфейсов ниже, чем 10 Гбит/с, они могут взаимодействовать только между обой, то есть соединение, например. интерфейсов 10GBase-RL и 10Base-WL невозможно. Интерфейсы группы W не являются полностью совместимыми по электрическим характеристикам с интерфейсами SONET STS-192/SDH STM-64. Поэтому для соединения сетей 10G Ethernet через первичную сеть SONET/SDH у мультиплексоров первичной сети должны быть специальные 10-гигабитные интерфейсы, совместимые со спецификациями 10GBase-W. Поддержка оборудованием 10GBase-W скорости 9,95328 Гбит/с обеспечивает принципиальную возможность передачи трафика 10G Ethernet через сети SONET/SDH в кадрах STS-192/STM-64. Физические интерфейсы, работающие в окне прозрачности Е, обеспечивают передачу данных на расстояния до 40 км. Это позволяет строить не только локальные сети, но и сети мегаполисов, что нашло отражение в поправках к исходному тексту стандарта 802.3. В 2006 году была принята спецификация 10GBase-T, которая дает возможность использовать знакомые администраторам локальных сетей кабели на витой паре. Правда, обязательным требованием является применение кабелей категории 6 или 6а: в первом случае максимальная длина кабеля не должна превышать 55 м, во втором — 100 м, что является традиционным для локальных сетей.
Архитектура коммутаторов Для ускорения операций коммутации сегодня во всех коммутаторах используются заказные специализированные БИС — ASIC, которые оптимизированы для выполнения основных операций коммутации. Часто в одном коммутаторе имеется несколько специализированных БИС, каждая из которых выполняет функционально законченную часть операций. Важную роль в построении коммутаторов играют также программируемые микросхемы FPGA (Field-Programmable Gate Array — программируемый в условиях эксплуатации массив вентилей). Эти микросхемы могут выполнять все функции, которые выполняют микросхемы ASIC, но в отличие от последних эти функции могут программироваться и перепрограммироваться производителями коммутаторов (и даже пользователями). Это свойство позволило резко удешевить процессоры портов коммутаторов, выполняющих сложные операции, например профилирование трафика, так как производитель FPGA выпускает свои микросхемы массово, а не по заказу того или иного производителя оборудования. Кроме того, применение микросхем FPGA позволяет производителям коммутаторов оперативно вносить изменения в логику работы порта при появлении новых стандартов или изменении действующих. Помимо процессорных микросхем для успешной неблокирующей работы коммутатору нужно иметь быстродействующий узел обмена, предназначенный для передачи кадров между процессорными микросхемами портов. В настоящее время в коммутаторах узел обмена строится на основе одной из трех схем: коммутационная матрица; § общая шина; § разделяемая многовходовая память. Часто эти три схемы комбинируются в одном коммутаторе. Коммутационная матрица обеспечивает наиболее простой способ взаимодействия процессоров портов, и именно этот способ был реализован в первом промышленном коммутаторе локальных сетей. Однако реализация матрицы возможна только для определенного числа портов, причем сложность схемы возрастает пропорционально квадрату количества портов коммутатора (рис. 13.23).
Рис. 13.23. Коммутационная матрица
Более детальное представление одного из возможных вариантов реализации коммутационной матрицы для восьми портов дано на рис. 13.24. Входные блоки процессоров портов на основании просмотра адресной таблицы коммутатора определяют по адресу назначения номер выходного порта. Эту информацию они добавляют к байтам исходного кадра в виде специального ярлыка — тега. Для данного примера тег представляет собой просто 3-разрядное двоичное число, соответствующее номеру выходного порта.
Рис. 13.24. Реализация коммутационной матрицы 8 х 8 с помощью двоичных переключателей
Матрица состоит из трех уровней двоичных переключателей, которые соединяют свой вход с одним из двух выходов в зависимости от значения бита тега. Переключатели первого уровня управляются первым битом тега, второго — вторым, а третьего — третьим. Матрица может быть реализована и иначе, на основании комбинационных схем другого типа, но ее особенностью все равно остается технология коммутации физических каналов. Известным недостатком этой технологии является отсутствие буферизации данных внутри коммутационной матрицы — если составной канал невозможно построить из-за занятости выходного порта или промежуточного коммутационного элемента, то данные должны накапливаться в их источнике, в данном случае — во входном блоке порта, принявшего кадр. Основные достоинства таких матриц — высокая скорость коммутации и регулярная структура, которую удобно реализовывать в интегральных микросхемах. Зато после реализации матрицы N х N в составе БИС проявляется еще один ее недостаток — сложность наращивания числа коммутируемых портов. В коммутаторах с общей шиной процессоры портов связывают высокоскоростной шиной, используемой в режиме разделения времени. Пример такой архитектуры приведен на рис. 13.25. Чтобы шина не блокировала работу коммутатора, ее производительность должна равняться, по крайней мере, сумме производительностей всех портов коммутатора. Для модульных коммутаторов характерно то, что путем удачного подбора модулей с низкоскоростными портами можно обеспечить неблокирующий режим работы, но в то же время некоторые сочетания модулей с высокоскоростными портами могут приводить к структурам, у которых узким местом является общая шина.
Рис. 13.25. Архитектура коммутатора с общей шиной
Кадр должен передаваться по шине небольшими частями, по несколько байтов, чтобы передача кадров между портами происходила в псевдопараллельном режиме, не внося задержек в передачу кадра в целом. Размер такой ячейки данных определяется производителем коммутатора. Некоторые производители выбирают в качестве порции данных, переносимых по шине за одну операцию, ячейку ATM с ее полем данных в 48 байт. Такой подход облегчает трансляцию протоколов локальных сетей в протокол ATM, если коммутатор поддерживает эти технологии. Кроме того, небольшой размер ячейки (ее формат может быть и фирменным, так как перенос данных между портами является сугубо внутренней операцией) уменьшает задержки доступа порта к общей шине. Входной блок процессора помещает в ячейку, переносимую по шине, тег, в котором указывает номер порта назначения. Каждый выходной блок процессора порта содержит фильтр тегов, который выбирает теги, предназначенные данному порту.
Шина, так же как и коммутационная матрица, не может осуществлять промежуточную буферизацию, но поскольку данные кадра разбиваются на небольшие ячейки, задержек с начальным ожиданием доступности выходного порта в такой схеме нет — здесь работает принцип коммутации пакетов, а не каналов. Разделяемая многовходовая память представляет собой третью базовую архитектуру взаимодействия портов. Пример такой архитектуры приведен на рис. 13.26.
Рис. 13.26. Архитектура коммутаторов с разделяемой памятью
Входные блоки процессоров портов соединяются с переключаемым входом разделяемой памяти, а выходные блоки этих же процессоров — с ее переключаемым выходом. Переключением входа и выхода разделяемой памяти управляет менеджер очередей выходных портов. В разделяемой памяти менеджер организует несколько очередей данных, по одной для каждого выходного порта. Входные блоки процессоров передают менеджеру портов запросы на запись данных в очередь того порта, который соответствует адресу назначения кадра. Менеджер по очереди подключает вход памяти к одному из входных блоков процессоров и тот переписывает часть данных кадра в очередь определенного выходного порта. По мере заполнения очередей менеджер производит также поочередное подключение выхода разделяемой памяти к выходным блокам процессоров портов, и данные из очереди переписываются в выходной буфер процессора. Применение общей буферной памяти, гибко распределяемой менеджером между отдельными портами, снижает требования к размеру буферной памяти процессора порта. Однако буферная память должна быть достаточно быстродействующей для поддержания необходимой скорости обмена данными между N портами коммутатора. Комбинированные коммутаторы. У каждой из описанных архитектур есть свои достоинства и недостатки, поэтому часто в сложных коммутаторах эти архитектуры применяются в комбинации друг с другом. Пример такого комбинирования приведен на рис. 13.27. Коммутатор состоит из модулей с фиксированным количеством портов (2-12), выполненных на основе специализированной БИС, реализующей архитектуру коммутационной матрицы. Если порты, между которыми нужно передать кадр данных, принадлежат одному модулю, то передача кадра осуществляется процессорами модуля на основе имеющейся в модуле коммутационной матрицы. Если же порты принадлежат разным модулям, то процессоры общаются по общей шине. В такой архитектуре передача кадров внутри модуля будет происходить быстрее, чем при межмодульной передаче, так как коммутационная матрица — это наиболее быстрое, хотя и наименее масштабируемое средство взаимодействия портов. Скорость внутренней шины коммутаторов может достигать нескольких гигабит в секунду, а у наиболее мощных моделей — до нескольких десятков гигабит в секунду.
Рис. 13.27. Комбинирование архитектур коммутационной матрицы и общей шины
|
|||||||||
|
|
Последнее изменение этой страницы: 2017-02-05; просмотров: 602; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.135.207.129 (0.022 с.) |