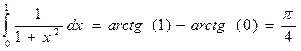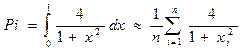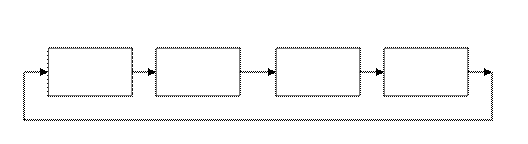Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Программа умножения матрицы на вектор
Результатом умножения матрицы на вектор является вектор результата. Для решения задачи используется алгоритм, в котором один процесс (главный) координирует работу других процессов (подчиненных). Для наглядности единая программа матрично-векторного умножения разбита на три части: общую часть, код главного процесса и код подчиненного процесса. В общей части программы описываются основные объекты задачи: матрица А, вектор b, результирующий вектор с, определяется число процессов (не меньше двух). Задача разбивается на две части: главный процесс (master) и подчиненные процессы. В задаче умножения матрицы на вектор единица работы, которую нужно раздать процессам, состоит из скалярного произведения строки матрицы A на вектор b. Знаком! отмечены комментарии.
program main use mpi integer MAX_ROWS, MAX_COLS, rows, cols parameter (MAX_ROWS = 1000, MAX_COLS = 1000) ! матрица А, вектор b, результирующий вектор с double precision a(MAX_ROWS,MAX_COLS), b(MAX_COLS), с(MAX_ROWS) double precision buffer (MAX_COLS), ans /* ans – имя результата*/ integer myid, master, numprocs, ierr, status (MPI_STATUS_SIZE) integer i, j, numsent, sender, anstype, row /* numsent – число посланных строк, sender – имя процесса-отправителя, anstype – номер посланной строки*/ call MPI_INIT(ierr) call MPI_COMM_RANK(MPI_COMM_WORLD, myid, ierr) call MPI_COMM_SIZE(MPI_COMM_WORLD, numprocs, ierr) ! главный процесс – master master = 0 ! количество строк и столбцов матрицы А rows = 100 cols = 100 if (myid.eq. master) then ! код главного процесса else ! код подчиненного процесса endif call MPI_FINALIZE(ierr) stop end
Код главного процесса. Единицей работы подчиненного процесса является умножение строки матрицы на вектор. ! инициализация А и b do 20 j = 1, cols b(j) = j do 10 i = 1, rows a(i,j) = i 10 continue 20 continue numsent = 0 ! посылка b каждому подчиненному процессу call MPI_BCAST(b, cols, MPI_DOUBLE_PRECISION, master, MPI_COMM_WORLD, ierr) ! посылка строки каждому подчиненному процессу; в TAG номер строки = i do 40 i = 1,min(numprocs-l, rows) do 30 j = I, cols buffer(j) = a(i,j) 30 continue call MPI_SEND(buffer, cols, MPI_DOUBLE_PRECISION, i, i, MPI_COMM_WORLD, ierr) numsent = numsent + l 40 continue ! прием результата от подчиненного процесса do 70 i = 1, rows ! MPI_ANY_TAG – указывает, что принимается любая строка call MPI_RECV(ans, 1, MPI_DOUBLE_PRECISION, MPI_ANY_SOURCE, MPI_ANY_TAG, MPI_COMM_WORLD, status, ierr) sender = status (MPI_SOURCE) anstype = status (MPI_TAG) ! определяем номер строки c(anstype) = ans if (numsent.lt. rows) then ! посылка следующей строки do 50 j = 1, cols buffer(j) = a(numsent+l, j) 50 continue call MPI_SEND (buffer, cols, MPI_DOUBLE_PRECISION, sender, numsent+l, MPI_COMM_WORLD, ierr)
numsent = numsent+l else ! посылка признака конца работы call MPI_SEND(MPI_BOTTQM, 0, MPI_DOUBLE_PRECISION,sender, 0, MPI_COMM_WORLD, ierr) endif 70 continue
Сначала главный процесс передает вектор b в каждый подчиненный про- цесс, затем пересылает одну строку матрицы A в каждый подчиненный процесс. Главный процесс, получая результат от очередного подчиненного процесса, пе- редает ему новую работу. Цикл заканчивается, когда все строки будут розданы и получены результаты. При передаче данных из главного процесса в параметре tag указывается номер передаваемой строки. Этот номер после вычисления произведения вме- сте с результатом будет отправлен в главный процесс, чтобы главный процесс знал, где размещать результат. Подчиненные процессы посылают результаты в главный процесс и пара- метр MPI_ANY_TAG в операции приема главного процесса указывает, что главный процесс принимает строки в любой последовательности. Параметр status обеспечивает информацию, относящуюся к полученному сообщению. В языке Fortran это – массив целых чисел размера MPI_STATUS_SIZE. Аргу- мент SOURCE содержит номер процесса, который послал сообщение, по этому адресу главный процесс будет пересылать новую работу. Аргумент TAG хра- нит номер обработанной строки, что обеспечивает размещение полученного ре- зультата. После того как главной процесс разослал все строки матрицы А, на запросы подчиненных процессов он отвечает сообщением с отметкой 0. Код подчиненного процесса. ! прием вектора b всеми подчиненными процессами call MPI_BCAST(b, cols, MPI_DOUBLE_PRECISION, master, MPI_COMM_WORLD, ierr) ! выход, если процессов больше количества строк матрицы if (numprocs.gt. rows) goto 200 ! прием строки матрицы 90 call MPI_RECV(buffer, cols, MPI_DOUBLE_PRECISION, master, MPI_ANY_TAG, MPI_COMM_WORLD, status, ierr) if (status (MPI_TAG).eq. 0) then go to 200 ! конец работы else row = status (MPI_TAG) ! номер полученной строки ans = 0.0 do 100 i = 1, cols ! скалярное произведение векторов ans = ans+buffer(i)*b(i) 100 continue ! передача результата головному процессу call MPI_SEND(ans,1,MPI_DOUBLE_PRECISION,master,row, MPI_COMM_WORLD, ierr) go to 90 ! цикл для приема следующей строки матрицы endif 200 continue Каждый подчиненный процесс получает вектор b. Затем организуется цикл, состоящий в том, что подчиненный процесс получает очередную строку матрицы А, формирует скалярное произведение строки и вектора b, посылает результат главному процессу, получает новую строку и так далее.
ЛЕКЦИЯ 15. OpenMP Интерфейс OpenMP задуман как стандарт для программирования на масштабируемых SMP-системах (модель общей памяти). В стандарт OpenMP входят спецификации набора директив компилятора, процедур и переменных среды. До появления OpenMP не было подходящего стандарта для эффективно- го программирования на SMP-системах. Наиболее гибким, переносимым и общепринятым интерфейсом параллель ного программирования является MPI (интерфейс передачи сообщений). Одна- ко модель передачи сообщений: • недостаточно эффективна на SMP-системах; • относительно сложна в освоении, так как требует мышления в "невычислительных" терминах. POSIX-интерфейс для организации нитей (Pthreads) поддерживается широко (практически на всех UNIX-системах), однако по многим причинам не подходит для практического параллельного програм- мирования: слишком низкий уровень, нет поддержки параллелизма по данным. OpenMP можно рассматривать как высокоуровневую надстройку над Pthreads (или аналогичными библиотеками нитей). За счет идеи "инкременталь- ного распараллеливания" OpenMP идеально подходит для разработчиков, же- лающих быстро распараллелить свои вычислительные программы с большими параллельными циклами. Разработчик не создает новую параллельную про- грамму, а просто последовательно добавляет в текст последовательной про- граммы OpenMP-директивы. При этом, OpenMP - достаточно гибкий механизм, предоставляющий разработчику большие возможности контроля над поведени- ем параллельного приложения. Предполагается, что OpenMP-программа на од- нопроцессорной платформе может быть использована в качестве последова- тельной программы, т.е. нет необходимости поддерживать последовательную и параллельную версии. Директивы OpenMP просто игнорируются последова- тельным компилятором. Спецификация OpenMP для C/C++, содержит следующую функциональ- ность: • Директивы OpenMP начинаются с комбинации символов "# pragma omp". Директивы можно разделить на 3 категории: определение парал лельной секции, разделение работы, синхронизация. Каждая директива может иметь несколько дополнительных. • Компилятор с поддержкой OpenMP определяет макрос " _OPENMP", ко торый может использоваться для условной компиляции отдельных бло- ков, характерных для параллельной версии программы. • Распараллеливание применяется к for-циклам, для этого используется ди ректива " #pragma omp for ". В параллельных циклах запрещается исполь- зовать оператор break. • Статические (static) переменные, определенные в параллельной области программы, являются общими (shared). • Память, выделенная с помощью malloc(), является общей (однако указа- тель на нее может быть как общим, так и приватным). • Типы и функции OpenMP определены во включаемом файле < omp.h >. • Кроме обычных, возможны также "вложенные" (nested) мьютексы - вме- сто логических переменных используются целые числа, и нить, уже за- хватившая мьютекс, при повторном захвате может увеличить это число. Программная модель OpenMP представляет собой fork-join параллелизм, в котором главный поток по необходимости порождает группы потоков, при
вхождении программы в параллельные области приложения. В случае симметричного мультипроцессинга SMP на всех процессорах процессорной системы исполняется один экземпляр операционной системы, которая отвечает за распределение прикладных процессов (задач, потоков) между отдельными процессорами. Интерфейс OpenMP является стандартом для программирования на мас- штабируемых SMP-системах с разделяемой памятью. В стандарт OpenMP вхо- дят описания набора директив компилятора, переменных среды и процедур. За счет идеи "инкрементального распараллеливания" OpenMP идеально подходит для разработчиков, желающих быстро распараллелить свои вычислительные программы с большими параллельными циклами. Разработчик не создает но- вую параллельную программу, а просто добавляет в текст последовательной программы OpenMP-директивы. Предполагается, что OpenMP-программа на однопроцессорной платформе может быть использована в качестве последовательной программы, т.е. нет необходимости поддерживать последовательную и параллельную версии. Директивы OpenMP просто игнорируются последовательным компилятором, а для вызова процедур OpenMP могут быть подставлены заглушки, текст которых приведен в спецификациях. В OpenMP любой процесс состоит из нескольких нитей управления, которые имеют общее адресное пространство, но разные по- токи команд и раздельные стеки. В простейшем случае, процесс состоит из од- ной нити. Обычно для демонстрации параллельных вычислений используют простую программу вычисления числа π. Рассмотрим, как можно написать такую программу в OpenMP. Число π можно определить следующим образом:
Вычисление интеграла затем заменяют вычислением суммы:
где xi = (i- 1/2 ) / n.
В последовательную программу вставлены две строки (директивы), и она становится параллельной
#include <stdio.h> double f(double y) {return(4.0/(1.0+y*y));} int main() { double w, x, sum, pi; int i; int n = 1000000; w = 1.0/n; sum = 0.0; #pragma omp parallel for private(x) shared(w)\ reduction(+:sum) for(i=0; i < n; i++) { x = w*(i-0.5); sum = sum + f(x); } pi = w*sum; printf("pi = %f\n", pi); } Программа начинается как единственный процесс на головном процессоре. Он исполняет все операторы вплоть до первой конструкции типа #pragma omp. В рассматриваемом примере это оператор parallel for, при исполнении которого порождается множество процессов с соответствующим каждому процессу окружением. В случае симметричного мультипроцессинга SMP на всех процессорах процессорной системы исполняется один экземпляр операционной системы, которая отвечает за распределение прикладных процессов (задач, потоков) между отдельными процессорами. Распараллеливание применяется к for-циклам, для этого используется директива " #pragma omp for ", по которой ОС раздает процессорам (ядрам) личный экземпляр программы, как в SPMD, попросту передает один и тотже отрезок программы на заданное число процессоров. Распараллеливание применяется к for-циклам, для этого используется директива
" #pragma omp for ", по котоой ОС раздает ппроцессорам (ядрам) личный эк- земпляр программы, как в SPMD. В рассматриваемом примере окружение состоит из локальной (PRIVATE) переменной х, переменной sum редукции (REDUCTION) и одной разделяемой (SHARED) переменной w. Переменные х и sum локальны в каждом процессе без разделения между несколькими процессами. Переменная w располагается в головном процессе. Оператор REDUCTION имеет в качестве атрибута опера- цию, которая применяется к локальным копиям параллельных процессов в кон- це каждого процесса для вычисления значения переменной в головном процес- се. Переменная цикла i является локальной в каждом процессе, так как именно с уникальным значением этой переменной порождается каждый процесс. Па- раллельные процессы завершаются оператором END DO, выступающим как синхронизирующий барьер для порожденных процессов. После завершения всех процессов продолжается только головной процесс. Директивы OpenMP с точки зрения C являются комментариями и начина- ются с комбинации символов #pragma, поэтому приведенная выше программа может без изменений выполняться на последовательной ЭВМ в обычном ре- жиме. Распараллеливание в OpenMP выполняется при помощи вставки в текст программы специальных директив, а также вызова вспомогательных функций. При использовании OpenMP предполагается SPMD-модель (Single Program Multiple Data) параллельного программирования, в рамках которой для всех параллельных нитей используется один и тот же код. Программа начинается с последовательной области – сначала работает один процесс (нить), при входе в параллельную область порождается (компилятором) ещё некоторое число процессов, между которыми в дальнейшем распре- деляются части кода. По завершении параллельной области все нити, кроме одной (нити мастера), завершаются, и начинается последовательная область. В программе может быть любое количество параллельных и последовательных областей. Кроме того, параллельные области могут быть также вложенными друг в друга. В отличие от полноценных процессов, порождение нитей является отно сительно быстрой операцией, поэтому частые порождения и завершения нитей не так сильно влияют на время выполнения программы. После получения исполняемого файла необходимо запустить его на требуемом количестве процессоров. Для этого обычно нужно задать количество ни тей, выполняющих параллельные области программы, определив значение
переменной среды MP_NUM_THREADS. После запуска начинает работать од- на нить, а внутри параллельных областей одна и та же программа будет выпол- няться всем набором нитей. При выходе из параллельной области производится неявная синхронизация и уничтожаются все нити, кроме породившей. Все по- рождённые нити исполняют один и тот же код, соответствующий параллельной области. Предполагается, что в SMP-системе нити будут распределены по раз- личным процессорам, однако это, как правило, находится в ведении операци- онной системы. Перед запуском программы количество нитей, выполняющих параллельную область, можно задать, с помощью переменной среды МP_NUM_THREADS. Например, в Linux это можно сделать при помощи следующей команды: export OMP_NUM_THREADS=n. Функция omp_get_num_procs () возвращает количество процессоров, доступных для использования программе пользователя на момент вызова. Директивы master (master... end master) выделяют участок кода, который будет выполнен только нитью-мастером. Остальные нити просто пропускают данный участок и продолжают работу с оператора, расположенно- го следом за ним. Неявной синхронизации данная директива не предполагает. Модель данных в OpenMP предполагает наличие как общей для всех нитей области памяти, так и локальной области памяти для каждой нити. В OpenMP переменные в параллельных областях программы разделяются на два основных класса: • shared (общие; все нити видят одну и ту же переменную); • private (локальные, каждая нить видит свой экземпляр переменной). Общая переменная всегда существует лишь в одном экземпляре для всей области действия. Объявление локальной переменной вызывает порождение своего экземпляра данной переменной (того же типа и размера) для каждой нити. Изменение нитью значения своей локальной переменной никак не влияет на изменение значения этой же локальной переменной в других нитях. Если не- сколько переменных одновременно записывают значение общей переменной без выполнения синхронизации или если как минимум одна нить читает значе- ние общей переменной и как минимум одна нить записывает значение этой переменной без выполнения синхронизации, то возникает ситуация так назы- ваемой «гонки данных». Для синхронизации используется оператор barrier: #pragma omp barrier Нити, выполняющие текущую параллельную область, дойдя до этой директивы, ждут, пока все нити не дойдут до этой точки прграммы, после чего разблокируются и продолжают работать дальше. Директивы OpenMP просто игнорируются последовательным компилятором, а для вызова функций OpenMP могут быть подставлены специальные «за- глушки» (stub), текст которых приведен в описании стандарта. Они гарантиру- ют корректную работу программы в последовательном случае – нужно только перекомпилировать программу и подключить другую библиотеку. OpenMP может использоваться совместно с другими технологиями парал- лельного программирования, например, с MPI. Обычно в этом случае MPI ис- пользуется для распределения работы между несколькими вычислительными узлами, а OpenMP затем используется для распараллеливания на одном узле. Простейшая программа, реализующаяю перемножение двух квадратных матриц, представлена ниже. В программе замеряется время на основной вычислительный блок, не включающий начальную инициализацию. В ос- новном вычислительном блоке программы на языке Фортран изменён порядок циклов с параметрами i и j для лучшего соответствия правилам размещения элементов массивов.
#include <stdio.h> #include <omp.h> #define N 4096 double a[N][N], b[N][N], c[N][N]; int main() { int i, j, k; double t1, t2; // инициализация матриц for (i=0; i<N; i++) for (j=0; j<N; j++) a[i][j]=b[i][j]=i*j; t1=omp_get_wtime(); // основной вычислительный блок #pragma omp parallel for shared(a, b, c) private(i, j, k) for(i=0; i<N; i++){ for(j=0; j<N; j++){ c[i][j] = 0.0; for(k=0; k<N; k++) c[i][j]+=a[i][k]*b[k][j]; } } t2=omp_get_wtime(); printf("Time=%lf\n", t2-t1)
ЛЕКЦИЯ 16.
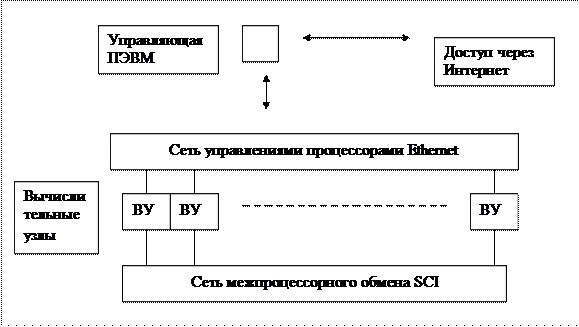
Рассмотрим реализации, которые позволяют увеличить количество одновременно работающих АЛУ, процессоров, что увеличивает быстродействие ЭВМ. ВЫЧИСЛИТЕЛЬНЫЕ КЛАСТЕРЫ. Кластер. Магистральным направлением развития параллельных ЭВМ для крупноформатного параллелизма является построение таких систем на базе средств массового выпуска: микропроцессоров, каналов обмена данными, сис- темного программного обеспечения, языков программирования. Системы с индивидуальной памятью идеально подходят для реализации на основе электронной и программной продукции массового производства. При этом не требуется разработки никакой аппаратуры. Такие системы получили название кластеры рабочих станций или просто «кластеры». Кластеры также используются и в системах для распределенных вычислений Грид. В общем случае, вычислительный кластер - это набор компьютеров (вычислительных узлов), объединенных некоторой коммуникационной сетью. Каждый вычислительный узел имеет свою оперативную память и работает под управлением своей операционной системы. Наиболее распространенным является использование однородных кластеров, то есть таких, где все узлы абсолютно одинаковы по своей архитектуре и производительности. Первым в мире кластером является кластер Beowulf, созданный в научно- космическом центре NASA – Goddard Space Flight Center летом 1994 года. На- званный в честь героя скандинавской саги, кластер состоял из 16 компьютеров. Особенностью такого кластера является масштабируемость, то есть возмож- ность увеличения количества узлов системы с пропорциональным увеличением производительности. Узлами в кластере могут служить любые серийно выпус- каемые автономные компьютеры, количество которых может быть от 2 до 1024 и более. В свою очередь кластеры можно разделить на две заметно отличающиеся по производительности ветви: • Кластеры типа Beowulf, которые строятся на базе обычной локальной сети ПЭВМ. Используются в вузах для учебной работы и небольших организациях для выполнениях проектов. • Монолитные кластеры, все оборудование которых компактно размещено в специализированных стойках массового производства. Это очень быстрые машины, число процессоров в которых может достигать сотен и тысяч. Про- цессоры в монолитных кластерах не могут использоваться в персональном режиме. Однако, в обоих случаях, кластер строится на продукции массового производства, в частности, на локальных сетях. Основное отличие кластеров от локальных сетей заключается в системном программном обеспечении (СПО). Таким пакетом в частности является широко распространенная библиотеке функций обмена для кластеров MPI (Message Passsing Interfase). Для реализации этих функций разработчики MPI на основе возможностей ОС Linux создали специальный пакет MPICH, решающий эту и многие другие задачи. Такой же пакет сделан и для ОС Windows NT. Организация кластера. Рассмотрим пример структуры кластера на базе локальной сети. Кластерная система состоит из: • стандартных вычислительных узлов (процессоры); • высокоскоростной сети передачи данных SCI; • управляющей сети Fast Ethernet/Gigabyte Ethernet; • управляющей ПЭВМ. • сетевой операционной системы LINUX или WINDOWS; • специализированных программных средств для поддержки обменов дан- ными (MPICH).
Управляющая ПЭВМ кластера является администратором кластера, то есть определяет конфигурацию кластера, его секционирование, подключение и отключение узлов, контроль работоспособности, обеспечивает прием заданий на выполнение вычислительных работ и контроль процесса их выполнения, планирует выполнение заданий на кластере. В качестве планировщиков обычно используются широко распрастраненные пакеты PBS, Condor, Maui и др. Для организации взаимодействия вычислительных узлов суперкомпьютера в его составе используются различные сетевые (аппаратные и программные) средства, в совокупности образующие две системы передачи данных: Сеть межпроцессорного обмена объединяет узлы кластерного уровня в кластер. Эта сеть поддерживает масштабируемость кластерного уровня суперкомпьютера, а также пересылку и когерентность данных во всех вычислительных узлах кластерного уровня суперкомпьютера в соответствии с программой на языке MPI. Сеть управления предназначена для управления системой, подключения рабочих мест пользователей, интеграции суперкомпьютера в локальную сеть предприятия и/или в глобальные сети. В качестве вычислительных узлов обычно используются однопроцессорные компьютеры, двух- или четырехпроцессорные SMP-серверы или их многоядерные реализации. Каждый узел работает под управлением своей копии операционной систе- мы, в качестве которой чаще всего используются стандартные операционные системы: Linux, Windows и др. Состав и мощность узлов может меняться даже в рамках одного кластера, давая возможность создавать неоднородные системы. Наиболее распространенной библиотекой параллельного программирования в модели передачи сообщений является MPI. Рекомендуемой бесплатной реализацией MPI является пакет MPICH, разработанный в Аргоннской национальной лаборатории. Коммуникационные сети. Коммутатором, противоположным по своим свойствам полному координатному соединителю, является общая шина UNIBUS, в которой осуществлятся только один обмен в единицу времени. Между этими крайними случаями имеется множество сетей, отличающихся назначением, быстродействием и стоимостью. Рассмотрим некоторые реальные системы обмена. Шинные технологии – Ethernet. Самая простая форма топологии (bus) физической шины представляет собой один основной кабель, оконцованный с обеих сторон специальными типами разъемов – терминаторами. При создании такой сети основной кабель прокладывают последовательно от одного сетевого устройства к другому. Сами устройства подключаются к основному кабелю с использованием подводящих кабелей и T-образных разъемов. Пример такой топологии:
Наиболее распространенной коммуникационной технологией для локальных сетей является технология Ethernet, которая имеет несколько технических реализаций. Технология Ethernet, Fast Ethernet, Gigabit Ethernet обеспечивают скорость передачи данных соответственно 10, 100 и 1000 Мбит/с. Все эти технологии используют один метод доступа – CSMA/CD (carrier-sense-multiply-access with collision detection), одинаковые форматы кадров, работают в полу- и полнодуплексном режимах. Метод предназначен для среды, разделяемой всеми абонентами сети. Основной недостаток сетей Ethernet на концентраторе состоит в том, что в них в единицу времени может передаваться только один пакет данных. Обста- новка усугубляется задержками доступа из-за коллизий. Для исключения за- держек такого рода используются промежуточные коммутаторы – свичи (switch). Кольцевые коммутаторы. Для кластеров большого размера (несколько десятков или сотен узлов) Ethernet оказывается медленным, поэтому используют более быстрые технологии, например, кольцевые. Наиболее известным представителем кольцевых структур является сеть SCI (Scalable Coherent Interface).Структура сети представлена на рисунке.
Каждый узел имеет входной и выходной каналы. Узлы связаны однона- правленными каналами «точка – точка». При объединении узлов должна обя- зательно формироваться циклическая магистраль (кольцо) из соединяемых узлов. Один узел в кольце, называемый «scrubber» (очиститель), выполняет функции уничтожения пакетов, не нашедших адресата. Этот узел помечает проходящие через него пакеты и уничтожает уже помеченные пакеты. В кольце может быть только один scrubber.
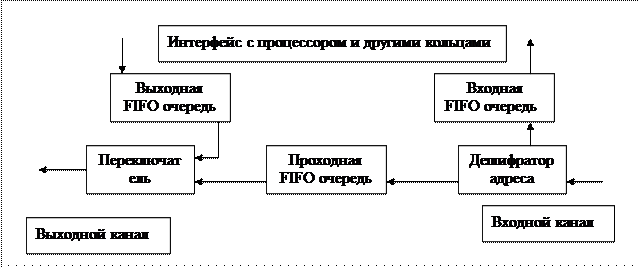
Узлы SCI должны отсылать сформированные в них пакеты, возможно с одновременным приемом других пакетов, адресованных узлу, и пропуском через узел транзитных пакетов. Для транзитных пакетов, прибывающих во время передачи узлом собственного пакета, предусмотрена проходная FIFO очередь. Размер проходной очереди должен быть достаточен для приема пакетов без переполнения. В узле также вводятся входная и выходная FIFO очереди для пакетов, принимаемых и передаваемых узлом соответственно. Узел SCI принимает поток данных и передает другой поток данных.Эти потоки состоят из SCI пакетов и свободных (пустых – iddle) символов. Через каналы непрерывно передаются либо символы пакетов, либо свободные символы, которые заполняют интервалы между пакетами. Узел может передавать пакеты, если его проходная FIFO очередь пуста. Передача пакета инициируется его перемещением в выходную FIFO очередь. Если в течение заданного времени не поступает ответный пакет, то выполняется повтор передачи пакета. Узел может послать много пакетов (вплоть до 64) прежде, чем будет полу чен ответный эхо-пакет. Эхо-пакеты могут приходить не в том порядке, в кото- ром были посланы инициировавшие их пакеты, поэтому необходимы номера пакетов для установления соответствия между пакетами и эхо-пакетами. Для предотвращения блокировок всем узлам предоставляется право доступа к SCI. Это означает, что все возможные 64К устройств могут начать передачу одновременно. Это и есть масштабируемость. Главный недостаток сети SCI - физические ограничения на общую протя- женность сети. Поэтому SCI применяется только для кластеров, поскольку они расположены на ограниченной территории. SCI не подходит для Грид. Время передачи сообщения от узла А к узлу В в кластерной системе опреде- ляется выражением T = S+ L / R, где S - латентность, L – длина сообщения, а R - пропускная способность канала связи. Латентность (задержка) – это промежу- ток времени между запуском операции обмена в программе пользователя и на- чалом реальной передачи данных в коммуникационной сети. Другими словами – это время передачи пакета с нулевым объемом данных. В таблице представлены характеристики некоторых технологий для обмена данными
ЛЕКЦИЯ 17. Метод Гаусса решения СЛАУ на кластере.
|
|||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-04-08; просмотров: 1121; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.119.126.80 (0.263 с.) |