Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Тема 2. Реляционная модель данных, реляционная алгебраСтр 1 из 10Следующая ⇒
Рис. 1.10. Классификация моделей данных
Наибольший интерес вызывают модели данных, используемые на концептуальном уровне. По отношению к ним внешние модели называются подсхемами и используют те же абстрактные категории, что и концептуальные модели данных. Кроме трех рассмотренных уровней абстракции, определенных в ANSI-архитектуре, при проектировании БД существует еще один уровень, предшествующий им. Модель этого уровня должна выражать информацию о предметной области в виде, независимом от используемой СУБД. Эти модели называются инфологическими, или семантическими, и отражают в естественной и удобной для разработчиков и других пользователей форме информационно-логический уровень абстрагирования, связанный с фиксацией и описанием объектов предметной области, их свойств и их взаимосвязей. Инфологические модели данных используются на ранних стадиях проектирования для описания структур данных в процессе разработки приложения, а даталогические модели уже поддерживаются конкретной СУБД. Документальные модели данных соответствуют представлению о слабоструктурированной информации, ориентированной в основном на свободные форматы документов, текстов на естественном языке. Модели, основанные на языках разметки документов, связаны прежде всего со стандартным общим языком разметки SGML (Standart Generalised Markup Language), который был утвержден ISO в качестве стандарта еще в 80-х гг. Этот язык предназначен для создания других языков разметки, он определяет допустимый набор тегов (ссылок), их атрибуты и внутреннюю структуру документа. Контроль за правильностью использования тегов осуществляется при помощи специального набора правил, называемых DTD-описаниями, которые используются программой клиента при разборе документа. Для каждого класса документов определяется свой набор правил, описывающих грамматику соответствующего языка разметки. С помощью SGML можно описывать структурированные данные, организовывать информацию, содержащуюся в документах, представлять эту информацию в некотором стандартизованном формате. Но ввиду некоторой своей сложности SGML использовался в основном для описания синтаксиса других языков (наиболее известным из которых является HTML), и немногие приложения работали с SGML-документами напрямую.
Гораздо более простой и удобный, чем SGML, язык HTML позволяет определять оформление элементов документа и имеет некий ограниченный набор инструкций — тегов, при помощи которых осуществляется процесс разметки. Инструкции HTML в первую очередь предназначены для управления процессом вывода содержимого документа на экран программы-клиента и определяют этим самым способ представления документа, но не его структуру. В качестве элемента гипертекстовой базы данных, описываемой HTML, используется текстовый файл, который может легко передаваться по сети с использованием протокола HTTP. Эта особенность, а также то, что HTML является открытым стандартом и огромное количество пользователей имеет возможность применять этот язык для оформления своих документов, безусловно, повлияли на рост популярности HTML и сделали его сегодня главным механизмом представления информации в Интернете. Однако HTML сегодня уже не удовлетворяет в полной мере требованиям, предъявляемым современными разработчиками к языкам подобного рода. И ему на смену был предложен новый язык гипертекстовой разметки, мощный, гибкий и одновременно удобный язык XML. В чем же заключаются его достоинства? XML (Extensible Markup Language) — это язык разметки, описывающий целый класс объектов данных, называемых XML-документами. Он используется в качестве средства для описания грамматики других языков и контроля за правильностью составления документов, т. е. сам по себе XML не содержит никаких тегов, предназначенных для разметки, он просто определяет порядок их создания. Тезаурусные модели основаны на принципе организации словарей, содержат определенные языковые конструкции и принципы их взаимодействия в заданной грамматике. Эти модели эффективно используются в системах-переводчиках, особенно многоязыковых переводчиках. Принцип хранения информации в этих системах и подчиняется тезаурусным моделям. Дескрипторные модели — самые простые из документальных моделей, они широко использовались на ранних стадиях использования документальных баз данных. В этих моделях каждому документу соответствовал дескриптор — описатель. Этот дескриптор имел жесткую структуру и описывал документ в соответствии с теми характеристиками, которые требуются для работы с документами в разрабатываемой документальной БД. Например, для БД, содержащей описание патентов, дескриптор содержал название области, к которой относился патент, номер патента, дату выдачи патента и еще ряд ключевых параметров, которые заполнялись для каждого патента. Обработка информации в таких базах данных велась исключительно по дескрипторам, т. е. по тем параметрам, которые характеризовали патент, а не сам текст патента.
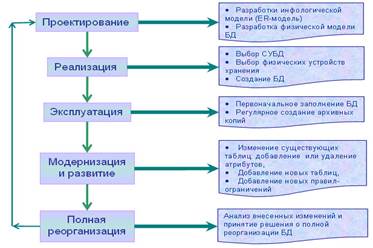
Как любой программно-организационно-техничекий комплекс банк данных существует во времени и пространстве и проходит определенные стадии в своем развитии (рис. 1.11):
На каждом этапе своего существования с банком данных связаны разные категории пользователей. Так, на этапе проектирования работают разработчики, на этапе реализации к разработчикам может подключаться администратор БД, на этапе эксплуатации кроме администратора с БД работают уже и конечные пользователи. Этапы, связанные с модернизацией и развитием, требуют наряду с администратором БД подключения администраторов отдельных приложений. Однако следует отметить, что на всех этапах главным остается администратор БД. Под администратором БД понимают группу лиц, ответственных за бесперебойное функционирование БД, корректное восстановление после сбоев, поддержку требуемой функциональности и скорости обработки информации.
Рис. 1.11. Этапы жизненного цикла БД
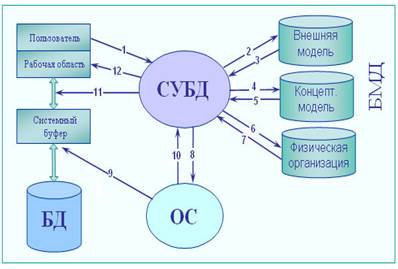
Схема прохождения запроса в БД показана на рис. 1.12.
Рис. 1.12. Схема прохождения запроса в БД
Указанная процедура осуществляется в следующей последовательности. · Пользователь посылает СУБД запрос на получение данных из БД. · СУБД выявляет, обращаясь к базе метаданных (БМД), внешнюю модель пользователя, который сформировал запрос к БД. · СУБД проводит анализ прав пользователя и внешней модели данных, соответствующих данному пользователю, подтверждает или запрещает доступ данного пользователя к запрошенным данным. · В случае запрета на доступ к данным СУБД сообщает пользователю об этом (стрелка 12) и прекращает дальнейший процесс обработки данных, в противном случае СУБД определяет часть концептуальной модели, которая затрагивается запросом пользователя. · СУБД получает информацию о запрошенной части концептуальной модели. · СУБД запрашивает информацию о местоположении данных на физическом уровне (файлы или физические адреса). · В СУБД возвращается информация о местоположении данных в терминах операционной системы. · СУБД вежливо просит операционную систему предоставить необходимые данные, используя средства операционной системы. · Операционная система осуществляет перекачку информации с устройств хранения и пересылает ее в системный буфер. · Операционная система оповещает СУБД об окончании пересылки информации в системный буфер.
· СУБД выбирает из доставленной информации, находящейся в системном буфере, только то, что нужно пользователю, и пересылает эти данные в рабочую область пользователя. · СУБД информирует пользователя о завершении обработки его запроса и пересылке найденных данных в его рабочую область. БМД — это база метаданных, именно здесь и хранится вся информация об используемых структурах данных, логической организации данных, правах доступа пользователей и, наконец, физическом расположении данных. Для управления БМД существует специальное программное обеспечение администрирования баз данных.
СУБД более быстро и экономно может обрабатывать такой курсор, поэтому если для вас действительно важно рассмотреть и обработать состояние БД на некоторый конкретный момент времени, то имеет смысл создать «нечувствительный курсор». 116. Вы разрабатываете приложение, которое подсчитывает начисление процентов по вкладам клиентов банка, какой курсор Вы будете использовать и почему? Нечувствительный, нам важно показать не сам процесс начисления, а слепок на определённый момент времени. Мы присвоили возвращаемое значение самой процедуре. Такой способ аналогичен механизму использования функций. Это возможно только в том случае, когда возвращается целое число. Если тип возвращаемого значения иной, то необходимо определить специальным образом возвращаемые, выходные параметры процедуры, которых в общем случае может быть несколько. 118. Есть хранимая процедура, которая считает количество экземпляров книги в библиотеке count_books(@isbn) Eсть хранимая процедура, которая считает количество экземпляров данной книги на руках у читателей count_read(@isbn) Как сосчитать количество свободных экземпляров данной книги, напишите оператор. См. вопрос 117. 119. Каков формат оператора вызова хранимой процедуры с параметрами? Что возвращает оператор RETURN? Каковы ограничения на его применение в хранимой процедуре? EXEC <имя процедуры> <значение_входного_параметра1>... <имя_переменной_для_выходного параметра1>... Оператор RETURN в СУБД MS SQL возвращает значение целочисленной переменной и прекращает выполнение. Возвращаемое значение должно быть целочисленным. 120. Что такое план выполнения процедуры? При выполнении процедуры план выполнения строится заново каждый раз или нет, поясните. План, в соответствии с которым процедура выполняется. Построение заново происходит при заданном RECOMPILE. При новых данных старый план может быть просто неэффективным, потому и необходимо перестраивать план выполнения.
121. Чем отличается использование входных и выходных параметров при вызове процедуры, покажите на примере. 122. Чем отличаются хранимые процедуры от пользовательских функций? В MS SQL SERVER 2000 существует множество заранее определенных функций, позволяющих выполнять самые разнообразные действия. Однако может возникнуть необходимость использовать некоторые специфичные функции. Для этого начиная с версии 8.0 (2000) появилась возможность описывать функции самим и хранить такие функции в виде полноценного объекта БД, наравне с хранимыми процедурами, представлениями и т. д. Удобство применения функций, определяемых пользователем очевидно: их, в отличие от хранимых процедур можно встраивать непосредственно в оператор SELECT, причем можно их использовать как для получения конкретных значений (в разделе SELECT), так и в качестве источника данных (в разделе FROM). При использовании UDF в качестве источников данных преимущество их использования перед представлениями заключается в том, что UDF в отличие от представлений могут иметь входные параметры, с помощью которых можно влиять на результат работы функции. Функции, определяемые пользователем, могут быть трех видов: скалярные функции, Inline-функции и многооператорные функции, возвращающие табличный результат.
END При наличии данных в подчинённых таблицах, триггер сработает некорректно. CREATE TRIGGER DELL_BOOKS ON [dbo].[BOOKS] -- задали тип триггера INSTEAD OF DELETE AS -- опишем переменную, в которую поместим шифр удаляемой книги declare @ISBN varchar(14) -- используя системную таблицу Deleted определеим значение шифра -- удаляемой книги и присвоим его нашей внутренней переменной @ISBN Select @ISBN=ISBN from Deleted -- удалим сначала из подчиненных таблиц все записи с заданным -- значением шифра книги Delete from BOOKS_CAT where BOOKS_CAT.ISBN=@ISBN Delete from Relation_93 where RELATION_93.ISBN= @ISBN -- Теперь удалим книгу Delete from books where Books.isbn= @ISBN Верный вариант, который согласует всё это с DRI.
Если вновь заносимая запись имеет такое же значение функции хэширования, которое использовала другая запись, уже имеющаяся в БД, то новая запись заносится в область переполнения на первое свободное место, а в записи-синониме, которая находится в основной области, делается ссылка на адрес вновь размещенной записи в области переполнения. Если же уже существует ссылка в записи-синониме, которая расположена в основной области, то новая запись получает дополнительную информацию в виде ссылки и уже в таком виде заносится в область переполнения. При этом цепочка синонимов не разрывается, но мы не просматриваем ее до конца, чтобы расположить новую запись в конце цепочки синонимов, а располагаем всегда новую запись на второе место в цепочке синонимов, что существенно сокращает время размещения новой записи. При таком алгоритме время размещения любой новой записи составляет не более двух обращений к диску с учетом того, что номер первой свободной записи в области переполнения хранится в виде системной переменной.
При поиске записи сначала вычисляется значение ее хэш-функции и считывается первая запись в цепочке синонимов, которая расположена в основной области. Если искомая запись не соответствует первой в цепочке синонимов, то далее поиск происходит перемещением по цепочке синонимов, пока не будет обнаружена требуемая запись. Скорость поиска зависит от длины цепочки синонимов, поэтому качество хэш-функции определяется максимальной длиной цепочки синонимов. Хорошим результатом может считаться наличие не более 10 синонимов в цепочке. При удалении произвольной записи сначала определяется ее место расположения. Если удаляемой является первая запись в цепочке синонимов, то после удаления на ее место в основной области заносится вторая (следующая) запись в цепочке синонимов, при этом все указатели (ссылки на синонимы) сохраняются. Если же удаляемая запись находится в середине цепочки синонимов, то необходимо провести корректировку указателей: в записи, предшествующей удаляемой, в цепочке ставится указатель из удаляемой записи. Если это последняя запись в цепочке, то механизм изменения указателей такой же, т. е. в предшествующую запись заносится признак отсутствия следующей записи в цепочке, который ранее хранился в последней записи. Механизмы удаления записей во многом аналогичны механизмам удаления в стратегии с областью переполнения. Однако еще раз кратко опишем их. Если удаляемая запись является первой записью в цепочке синонимов, то после удаления на ее место перемещается следующая (вторая) запись из цепочки синонимов и проводится соответствующая корректировка указателя третьей записи в цепочке синонимов, если таковая существует. Если же удаляется запись, которая находится в середине цепочки синонимов, то производится только корректировка указателей: в предшествующей записи указатель на удаляемую запись заменяется указателем на следующую за удаляемой запись, а в записи, следующей за удаляемой, указатель на предыдущую запись заменяется на указатель на запись, предшествующую удаляемой. 127. Что такое индексные файлы, какие типы индексных файлов бывают? Как строятся индексные файлы с плотным индексом? Как рассчитывается размер данного файла и время доступа к произвольной записи? Несмотря на высокую эффективность хэш-адресации, в файловых структурах далеко не всегда удается найти соответствующую функцию, поэтому при организации доступа по первичному ключу широко используются индексные файлы. В некоторых коммерческих системах индексными файлами называются также файлы, организованные в виде инвертированных списков, которые используются для доступа по вторичному ключу. Мы будем придерживаться классической интерпретации индексных файлов и надеемся, что если вы столкнетесь с иной интерпретацией, то сумеете разобраться в сути, несмотря на некоторую путаницу в терминологии. Индексные файлы можно представить как файлы, состоящие из двух частей. Это не обязательно физическое совмещение этих двух частей в одном файле, в большинстве случаев индексная область образует отдельный индексный файл, а основная область образует файл, для которого создается индекс. Но нам удобнее рассматривать эти две части совместно, так как именно взаимодействие этих частей и определяет использование механизма индексации для ускорения доступа к записям. В зависимости от организации индексной и основной областей различают 2 типа файлов: с плотным индексом и с неплотным индексом. Эти файлы имеют еще дополнительные названия, которые напрямую связаны c методами доступа к произвольной записи, которые поддерживаются данными файловыми структурами. Рис. 11.3. Структура плотного индекса Здесь значение ключа — это значение первичного ключа, а номер записи — это порядковый номер записи в основной области, которая имеет данное значение первичного ключа. Так как индексные файлы строятся для первичных ключей, однозначно определяющих запись, то в них не может быть двух записей, имеющих одинаковые значения первичного ключа. В индексных файлах с плотным индексом для каждой записи в основной области существует одна запись из индексной области. Все записи в индексной области упорядочены по значению ключа, поэтому можно применить более эффективные способы поиска в упорядоченном пространстве. Длина доступа к произвольной записи оценивается не в абсолютных значениях, а в количестве обращений к устройству внешней памяти, которым обычно является диск. Именно обращение к диску является наиболее длительной операцией по сравнению со всеми обработками в оперативной памяти. Самым эффективным алгоритмом поиска на упорядоченном массиве является логарифмический, или бинарный, поиск. Очень хорошо изложил этот алгоритм барон Мюнхгаузен, когда объяснял, как поймать льва в пустыне. При этом все пространство поиска разбивается пополам, и так как оно строго упорядочено, то определяется сначала, не является ли элемент искомым, а если нет, то в какой половине его надо искать. Далее определенную половину также делим пополам и производим аналогичные сравнения и т. д., пока не обнаружим искомый элемент. Максимальное количество шагов поиска определяется двоичным логарифмом от общего числа элементов в искомом пространстве поиска: Tn = log 2N, Где N — число элементов. Однако в нашем случае является существенным только число обращений к диску. Поиск происходит в индексной области, где применяется двоичный алгоритм поиска индексной записи, а потом путем прямой адресации мы обращаемся к основной области уже по конкретному номеру записи. Для того чтобы оценить максимальное время доступа, нам надо определить количество обращений к диску для поиска произвольной записи. На диске записи файлов хранятся в блоках. Размер блока определяется физическими особенностями дискового контроллера и операционной системой. В одном блоке могут размещаться несколько записей. Значит нам надо определить количество индексных блоков, которое потребуется для размещения всех требуемых индексных записей, а потому максимальное число обращений к диску будет равно двоичному логарифму от заданного числа блоков плюс единица. После поиска номера записи в индексной области необходимо обратиться к основной области файла. Поэтому формула для вычисления максимального времени доступа в количестве обращений к диску выглядит следующим образом: Tn = log 2N бл. инд. + 1. Рассмотрим конкретный пример и сравним время доступа при последовательном просмотре и при организации плотного индекса. 128. Как строятся индексные файлы с неплотным индексом? Как рассчитывается размер данного файла и время доступа к произвольной записи? Попробуем усовершенствовать способ хранения файла: будем хранить его в упорядоченном виде и применим алгоритм двоичного поиска для доступа к произвольной записи. Тогда время доступа к произвольной записи будет существенно меньше. Для нашего примера это будет: T = log2KBO = log 212 500 = 14 обращений к диску. Рис. 11.4. Структура неплотного индекса В индексной области мы теперь ищем нужный блок по заданному значению первичного ключа. Так как все записи упорядочены, то значение первой записи блока позволяет нам быстро определить, в каком блоке находится искомая запись. Все остальные действия происходят в основной области. Время сортировки больших файлов весьма значительно, но поскольку файлы поддерживаются сортированными с момента их создания, накладные расходы в процессе добавления новой информации будут гораздо меньше. Оценим время доступа к произвольной записи для файлов с неплотным индексом. Алгоритм решения задачи аналогичен описанному ранее. Сначала определим размер индексной записи. Если ранее ссылка рассчитывалась исходя из того, что требовалось ссылаться на 100 000 записей, то теперь нам требуется ссылаться всего на 12 500 блоков, поэтому для ссылки достаточно 2 байт. Тогда длина индексной записи будет равна: LI = LK + 2 = 14 + 2 = 14 байт. Тогда количество индексных записей в одном блоке будет равно KIZB = LB/LI = 1 024/14 = 73 индексные записи в одном блоке. Определим количество индексных блоков, которое необходимо для хранения требуемых индексных записей: KIB = KBO/KZIB = 12 500/73 = 172 блока. Тогда время доступа по прежней формуле будет определяться так: T поиска = log 2 KIB + 1 = log 2 172 + 1 = 8 + 1 = 9 обращений к диску. Калькированный термин «B-дерево», в котором смешивается английский символ «B» и добавочное слово на русском языке, настолько устоялся в литературе, посвященной организации физического хранения данных, что я не решусь его корректировать. Встретив как-то термин «Б-дерево», я долго его трактовала, потому что привыкла уже к устоявшемуся обозначению. Поэтому будем работать с этим термином. Построение В-деревьев связано с простой идеей построения индекса над уже построенным индексом. Действительно, если мы построим неплотный индекс, то сама индексная область может рассматриваться как основной файл, над которым надо снова построить неплотный индекс, а потом снова над новым индексом строим следующий и так до того момента, пока не останется всего один индексный блок. В общем случае получим некоторое дерево, каждый родительский блок которого связан с одинаковым количеством подчиненных блоков, число которых равно числу индексных записей, размещаемых в одном блоке. Количество обращений к диску при этом для поиска любой записи одинаково и равно количеству уровней в построенном дереве. Исключение составляет самый нижний уровень, где расположены записи основной области. Именно эти записи и являются «листьями» (конечными вершинами) данного дерева. Такие деревья называются сбалансированными (balanсed) именно потому, что путь от корня до любого листа в этом древе одинаков. Термин «сбалансированное» (от английского balanced — сбалансированный, взвешенный) и дал название данному методу организации индекса. Не путайте, пожалуйста, с двоичными деревьями, они также могут иметь сокращение B-tree (Binary Tree), но это совсем другая структура. Построим подобное дерево для нашего примера и рассчитаем для него количество уровней и, соответственно, количество обращений к диску. На первом уровне, как нам известно, число блоков равно числу блоков основной области — 12 500 блоков. Второй уровень образуется из неплотного индекса, мы его тоже уже строили и вычислили, что количество блоков индексной области в этом случае равно 172 блокам. А теперь над этим вторым уровнем снова построим неплотный индекс. Не будем менять длину индексной записи, а будем считать ее прежней, равной 14 байтам. Количество индексных записей в одном блоке нам тоже известно и равно 73. Поэтому сразу определим, сколько блоков нам необходимо для хранения ссылок на 172 блока: KIB 3 = KIB 2 /KZIB = 172/73 = 3 блока. Основной файл F1
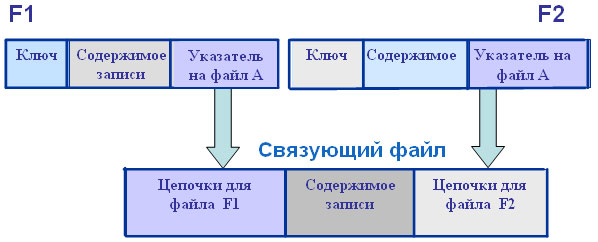
В подчиненном файле также к каждой записи добавляется специальный указатель, в нем хранится номер записи, которая является следующей в цепочке записей подчиненного файла, связанной с одной записью основного файла. Таким образом, каждая запись подчиненного файла делится на две области: область указателя и область, содержащую собственно запись. Структура подчиненного файла:
В качестве примера рассмотрим связь между преподавателями и занятиями, которые эти преподаватели проводят. В файле F1 приведен список преподавателей, а в файле F2 — список занятий, которые они ведут.
В этом случае содержимое двух взаимосвязанных файлов F1 и F2 может быть расшифровано следующим образом: первая запись в файле F1 связана с цепочкой записей файла F2, которая начинается с записи номер 1, следующая запись номер 4 и последняя запись в цепочке — запись номер 5. Последняя — потому, что пятая запись не имеет ссылки на следующую запись в цепочке. Аналогично можно расшифровать и остальные связи. Если мы проведем интерпретацию данных связей на уровне предметной области, то можно утверждать, что преподаватель Иванов ведет предмет «Вычислительные сети» в группе 4306, «Моделирование» в группе 84305 и «Вычислительные сети» в группе 4309. Однако часто бывает необходимо просматривать цепочку подчиненных записей в прямом и обратном направлениях. В этом случае применяют двойные указатели. В основном файле один указатель равен номеру первой записи в цепочке записей подчиненного файла, а второй — номеру последней записи. В подчиненном файле один указатель равен номеру следующей записи в цепочке, а другой — номеру предыдущей записи в цепочке. Для первой и последней записей в цепочке один из указателей пуст, т. е. равен пробелу. Для нашего примера это выглядит следующим образом:
Один файл (подчиненный или основной) может быть связан с несколькими другими файлами, при этом для каждой связи моделируются свои указатели. Связь двух основных файлов F1 и F2 с одним связующим файлом F3 моделируется как показано на рис. 11.5.
Рис. 11.5. Взаимосвязь двух основных и одного связующего файлов 132. Какие типы страниц используются в MSSQLServer? Как организованы страницы данных в MS SQL Server? В SQL 2000 существуют 6 основных типов страниц: · страница данных (Data page). В станицах этого типа хранятся структурированные данные, т. е. все типы данных, исключая тип text, ntext, image; · индексные страницы (Index page). В страницах этого типа хранятся индексы; · текстовые страницы (Text/image page). В страницах данного типа хранятся как раз слабоструктурированные данные типа text, ntext, image; · карты распределения блоков (Global allocation map page), часто именуемые GAM. Этот тип страниц хранит информацию об использовании экстентов (блоков); · карты свободного пространства (Page free space page). В страницах этого типа хранится информация о свободном пространстве на страницах; · индексные карты размещения (Index Allocation Map page), называемые IAM. Страницы этого типа хранят информацию об экстентах, которые используются конкретными таблицами или индексами. Организация страницы данных(параметры): · номер страницы в формате <номер файла, номер страницы>; · идентификатор объекта, которому принадлежит страница; · номер индекса, которому принадлежит страница; · уровень внутри индексного дерева, которому принадлежит страница; · количество отведенных строк на странице, количество заполненных слотов; · общий объем свободного пространства на странице; · указатель на расположение свободного пространства после последней строки на странице; · минимальная длина строки на странице; · объем зарезервированного пространства.
Типовые задания Задание 1. Написать запросы в реляционной алгебре Даны отношения, моделирующие работу туристического агенства, имеющего много филиалов в различных странах: R1
R2
R3
Составить запросы, позволяющие выбрать: 1. Клиентов, заключивших договоры с несколькими филиалами. 2. Филиалы, которые работают с клиентами только одной страны. 3. Клиентов, которые заключили несколько договоров с одним филиалом. 4. Филиалы, которые заключили договоры только с клиентами из той же станы, в которой расположен этот филиал. 5. Клиентов, которые заключили несколько договоров с разными филиалами. 6. Клиентов, которые заключили только один договор. 7. Задание 2. Схема БД, которая моделирует работу с лицевыми счетами физических лиц.
Список всех атрибутов с указанием их типа
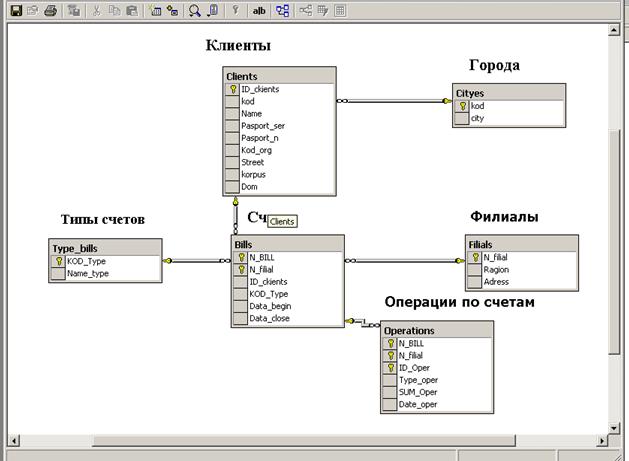
Физическая модель БД «bank» на сервере
Написать запросы на языке SQL
1. Вывести список филиалов банка, которые имеют минимальное количество счетов. 2. Вывести список районов с указанием количества филиалов банка, которые расположены в данном районе. 3. Вывести список счетов, которые открыты в филиале номер 1 нашего банка. 4. Вывести сумму вкладов на всех счетах филиала № 1 5. Вывести остаток на всех счетах господина Андреева А.А. 6. Вывести количество операций занесения денег на каждый счет, т.е. получить таблицу <счет, количество операций > 7. Вывести общую сумму снятых денег со всех счетов господина Андреева А.А. 8. Вывести список филиалов банка с указанием количества счетов каждого типа, открытых в данных филиалах. 9. Вывести список филиалов, в которых не открыто ни одного счета. 10. Вывести список клиентов, которые открыли счета, по которым не выполнено ни одной операции занесения или снятия денег.
Задание 3. Дана таблица:
По заданной таблице выполнить следующие действия:
1. Проанализировать содержание таблицы и выбрать 2 столбца,между которыми существует связь М:М (многие к многим). 2. Для выбранных столбцов привести логическую схему БД, моделирующую данные соответствующие связи (в нотации сетевой модели). 3. Представить схему связей между экземплярами соответствующих наборов, соответствующую данным, приведенным в исходной таблице. 4. Представить физическую модель, соответствующую данной логической схеме базы данных с использованием двунаправленных цепочек. 5. Представить изменения значений указалей при выполнении двух следующих действий над наблицей: · удалении 4-ой стро
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2017-01-27; просмотров: 127; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.145.52.86 (0.141 с.) |