Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Принципы работы графического адаптера
Видеоподсистема компьютера предназначена для отображения графических изображений, хранящихся в той или иной форме в памяти компьютера или создаваемых на основе геометрических моделей ЗЭ-изображений на плоском экране монитора. Современные мониторы являются растровыми устройствами, в которых изображение на экране создается из тысяч пикселов. Пиксел — минимальный элемент изображения на экране, который может быть сгенерирован компьютером. Число пикселов в горизонтальной строке экрана, умноженное на число пикселов в столбце экрана, равно полному числу пикселов на экране и называется разрешающей способностью монитора. В современных видеоадаптерах большая часть графических функций реализуется непосредственно в видеоадаптере на аппаратном уровне, что позволяет разгрузить ЦП, но требует использования в видеоадаптере специализированного процессора — графического или видеопроцессора. Функциональные возможности и сложность современных графических процессоров, как правило, существенно превосходят возможности ЦП. Например, графические процессоры ATI Radeon XI800 XT и NVIDIA GeForce 7800 GTX содержат 320 и 302 млн. транзисторов соответственно. В их структуру входит несколько десятков специализированных процессоров, выполняющих операции арифметики с плавающей запятой. В то же время двухядерный процессор Intel Pentium Extreme Edition 840 содержит всего два процессора и 230 млн транзисторов, из которых большая часть приходится на кэш-память второго уровня. Почти все ЗD-модели, используемые в самых различных логотипах, рекламных роликах и кинофильмах, создаются на специальных рабочих станциях, оснащенных несколькими мощными процессорами и специализированными 3D- ускорителями. Яркий пример таких рабочих станций — машины, производимые компанией SGI (Silicon Graphics Inc), являющейся также создателем стандарта OpenGL. В данной области этим рабочим станциям SGI нет равных, но подавляющее большинство профессионалов используют персональные компьютеры благодаря их невысокой по сравнению со специализированными станциями стоимости, а также большому количеству написанного программного обеспечения и более удобному интерфейсу. В связи с этим все видеоадаптеры, выпускаемые для ПК, можно разделить на три больших класса:
♦ бюджетные офисные видеокарты для широкого применения; ♦ игровые видеокарты, поскольку компьютерные игры — наиболее массовая область их применения; ♦ профессиональные видеокарты для выполнения сложных профессиональных работ. Профессиональные карты отличаются от игровых тем, что они предназначены для быстрого и качественного отображения трехмерных сцен с большим количеством объектов сложной формы, набором различных источников освещения и большим числом разнообразных текстур, т. е. в этом случае очень важна вычислительная мощность графического процессора и различные технологии повышения качества визуализации. Примером профессиональных графических карт могут служить карты семейств Quadro и nForce Professional фирмы Nvidia и карты семейства FireGL фирмы ATI. Обычно профессиональные графические карты в архитектурном плане практически аналогичны игровым и содержат те же графические процессоры. Основные отличия заключаются в том, что профессиональные карты обычно ориентированы на применение в качестве API OpenGL, снабжаются специальными наборами драйверов (часто ориентированными на конкретные приложения) и высокой ценой. Далее в основном рассматриваются особенности видеоадаптеров первых двух классов как наиболее массовых и часто используемых в качестве замены профессиональных из-за высокой цены последних. Современные графические адаптеры используют последние достижения трехмерной компьютерной графики, реализуемые на аппаратном уровне и программным способом. Даже краткое перечисление характеристик, функций и поддерживаемых технологий в спецификации видеоадаптера иногда занимает несколько страниц плотного текста. Для оценки способности видеоадаптера с помощью известного набора тестирующих программ приводится внушительный список параметров, в котором трудно разобраться, не владея базовыми понятиями в области КГ. В связи с этим ниже излагаются основы устройства и принципы работы элементов графической подсистемы на популярном уровне, достаточном для самостоятельного изучения. Параметры видеоадаптеров. Современные видеоадаптеры являются достаточно сложными устройствами и характеризуются большим числом параметров и характеристик, многие из которых оценивают качество отображаемого изображения и являются неформальными. Кроме того, в зависимости от области применения к качеству отображения графики на экране монитора предъявляются различные требования. Однако можно выделить ряд числовых параметров, позволяющих оценить графические возможности видеоадаптера и сравнить их различные модели.
Емкость графической памяти или видеопамяти. Определяет сложность обрабатываемых изображений и параметры качества и скорости отображения. Качество изображения на экране монитора характеризуется совокупностью ПО взаимосвязанных параметров: максимальная разрешающая способность, максимальное число отображаемых цветов или разрядность кодирования цвета пиксела, максимальная частота кадровой развертки. Эти параметры задаются в окнах настройки ОС и в некоторой степени зависят от емкости графической памяти. Однако перечисленные параметры определяют только объем буфера кадра, в котором непосредственно формируется изображение, выводимое на экран монитора, а в современных видеоадаптерах в видеопамяти кроме буфера кадра размещается много других данных: буфер глубины (Z), данные вершин, текстуры и др. В настоящее время емкость видеопамяти достигает 1024 Мбайт, а значения указанных параметров часто превышают возможности мониторов. Тактовая частота процессора. Обычно тактовая частота процессора существенно ниже тактовой частоты ЦП и составляет 400...625 МГц. Тип графической памяти, разрядность шины и тактовая частота памяти. В современных видеоадаптерах используется синхронная динамическая память (SDRAM) типа DDR3 и DDR2 с разрядностью шины памяти от 64 до 256 разрядов и тактовой частотой до 1,7 ГГц. Максимальная пропускная способность шины памяти. Определяет скорость отображения и скорость работы графического процессора. В современных видеопроцессорах максимальная пропускная способность шины памяти может достигать 50 Гбайт/с. Тип графического интерфейса. Все современные карты используют один из двух интерфейсов либо параллельный AGP, либо более современный, последовательный PCI Express. Число пиксельных конвейеров. Пиксельные конвейеры построены на специализированных процессорах и используются для выполнения пиксельных шейдеров — специальных программ обработки пикселов изображения. В современных видеопроцессорах (ATI RADEON XI900 (R580)) содержится до 48 (16x3) пиксельных конвейеров. Число блоков текстурирования. Блоки (процессоры) текстурирования выполняют операции с текстурами для повышения реалистичности изображения на экране монитора. Текстура — плоское или трехмерное изображение элементарного участка реальной поверхности, которое может накладываться на трехмерные объекты с учетом их формы, положения и уровня детализации (LOD level). В современных видеопроцессорах (NVIDIA GeForce 7800 GTX) содержится до 24 текстурных блоков. Число вершинных конвейеров. В данном случае под вершиной понимают вершину многоугольника (полигона) и точку в трехмерном пространстве, положение которой определяется координатами X, Y и Z и переменной W (учитывающей перспективную проекцию). В графических процессорах для персональных компьютеров при описании трехмерных объектов используются полигональные модели, состоящие из простейших многоугольников — треугольников, положение которых в пространстве определяется положением их вершин. Вершинные конвейеры построены на специализированных вершинных процессорах и используются для выполнения вершинных шейдеров — специальных программ для обработки координат вершин и произвольных точек треугольников при перемещении трехмерных объектов, удаления невидимых граней объектов, сортировки вершин и т. п. В современных видеопроцессорах (NVIDIA GeForce 7800 GTX и ATI RADEON XI800 (R520)/X 1900 (R580)) содержится до восьми вершинных конвейеров.
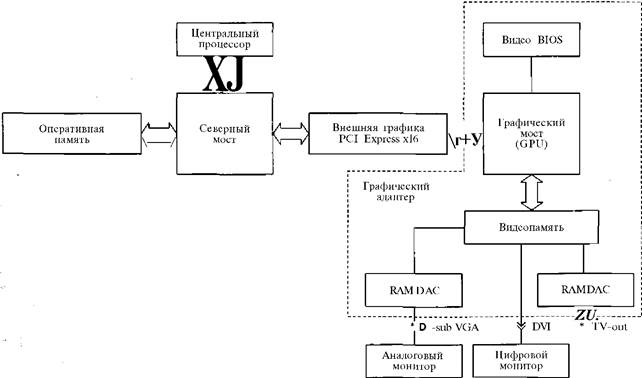
Скорость обработки полигонов. Предельное значение скорости обработки полигонов определяется числом вершинных конвейеров и тактовой частотой работы графического процессора. Реальная скорость зависит от ряда факторов и от особенностей используемого программного обеспечения и решаемых задач. В современных видеоадаптерах высокого уровня этот параметр достигает значений в 400 млн. треугольников в секунду и выше. Скорость закрашивания пикселов. Максимальное значение скорости закрашивания пикселов определяется числом пиксельных конвейеров и тактовой частотой работы графического процессора. Реальная скорость зависит от многих факторов и в современных видеоадаптерах высокого уровня этот параметр достигает 6... 7 тыс. мегапикселов в секунду. Кроме перечисленных параметров широко используются и другие параметры, измеряемые при сравнении видеоадаптеров с использованием различных тестовых задач. Устройство графического адаптера. Графический адаптер состоит из следующих функциональных блоков (рис. 2.16): ♦ графического процессора; ♦ 2О-ускорителя (часто входит в графический процессор); ♦ процессора обработки видеосигналов (часто входит в графический процессор); ♦ видео BIOS; ♦ видеопамяти; ♦ цифроаналогового преобразователя (RAMDAC), цифрового видеовыхода (DVI) и других интерфейсов (часто входят в графический процессор); ♦ интерфейсов сопряжения с чипсетом системной платы; ♦ аналоговых элементов. Графический процессор — GPU (Graphic Processing Unit). Непрерывный рост требований к качеству изображения привел к созданию специализированной графической многопроцессорной системы, которая обычно называется графическим процессором и занимается исключительно расчетом и формированием изображения, снимая эти функции с ЦП. Современные графические процессоры по сложности не уступают ЦП, более того, часто в них используются более эффективные технологии по сравнению с ЦП. Современные графические процессоры включают в себя комплекс разнообразных функциональных устройств, которые раньше выполнялись в виде отдельных микросхем, что позволяет повысить их производительность. Как и ЦП, графические процессоры характеризуются сложной внутренней архитектурой, рабочей частотой графического ядра, технологическими нормами, по которым изготовлена микросхема, и другими параметрами.
Рис. 2.12. Структурная схема графического адаптера
Видео BIOS. В микросхеме BIOS, установленной на плате видеоадаптера, хранятся программы, обеспечивающие инициализацию видеокарты, поддержку простейшего интерфейса пользователя, базовые компоненты драйвера и другие необходимые компоненты. Видеопамять. Важную роль в повышении производительности видеоадаптера играют характеристики видеопамяти, определяемые ее типом, частотой работы, величиной задержек, шириной шины памяти. ЦП компьютера направляет данные в видеопамять, а графический процессор видеокарты считывает оттуда информацию. Кроме того, в видеопамяти хранится кадровый буфер и промежуточные данные, необходимые графическому процессору. Современные видеокарты высокого уровня оснащаются 4-канальной памятью типа GDDR3 объемом до 1024 Мбайт и рабочей частотой до 1700 МГц, шиной шириной в 256 (64x4) разрядов. Средние значения задержек видеопамяти DDR достигают 1,3 не. Объем видеопамяти, установленной на карте, важен в первую очередь для обработки трехмерных изображений с текстурами высокого разрешения при большой глубине цвета. Большая емкость памяти необходима для быстрого вывода трехмерных изображений с высоким разрешением, поскольку в видеопамять при этом загружается огромный объем дополнительной информации, прежде всего массивы текстур. RAMDAC. Графический процессор, получив информацию об изображении из видеопамяти, обрабатывает ее и передает либо в цифроаналоговый преобразователь (RAMDAC) для вывода на аналоговый монитор, либо в схему формирования цифрового сигнала TDMS (а через нее на цифровой видеовыход DVI) для вывода на цифровой монитор. RAMDAC состоит из памяти с произвольным доступом (RAM) и цифроаналогового преобразователя (DAC — Digital to Analog Converter). B RAMDAC обычно используется статическая память, по быстродействию близкая к кэш-памяти процессоров. Цифроаналоговый преобразователь содержит три параллельных канала — по одному на каждый цвет. Схемотехника RAMDAC развивается очень быстро, сегодня стандартные RAMDAC обеспечивают разрешение и частоту развертки при 32-битном цвете, превышающие возможности современных мониторов. Кроме того, в них поддерживается режим Direct Color, т. е. возможность прямого доступа к элементам DAC. Это позволяет создавать независимые таблицы для каждого из трех основных цветов, что дает возможность корректировать искажения яркости цвета на электронно-лучевой трубке (ЭЛТ) монитора, вызванные нелинейной зависимостью между подаваемым на ЭЛТ напряжением и яркостью. Эта операция называется гамма-коррекцией. С ее помощью можно регулировать яркость в диапазоне от 0,3 до 4,0, где 1,0 — значение по умолчанию.
Качество получаемого изображения в решающей степени зависит от таких характеристик RAMDAC, как его частота, разрядность, время переключения сигнала с уровня черного цвета на уровень белого и обратно, варианта исполнения (внешний или внутренний). Частота RAMDAC говорит о том, какое максимальное разрешение и при какой частоте кадровой развертки сможет поддерживать видеоадаптер. RAMDAC в современных графических процессорах, как правило, работают с тактовой частотой, равной 400 МГц. Разрядность RAMDAC показывает, какое число цветов способен воспроизвести видеоадаптер. Большинство микросхем поддерживает представление 8 бит на каждый канал цвета, что обеспечивает отображение около 16,7 млн цветов. За счет гамма-коррекции исходное цветовое пространство расширяется. Современные RAMDAC поддерживают целочисленный тип данных RGB A (10:10:10:2) в буфере кадра для более качественного рендеринга с разрядностью 10 бит по каждому каналу, охватывающему более 1 млрд цветов. Следует обратить внимание на то, как именно выполнен модуль RAMDAC на видеокарте — внутренним или внешним. Обычно в современных графических процессорах он размещается на одном кристалле с видеопроцессором. Многие современные видеокарты поддерживают одновременную работу с двумя мониторами, поэтому в такие карты устанавливаются по два RAMDAC и соответственно по два разъема для подключения монитора. В подавляющем большинстве видеокарт имеется также выход на телевизор (TV-out), позволяющий просматривать мультимедийные программы или фильмы на телевизионном экране. Телевизионный сигнал обычно формируется отдельной специализированной микросхемой, получающей данные от RAMDAC. Большинство современных видеоадаптеров имеют выход DVI (часто два) для подключения цифрового монитора. Преимущество цифрового интерфейса перед RAMDAC заключается в том, что при выводе изображения не выполняются цифроаналоговые преобразования изначально цифрового сигнала, что теоретически обеспечивает лучшее качество. На практике разница незаметна: современные видеоадаптеры выдают идеальную картинку и на аналоговые, и на цифровые устройства. Интерфейс. Интерфейс видеокарты обеспечивает сопряжение с северным мостом чипсета. Рост производительности видеоадаптеров потребовал разработки и внедрения специализированного интерфейса AGP (Accelerated Graphic Port — ускоренный графический порт), который обеспечил приоритетный доступ видеоадаптера к системной памяти и пиковую пропускную способность шины 2133 Мбайт/с (версия AGP8X). В настоящее время осуществляется переход на последовательный интерфейс PCI Express. В современных компьютерах для подключения графических карт используется версия PCI Express xl6 с максимальной пропускной способностью шины 4000 Мбайт/с в обоих направлениях. Аналоговые компоненты. Аналоговые компоненты видеокарты обеспечивают стабильное питание микросхем и формирование сигналов нужной формы на аналоговых выходах (на монитор и телевизор). Видеокарты высокой производительности имеют высокое энергопотребление, часто потребляемая мощность превышает 100 Вт и поэтому их снабжают специальным дополнительным разъемом питания. Кроме того, высокая потребляемая мощность требует эффективной системы охлаждения и системы контроля температуры графического процессора, которые по сложности не уступают соответствующим системам ЦП. Высокая частота аналоговых сигналов на выходах к монитору и к телевизору требует тщательного согласования с приемниками, а также защиты от помех. Качество выходных сигналов видеокарты в значительной мере определяется качеством используемых аналоговых компонентов и технологическим уровнем производства видеокарт. Технологии SLI и CrossFire. Возможность параллельной обработки графической информации на уровне видеоадаптеров или одновременное использование двух видеоадаптеров для повышения производительности была реализована впервые компанией 3dfx в 1998 г. в видеокарте 3dfx Voodoo2 Graphics. Эта технология получила название SLI. В то время аббревиатура расшифровывалась как Scan Line Interleaving (чересстрочное сканирование кадров). С помощью этой технологии для увеличения производительности можно было объединять видеоускорители в ЗБ-приложениях. Подключение производилось по следующему принципу: монитор подключался к ускорителю, а специальный кабель соединял ускоритель с 2Б-видеокартой. Возможности SLI позволяли соединять видеоускоритель с таким же ускорителем посредством плоского кабеля, похожего на АТА- или FDD-шлейф. Таким образом, вся видеосистема занимала три слота PCI, что было не очень удобно, но (по зявлениям компании 3dfx) позволяло увеличить производительность вдвое. Однако реальный прирост производительности составлял 20...50 %. Принцип работы Voodoo2 SLI заключался в том, что адаптеры вычисляли строки изображения поочередно. Каждый ускоритель записывал свои строки в видеопамять и через свой цифроаналоговый преобразователь выводил их на монитор. Если компоненты видеокарт отличались по характеристикам, могли возникать ошибки в отображении картинки. Длительный период времени видеокарте Voodoo2 Graphics в режиме SLI по производительности не было равных. Однако с появлением новых чипов nVidia RivaTNT и ATI Rage и шины AGP, а также объединением 2О-ускорителя и видеокарты в одном устройстве ускорители Voodoo2 Graphics стали пользоваться все меньшей популярностью и вскоре исчезли с рынка. Технология параллельного использования двух видеоадаптеров была возрождена компанией nVidia после разработки шины PCI Express. Число разъемов с этой шиной на современных системных платах, как правило, превышает 2 (в отличие от шины AGP). nVidia, возрождая технологию SLI, решила не менять ее название. Изменилась только расшифровка аббревиатуры. Теперь SLI расшифровывается как Scalable Link Interface (масштабируемый соединительный интерфейс). Для функционирования технологии nVidia SLI необходимо наличие двух видеокарт с поддержкой SLI, системной платы с чипсетом, поддерживающим SLI, можно (но не обязательно) использовать переходную плату SLI-bridge для связи видеокарт и соответствующий драйвер. Технология SLI поддерживает два режима работы пары видеокарт: Split Frame Rendering (SFR) и Alternate Frame Rendering (AFR). В режиме SFR происходит разделение кадра на две части, за рендеринг каждой из которых отвечает отдельный видеоадаптер. При этом кадр разделяется динамически в зависимости от сложности сцены. Такой режим позволяет добиться максимальной производительности за счет равномерной загрузки каждой видеокарты. Метод разделения называется Symmetric Multi-Rendering with Dynamic Load Balancing (SMR), т.е. симметричный мультирендеринг с динамическим распределением нагрузки. В режиме AFR каждый адаптер обрабатывает свой кадр. ЦП перенаправляет ведущей карте запрос на обработку первого кадра и сразу же отправляет ведомой карте запрос на обработку второго кадра. Таким образом, одна видеокарта обрабатывает нечетные кадры, а вторая — четные. Позднее компания nVidia на базе графического процессора nVidia GeForce 7900 GTX/GT (G71) разработала следующий вариант технологии SLI — для четырех чипов. Разумеется, такие решения существовали и раньше, например в промышленных симуляторах для обучения пилотов и в графических суперкомпьютерах. Однако эта технология впервые реализована на обычном PC на базе, вставляемой в один слот двухчиповой карты на базе GeForce от nVidia. Карта с двумя чипами сама по себе представляет SLI-решение. На системную плату, поддерживающую SLI, можно устанавливать две такие двухчиповые карты. Таким образом, компания nVidia предлагает два варианта — одиночное SLI-решение на двух чипах внутри одной карты и SLI-решение на четырех чипах (Quad- SLI путем установки второй подобной карты). Очевидно, что производительность четырехпроцессорной конфигурации будет высокой, а при некоторых условиях и очень высокой. Выпуск подобной двухчиповой графической карты стал возможным только благодаря низкому энергопотреблению и тепловыделению, а также низкой себестоимости чипа. Карта состоит из базовой и дополнительной плат, занимает ширину двух слотов и при работе в режиме Quad-SLI связывается двумя каналами с соседней двухчиповой картой. Таким образом, получаем топологию квадрата — оба чипа карты связаны друг с другом и каждый связан с еще одним чипом соседней карты. Кроме того, на каждой двухчиповой карте установлен мост PCI-E х16, осуществляющий арбитраж и доступ к обоим ускорителям со стороны системы. Режимы работы двух видеокарт аналогичны предыдущим. Есть три режима совместной работы: AFR (чередование расчета кадров между ускорителями), зональный рендеринг (разделение экрана на четыре зоны) и SLI-AA — использование ускорителей для расчета разных АА семплов в пределах одного пиксела. Кроме того, логичным становится комбинирование режимов, например, 2xAFR от двух двухзональных кадров (чередование кадров, каждый из которых построен SLI-методом разделения зон) или зональное разделение 2xSLI-AA и т. д. Комбинаций может быть много, никаких новых архитектурных изменений для этого не нужно, в технологии SLI уже заложены различные возможности, а сочетанием управляет драйвер. Позднее аналогичная технология, получившая название CrossFire, была представлена и компанией ATI. В отличие от SLI, где обе видеокарты должны поддерживать технологию SLI, CrossFire позволяет объединять видеокарты, из которых только одна должна быть выполнена с поддержкой этой технологии, вторая же может быть любой. Кроме того, в технологии CrossFire применяется внешнее соединение видеокарт при помощи специального кабеля. Помимо метода, аналогичного SMR, технология CrossFire предполагает применение еще трех способов рендеринга: SuperTiling, в котором экран делится на множество квадратов и каждая карта обсчитывает половину этих квадратов; чередование кадров (Alternate frame rendering), при котором одна карта отвечает за рендеринг одного кадра, а другая — за рендеринг следующего кадра; и наконец, так называемый Super AA (суперсглаживание), обеспечивающий полноэкранное сглаживание в режиме до 14х. Основным достоинством технологий SLI и CrossFire является увеличение производительности в ЗD-приложениях. Во многих играх увеличение производительности достигает 60...70 %. В тестовых приложениях это значение иногда доходит и до 100 %. Из недостатков рассматриваемых технологий следует выделить высокую стоимость видеосистемы, включая мощный блок питания (от 400 Вт) и системную плату на специальном чипсете. Графические процессоры. Архитектура современных графических процессоров является многопроцессорной, она содержит набор относительно простых специализированных процессоров и АЛУ, ориентирована на полигональное представление трехмерной графики, используемой в современных компьютерных играх, и опирается на следующие основные свойства такого представления: ♦ значительная доля арифметических операций над векторными данными в графических алгоритмах с незначительным количеством логических операций; ♦ возможность эффективного распараллеливания процессов обработки графических объектов благодаря их взаимной независимости; ♦ потоковый характер построения изображения, что позволяет организовать графический конвейер. Исходные данные, которыми оперируют современные графические процессоры (параметры вершин, матрицы преобразования, значения цвета и т. п.), организованы в виде векторов и соответственно большинство операций, выполняемых графическим процессором, являются векторными. Графические векторы, как правило, имеют четвертый порядок, т.е. содержат четыре числа, например три цветных компонента (R, G, В) и степень прозрачности (альфа- канал). Поэтому графические процессоры содержат векторные АЛУ, исполняющие операции с четырьмя компонентами того или иного формата, с произвольной перестановкой компонентов перед вычислениями, с возможностью выполнять разные операции по схеме 3+1 компонентов или даже менее часто востребованной, но все равно потенциально выгодной — 2+2 (две операции над двумя компонентами). Операции со значениями цвета и прозрачности — чисто арифметические. Логически данные друг от друга не зависят, поэтому их можно обрабатывать параллельно. Для этого достаточно иметь одно векторное АЛУ и общий блок управляющей логики, обеспечивающий произвольную перестановку компонентов перед вычислениями. В реальных задачах часто встречаются ситуации, когда необходимо обработать векторы второго порядка или скалярные величины (особенно это касается пиксельных конвейеров и пиксельных алгоритмов). В этом случае вычисления оптимизируются по схеме 2+2. Особенность графических алгоритмов состоит в том, что объекты, обрабатываемые в графическом конвейере, как правило, не зависят друг от друга, при этом возможно распараллеливание обработки данных на нескольких уровнях. Например, при обработке вершин треугольника все три вершины будут обработаны по одному и тому же алгоритму, и более того, совершенно не важен порядок их обработки. Поэтому можно обрабатывать сразу несколько вершин параллельно, так как современные графические процессоры содержат группу вершинных процессоров (8 в nVidia GeForce 7800 GTX). Обработка пикселов еще лучше поддается распараллеливанию. Как следствие происходит рост числа пиксельных конвейеров в архитектуре графического процессора (48 в ATI RADEON XI900 ХТХ/ХТ (R580)), т. е. мощность графического процессора обычно наращивается путем увеличения числа вершинных и пиксельных конвейеров. С внедрением DirectX 9.0с (пиксельные и вершинные шейдеры версии 3.0) в графических алгоритмах появилась возможность динамического управления вычислениями (циклы и ветвления, вызов подпрограмм, предикаты, возврат и другие операции). Характер и порядок обработки данных может зависеть от их исходных значений. Поэтому возникла необходимость создания полноценных параллельных конвейеров, каждый из которых оснащен управляющей логикой обработки динамических ветвлений. Все данные, поступающие в конвейеры графического процессора, организованы как однородные потоки данных. Следовательно, они могут быть предварительно подготовлены для обработки, т. е. выбраны из памяти, помещены в кэш-память и организованы в очереди. Первоначально эти возможности были реализованы в графических процессорах компании NVidia, а затем и в процессорах компании ATI. Архитектура графического процессора (GPU). Структурная схема графического процессора GeForce 7800 GTX компании nVidia представлена на рис. 2.13.
Рис. 2.13. Структурная схема графического процессора GeForce 7800 GTX компании nVidia
ЦП компьютера, подготавливая полигональное описание трехмерной сцены, создает поток параметров вершин полигонов (треугольников), описывающих поверхности трехмерных объектов, присутствующих в кадре. Блок выборки геометрии графического процессора извлекает из ОП или видеопамяти геометрические данные и направляет их в кэш-память вершин. GPU поколения DirectX 9 поддерживают несколько вариантов структуры хранения геометрических данных в видеопамяти, учитывающих особенности полигональных моделей. Кроме того, аппаратно поддерживается гибкий формат данных: для каждой вершины могут храниться не только обычные параметры (координаты или вектор нормали), но и любые другие наборы допустимых скалярных или векторных величин. Технологии памяти развиваются не так стремительно, однако потоковая природа графических алгоритмов позволяет обеспечить современные графические процессоры данными. В графический процессор поступает много разных данных, из него выходит только результирующее изображение. При этом все поступающие данные по своей сути — потоки, они считываются последовательно или почти последовательно. Таким образом, потоки данных могут быть кэшированы, выбраны предварительно, помещены в очереди, для того чтобы подсистема памяти не простаивала и работала эффективно. В современных графических процессорах практически нет произвольного доступа к памяти, что существенно снижает эффективность кэширования. Поэтому в отличие от обычных процессоров кэш-памяти GPU относительно малы, раздельны и работают, как правило, только на чтение. Это позволяет сделать их особенно эффективными — даже кэш-память буфера кадра можно разбить на две части, одна из которых работает только на чтение, а вторая является обычной очередью записи. При этом поддерживается работа с несколькими потоками данных, когда часть атрибутов вершины хранится в одном массиве данных, а другая часть — в другом. Как правило, выборка из памяти происходит одновременно несколькими потоками (обычно по 4 каналам по 64 разряда в каждом). Далее каждая из вершин попадает в вершинный процессор.
Рис. 2.14. Структурная схема вершинного процессора для GPU nVidia GeForce 7800 GTX
Вершинный процессор. В современных графических процессорах блоки обработки вершинных программ соответствуют спецификации Microsoft DirectX 9.0c, т. е. поддерживают вершинные шейдеры (Vertex Shader, VS) версии 3.0. Производительность и число вершинных блоков растут с развитием архитектуры графических процессоров. Структура вершинного процессора компании nVidia представлена на рис. 2.14. Вершинные процессоры позволяют специальным программам (вершинным шейдерам) обрабатывать каждую вершину объекта, выполняя трансформации, расчет освещенности и другие операции. Собственно, графический процессор содержит восемь независимых вершинных процессоров, каждый из которых исполняет свои команды и имеет собственное устройство управления, т. е. разные процессоры могут одновременно исполнять различные участки программ над разными вершинами. За один такт вершинный процессор может выполнить одну векторную операцию (до четырех компонентов в формате с плавающей точкой FP32), одну скалярную операцию в формате FP32 и осуществить один доступ к текстуре (TMU). Поддерживаются целочисленные и плавающие форматы текстур и мипмэппинг. Вершинные процессоры поддерживают статические ветвления, а также динамический контроль выполнения (Flow Control): циклы и ветвления, вызов подпрограмм, предикаты, возврат и другие операции. Из вершинного процессора вершины, обработанные вершинным шейдером с учетом преобразований и освещения, передаются в небольшой промежуточный пост кэш-вершин. Далее осуществляется сборка примитивов, т. е. вершины группируются согласно с используемой топологией и отправляются в блок установки треугольников, где происходит предварительная подготовка данных, не- обходимых для закраски всего треугольника. Здесь же производится отбрасывание невидимых и повернутых к наблюдателю обратной стороной треугольников. Затем треугольник разбивается на фрагменты, часть которых признается невидимыми и отбрасывается в ходе предварительного теста глубины (Z-теста) на уровне фрагментов (технология удаления невидимых поверхностей HSR (Hidden Surface Remove)). Как правило, конечным результатом этого процесса являются видимые (или частично видимые) фрагменты размером 2x2 пиксела, называемые квадами и подлежащие закраске. Именно такие фрагменты наиболее удобны для быстрой закраски пикселов (по нескольким, в основном математическим причинам, связанным с интерполяцией текстурных координат). В современных процессорах закраска осуществляется в два этапа и на двух уровнях — блоков размером 4x4 пиксела (удобно для работы с буфером глубины — Z-буфером) и квадов размером 2x2 (квадами осуществляется закраска в пиксельном процессоре). Вначале треугольник полностью покрывается блоками и, если даже один пиксел блока принадлежит треугольнику, он считается кандидатом на закраску. Далее из рассмотрения удаляются все полностью невидимые блоки. Остальные блоки разбиваются на квады и для каждого из них вычисляются Z-координаты. Сравниваются значения глубины и отбрасываются полностью невидимые квады, а остальные отправляются на установку и закраску в пиксельный процессор. При этом квады дополняются вычисленными значениями глубины и специальной битовой маской, определяющей видимые и невидимые пикселы квада. В результате этого процесса в среднем половина пикселов будет отброшена еще до закраски. Затем квады отправляются на установку фрагментов. Здесь для каждого из них вычисляются необходимые далее параметры: текстурные координаты, МГР-уровень, векторы и установочные данные для анизотропной фильтрации и т. д. По мере роста сложности пиксельных шейдеров растет число передаваемых и интерполируемых для каждой точки параметров. Интерполяция требует сложных вычислительных операций, но использование квадов позволяет существенно повысить эффективность этого процесса за счет определения базовых параметров для одного пиксела, а для остальных — векторов преобразований. После установки и интерполяции параметров происходит закраска фрагментов в пиксельном процессоре. Пиксельный процессор. После расчета значений цвета в пиксельном процессоре происходит смешивание значений с уже существующими в буфере кадра или блендинга (если включен соответствующий режим) или просто запись результирующих значений цвета и глубины в буфер кадра. На этом этапе возможно выполнение дополнительных операций: гамма-коррекция, вычисление самого дальнего значения глубины блока 4x4 для пересылки в иерархический буфер глубины, сжатие Z-координат и т. д.
Структура пиксельного процессора компании nVidia представлена на рис. 2.15. В пиксельном процессоре в обработке находится одновременно несколько сотен квадов. Для процессора квад представляет собой структуру данных, содержащую для каждого из четырех пикселов следующую информацию:
Рис. 2.15. Структурная схема пиксельного процессора для GPU nVidia GeForce 7800 GTX
♦ флаг активности данного пикселя (поскольку не все точки квада могут быть видимыми); ♦ флаг значения предиката для данного пиксела; ♦ значение Z и, возможно, значения буфера шаблонов; ♦ два векторных временных регистра FP32[4], которые могут быть разделены на четыре FP16[4]. Все обрабатываемые квады по очереди проходят через длинный пиксельный конвейер, состоящий из АЛУ, двух текстурных модулей и затем еще двух АЛУ. Длина конвейера составляет более двухсот тактов. Большая часть конвейера (около 170 тактов) приходится на операции выборки и фильтрации текстур, выполняемые в текстурных блоках. В нормальном режиме работы конвейер способен выдавать по кваду за один такт.
|
|||||||||
|
|
Последнее изменение этой страницы: 2016-04-25; просмотров: 937; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.14.130.24 (0.052 с.) |