
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Сортировка трасс по опв и накопление возбуждений.
Для накопления многократных возбуждений в каждой точке возбуждения и приема, нужно отсортировать сейсмические трассы так, чтобы в ансамбль (см. “ Ensemble Stack ”) попадали все трассы, полученные в каждой точке приема с определенного пункта возбуждения. С этой целью сначала какому-либо параметру заголовка трасс нужно присвоить такое значение, которое будет уникальным именно для таких трасс. Например: пусть работы производились 24 канальной установкой с использованием поперечных (S) волн, на каждом пункте возбуждения производилось 10 ударов «левых» (y-), 10 ударов «правых» (y+). Пункты возбуждения совпадали с пунктами приема: сначала производилось 10+10 возбуждений у 1 пикета приема (1 канала), затем 10+10 возбуждений у 2 пикета, и т.д. Пусть мы эти сейсмограммы в такой же последовательности ввели и в нашу базу данных. Тогда 1 пикету приема при возбуждении «левых» ударов у 1 пикета соответствуют трассы 1, 25, …217, а 2 пикету – 2, 26, …218 и т.д. При возбуждении «правых» ударов 1 пикету соответствуют трассы 241, 265,…457, а 2 пикету – 242, 266,…458 и т.д. Входим в пункт меню “ Database”->”Geometry spreadsheet ” и заполняем, к примеру, следующие заголовки трасс: “ FFID ” – номер полевой сейсмограммы, “ SOU_INL ” – номер пункта возбуждения на профиле, “ TRC_TYPE ” – тип сейсмической трассы (например: 0 – «левый» удар, 1 – «правый» удар), “ CHAN ” – номер канала, “ TR_FOLD ” – этот параметр мы используем как раз для присвоения указанного выше уникального значения для накапливаемых трасс (см. рис.52). Далее создаем поток, в котором первой операцией является “ Trace Input ” - ввод сейсмических данных из внутренней базы данных (в данном случае – “ RaTrcOut1 ”, который был сохранен предыдущим потоком ввода полевых данных, и заголовки трасс которого мы указанным образом отредактировали). Первым полем сортировки “ Sort Fields ” является “ TR_FOLD ”, который имеет уникальное значение для суммируемых по общему пункту возбуждения трасс. Вторым полем сортировки указан “ TRC_TYPE ” – в нашем случае тип удара («левый» или «правый»). В поле “ Selection ” указано “ *:1 ”, что означает: по первому полю сортировки читать все трассы, а по второму – только те, у которых TRC_TYPE=1, т.е. только «правые» удары (для обработки «левых» ударов рекомендуется создать второй подобный поток).
Второй операцией включаем “ Screen Display ” – для визуального контроля правильности сортировки данных. В окне параметров визуализации “ Display parameters ” устанавливаем флажок на опции “ Ensemble boundaries ” – тогда на экране ансамбли – суммируемые трассы будут разделены белой полосой (рис.53). Запустив поток нужно убедиться, что суммируемые трассы правильно собраны в ансамбли, и, что считаны только требуемые трассы, т.е. только правые удары. Внутри ансамбля в данном случае трассы никак не упорядочены. Если нужно их как-то упорядочить (например: по порядку ударов), то можно в “ Trace Input ” добавить еще поля сортировки (например: “ FFID ”).
Рис.52. Пример работы с потоком для накопления возбуждений – трасс, сгруппированных по общему пункту возбуждения и общему пункту приема - “ TR_FOLD ”. В накоплении участвуют только трассы, записанные при «правом» ударе (“TRC_TYPE”=1). Для иллюстрации возможностей одновременно открыты: окно ввода параметров процедуры “ Trace Input ”, окно помощи – RadExPro Plus Documentation, окно присвоения геометрии – Geometry Spreadsheet – с открытым окном математических выражений – Trace Header Math.
Рис.53. Пример изображения на экране трасс, сгруппированных в ансамбли по общему пункту возбуждения и общему пункту приема - “ TR_FOLD ”. “ SOU_INL ” – номера пунктов возбуждения на профиле.
Рис. 54. Результат суммирования (“ Ensemble Stack ”) трасс, изображенных на рис.53.
Следующей операцией является “ Ensemble Stack ” – суммирование или осреднение трасс по ансамблю. Суммируются все трассы, попадающие в ансамбль. Возможны 3 режима осреднения отсчетов трасс: 1) “ Mean ” – нахождение арифметического среднего – линейная операция, лучше всего работает при стационарном шуме и постоянном уровне сигнала; 2) “ Median ” – медианное осреднение, помогает отбросить большие выбросы по отдельным трассам; 3) “ Alpha trimmed ” – примерно то же, но с возможностью настройки. В результате этой операции остается лишь столько трасс, сколько было ансамблей (рис.54), т.е. с каждого пункта возбуждения по одной 24-канальной сейсмограмме (для правых ударов, столько же для левых). Их можно посмотреть (“ Screen Display ”) и сохранить в базе (“ Trace Output ”).
Вычитание «левых» ударов от «правых» (можно и наоборот) с целью усиления записей поперечных волн и подавления записей продольных волн можно сделать еще до накопления возбуждений (для каждой пары ударов), после накопления возбуждений (для каждой пары накопленных трасс), или же после получения временных разрезов ОГТ для «левых» и «правых» ударов раздельно. Однако с точки зрения редактирования (отбрасывания) бракованных трасс, выгоднее сделать это в самом конце обработки, выбрасывая бракованные трассы (или просто некоторые интервалы записи – “ muting ”) вне зависимости от другой части пары «левых» и «правых» ударов. Поэтому пока продолжим обработку записей «левых» и «правых» ударов раздельно.
Суммирование трасс по ОГТ. В данном потоке необходимо произвести сортировку трасс в ансамбли по ОГТ, ввести априорные кинематические поправки и просуммировать трассы, соответствующие одному и тому же ОГТ. Основная идея метода ОГТ исходит из того, что если отражающая граница горизонтальная и поверхность наблюдений горизонтальная, то при равной удаленности источника и приемника от центральной точки лучи волны отражаются от одной и той же точки границы под этой центральной точкой, вне зависимости от расстояния источник-приемник (Глава III, рис.21). Однако в случае наклонной границы точка отражения смещается от центральной точки в сторону восстания границы, причем тем больше, чем больше расстояние источник-приемник (Глава I, рис.6). Таким образом, в действительности образуется общая глубинная площадка, а не точка, к тому же она смещена от общей центральной точки на поверхности наблюдений. При суммировании трасс по ОГТ знать заранее величину смещения и размеры площадки не представляется возможным (в принципе, истинное положение точек отражения можно восстановить при миграции). Поэтому условно результирующую трассу относят к середине разноса источник-приемник, и, исходя из этого, иногда используют название - метод общей средней точки (ОСТ). С другой стороны, с учетом реальных положений источников и приемников на профиле, а также в стремлении суммировать по ОГТ как можно больше трасс, в каждую сейсмограмму ОГТ относят все трассы с отражениями от общей глубинной площадки заданных размеров, а не от точки. Размеры площадки задаются исходя из разумных требований горизонтальной разрешенности и кратности наблюдений. Принято этот процесс называть бинированием [2, 9]. Чтобы сейсмические трассы можно было сортировать в ансамбли по общей глубинной площадке, какому-либо параметру заголовка таких трасс нужно присвоить одинаковые значения (cdp). Причем это значение должно быть уникальным для каждого ОГТ. Предварительно в заголовках всех трасс должны быть присвоены значения координатам точек приема и возбуждения - REC_X, SOU_X. По ним определяются координаты средних точек CDP_X (как половина суммы). Затем соответствующим округлением, и, если требуется, смещением нуля, эти значения присваиваются номерам ОГТ – CDP (см. рис.55). Требуется присвоить значения также разносам источник-приемник – OFFSET и AOFFSET. Они нужны для вычисления кинематических поправок – NMO.
Рис.55. Присвоение геометрии перед суммированием по ОГТ. Далее создаем поток для суммирования трасс по ОГТ (рис.56), результатом которого должен стать временной разрез ОГТ (рис.57).
На представленном примере, как и обычно, первая процедура – ввод данных из базы – ввод накопленных трасс «правых» ударов (CSP_Stack_Right). Первым полем сортировки является CDP, т.е. трассы общей глубинной площадки попадут в один ансамбль. Вторым полем сортировки является абсолютная величина разноса источник-приемник (AOFFSET) – нужно лишь для сортировки трассы внутри каждой сейсмограммы ОГТ, чтобы можно было визуально проследить оси синфазности волн (гиперболы). В поле выбора (“ Selection ”) отбрасываются первые и последние 5 площадок ОГТ с очень малой кратностью перекрытия. После каждой процедуры можно включать визуализацию на экране (“Screen Display”) и проконтролировать результаты. Следующая процедура – “ Amplitude Correction ” – нужна для выравнивания амплитуд суммируемых трасс. Без нее очень сильные поверхностные волны, попадающие на некоторых трассах в интервалы записи полезных отраженных волн, могут полностью «забить» их даже в суммотрассах ОГТ. Поэтому в данном случае выбираем автоматическую регулировку усиления (AGC) с временным окном 100 мс (вся длина трассы 1000 мс), а также выравнивание трасс(Trace equalization) по среднему уровню сигнала в интервале 0-512 мс.
Процедура – “ NMO/NMI ” – ввод кинематических поправок
где
При этом предполагается, что скорость в покрывающей толще для каждой отражающей границы постоянная, но для разных границ, а также разных интервалов профиля, может быть разная. Поэтому, в общем случае
Однако пока мы эту информацию не знаем, можно полагать, что скорость по горизонтали не меняется, а по глубине также постоянна, или меняется по предварительно заданному единому закону (см. рис. слева). В дальнейшем, когда в результате скоростного анализа (Velocity Analysis) будут определены скоростные законы для разных точек профиля, можно будет использовать эти скорости для вычисления кинематических поправок (Get from file).
Рис.57. Временной разрез ОГТ – результат работы потока на рис.56.
Процедура полосовой фильтрации “ Bandpass Filtering ” позволяет дополнительно ослабить некоторые помехи и улучшить прослеживаемость отраженных волн. “ Trace Output->CDPstack-right ” позволяет сохранить полученный временной разрез ОГТ в базе данных для дальнейшей обработки, например, для комбинирования с разрезом «левых» ударов, и т.д. Полученный разрез не отличается высоким качеством, что не удивительно, так как мы пока не использовали многие интерактивные процедуры, позволяющие целенаправленно подбирать параметры обработки. Такой разрез может считаться лишь предварительным результатом («сырой разрез» - “ raw stack ”). Однако он полезен для понимания общей геологической ситуации, и выбора дальнейшей стратегии обработки. Теперь в процесс обработки можно добавлять дополнительные процедуры с целью подбора оптимальных параметров обработки и улучшения результатов.
12.7. Редактирование (браковка) сейсмограмм и отдельных трасс.
Во время полевых работ оператор должен стараться, чтобы все записи были качественными, т.е. обладали высоким отношением сигнал/помеха, не было аппаратных сбоев записи. Однако не всегда удается этого добиться, так как иногда возможны случайные очень сильные («ураганные») помехи на каких-либо каналах или по всей сейсмограмме, может отказать какой-либо сейсмоприемник или усилитель, возможны и сбои записывающей аппаратуры. Качество суммарной записи улучшиться, если такие сейсмограммы, отдельные трассы или интервалы трасс исключить из списка суммируемых трасс. Разработаны различные способы, позволяющие делать это вручную, в автоматическом и полуавтоматическом режимах. Рассмотрим здесь лишь наиболее очевидные из них. В любом случае, сначала нужно определить, какие помехи или сбои представляют опасность, как они распределены в записях. Для этого нужно создать поток «Повальный вывод», где визуализировать все введенные в базу данных исходные сейсмограммы. Далее можно поступать по разному: Если выяснится, к примеру, что все время не писал какой-либо канал сейсмостанции (скажем, 5), нет смысла в последующем использовать трассы, соответствующие этому каналу. Поэтому, при вводе исходных данных (Trace Input) в поле сортировки (Sort Fields) указываем поле заголовка - каналы (CHAN), а в поле выбора (Selection) в соответствующей позиции – все каналы, за исключением данного (1-4, 6-24). Естественно, соответствующие поля заголовков трасс данной базы должны быть предварительно заполнены. Если в конце потока данные будут сохранены снова, то в новой базе данных эти трассы уже будут отсутствовать, т.е. в последующем уже про эту сортировку можно не думать. Точно так же можно поступать, если плохими окажутся целые полевые сейсмограммы (FFID). Сложнее придется, если плохими окажутся некоторые трассы в произвольной последовательности. Конечно, если таких трасс немного, можно выписать их номера по сквозной нумерации в файле (TRACENO), задать сортировку по этому параметру, и указать в поле выбора все трассы, за исключением выписанных номеров. Однако при большом количестве бракованных трасс такой способ становится неудобным. Логично сделать так, чтобы система сама запомнила такие трассы, например, присваивая определенные значения какому-либо параметру заголовка таких трасс.
Это можно сделать следующим способом. Прежде всего, создаем поток, состоящий из 3 процедур: чтения данных из базы - “ Trace Input ”, визуализации на экране - “ Screen Display ” и сохранения данных в базе под тем же именем -“ Trace Output ” (рис.58).
Рис. 58. Пример выделения бракованных трасс пикированием. В поле PICK1 заголовков трасс 5, 11, 26 будут записаны реальные времена пикировок, а для остальных трасс – 9999. Данные сохраняются в базе b80tst по завершении работы потока.
Затем, в режиме “ Screen Display ”, когда трассы изображены на экране, выбираем “Tools”-“Pick”-“New pick”. Задаем режим пикирования “Tools”-“Pick”-“Marks only” – трассы будут просто выделены цветом. Потом пикированием выделяем бракованные трассы. Когда выделение закончено, выбираем “Tools”-“Pick”-“Save to header” – всплывает панель дополнительного меню. На ней выбираем поле заголовка трасс (“Header field”), которому хотим присвоить пикированные значения (например, PICK1). В принципе, нужно выбрать такое поле, которое для других целей не используется. Затем нажимаем “Reflect changes in”, и во всплывающем окне “Choose dataset” выбираем имя базы данных, в заголовках которой хотим отразить эти пикировки (та же самая база, которая в данный момент обрабатывается). Нажимаем кнопку “OK”. При завершении процедур потока пикировки будут сохранены в соответствующих ячейках заголовков. Такие же ячейки всех остальных, не пикированных трасс, система заполняет одинаковыми значениями 9999, что и позволяет при последующей сортировке по выбранному параметру отличить пикированные трассы от остальных (так как обычно трассы такой большой длительности не записываются).
12.8. Обнуление (мьютинг) отдельных интервалов записи.
Некоторые виды помех образуются при каждом возбуждении волн, но присутствуют лишь в определенных интервалах записи, и от них можно избавиться, обнуляя перед суммированием эти интервалы (мьютинг). Чаще всего такими помехами являются прямые и преломленные волны в начальной части записи, а также поверхностные волны. Поэтому широко применяется обнуление начальных интервалов трасс до определенных времен. Осуществить это можно в процедуре “ Trace Editing ”, выбирая режим “ Top muting”. Далее надо задать горизонт (“ Horizon” - времена t(x)), до которого запись обнуляется. Можно задать это вручную (“ Specify”), как x1:t1, x2:t2 и т.д. Но удобнее использовать пикированные данные. Для этого следует предварительно пропикировать соответствующую линию, за которой удаляемые помехи заканчиваются, и сохранить ее (в зависимости от соответствующего параметра, например: AOFFSET) в базе данных. А в окне меню “ Trace Editing ” - “ Top muting” – “Horizon ” указать “Pick in database” и выбрать (“ Select”) соответствующий файл пикировки. После применения процедуры начальные части всех трасс будут обнулены до времен, соответствующих указанному в заголовке параметру. В промежуточных интервалах времена линейно интерполируются. Таким же образом можно обнулять и хвостовые интервалы трасс (“Botton muting”), хотя такая операция применяется реже. Существует возможность исключить из суммирования отдельные импульсные выбросы или даже интервалы записи, в автоматическом режиме, по резкому отличию значения выборки по отдельной трассе от значений выборок в других трассах. Для этого в меню процедуры суммирования-осреднения (Ensemble Stack) нужно выбрать режим “ Median ”, вместо режима “ Mean ” (т.е. сделать медианное осреднение, вместо простого арифметического осреднения).
Ввод статических поправок.
Решение обратной задачи сейсморазведки производится при многих упрощающих предположениях. В частности, очень часто поверхность наблюдений предполагают плоской и горизонтальной, покрывающую толщу считают однородной и изотропной. Так как реальные среды могут достаточно сильно отличаться от таких моделей, то наблюденные данные специально подгоняют под них, вводя поправки, которые называются статическими, потому что их величина зависит лишь от местоположения источника или приемника, но не зависит от расстояния между ними или от времени прихода волн. Способы определения величин этих поправок подробно описаны в § 10. Существует несколько способов ввода таких поправок и коррекции их величин в системе RadExPro. Ввод статических поправок осуществляется процедурой “ Apply Statics ”. В меню процедуры нужно выбрать источник поправок:
“ Header Word ” – значения поправок берутся с указанного поля заголовка трасс (предварительно нужно позаботиться о присвоении этих значений к соответствующим заголовкам трасс). “ Get from database ” - значения поправок берутся с указанного объекта базы данных. Обычно это – пикированные времена по некоторому горизонту (предварительно нужно пропикировать и сохранить). “ Use file ” - значения поправок берутся с указанного файла. Файл должен иметь текстовый формат, в точности подобный формату файла “ Export picks ”. Если указать непосредственно файл, сохраненный как “ Export picks ”, то результат будет такой же, как если бы времена пикировок были указаны через “ Get from database ”. Преимущество такого способа в том, что текстовый файл может быть дополнительно отредактирован вручную или с помощью специальных программ, например, “ Microsoft Excel ”. Значения поправок могут быть прибавлены к первоначальным временам выборок (Apply fractional statics), вычтены от них (Subtract static), или же в качестве поправок могут быть использованы лишь значения разности между заданным временем (задается в окне) и указанными поправками (Relative to time).
|
|||||||||
|
|
Последнее изменение этой страницы: 2016-06-26; просмотров: 653; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.119.159.150 (0.041 с.) |
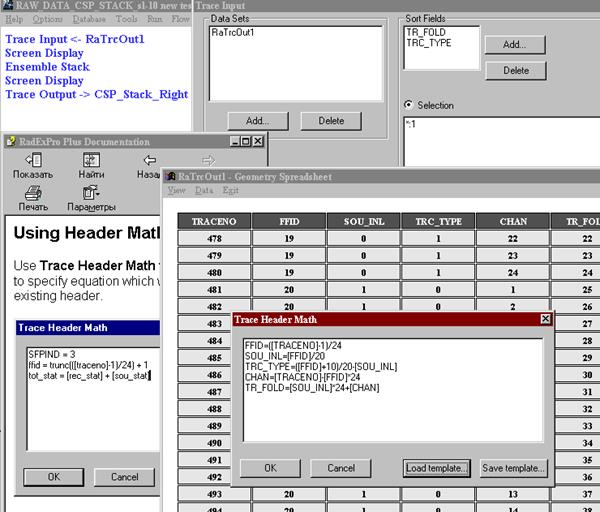

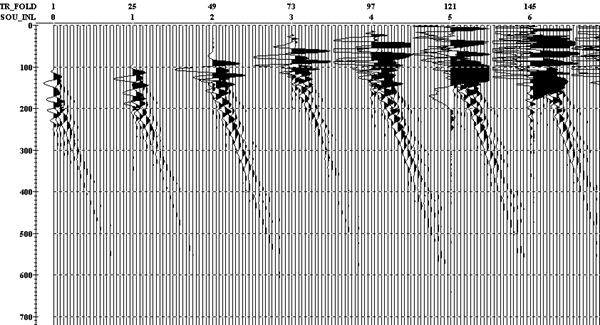
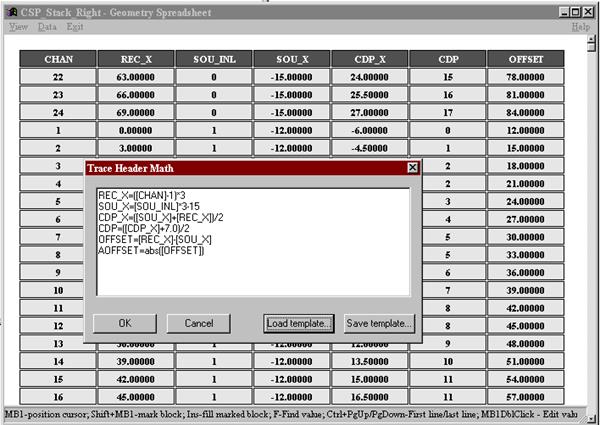
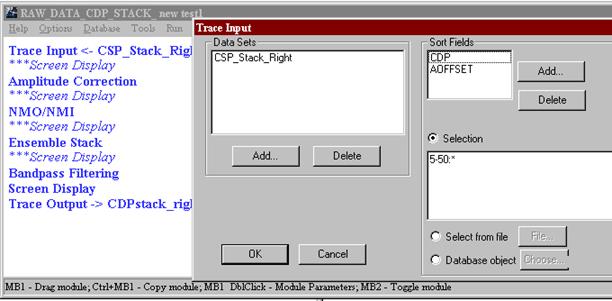 Рис.56. Поток для суммирования трасс по ОГТ.
Рис.56. Поток для суммирования трасс по ОГТ.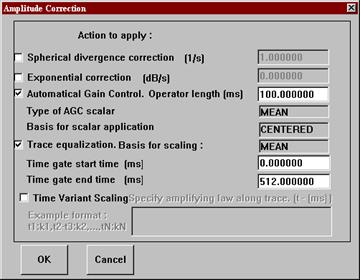
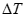 , которые вычисляются по формуле
, которые вычисляются по формуле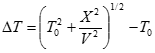
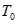 - время прихода отраженной волны к приемнику с нулевым удалением,
- время прихода отраженной волны к приемнику с нулевым удалением,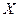 - удаление источник-приемник,
- удаление источник-приемник,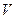 - скорость в покрывающей толще (Vогт).
- скорость в покрывающей толще (Vогт).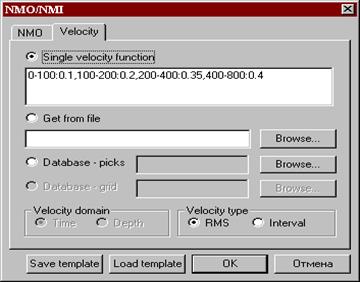 Vогт = Vогт (h, x)
Vогт = Vогт (h, x)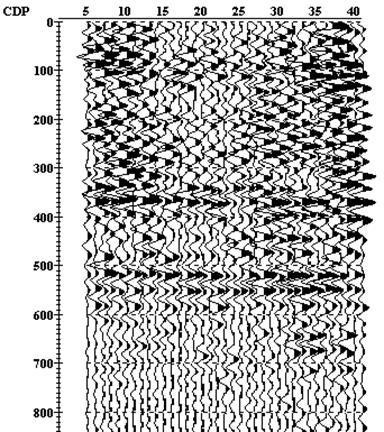 Далее идет процедура суммирования “ Ensemble Stack ”, в результате которой собственно и получается временной разрез ОГТ.
Далее идет процедура суммирования “ Ensemble Stack ”, в результате которой собственно и получается временной разрез ОГТ.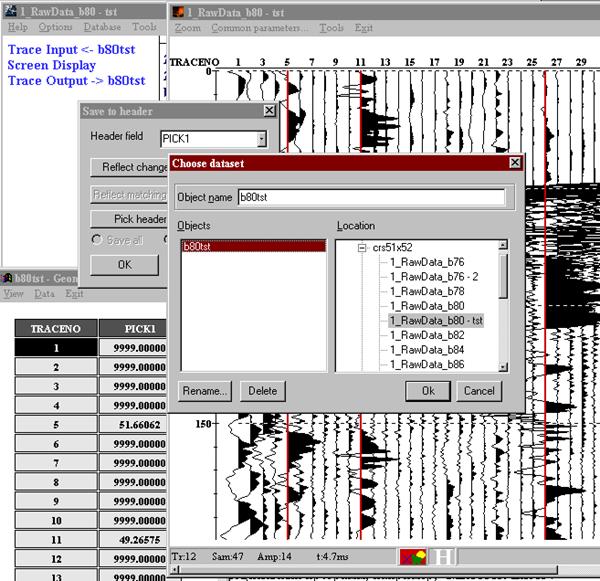
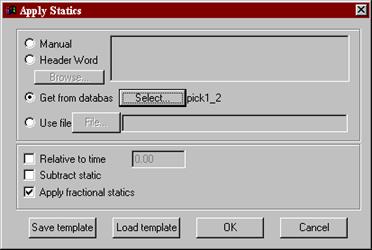 “ Manual ” – поправки задаются в текстовом формате в окне меню: x1:t1, x2-x3:t2, и т.д.
“ Manual ” – поправки задаются в текстовом формате в окне меню: x1:t1, x2-x3:t2, и т.д.


