
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Операция «соединения» и ее свойства.Стр 1 из 13Следующая ⇒
Операция «соединения» и ее свойства. Реляционная алгебра. Реляционная алгебра представляет собой основу доступа к реляционным данным. Основная цель алгебры – обеспечить запись выражений. Реляционная алгебра, определенная Коддом состоит из 8 операторов, составляющих 2 группы:
В основе реляционной модели лежит понятие «отношение». Отношение представляет собой подмножество декартова произведения доменов. Доменом называется некоторое множество допустимых значений, которое может принимать некоторый атрибут объекта. Декартовым произведением доменов D1, D2,...Dn называется
множество всех кортежей состоящих из k элементов - по одному из каждого домена. Таким образом декартово произведение позволяет получить все возможные комбинации из элементов доменов. Математически отношение записывается как
Кортежем называется элемент отношения. Математическое отношение используется двояко: 1. Для представления набора объектов (набор объектов - это множество подобных объектов). 2. Для предоставления связей между наборами объектов. Для представления набора объектов атрибуты соответствуют столбцами отношения. Множество допустимых значений атрибута соответствует соответствующему домену. Каждый кортеж отношения выполняет роль описания отдельного объекта из набора, при этом отношение выполняет роль описания всего набора объектов. Схемой отношения называют список имен атрибутов отношения. Если отношение R, а его схема имеет атрибуты A1,A2,...Ak, то схема отношения записывается как R(A1,A2,...Ak) Разложение без потерь. Теорема. Примеры Реляционная алгебра. Реляционная алгебра представляет собой основу доступа к реляционным данным. Основная цель алгебры – обеспечить запись выражений. Реляционная алгебра, определенная Коддом состоит из 8 операторов, составляющих 2 группы:
В основе реляционной модели лежит понятие «отношение».
Отношение представляет собой подмножество декартова произведения доменов. Доменом называется некоторое множество допустимых значений, которое может принимать некоторый атрибут объекта. Декартовым произведением доменов D1, D2,...Dn называется
множество всех кортежей состоящих из k элементов - по одному из каждого домена. Таким образом декартово произведение позволяет получить все возможные комбинации из элементов доменов. Математически отношение записывается как
Кортежем называется элемент отношения. Математическое отношение используется двояко: 3. Для представления набора объектов (набор объектов - это множество подобных объектов). 4. Для предоставления связей между наборами объектов. Для представления набора объектов атрибуты соответствуют столбцами отношения. Множество допустимых значений атрибута соответствует соответствующему домену. Каждый кортеж отношения выполняет роль описания отдельного объекта из набора, при этом отношение выполняет роль описания всего набора объектов. Схемой отношения называют список имен атрибутов отношения. Если отношение R, а его схема имеет атрибуты A1,A2,...Ak, то схема отношения записывается как R(A1,A2,...Ak) Теорема Хита. Пусть задано отношение r {A, B, C} (A, B и C, в общем случае, являются составными атрибутами) и выполняется FD A
Рис. 1. Результат естественного соединения отношений СЛУЖ и ЗАРП_ПРО Тогда r = (r PROJECT {A, B}) NATURAL JOIN (r PROJECT {A, C}). Доказательство. Прежде всего, докажем, что в теле результата естественного соединения (обозначим этот результат через r1) содержатся все кортежи тела отношения r. Действительно, пусть кортеж {a, b, c}
Для иллюстрации общего случая применения теоремы Хита рассмотрим отношение СЛУЖАЩИЕ_ОТДЕЛЫ_ПРОЕКТЫ {СЛУ_НОМ, СЛУ_ОТД, ПРО_НОМ} (рис 2). Атрибут СЛУ_ОТД содержит номера отделов, в которых работают служащие, а ПРО_НОМ – номера проектов, в которых служащие принимают участие. Каждый служащий работает только в одном отделе, т. е. имеется FD СЛУ_НОМ
Рис. 2. Декомпозиция без потерь по теореме Хита. В отношении СЛУЖАЩИЕ_ОТДЕЛЫ_ПРОЕКТЫ атрибут СЛУ_НОМ не является возможным ключом, но, как показано на рис 2., наличия FD СЛУ_НОМ Полностью соединимые отношения. Примеры Реляционная алгебра. Реляционная алгебра представляет собой основу доступа к реляционным данным. Основная цель алгебры – обеспечить запись выражений. Реляционная алгебра, определенная Коддом состоит из 8 операторов, составляющих 2 группы:
В основе реляционной модели лежит понятие «отношение». Отношение представляет собой подмножество декартова произведения доменов. Доменом называется некоторое множество допустимых значений, которое может принимать некоторый атрибут объекта. Декартовым произведением доменов D1, D2,...Dn называется
множество всех кортежей состоящих из k элементов - по одному из каждого домена. Таким образом декартово произведение позволяет получить все возможные комбинации из элементов доменов. Математически отношение записывается как
Кортежем называется элемент отношения. Математическое отношение используется двояко: 5. Для представления набора объектов (набор объектов - это множество подобных объектов). 6. Для предоставления связей между наборами объектов. Для представления набора объектов атрибуты соответствуют столбцами отношения. Множество допустимых значений атрибута соответствует соответствующему домену. Каждый кортеж отношения выполняет роль описания отдельного объекта из набора, при этом отношение выполняет роль описания всего набора объектов. Схемой отношения называют список имен атрибутов отношения. Если отношение R, а его схема имеет атрибуты A1,A2,...Ak, то схема отношения записывается как R(A1,A2,...Ak) Условие полного соединения.
Пример: r(A,B) s(A,B) q(A,B,C) ab1 b1c ab1c ab2
ab – неполное соединение
b1c - полное соединение. Для того чтобы было полное соединение необходимо, чтобы в соединяемых столбцах были все значения R и S. Управление транзакциями Под транзакцией понимается неделимая с точки зрения воздействия на БД последовательность операторов манипулирования данными (чтения, удаления, вставки, модификации) такая, что либо результаты всех операторов, входящих в транзакцию, отображаются в БД, либо воздействие всех этих операторов полностью отсутствует.
Операция считается транзакцией, если она удовлетворяет требованиям ACID-теста (Atomicity, Consistency, Isolation, Durability атомарность, согласованность, изолированность, долговечность). Атомарность - лозунг транзакции - "Все или ничего": при завершении транзакции оператором COMMIT результаты гарантированно фиксируются во внешней памяти (смысл слова commit - "зафиксировать" результаты транзакции); при завершении транзакции оператором ROLLBACK результаты гарантированно отсутствуют во внешней памяти (смысл слова rollback - ликвидировать результаты транзакции). Согласованность – по окончанию транзакции целостность должна быть установлена, но в ходе выполнения транзакции целостность может временно нарушаться. Изолированность означает, что параллельно выполняющиеся транзакции не мешают друг другу. Долговечность означает, что все подтвержденные в ходе выполнения изменения должны быть внесены в базу данных даже в случае сбоев системы. Поддержание механизма транзакций - показатель уровня развитости СУБД. Корректное механизм поддержания транзакций одновременно является основой обеспечения целостности баз данных и также является базисом изолированности пользователей в многопользовательских системах. Часто эти два аспекта рассматриваются по отдельности, но на самом деле они взаимосвязаны, что и будет показано ниже. Уровни изоляции Стандарт SQL/92 определяет уровни изоляции транзакций в многопользовательской системе через отсутствие таких аномалий доступа к базе данных, которые могут в конечном итоге угрожать целостности данных. В стандарте различаются следующие аномалии: · Потерянные изменения. Транзакция Т1 читает данные. Транзакция Т2 читает те же данные. Транзакция T1 на основании прочитанного значения вычисляет новое значение данных, записывает его в базу данных и завершается. Транзакция T2 на основании прочитанного значения вычисляет новое значение данных, записывает его в базу данных и завершается. В результате значение, записанное транзакцией Т2, "затрет" значение, записанное транзакцией Т1. · Грязное чтение. Транзакция Т1 изменяет некоторые данные, но еще не завершается. Транзакция Т2 читает эти же данные (с изменениями, внесенными транзакцией Т1) и принимает на их основе какие-то решения. Транзакция Т1 выполняет откат. В результате решение, принятое транзакцией Т2 основано на неверных данных. · Неповторяющееся чтение. Транзакция Т1 в ходе своего выполнения несколько раз читает одни и те же данные. Транзакция Т2 в интервалах между чтениями транзакцией Т1 изменяет эти данные и фиксируется. В результате оказывается, что чтения одних и тех же данных в транзакции Т1 дает разные результаты.
· Фантом. Транзакция Т1 в ходе своего выполнения несколько раз выбирает множество строк по одним и тем же критериям. Транзакция Т2 в интервалах между выборками транзакции Т1 добавляет или удаляет строки или изменяет столбцы некоторых строк, используемых в критерии выборки, и фиксируется. В результате оказывается, что одни и те же выборки в транзакции Т1 выбирают разные множество строк. Определение уровней изоляции в стандарте:
Запуск транзакции В общем виде, синтаксис команды SQL для запуска транзакции: SET TRANSACTION [Access mode] [Lock Resolution] [Isolation Level] [Table Reservation] Значения, принимаемые по-умолчанию: SET TRANSACTION READ WRITE WAIT ISOLATION LEVEL SNAPSHOT Access Mode - определяет тип доступа к данным. Может принимать два значения: READ ONLY - указывает, что транзакция может только читать данные и не может модифицировать их. READ WRITE - указывает, что транзакция может читать и модифицировать данные. Это значение принимается по умолчанию. Пример: SET TRANSACTION READ WRITE Isolation Level - определяет порядок взаимодействия данной транзакции с другими в данной базе. Может принимать значения: · SNAPSHOT - значение по умолчанию. Внутри транзакции будут доступны данные в том состоянии, в котором они находились на момент начала транзакции. Если по ходу дела в базе данных появились изменения, внесенные другими завершенными транзакциями, то данная транзакция их не увидит. При попытке модифицировать такие записи возникнет сообщение о конфликте. · SNAPSHOT TABLE STABILITY - предоставляет транзакции исключительный доступ к таблицам, которые она использует. Другие транзакции смогут только читать данные из них. · READ COMMITTED - позволяет транзакции видеть текущее состояние базы. Конфликты, связанные с блокировкой записей происходят в двух случаях: · Транзакция пытается модифицировать запись, которая была изменена или удалена уже после ее старта. Транзакция типа READ COMMITTED может вносить изменения в записи, модифицированные другими транзакциями после их завершения. · Транзакция пытается модифицировать таблицу, которая заблокирована другой транзакцией типа SNAPSHOT TABLE STABILITY. Lock Resolution - определяет ход событий при обнаружении конфликта блокировки. Может принимать два значения: · WAIT - значение по умолчанию. Ожидает разблокировки требуемой записи. После этого пытается продолжить работу. · NO WAIT - немедленно возвращает ошибку блокировки записи. Table Reservation - позволяет транзакции получить гарантированный доступ необходимого уровня к указанным таблицам. Существует четыре уровня доступа:
· PROTECTED READ - запрещает обновление таблицы другими транзакциями, но позволяет им выбирать данные из таблицы. · PROTECTED WRITE - запрещает обновление таблицы другими транзакциями, читать данные из таблицы могут только транзакции типа SNAPSHOT или READ COMMITTED. · SHARED READ - самый либеральный уровень. Читать могут все, модифицировать - транзакции READ WRITE. · SHARED WRITE - транзакции SNAPSHOT или READ COMMITTED READ WRITE могут модифицировать таблицу, остальные - только выбирать данные. Завершение транзакции Когда все действия, составляющие транзакцию успешно выполнены или возникла ошибка, транзакция должна быть завершена, для того, чтобы база данных находилась в непротиворечивом состоянии. Для этого есть два SQL-выражения:
Технологии «клиент-сервер» Сервер – это компьютер, управляющий некоторыми ресурсами и предоставляющий их для коллективного использования. Сервера бывают почтовые, баз данных, вычислительные. Клиент – это программа или компьютер, обращающийся к услугам сервера Существуют разные технологии клиент-сервер. Любая программа может быть представлена из нескольких частей: 1. Ввод/вывод (интерфейсная часть); 2. Вычисление на основе каких-либо бизнес правил; 3. Обращение к данным; 4. Управляющая часть, создает единый алгоритм. В зависимости от того, как поделить эти части между сервером и клиентом, получаются различные технологии. 1 вариант - файловый сервер. Введем обозначения: К – клиент, С – сервер. К выполняет 1,2,4 части, а на С содержится информация, необходимая для запроса, т.е. С выполняет 3 часть.
К С ответ-файл В данной технологии основная нагрузка падает на клиента.
Данная технология позволяет получить только ту информацию, которая нас интересует, а не весь файл. Запросы пишутся на динамическом SQL. А в ответ получаем ту порцию информации, которую запросили, эта порция информации называется курсором. Динамический SQL - это операторы SQL, которые передаются и выполняются на сервере. Имеют место следующие операторы: Prepare имя_оператора from строка, Select, Insert, Delete, Update Execute имя_оператора – позволяет выполнить запомненный на сервере оператор; Drop имя_оператора – позволяет удалит оператор; Эти операторы передаются в интерактивном режиме, а если хотим записать в рамках какой-то программы, то, например на Паскале, это будет выглядеть так: Exec sql “sql оператор”. Описание курсора на SQL: Declare имя_курсора [scroll] cursor for подзапрос [for update]. Курсор может быть обычным, то есть просматриваемым в одном направлении, от начала к концу, если стоит scroll, то просматривать курсор можно в любом направлении. Если стоит for update, то это значит, что курсор изменяемый, все изменения будут запоминаться на сервере. Операции с курсором: Open имя_курсора – позволяет получить курсор; Fetch имя_курсора – позволяет перейти к следующей записи курсора, если перед именем курсора поставить Last, то перейдем к последней записи, First – к первой записи, Current к текущей; Close имя_курсора – закрытие курсора, но он остается определенным; Free имя_курсора – удаление курсора. 3 вариант – сервер Базы Данных.
Бизнес-правила хранятся на сервере в виде хранимых процедур. Хранимые процедуры – это программы, написанные на некотором языке хранимых процедур с SQL вставками. Их можно написать заранее и поместить в библиотеку. Модель сервера базы данных В архитектуре клиент-сервер для обработки данных выделяется специальное ядро - так называемый сервер баз данных, который принимает на себя функции обработки запросов пользователей, именуемых теперь клиентами. Сервер баз данных представляет собой программу, выполняющуюся, как правило, на мощном компьютере. Приложения-клиенты посылают с рабочих станций запросы на выборку (вставку, обновление, удаление) данных. При этом сервер выполняет всю “грязную” работу по отбору данных, отправляя клиенту только требуемую “выжимкуТакой подход обеспечивает решение трех важных задач:
Модель сервера приложений.
Оператор Select Оператор SELECT – один из наиболее важных и самых распространенных операторов SQL. Он позволяет производить выборки данных из таблиц и преобразовывать к нужному виду полученные результаты. Будучи очень мощным, он способен выполнять действия, эквивалентные операторам реляционной алгебры, причем в пределах единственной выполняемой команды. При его помощи можно реализовать сложные и громоздкие условия отбора данных из различных таблиц. Оператор SELECT – средство, которое полностью абстрагировано от вопросов представления данных, что помогает сконцентрировать внимание на проблемах доступа к данным. Примеры его использования наглядно демонстрируют один из основополагающих принципов больших (промышленных) СУБД: средства хранения данных и доступа к ним отделены от средств представления данных. Операции над данными производятся в масштабе наборов данных, а не отдельных записей. Оператор SELECT имеет следующий формат: SELECT [ALL | DISTINCT ] {*|[имя_столбца [AS новое_имя]]} [,...n] FROM имя_таблицы [[AS] псевдоним] [,...n] [WHERE <условие_поиска>] [GROUP BY имя_столбца [,...n]] [HAVING <критерии выбора групп>] [ORDER BY имя_столбца [,...n]] Оператор SELECT определяет поля (столбцы), которые будут входить в результат выполнения запроса. В списке они разделяются запятыми и приводятся в такой очередности, в какой должны быть представлены в результате запроса. Если используется имя поля, содержащее пробелы или разделители, его следует заключить в квадратные скобки. Символом * можно выбрать все поля, а вместо имени поля применить выражение из нескольких имен. Если обрабатывается ряд таблиц, то (при наличии одноименных полей в разных таблицах) в списке полей используется полная спецификация поля, т.е.Имя_таблицы.Имя_поля. Предложение FROM Предложение FROM задает имена таблиц и просмотров, которые содержат поля, перечисленные в операторе SELECT. Необязательный параметр псевдонима – это сокращение, устанавливаемое для имени таблицы. Обработка элементов оператора SELECT выполняется в следующей последовательности: · FROM – определяются имена используемых таблиц; · WHERE – выполняется фильтрация строк объекта в соответствии с заданными условиями; · GROUP BY – образуются группы строк, имеющих одно и то же значение в указанном столбце; · HAVING – фильтруются группы строк объекта в соответствии с указанным условием; · SELECT – устанавливается, какие столбцы должны присутствовать в выходных данных; · ORDER BY – определяется упорядоченность результатов выполнения операторов. Порядок предложений и фраз в операторе SELECT не может быть изменен. Только два предложения SELECT и FROM являются обязательными, все остальные могут быть опущены. SELECT – закрытая операция: результат запроса к таблице представляет собой другую таблицу. Существует множество вариантов записи данного оператора, что иллюстрируется приведенными ниже примерами. Предикат DISTINCT следует применять в тех случаях, когда требуется отбросить блоки данных, содержащие дублирующие записи в выбранных полях. Значения для каждого из приведенных в инструкцииSELECT полей должны быть уникальными, чтобы содержащая их запись смогла войти в выходной набор. Предложение WHERE С помощью WHERE-параметра пользователь определяет, какие блоки данных из приведенных в списке FROM таблиц появятся в результате запроса. За ключевым словомWHERE следует перечень условий поиска, определяющих те строки, которые должны быть выбраны при выполнении запроса. Существует пять основных типов условий поиска (или предикатов): · Сравнение: сравниваются результаты вычисления одного выражения с результатами вычисления другого. · Диапазон: проверяется, попадает ли результат вычисления выражения в заданный диапазон значений. · Принадлежность множеству: проверяется, принадлежит ли результат вычислений выражения заданному множеству значений. · Соответствие шаблону: проверяется, отвечает ли некоторое строковое значение заданному шаблону. · Значение NULL: проверяется, содержит ли данный столбец определитель NULL (неизвестное значение). Сравнение В языке SQL можно использовать следующие операторы сравнения: = – равенство; < – меньше; > – больше; <= – меньше или равно; >= – больше или равно; <> – не равно. Более сложные предикаты могут быть построены с помощью логических операторов AND, OR или NOT, а также скобок, используемых для определения порядка вычисления выражения. Вычисление выражения в условиях выполняется по следующим правилам: · Выражение вычисляется слева направо. · Первыми вычисляются подвыражения в скобках. · Операторы NOT выполняются до выполнения операторов AND и OR. · Операторы AND выполняются до выполнения операторов OR. Оператор BETWEEN используется для поиска значения внутри некоторого интервала, определяемого своими минимальным и максимальным значениями. При этом указанные значения включаются в условие поиска. Оператор IN используется для сравнения некоторого значения со списком заданных значений, при этом проверяется, соответствует ли результат вычисления выражения одному из значений в предоставленном списке. При помощи оператора IN может быть достигнут тот же результат, что и в случае применения оператора OR, однако оператор IN выполняется быстрее. Предложение ORDER BY В общем случае строки в результирующей таблице SQL-запроса никак не упорядочены. Однако их можно требуемым образом отсортировать, для чего в оператор SELECT помещается фраза ORDER BY, которая сортирует данные выходного набора в заданной последовательности. Сортировка может выполняться по нескольким полям, в этом случае они перечисляются за ключевым словом ORDER BY через запятую. Способ сортировки задается ключевым словом, указываемым в рамках параметра ORDER BY следом за названием поля, по которому выполняется сортировка. По умолчанию реализуется сортировка по возрастанию. Явно она задается ключевым словом ASC. Для выполнения сортировки в обратной последовательности необходимо после имени поля, по которому она выполняется, указать ключевое слово DESC. Предложение GROUP BY Часто в запросах требуется формировать промежуточные итоги, что обычно отображается появлением в запросе фразы "для каждого...". Для этой цели в операторе SELECT используется предложение GROUP BY. Запрос, в котором присутствует GROUP BY, называется группирующим запросом, поскольку в нем группируются данные, полученные в результате выполнения операции SELECT, после чего для каждой отдельной группы создается единственная суммарная строка. Стандарт SQL требует, чтобы предложение SELECT и фраза GROUP BY были тесно связаны между собой. При наличии в операторе SELECT фразы GROUP BY каждый элемент списка в предложении SELECT должен иметь единственное значение для всей группы. Более того, предложение SELECT может включать только следующие типы элементов: имена полей, итоговые функции, константы и выражения, включающие комбинации перечисленных выше элементов. Предложение HAVING При помощи HAVING отражаются все предварительно сгруппированные посредством GROUP BY блоки данных, удовлетворяющие заданным в HAVING условиям. Это дополнительная возможность "профильтровать" выходной набор. Соединение - это процесс, когда две или более таблицы объединяются в одну. Способность объединять информацию из нескольких таблиц или запросов в виде одного логического набора данных обусловливает широкие возможности SQL. Формат операции: FROM имя_таблицы_1 {INNER | LEFT | RIGHT} JOIN имя_таблицы_2 ON условие_соединения Операция тета-соединения в языке SQL называется INNER JOIN (внутреннее соединение) и используется, когда нужно включить все строки из обеих таблиц, удовлетворяющие условию объединения. Внешнее соединение похоже на внутреннее, но в результирующий набор данных включаются также записи ведущей таблицы соединения, которые объединяются с пустым множеством записей другой таблицы. Какая из таблиц будет ведущей, определяет вид соединения. LEFT - левое внешнее соединение, ведущей является таблица, расположенная слева от вида соединения; RIGHT - правое внешнее соединение, ведущая таблица расположена справа от вида соединения. Пример: Определить суммарную стоимость каждого товара первого сорта за каждый месяц. SELECT Товар.Название, Month(Сделка.Дата) AS Месяц, Sum(Товар.Цена*Сделка.Количество) AS Стоимость FROM Товар INNER JOIN Сделка ON Товар.КодТовара=Сделка.КодТовара WHERE Товар.Сорт="Первый" GROUP BY Товар.Название, Month(Сделка.Дата) Для товаров первого сорта установить цену в значение 140 и остаток – в значение 20 единиц. UPDATE Товар SET Товар.Цена=140, Товар.Остаток=20 WHERE Товар.Сорт=" Первый " Вывести информацию о всех товарах. Для проданных товаров будет указана дата сделки и количество. Для непроданных эти поля останутся пустыми. SELECT Товар.*, Сделка.* FROM Товар LEFT JOIN Сделка ON Товар.КодТовара=Сделка.КодТовара; Индексация. Достоинства и недостатки. Примеры Самая распространённая задача, которую решают приложения работающие с базами данных - это поиск необходимых записей по заданному критерию. Внутренняя модель данных рассматривает задачу хранения информации на внешних носителях с целью: · уменьшения внешней памяти. · уменьшения времени доступа к требуемой информации. Эти цели достигаются при помощи использования факторизации и индексации. Индексация используется для увеличения скорости доступа к данным за счет применения индекса. Индекс - это таблица из 2-х полей, в которой первое поле является ключом индексации в сортированном порядке, а второе поле содержит указатель записи файла, в которой хранится ключ индексации. Ключом индексации называется поле или часть поля или совокупность полей, по которым осуществляется поиск информации. Указатель же (ссылка) используется для адресации объектов в памяти и может быть:- абсолютным адресом - относительным адресом (состоящим из базы и смещения) - каким-либо специальным символом или флажком, помечающим место хранения объекта. Индекс позволяет производить дихотомический или двоичный поиск. Индекс позволяет ускорить поиск и представить файл в отсортированном виде без физического перемещения записей. Индекс можно хранить в памяти, так как он занимает мало места. Виды индексов: Плотный индекс позволяет точно определить, где найти каждый член. Неплотный индекс дает возможность установить блок, который содержит данный член, но не позволяет точно определить в каком месте он находится. В Уникальном индексе только один указатель может быть связан с соответствующим ему ключом. Уникальные индексы - это индексы строящиеся по первичному ключу. Селективный индекс строится по некоторому подмножеству значений, выбираемому из множества возможных значений по определенном условию. Основная идея Иерархического индекса заключается в том, что можно добиться повышения эффективности, используя индекс, позволяющий перейти к более детальному индексу, который в свою очередь, позволяется перейти к еще более детальному индексу и т.д. до тех пор, пока не будут достигнуты реальные данные. Как бы не были организованы индексы в конкретной СУБД, их основное назначение состоит в обеспечении эффективного прямого доступа к кортежу отношения по ключу. Индекс определяется для одного отношения, и ключом является значение атрибута (возможно, составного). Если ключом индекса является возможный ключ отношения, то индекс должен обладать свойством уникальности, т.е. не содержать дубликатов ключа. На практике ситуация выглядит обычно так: при объявлении первичного ключа отношения автоматически заводится уникальный индекс, а единственным способом объявления возможного ключа, отличного от первичного, является явное создание уникального индекса. Это связано с тем, что для проверки сохранения свойства уникальности возможного ключа, так или иначе, требуется индексная поддержка. Поскольку при выполнении многих операций языкового уровня требуется сортировка отношений в соответствии со значениями некоторых атрибутов, полезным свойством индекса является обеспечение последовательного просмотра кортежей отношения в диапазоне значений индекса в порядке возрастания или убывания значений. Наконец, одним из способов оптимизации выполнения эквисоединения отношений (наиболее распространенная из числа дорогостоящих операций) является организация так называемых мультииндексов для нескольких отношений, обладающих общими атрибутами. Любой из этих атрибутов (или их набор) может выступать в качестве ключа мультииндекса. Значению ключа сопоставляется набор кортежей всех связанных мультииндексом отношений, значения выделенных атрибутов которых совпадают со значением ключа. Общей идеей любой организации индекса, поддерживающего прямой доступ по ключу и последовательный просмотр в порядке возрастания или убывания значений ключа является хранение упорядоченного списка значений ключа с привязкой к каждому значению ключа списка идентификаторов кортежей. Одна организация индекса отличается от другой главным образом в способе поиска ключа с заданным значением. Производительность Для оптимальной производительности запросов индексы обычно создаются на тех столбцах таблицы, которые часто используются в запросах. Для одной таблицы может быть создано несколько индексов. Однако увеличение числа индексов замедляет операции добавления, обновления, удаления строк таблицы, поскольку при этом приходится обновлять сами индексы. Кроме того индексы занимают дополнительный объем памяти, поэтому перед созданием индекса следует убедиться, что планируемый выигрыш в производительности запросов превысит дополнительную затрату ресурсов компьютера на сопровождение индекса. B-деревья
|
||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2017-01-25; просмотров: 349; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.142.173.227 (0.147 с.) |
 где D1 = {d1.1,d1.2,...d1.k} и т.д.
где D1 = {d1.1,d1.2,...d1.k} и т.д.
 B.
B.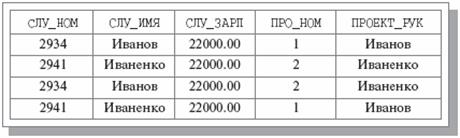
 r. Тогда по определению операции взятия проекции {a, b}
r. Тогда по определению операции взятия проекции {a, b} 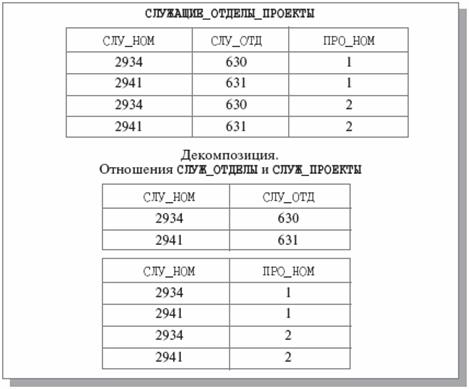
 Дано r(R) и s(S), тогда q(RS)=r s
Дано r(R) и s(S), тогда q(RS)=r s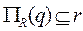 , если выполняется равенство, то r полностью соединимо.
, если выполняется равенство, то r полностью соединимо. , если выполняется равенство, то s полностью соединимо.
, если выполняется равенство, то s полностью соединимо. A,B
A,B B,C
B,C запрос
запрос 2 вариант – удаленный доступ.
2 вариант – удаленный доступ.



