Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Алгоритм нахождения нужных записей подчиненного файла ⇐ ПредыдущаяСтр 10 из 10
· Шаг 1. Ищем запись в основном файле в соответствии с его организацией (с помощью функции хэширования, или с использованием индексов, или другим образом). Если требуемая запись найдена, то переходим к шагу 2, в противном случае выводим сообщение об отсутствии записи основного файла. · Шаг 2. Анализируем указатель в основном файле. Если он пустой, т. е. стоит прочерк, значит, для этой записи нет ни одной связанной с ней записи в подчиненном файле. Выводим соответствующее сообщение, в противном случае переходим к шагу 3. · Шаг 3. По ссылке-указателю в найденной записи основного файла переходим прямым методом доступа по номеру записи на первую запись в цепочке подчиненного файла. Переходим к шагу 4. · Шаг 4. Анализируем текущую запись на содержание если это искомая запись, то сохраняем содержимое записи в некотором промежуточном буфере и переходим к шагу 5. Если же текущая запись не является искомой, то ничего не записываем в промежуточный буфер и также переходим к шагу 5. · Шаг 5. Анализируем указатель на следующую запись в цепочке. Если он пуст, то анализируем буфер; если буфер пуст, то выводим сообщение, что искомая запись отсутствует, и прекращаем поиск. В противном случае по ссылке-указателю переходим на следующую запись в подчиненном файле и снова переходим к шагу 4 131. Как строятся взаимосвязанные файлы с двунаправленными цепочками? Разработать алгоритмы удаления записей и добавления записей в данные файлы. Использование цепочек записей позволяет эффективно организовывать модификацию взаимосвязанных файлов. Для того чтобы эффективно использовать дисковое пространство при включении новой записи в подчиненный файл, ищем первое свободное место, т. е. запись, помеченную символом «*», и на ее место заносим новую запись, после этого производим модификацию соответствующих указателей. Необходимо различать 3 случая: 1) добавление записи на первое место в цепочке; 2) добавление записи в конец цепочки; Добавление записи на заданное место в цепочке. Однако часто бывает необходимо просматривать цепочку подчиненных записей в прямом и обратном направлениях. В этом случае применяют двойные указатели. В основном файле один указатель равен номеру первой записи в цепочке записей подчиненного файла, а второй — номеру последней записи. В подчиненном файле один указатель равен номеру следующей записи в цепочке, а другой — номеру предыдущей записи в цепочке. Для первой и последней записей в цепочке один из указателей пуст, т. е. равен пробелу.
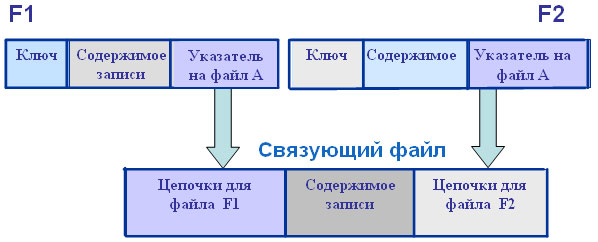
Для нашего примера это выглядит следующим образом:
Один файл (подчиненный или основной) может быть связан с несколькими другими файлами, при этом для каждой связи моделируются свои указатели. Связь двух основных файлов F1 и F2 с одним связующим файлом F3 моделируется как показано на рис. 11.5.
Рис. 11.5. Взаимосвязь двух основных и одного связующего файлов 132. Какие типы страниц используются в MSSQLServer? Как организованы страницы данных в MS SQL Server? В SQL 2000 существуют 6 основных типов страниц: · страница данных (Data page). В станицах этого типа хранятся структурированные данные, т. е. все типы данных, исключая тип text, ntext, image; · индексные страницы (Index page). В страницах этого типа хранятся индексы; · текстовые страницы (Text/image page). В страницах данного типа хранятся как раз слабоструктурированные данные типа text, ntext, image; · карты распределения блоков (Global allocation map page), часто именуемые GAM. Этот тип страниц хранит информацию об использовании экстентов (блоков); · карты свободного пространства (Page free space page). В страницах этого типа хранится информация о свободном пространстве на страницах; · индексные карты размещения (Index Allocation Map page), называемые IAM. Страницы этого типа хранят информацию об экстентах, которые используются конкретными таблицами или индексами.
Организация страницы данных(параметры): · номер страницы в формате <номер файла, номер страницы>; · идентификатор объекта, которому принадлежит страница; · номер индекса, которому принадлежит страница; · уровень внутри индексного дерева, которому принадлежит страница; · количество отведенных строк на странице, количество заполненных слотов; · общий объем свободного пространства на странице; · указатель на расположение свободного пространства после последней строки на странице; · минимальная длина строки на странице; · объем зарезервированного пространства.
Типовые задания Задание 1. Написать запросы в реляционной алгебре Даны отношения, моделирующие работу туристического агенства, имеющего много филиалов в различных странах: R1
R2
R3
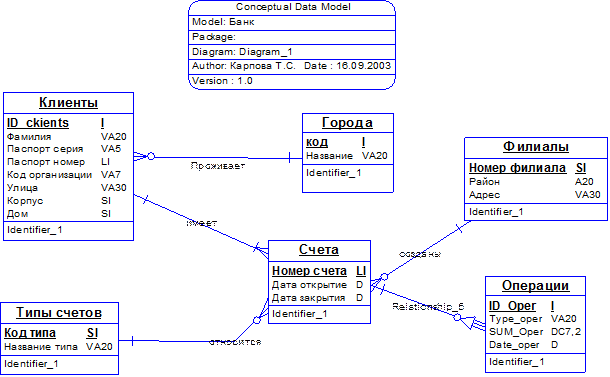
Составить запросы, позволяющие выбрать: 1. Клиентов, заключивших договоры с несколькими филиалами. 2. Филиалы, которые работают с клиентами только одной страны. 3. Клиентов, которые заключили несколько договоров с одним филиалом. 4. Филиалы, которые заключили договоры только с клиентами из той же станы, в которой расположен этот филиал. 5. Клиентов, которые заключили несколько договоров с разными филиалами. 6. Клиентов, которые заключили только один договор. 7. Задание 2. Схема БД, которая моделирует работу с лицевыми счетами физических лиц.
Список всех атрибутов с указанием их типа
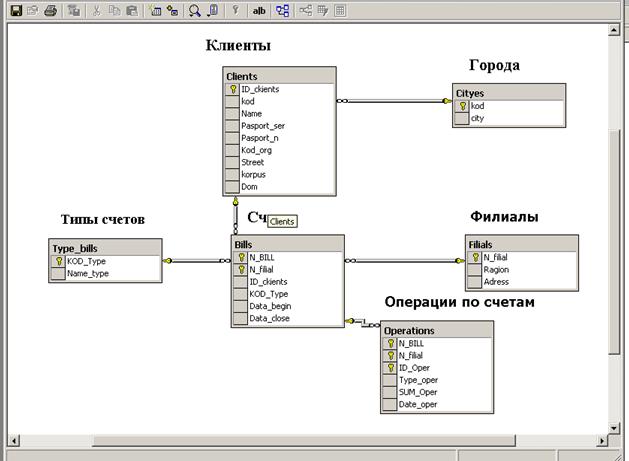
Физическая модель БД «bank» на сервере
Написать запросы на языке SQL
1. Вывести список филиалов банка, которые имеют минимальное количество счетов. 2. Вывести список районов с указанием количества филиалов банка, которые расположены в данном районе. 3. Вывести список счетов, которые открыты в филиале номер 1 нашего банка. 4. Вывести сумму вкладов на всех счетах филиала № 1 5. Вывести остаток на всех счетах господина Андреева А.А. 6. Вывести количество операций занесения денег на каждый счет, т.е. получить таблицу <счет, количество операций > 7. Вывести общую сумму снятых денег со всех счетов господина Андреева А.А. 8. Вывести список филиалов банка с указанием количества счетов каждого типа, открытых в данных филиалах. 9. Вывести список филиалов, в которых не открыто ни одного счета. 10. Вывести список клиентов, которые открыли счета, по которым не выполнено ни одной операции занесения или снятия денег.
Задание 3. Дана таблица:
По заданной таблице выполнить следующие действия:
1. Проанализировать содержание таблицы и выбрать 2 столбца,между которыми существует связь М:М (многие к многим). 2. Для выбранных столбцов привести логическую схему БД, моделирующую данные соответствующие связи (в нотации сетевой модели). 3. Представить схему связей между экземплярами соответствующих наборов, соответствующую данным, приведенным в исходной таблице. 4. Представить физическую модель, соответствующую данной логической схеме базы данных с использованием двунаправленных цепочек. 5. Представить изменения значений указалей при выполнении двух следующих действий над наблицей: · удалении 4-ой строки таблицы. · добавлении 2-х новых строк, следующего содержания:
Задание 4 Расcчитать размер и время доступа к произвольной записи для файлов с тремя способами организации: – индексно-последовательный (неплотный индекс); – индексно-прямой (плотный индекс); – В-дерево. Обозначения LZ – длина записи в байтах; LK – длина ключа в байтах; LB – размер блока в байтах; KZ – количество записей в файле. Характеристики файла LZ = 126 б, KZ = 66000, LK = 14 б, LB = 512 б. % расширения файла -20
Заведующий кафедрой прикладной информатики Изранцев В.В.
Ответственный за УМК дисциплины Карпова Т.С.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2017-01-27; просмотров: 125; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.145.74.54 (0.038 с.) |