Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Принципы активных систем баз данныхСтр 1 из 3Следующая ⇒
НОВОСИБИРСК 2000
1. ВВЕДЕНИЕ
При проектировании приложений базы данных можно извлечь пользу из свойств активных баз данных. Свойства активных баз данных заключаются в том, что процедурные элементы общей среды встраиваются в систему базы данных и управляются декларативным образом. Развитие технологии активных баз данных рассматривается в настоящее время как одна из главных тенденций, которая будет революционизировать разработку приложений. Философия, на которой основана эта технология - хранение операций над данными и процедур вместе с самими данными, - широко используется в других областях, например в объектно-ориентированных базах данных. Внедрение активных баз данных позволяет привносить интеллектуальные элементы в управление информационными системами. Главное различие между активными базами данных и традиционными пассивными базами данных заключается, в конечном счете, в том, что в системах последнего типа вся процедурная логика, включая выборку и модификацию данных, управляемых СУБД, координируется вне сферы управления данными. Если предполагается, что в результате выполнения определенной операции обновления данных (рассматриваемой как некоторое событие) должна вызываться какая-либо другая последовательность действий, выполнение этих других действий должно инициироваться логикой приложения или некоторыми иными внешними агентами. Напротив, среда активных баз данных поддерживает инициацию таких других действий и управление ими внутри среды базы данных в соответствии с предварительно установленными правилами. При этом нет необходимости получения каких-либо дальнейших управляющих воздействий от приложений или от каких-либо других внешних источников. . К числу основных принципов реализации активных баз данных относятся: • триггеры баз данных, которые запускаются при наступлении предопределенного события (или комбинации событий); • хранимые процедуры, встраивающие процедурную логику в среду базы данных, а не в подсистему приложения. Наряду с основными принципами активных баз данных такие их составные элементы, как модели управления транзакциями, модели переходов состояний и техника использования более чем одного триггера на событие, помогут распространить возможности существующих в настоящее время технологий активных баз данных на сферу интеллектуальных баз данных.
Для работы с системами баз данных масштаба SQL сервер важно знать способы использования активных элементов баз данных. В рамках данной лабораторной работы рассматриваются активные технологии баз данных: хранимые процедуры и триггеры. Для выполнения лабораторной работы требуется знание основ управления SQL-сервером, и технологии работы с компоненты MS Office. Кроме того, требуется знание реляционной алгебры и реляционного исчисления, а также методов проектирования реляционных баз данных и управления ими с помощью языка SQL. В результате выполнения лабораторной работы Вы познакомитесь с технологией создания приложений баз данных, основанных на активных конструкциях.
ОСНОВНЫЕ ПОНЯТИЯ Традиционные базы данных являются пассивными. Объекты данных обычно помещаются в базу данных пользователем или приложением. Выборка объектов осуществляется опять-таки под воздействием внешних источников. Подобным же образом под влиянием какого-либо внешнего источника информация изменяет место своего хранения в базе данных (например, переносится из одной таблицы в другую). Бизнес -правила, применяемые к содержимому базы данных (например, правила обновления конкретного элемента данных, последующие за этим действия над другими элементами как результат такого обновления), также управляются некоторым внешним -источником. Короче говоря, традиционные базы данных не являются активными "игроками" в информационных системах и вместо этого играют организационную роль, направленную на обеспечение хранения данных. В последние годы эта роль изменяется, а важность концепции активных баз данных будет возрастать на протяжении оставшихся лет текущего десятилетия. Можно по существу, утверждать, что технология активных баз данных - это врата, открывающие путь к базам знании, исследуемым в области искусственного интеллекта (ИИ). Обычно принято связывать зарождение идеи активных баз данных с появлением концепции триггера - механизма, впервые предложенного в исследовательском проекте System R компании IBM. Поддержка концепции триггера предусматривалась в языке этой системы SEQUEL (впоследствии названном SQL), спецификации которого были опубликованы первоначально в 1975 г. Однако ради исторической справедливости следует заметить, что идея триггеров была гораздо ранее воплощена в языке определения данных CODASYL (хотя термин "триггер" тогда еще и не употреблялся).
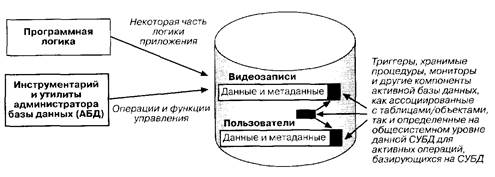
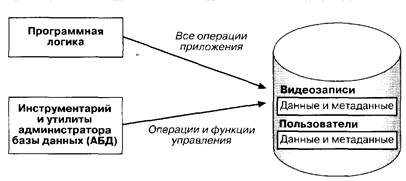
Начиная уже с версии этого языка, опубликованной в 1971 г. в нем предусматривалась поддержка концепции процедуры базы данных, которая может ассоциироваться с различными объектами базы данных в спецификациях схемы - с областями базы данных, с записями, элементами данных, наборами. Позднее, в версии 1973 г. такие возможности были введены и для самой схемы базы данных. Процедура базы данных запускается в случае, если над объектом базы данных, с которым она ассоциирована, выполняется одна из заданных в спецификации операций. При этом выполнение процедуры может предшествовать выполнению указанной операции, следовать за ним или иметь место в случае возникновения ошибки. Естественно, предполагается, что СУБД обладает механизмом, отслеживающих возникновение условий выполнения процедур базы данных. Программный код процедур базы данных интегрируется с базой данных, а не с логикой приложений. Таким образом, мы имеем здесь дело и с прообразом идеи «хранимых процедур», воплощенной впоследствии в реляционных системах и получившей статус расширения стандарта SQL-92. Рис. 1. Пассивные системы баз данных С другой стороны, активные системы баз данных предусматривают возможности, позволяющие: - содержать логику обработки (до некоторой степени) в самой базе данных так, чтобы она управлялась СУБД, а не прикладным программным обеспечением приложений; - обеспечивать некоторую форму мониторинга событий и условий, которые воздействуют на данные и могут инициировать обработку, управляемую базой данных; - включать в систему базы данных также некоторое средство, с помощью которого эти события и условия могли бы запускать логику внутри базы данных. Как показано на рис. 2, все эти три возможности - логика, триггеры для этой логики и средства мониторинга для активизации триггеров - выносятся из программ приложений в саму базу данных, обеспечивая более тесную связь системных данных и операций над данными, чем это было принято в традиционных пассивных управляемых СУБД системах.
Рис.2. Активные системы баз данных В создании активных сред помогает несколько основных конструкций базы данных: ограничения, утверждения, хранимые процедуры и триггеры.
Бизнес - правила Одними из наиболее трудных областей применения вычислительных средств в настоящее время являются представление бизнес -правил и организация управления ими, иначе говоря, спецификация способов передачи информации от одной сущности информационной системы (например, от пользователя или от какого-либо компонента системы) к другой, а также условий, при которых эти потоки информации имеют место. Активные базы данных обеспечивают общую платформу для представления, поддержки и эффективного исполнения бизнес -правил в единой среде информационной системы.
Разработка приложений Спецификация компонентов бизнес -правил (в частности, триггеров и последовательностей действий, вызываемых запуском этих триггеров) является в активных базах данных декларативной, а не процедурной, как в традиционных СУБД. Иначе говоря, такие операторы SQL, как CREATE TRIGGER (создать триггер) и CREATE ASSERTION (создать утверждение), специфицирующие некоторые компоненты бизнес -правил, и хранимые процедуры могут присоединяться к объектам, которыми они оперируют. Декларативная спецификация бизнес -правил - значительно более продуктивный процесс, чем процедурная, требуемая в пассивных системах. Такое соотношение этих двух подходов объясняется главным образом тем, что управляющая логика (мониторы, механизмы восстановления) уже представлена в среде СУБД, и нет необходимости возлагать задачу ее разработки на пользователей в их приложениях.
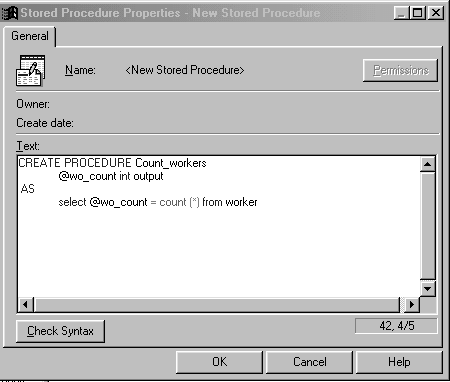
Рис.1. Окно Enterprise Manager для выбора списка хранимых процедур В окне для работы с хранимыми процедурами в колонке Type возле имени процедур находится ключевое слово System, которое показывает принадлежность данной процедуры к группе системных процедур. С другой стороны, все процедуры, создаваемые пользователем, помечаются ключевым словом User в колонке Type. Для создания новой процедуры выберите команду New Stored Procedures меню Action, после чего на экране отобразится диалоговое окно, в котором будет расположена область для ввода текста процедуры (рис. 2). Для решения выше рассмотренной задачи создадим новую хранимую процедуру, после чего системой будет предложена заготовка SQL-команда, используемая для создания процедуры:
CREATE PROCEDURE [PROCEDURE NAME] AS. Здесь вместо текста [PROCEDURE NAME] необходимо ввести имя создаваемой процедуры, после чего набрать текст ее команд.
Рис. 2. Диалоговое окно редактора хранимых процедур
Следующим этапом будет проверка работоспособности созданной процедуры. Для этого запустите утилиту SQL Server Query Analyzer, после чего осуществите подключение к требуемому серверу баз данных. Выберите базу данных Premier1 в выпадающем списке DB. Далее необходимо набрать и выполнить ряд команд (рис. 3).
Рис. 3. Диалоговое окно Query Analyzer c командами запуска хранимой процедуры Count_workers и результатом ее выполнения В процедуре сначала определяется локальная переменная @worker_count. Затем вызывается ранее определенная хранимая процедура count_workers. Результат выполнения будет помещен в локальную переменную @worker_count. С помощью оператора Print значение этой переменной выводится на экран.
Разумеется, преимущество применения хранимых процедур существенно больше, когда сама процедура обширнее и сложнее. Во втором, более сложном примере, предположим, что мы хотели бы сохранить процедуру, подсчитывающую среднюю ставку рабочих указанной специальности. Это означает, что вызывающая процедуру программа передает ей тип специальности, а процедура возвращает величину средней ставки работников этой специальности. Мы создадим процедуру calc_wage_fcns (рис. 4).
Рис. 4. Диалоговое окно редактора хранимых процедур с текстом процедуры Calc_wage_fcns У этой хранимой процедуры есть выходной параметр @avg_hrly_rate (средняя почасовая ставка) и входной - @skill_type. Вызывающая программа должна задавать локальную переменную типа real для фиксации выходного параметра, и значение типа специальности. Более того, в ней эти параметры должны быть указаны в том же порядке, в котором они перечислены при определении процедуры. Приведем пример вызова процедуры Сalc_wage_fcns (рис. 5).
Рис. 5. Диалоговое окно Query Analyzer c командами запуска хранимой процедуры Calc_wage_fcns и результатом ее выполнения
Обратите внимание, что команду «execute» можно сократить до «ехес». Хотя значение входного параметра (в нашем случае «Штукатур») является символьной величиной, его не нужно заключать в кавычки, за исключением тех случаев, когда оно дополнено пробелами, содержит знаки препинания или начинается с цифры. Процедура calc_wage_fcns подставит значение «Штукатур» в переменную @skill_type, и будет подсчитана средняя почасовая ставка штукатура. Когда значение будет возвращено вызывающей программе, оно будет помещено в переменную @avg_wage. Значения по умолчанию. При определении хранимой процедуры можно задать значение параметра по умолчанию. Если вызывающая программа не задает значения входного параметра, то программа использует значение по умолчанию. Значением по умолчанию может быть любое допустимое значение заданного типа данных, включая пустое. Рассмотрим пример, в котором используется пустое значение. Мы просто видоизменим предыдущий пример. В случае если вызывающая программа задает только выходной параметр, но не указывает тип специальности, мы будем считать среднюю ставку всех работников. Значение параметра по умолчанию. Значение параметра, задаваемое системой в том случае, если вызывающая программа опускает его значение. Измененная процедура представлена на рис. 6.
Рис. 6. Диалоговое окно редактора хранимых процедур с текстом измененной процедуры Calc_wage_fcns
Если вы сравните эту версию с предыдущей версией, то увидите, что значение по умолчанию определяется сразу после задания типа данных параметра: @skill_type char (10) = null. Помещая «null» после определения параметра, мы говорим, что если никакое значение параметру не передано, то параметр считается имеющим пустое значение. Выполняемая часть процедуры изменена, так, чтобы учитывать такую возможность - тип специальности не передан вызывающей программой.
Вызов и результат выполнения процедуры представлен на рис. 7.
Рис. 7. Диалоговое окно Query Analyzer c командами запуска измененного варианта хранимой процедуры Calc_wage_fcns и результатом ее выполнения Применение команды RETURN. Когда последняя команда процедуры выполнена, процедура завершается и возвращает управление вызывающей процедуре. Как быть, если логика процедуры такова, что мы хотим выйти из нее раньше? Команда RETURN обрывает выполнение хранимой процедуры и немедленно возвращает управление вызывающей программе. Предположим, что мы хотим придать одной хранимой процедуре несколько разных функций. Например, мы хотим позволить пользователю запрашивать максимальную, минимальную или среднюю почасовую ставку из таблицы worker. Процедура, которая это делает, представлена на рис. 8.
Рис. 8. Диалоговое окно редактора хранимых процедур с текстом процедуры Calc_wage_fcns1 В этом примере вызывающей программе требуется одна из трех функций. Если выбрана функция «max», то мы вычисляем максимальное значение и немедленно возвращаемся в исходную программу, так как не хотим вычислять остальные две функции. Результат выполнения хранимой процедуры представлен на рис. 9. Из этого примера нетрудно понять, как команда RETURN может применяться в хранимых процедурах.
Рис. 9. Диалоговое окно Query Analyzer c командами запуска хранимой процедуры Calc_wage_fcns1 и результатом ее выполнения В хранимых процедурах часто используются так называемые системные переменные, которые представляют пользователю определенную информацию о системе SQL-сервер. В таблицах 1 и 2 представлены системные статистические переменные и переменные, используемые для конфигурирования сервера. Табл. 1 Табл. 2 Рис. 10. Диалоговое окно свойств триггера В диалоговом окне появится заготовка для создания текста триггера. Необходимо указать имя триггера, имя таблицы на которую он определен, тип триггера и после ключевого слова AS ввести тест триггера (рис. 11). С помощью клавиши Check Syntax можно проверить корректность текста триггера.
Рис. 11. Текст триггера update_assigment Для того чтобы разобраться в этом определении триггера, мы должны рассмотреть его по частям. Начнем с первых трех строк: create trigger update_assignment on assignment for insert, update, delete Первая строка дает триггеру имя «update_assignment»; вторая означает, что он применяется к таблице assignment. Третья строка задает, что триггер будет запускаться от каждой операции - ввода, обновления или удаления. Следующая строка триггера, «as», открывает программную часть определения триггера. Все, что следует за этой строкой, выполняется системой при запуске триггера. Теперь рассмотрим эту часть. Она состоит из двух команд обновления, каждая из которых применяется к таблице worker. Первая команда update прибавляет к значению столбца cumulative_pay значение, вычисленное по таблице inserted, а вторая команда update вычитает из значения столбца cumulative_pay значение, вычисленное по таблице deleted. update worker set cumulative_pay = cumulative_pay + 8 * hrly_rate * (select sum (num_day) from inserted where inserted.worker_id = worker.worker_id) update worker set cumulative_pay = cumulative_pay - 8 * hrly_rate * (select sum (num_day) from deleted where deleted.worker_id = worker.worker_id) Эти две команды заставляют систему проходить таблицу worker дважды. Первая команда update рассматривает строки, которые были добавлены к таблице assignment. Если какие-либо строки были добавлены, то есть в случае ввода данных в таблицу assignment или ее обновления, атрибут num_days (число дней) добавленных кортежей учитывается в соответствующем кортеже таблицы worker. Аналогично, вторая команда рассматривает строки, которые были удалены из таблицы assignment. Если удаленные строки есть, то есть в случае удаления данных из таблицы assignment или ее обновления, атрибут num_day удаленных кортежей учитывается (путем вычитания) в соответствующем кортеже таблицы worker. Если обе таблицы inserted и deleted пусты, то команды update просто никак не отразятся на таблице worker. Таким образом, этот триггер будет работать именно так, как нам нужно. Для проверки действия триггера откроем Query Analyzer и выполним команду на обновление одной из строк таблицы Assignment. После этого можно посмотреть содержимое таблицы Worker. Значения поля cumulative_pay этой таблицы изменились автоматически (рис. 12).
Рис. 12. Проверка действия триггера с помощью Query Analyzer Применение триггеров в SQL Server и Oracle. Триггеры запускаются тогда, когда к таблице применяется заданная команда модификации данных (insert (ввод), delete (удаление) или update (обновление)). Не имеет значения, какой пользователь, или какая программа вносит изменения. Если триггер определен для этой команды, он запускается. Следовательно, важно пользоваться триггерами именно для тех операций, которые должны всегда выполняться при заданном типе изменения. В приведенных выше примерах вы встретились с ситуациями, в которых триггеры могут использоваться достаточно эффективно. Но существует и множество других. Одно важное применение триггеров связано с поддержанием целостности. Например, в SQL Server триггеры используются для поддержания единственности значений первичных ключей и целостности на уровне ссылок. В Oracle, с другой стороны, эти возможности встроены в язык определения данных. Так, в Oracle мы просто объявляем некоторые атрибуты первичными или внешними ключами, и единственность их значений и целостность ссылок поддерживается автоматически. Но в SQL Server для обеспечения выполнения этих ограничений требуется определять триггеры. Таким образом, в SQL Server триггеры являются важным инструментом поддержания целостности базы данных. В последней версии SQL Server поддержание целостности также как и в Oracle целостность на уровне ссылок поддерживается автоматически. Однако триггеры можно использовать для операций каскадного удаления или обновления записей. В базах данных Oracle триггеры нужны по аналогичным причинам. Хотя первичные и внешние ключи поддерживаются автоматически, любое бизнес-правило, требующее ссылки на другую таблицу базы данных, может поддерживаться в Oracle только при помощи триггера. Вы скажете, что в определении схемы базы данных Oracle позволяет задавать СНЕСК- ограничения, обеспечивающие выполнение некоторых правил в базе данных. Вспомните, однако, что СНЕСК- ограничения не могут содержать подзапросы, ссылающиеся на другие таблицы или даже на другие кортежи той же самой таблицы. Таким образом, СНЕСК- ограничение может рассматривать только один кортеж за раз. Рассмотрим такое правило: «Расписание работника не может быть составлено более чем на 100 дней» Для этого правила требуется запрос к таблице assignment, подсчитывающий общее число дней (num_days), расписанных для данного работника. СНЕСК- ограничением это правило задать нельзя. Однако триггер прекрасно справится с ним. ЗАДАНИЕ. 1. Создайте хранимую процедуру, получающую в качестве параметра skill_type, вычисляющую и возвращающую среднее число дней среди записей назначений работников этой специальности. 2. Предположим, что в таблице building есть поле tot_num_days, содержащее суммарное число дней работы разных работников на этом здании. Создайте триггер, который будет обновлять это поле при каждом обновлении таблицы assignment.
НОВОСИБИРСК 2000
1. ВВЕДЕНИЕ
При проектировании приложений базы данных можно извлечь пользу из свойств активных баз данных. Свойства активных баз данных заключаются в том, что процедурные элементы общей среды встраиваются в систему базы данных и управляются декларативным образом. Развитие технологии активных баз данных рассматривается в настоящее время как одна из главных тенденций, которая будет революционизировать разработку приложений. Философия, на которой основана эта технология - хранение операций над данными и процедур вместе с самими данными, - широко используется в других областях, например в объектно-ориентированных базах данных. Внедрение активных баз данных позволяет привносить интеллектуальные элементы в управление информационными системами. Главное различие между активными базами данных и традиционными пассивными базами данных заключается, в конечном счете, в том, что в системах последнего типа вся процедурная логика, включая выборку и модификацию данных, управляемых СУБД, координируется вне сферы управления данными. Если предполагается, что в результате выполнения определенной операции обновления данных (рассматриваемой как некоторое событие) должна вызываться какая-либо другая последовательность действий, выполнение этих других действий должно инициироваться логикой приложения или некоторыми иными внешними агентами. Напротив, среда активных баз данных поддерживает инициацию таких других действий и управление ими внутри среды базы данных в соответствии с предварительно установленными правилами. При этом нет необходимости получения каких-либо дальнейших управляющих воздействий от приложений или от каких-либо других внешних источников. . К числу основных принципов реализации активных баз данных относятся: • триггеры баз данных, которые запускаются при наступлении предопределенного события (или комбинации событий); • хранимые процедуры, встраивающие процедурную логику в среду базы данных, а не в подсистему приложения. Наряду с основными принципами активных баз данных такие их составные элементы, как модели управления транзакциями, модели переходов состояний и техника использования более чем одного триггера на событие, помогут распространить возможности существующих в настоящее время технологий активных баз данных на сферу интеллектуальных баз данных. Для работы с системами баз данных масштаба SQL сервер важно знать способы использования активных элементов баз данных. В рамках данной лабораторной работы рассматриваются активные технологии баз данных: хранимые процедуры и триггеры. Для выполнения лабораторной работы требуется знание основ управления SQL-сервером, и технологии работы с компоненты MS Office. Кроме того, требуется знание реляционной алгебры и реляционного исчисления, а также методов проектирования реляционных баз данных и управления ими с помощью языка SQL. В результате выполнения лабораторной работы Вы познакомитесь с технологией создания приложений баз данных, основанных на активных конструкциях.
ОСНОВНЫЕ ПОНЯТИЯ Традиционные базы данных являются пассивными. Объекты данных обычно помещаются в базу данных пользователем или приложением. Выборка объектов осуществляется опять-таки под воздействием внешних источников. Подобным же образом под влиянием какого-либо внешнего источника информация изменяет место своего хранения в базе данных (например, переносится из одной таблицы в другую). Бизнес -правила, применяемые к содержимому базы данных (например, правила обновления конкретного элемента данных, последующие за этим действия над другими элементами как результат такого обновления), также управляются некоторым внешним -источником. Короче говоря, традиционные базы данных не являются активными "игроками" в информационных системах и вместо этого играют организационную роль, направленную на обеспечение хранения данных. В последние годы эта роль изменяется, а важность концепции активных баз данных будет возрастать на протяжении оставшихся лет текущего десятилетия. Можно по существу, утверждать, что технология активных баз данных - это врата, открывающие путь к базам знании, исследуемым в области искусственного интеллекта (ИИ). Обычно принято связывать зарождение идеи активных баз данных с появлением концепции триггера - механизма, впервые предложенного в исследовательском проекте System R компании IBM. Поддержка концепции триггера предусматривалась в языке этой системы SEQUEL (впоследствии названном SQL), спецификации которого были опубликованы первоначально в 1975 г. Однако ради исторической справедливости следует заметить, что идея триггеров была гораздо ранее воплощена в языке определения данных CODASYL (хотя термин "триггер" тогда еще и не употреблялся). Начиная уже с версии этого языка, опубликованной в 1971 г. в нем предусматривалась поддержка концепции процедуры базы данных, которая может ассоциироваться с различными объектами базы данных в спецификациях схемы - с областями базы данных, с записями, элементами данных, наборами. Позднее, в версии 1973 г. такие возможности были введены и для самой схемы базы данных. Процедура базы данных запускается в случае, если над объектом базы данных, с которым она ассоциирована, выполняется одна из заданных в спецификации операций. При этом выполнение процедуры может предшествовать выполнению указанной операции, следовать за ним или иметь место в случае возникновения ошибки. Естественно, предполагается, что СУБД обладает механизмом, отслеживающих возникновение условий выполнения процедур базы данных. Программный код процедур базы данных интегрируется с базой данных, а не с логикой приложений. Таким образом, мы имеем здесь дело и с прообразом идеи «хранимых процедур», воплощенной впоследствии в реляционных системах и получившей статус расширения стандарта SQL-92. Принципы активных систем баз данных
Как мы уже упоминали, системы баз данных традиционно были пассивными. В примере с магазином видеозаписей на рис. 1 приложения, пользователи, программное обеспечение операционной системы или некоторый другой внешний источник должны были уведомлять СУБД, каким образом хранить, осуществлять выборку или реорганизовывать информацию. Даже вне такой сферы, как операции случайного пользователя, у нас возникают задачи реализации логики обработки содержимого базы данных, обычно возлагаемые на прикладные программы.
Рис. 1. Пассивные системы баз данных С другой стороны, активные системы баз данных предусматривают возможности, позволяющие: - содержать логику обработки (до некоторой степени) в самой базе данных так, чтобы она управлялась СУБД, а не прикладным программным обеспечением приложений; - обеспечивать некоторую форму мониторинга событий и условий, которые воздействуют на данные и могут инициировать обработку, управляемую базой данных; - включать в систему базы данных также некоторое средство, с помощью которого эти события и условия могли бы запускать логику внутри базы данных. Как показано на рис. 2, все эти три возможности - логика, триггеры для этой логики и средства мониторинга для активизации триггеров - выносятся из программ приложений в саму базу данных, обеспечивая более тесную связь системных данных и операций над данными, чем это было принято в традиционных пассивных управляемых СУБД системах.
Рис.2. Активные системы баз данных В создании активных сред помогает несколько основных конструкций базы данных: ограничения, утверждения, хранимые процедуры и триггеры.
|
|||||||||
|
|
Последнее изменение этой страницы: 2016-04-26; просмотров: 509; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.142.40.43 (0.118 с.) |