Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Основной алгоритм скорости ячеек
Соглашение по трафику основывается на так называемом основном алгоритме скорости ячеек (Generic Cell Rate Algorithm - GCRA). Иногда его называют “дырявое ведро” (continuous leaky bucket), и эта аналогия будет использоваться далее. Данный алгоритм точно определяет, когда поток ячеек нарушает или не нарушает соглашение по трафику. Рассмотрим последовательность прибывающих ячеек. Эта последовательность обрабатывается для определения того, какая ячейка нарушает соглашение. Алгоритм определяется двумя параметрами: инкрементный параметр “l” и ограничивающий параметр “L”. Представим ведро с дырой в дне. Одна порция жидкости вытекает из ведра за один период времени. Параметр “l” управляет тем, как часто порция жидкости может быть налита в ведро. Это также можно представлять, как время, которое должно проходить между ячейками. Следовательно, “скорость” поступления порций жидкости в секунду обратно пропорциональна значению параметра “l”. Чем больше “l”, тем больше время, которое должно пройти между допустимыми порциями, т.е. скорость передачи снижается. Параметр “L” схож с параметром “l”, за исключением того, что “L” влияет на размер выбросов нагрузки, которые могут быть обслужены. Таким образом, “l” и “L” вместе определяют размер ведра. Предположим, что l=1. В этом случае ячейка может быть передана сразу же после того, как она появилась на приемном порту, т.е. скорость передачи ячеек равна скорости канала (линии). Если l=2, то ячейка может быть передана в каждый второй промежуток времени, т.е. скорость передачи ячеек будет составлять половину скорости канала (линии). (Здесь, для простоты, мы игнорируем параметр “L”). Таким образом, 1/l представляет собой допустимую скорость передачи ячеек как часть скорости передачи ячеек в линии. Другими словами, скорость передачи ячеек (ячейки/сек) = (1/l) ´ скорость передачи ячеек в линии (ячейки/сек). Чтобы быть чуть более конкретными, представим, что в ведро наливается вода и что из ведра через дыру выливается один литр воды в единицу времени (за время передачи ячейки). Каждый раз, когда в сеть для данного соединения поступает ячейка, то сидящий рядом с ведром контролер трафика выливает в ведро “l” литров воды. Конечно, вода начинает вытекать.
Если l=2, то только одна из двух ячеек приводит к помещению порции воды в ведро. Другая ячейка может содержать “воду” для другого интерфейса или она может быть просто “пустой”. Если ведро изначально пусто, то в него может поместиться много порций воды, но в конце концов оно заполнится. Конечно хорошо, если это случится попозже. Общая скорость, которая может быть обслужена, зависит от разницы между величиной “l” и скоростью вытекания. “l” определяет общую (“долгосрочную”) скорость передачи ячеек. “L” определяет размер неравномерности нагрузки, поскольку он определяет размер ведра. Следовательно, “L” определяет каким образом ячейки проходят через сеть. Это иллюстрируется двумя следующими подразделами.
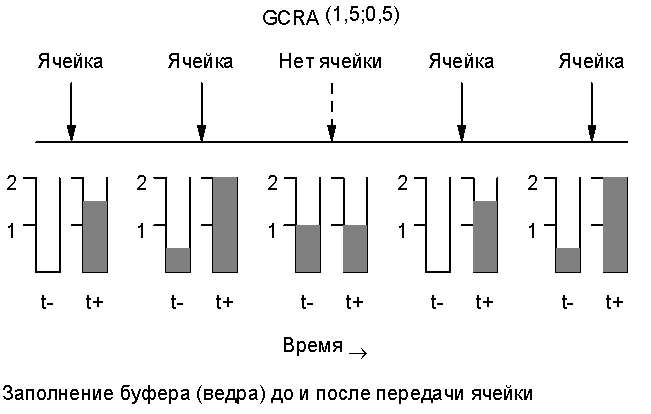
Равномерный трафик Рассмотрим работу алгоритма GCRA на примере равномерного трафика. На диаграмме показано поступление ячеек, а также состояние ведра до (t-) и после (t+) поступления ячейки. Предположим, что ведро пусто и поступает ячейка для данного соединения. Наливаем полтора литра воды в ведро. (Каждой ячейке соответствует полтора литра. Это инкрементный параметр “l”. Однако, за единицу времени может выливаться только один литр.) Ко времени поступления следующей ячейки выливается один литр и в ведре остается пол-литра воды. Доливаем в ведро еще полтора литра, соответствующих второй поступившей ячейке. Теперь ведро содержит пол-литра от предыдущей ячейки и полтора - от поступившей, т.е. ведро заполнено. Если в следующей момент поступит ячейка, то она будет нарушать соглашение, т.к. в ведре нет места для очередных полутора литров воды. Предположим, что мы выполняем правила и не посылаем очередной ячейки, т.е. уровень воды в ведре остается прежним. В следующий момент вытекает и оставшаяся вода и мы снова имеем пустое ведро, т.е. то состояние, с которого начали. Такой тип трафика называют “равномерным”, поскольку он имеет периодичный характер. В данной случае за три единицы времени передаются две ячейки и это повторяется периодически. Конечно, две ячейки из трех дают отношение, обратное инкрементному параметру l=1,5. Меняя величину параметра “l” и скорость вытекания можно получить желаемое соотношение переданных ячеек и общего времени - 17 из 23, 15 из 16 и т.д. Это дает полную гибкость для достижения любой степени детализации скорости передачи.
Неравномерный трафик Теперь рассмотрим пример неравномерного трафика. Увеличим значение ограничивающего параметра до 7, а инкрементного - до 4,5, т.е. емкость ведра составит 7 + 4,5=11,5. В данном примере передаются три ячейки и ведро после них заполнено почти полностью, т.к. инкрементный параметр достаточно велик. После этого приходится ждать (и достаточно долго), пока вода будет выливаться из ведра литр за литром, прежде чем можно будет передавать очередную ячейку. Если дождаться момента полного освобождения ведра, то можно будет опять передать очередную порцию из трех ячеек. Этот пример демонстрирует тот факт, что увеличение ограничивающего параметра позволяет обслуживать значительно неравномерный тип трафика.
Идентификатор типа нагрузки Поле идентификатора типа нагрузки (Payload Type Identifier) содержит три бита. Первый бит служит для обозначения собственно типа ячейки: пользовательская или служебная. (Служебные ячейки могут использоваться для диагностики сети АТМ. Допустим, что посылаемые в сеть ячейки не достигают пункта назначения. Тогда можно послать в сеть ячейку с установленным битом - служебную ячейку. Эта ячейка будет иметь тот же VPI/VCI и будет проходить тем же маршрутом. Однако, поскольку это служебная ячейка, коммутаторы могут идентифицировать ее и размещать в поле нагрузки данной ячейки информацию о ее прохождении. Более того, в некоторой точке сети ячейка может быть отправлена обратно). Если ячейка пользовательская, то второй бит PTI называется битом уведомления приемника о перегрузке (Explicit Forward Congestion Indicator - EFCI). Если ячейка проходит через точку сети, которая находится в состоянии перегрузки, то данный бит устанавливается. В этой точке бит EFCI используется для управления перегрузкой для категории обслуживания доступной скорости передачи ARB. Опять же, если ячейка пользовательская, третий бит переносится сетью прозрачно. В настоящее время он определен только для использования уровнем адаптации АТМ AAL5.
Основное управление потоком Поле основного управления потоком (Generic Flow Control) занимает первые четыре бита заголовка. Оно определено только для UNI. Оно не используется в интерфейсе узел - сеть (Network Node Interface - NNI), который является интерфейсом коммутаторов АТМ. Поле GFC в настоящее время еще не определено, зарезервировано и принято равным нулю. Возможным использованием этого поля может являться управление потоком или множественный доступ к разделяемой сети АТМ с использованием местных средств доступа.
Контрольная сумма заголовка Последние восемь бит заголовка являются контрольной суммой заголовка (header error check - HEC). При прохождении ячейки через сеть ее VPI/VCI могут быть испорчены ошибками, что может привести к доставке ячейки не по назначению. Для обнаружения и исправления ошибок в заголовке используется HEC. Кроме того, HEC может использоваться физической средой, например, SDH при определении границ ячеек. HEC может использоваться в двух режимах. Первым является режим обнаружения ошибок с помощью циклического кода (CRC). Если ошибка в заголовке обнаруживается, то ячейка сбрасывается. Вторым режимом является режим исправления одиночных ошибок. Применение того и другого режима зависит от используемой физической среды. Если используется оптическое волокно, то исправления однократной ошибки оказывается вполне достаточно, поскольку в данной физической среде наиболее вероятны такие ошибки. При использовании в качестве физической среды медного кабеля наиболее вероятно группирование ошибок. В данном случае применение режима исправления однократной ошибки увеличивает риск восприятия многократной ошибки как однократной и ее неправильного “исправления”. Это происходит потому, что свойства обнаружения ошибок ухудшаются в режиме исправления ошибок.
Отметим, что HEC пересчитывается от соединения к соединению, поскольку она зависит от значений VPI/VCI, которые меняются при прохождении через сеть.
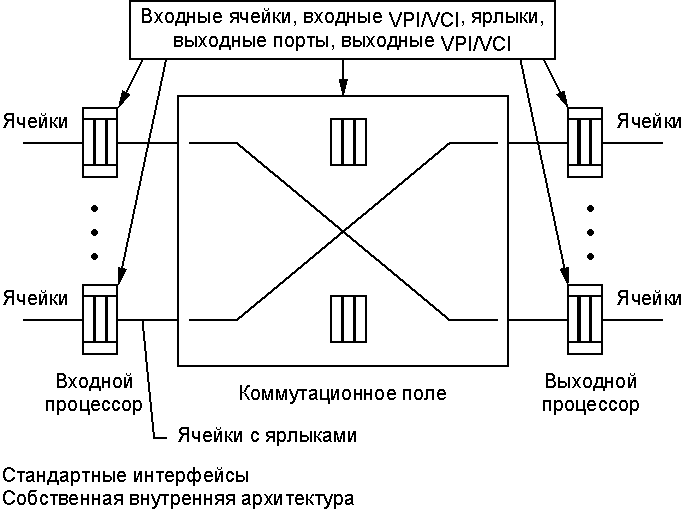
АТМ коммутация АТМ коммутация Рассмотрев физический уровень и заголовок ячейки, рассмотрим как коммутируются ячейки. В данном разделе дается общее описание способов коммутации, применяемых в коммутаторах АТМ. На рисунке показана общая схема коммутатора. В состав коммутатора входит коммутационное поле определенного типа, а также входные и выходные процессоры. Входной процессор анализирует заголовок и определяет в какой выходной порт должна направляться ячейка. Коммутатор использует рассмотренную выше таблицу соединений, причем ярлык может применяться или не применяться. (Обычно ярлык используется. Ярлык (tag) является сообщением процессора коммутационному полю, в котором коммутационному полю сообщается каким образом обрабатывать данную ячейку. Ярлык используется только внутри коммутатора, его формат различен для разных коммутаторов и зависит от типа коммутационного поля.) Заметим, что коммутационное поле, входные и выходные процессоры могут буферизировать информацию. Когда говорят о коммутаторе с буферизацией по входу, коммутаторе с буферизацией по выходу или коммутаторе с буферизацией в коммутационном поле, то это означает, что в данном узле производится основная буферизация ячеек.
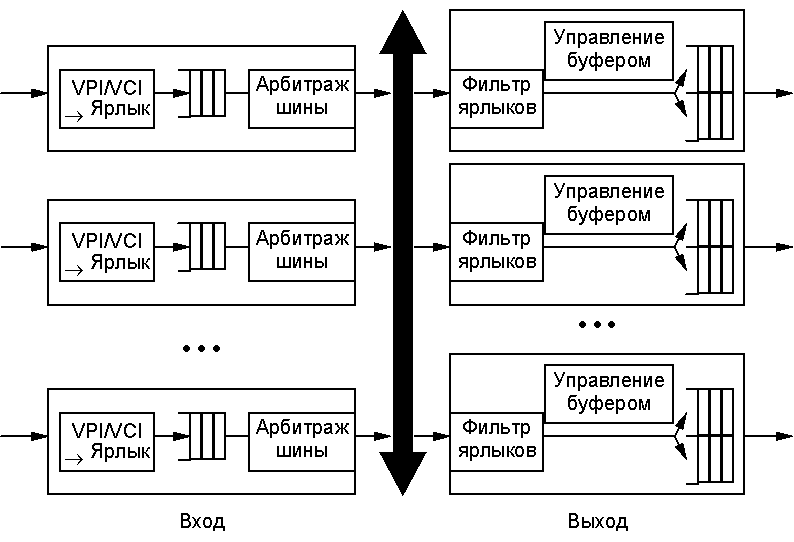
Разделяемая магистраль Небольшие коммутаторы АТМ, применяемые в локальных сетях, обычно строятся на основе общей среды, чаще всего разделяемой магистрали (шины) (Shared Backplane). На рисунке показаны входные процессоры, преобразующие VPI/VCI в ярлык. Доступ входных процессоров к общей разделяемой шине осуществляется на основе арбитража шины. Один из входных процессоров получает доступ к шине и посылает ячейку через общую шину на входы всех выходных процессоров.
Выходные процессоры анализируют ярлык с целью установления принадлежности данной ячейки данному выходному процессору. Выходной процессор, которому предназначается ячейка, считывает ее с шины, убирает ярлык (это выполняет фильтр ярлыков) и записывает ячейку в выходной буфер для последующей передачи в линию. Заметим, что поскольку каждый выходной процессор видит каждую ячейку, то для данной архитектуры вполне естественной является передача широковещательных сообщений. Для этой цели возможно использование специального типа ярлыка. В соединениях АТМ типа “точка - много точек” одна ячейка многократно копируется для передачи в сеть АТМ. Для таких соединений архитектура с разделяемой магистралью является наиболее приемлемой. Очень важным моментом в коммутации АТМ является управление выходным буфером. Наличие выходного буфера необходимо, поскольку на данный выходной порт могут поступать ячейки с нескольких входных портов и эти ячейки необходимо хранить до того, как они будут направлены в линию. На рисунке не случайно показаны два буфера. Почему два? Прежде всего по тому, что обычно гарантируются два типа качества обслуживания. Например, для речи желательно иметь малую задержку. На практике допустимо даже потерять ячейку с речевой информацией, нежели получить ее со значительной задержкой. Такой тип трафика можно направлять в отдельный относительно малый буфер. Передача данных, в отличие от речи, предъявляет совершенно другие требования. В этом случае потеря ячеек крайне нежелательна, поэтому для данного типа трафика организуется относительно большой буфер. Это несколько увеличит задержку на передачу данных, но потери ячеек будут существенно меньше.
Разделяемая память Еще одной возможной архитектурой является так называемая “разделяемая” или “коллективная память” (Shared Memory). Это двухпортовая память с возможностью чтения и записи в N раз быстрее скорости поступления ячеек с портов (N – число портов). Входные процессоры принимают ячейки. Устройство управления очередью определяет последовательность записи ячеек в буферы разделяемой памяти и считывания ячеек в буферы выходных процессоров. Назначение выходных процессоров аналогично рассмотренному выше. В данной архитектуре передача широковещательных сообщений обеспечивается хранением ячеек в буферах разделяемой памяти и их многократной записью в выходные порты. В данном случае основная буферизация производится в разделяемой памяти, т.е. в коммутационном поле.
Пространственное разделение Третьим типом архитектуры является пространственное разделение на основе простейших коммутационных элементов (self-routing fabric). Эта технология позволяет строить коммутационные элементы на основе многих небольших логических элементов.
Ярлык идентифицирует назначение ячейки. Каждый элемент принимает логическое решение. Например, допустим, что входящая ячейка получила ярлык 111. Первый бит анализируется на первом шаге. Поскольку он равен 1, ячейка коммутируется на нижний выход элемента и попадает на вход второго логического элемента. Он анализирует второй бит ярлыка и, поскольку он равен 1, также коммутирует ячейку на свой нижний выход. Третий элемент обнаруживает, что третий бит ярлыка также равен 1, и направляет ячейку на нижний выходной порт. Следовательно, ячейка с ярлыком 111 коммутируется на нижний порт независимо от номера входного порта, с которого она поступила. Таким образом, ярлык однозначно определяет номер выходного порта. Однако, в данной архитектуре возможен конфликт при одновременной коммутации нескольких ячеек, поскольку ячейки могут предназначаться для одного и того же выходного порта. Для предотвращения этого используются определенные технические решения, основанные на анализе возможности появления таких конфликтов. После принятия решения о возможном возникновении конфликта одна из потенциально конфликтующих ячеек временно задерживается во входном буфере. Одной из интересных особенностей данной архитектуры является то, что увеличивая число столбцов и строк логических элементов, можно получить достаточно большое число портов. Соответственно можно получать все большие и большие коммутаторы. Поэтому иногда данную архитектуру называют бесконечно наращиваемой коммутационной технологией.
|
|||||||||
|
|
Последнее изменение этой страницы: 2016-08-12; просмотров: 231; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.220.16.184 (0.03 с.) |