Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Значения коэффициента корреляции
* (x1) отгружено товаров собственного производства, выполнено работ и услуг собственными силами, (x2) в том числе инновационные товары, работы, услуги, (x3) затраты на инновационную деятельность, (x4) объем инвестиций в основной капитал, направленных на ИКТ оборудования, в фактически действовавших ценах, (x5) численность персонала, занятого научными исследованиями и разработками, по категориям по РФ, (x6) внутренние затраты на научные исследования и разработки по видам экономической деятельности по РФ, (x7) внутренние текущие затраты на научные исследования и разработки, а также (x8) затраты на инновационную деятельность малых предприятий по субъектам РФ и (y) инвестиции в основной капитал в РФ. __________________ * Источник: составлено авторами на основе проведенных расчетов
Известно, что значение данного коэффициента не превышает 1 по модулю: при этом, чем оно выше, тем более выражена связь между исследуемыми показателями. Таким образом, проанализировав данные таблицы, можно сделать вывод о том, что показатель инвестиций в основной капитал РФ тесно связан с другими показателями, так как значение модуля коэффициента корреляции находится в промежутке от 0,9 до 1, что говорит о прямой взаимозависимости этих величин. Очевидный интерес вызывает то, что количество задействованных в наукоёмких производствах людей или количества трудовых ресурсов имеет обратную корреляцию. Это наблюдение свидетельствует о том, что при увеличении инвестиций в основной капитал сокращается численность персонала, связанного с наукоёмкими производствами. Для практического создания и обучения модели был использован язык программирования Python с библиотеками pandas, matplotlib и sklearn [4]. Изначально на этом этапе использованные данные привели в формат, позволяющий модели машинного обучения выявлять малозаметные закономерности и на их основе прогнозировать один показатель на основе множества других. Для решения этой задачи потребовалось выбрать модель, наиболее подходящую нашей задаче из библиотеки sklearn [4]. Исходя из показателей корреляции мы видим, что она высока и близка к линейной. Следовательно, надо выбрать модель регрессии. Линейная регрессия может использоваться, однако, учитывая то, что мы анализируем скорее не временной ряд, а множество показателей, то наиболее всего нам подходит метод опорных векторов, как способ обучения модели с учителем, позволяющий нивелировать количественный разброс между показателями (LinearSVR). Для оптимальной настройки показателей модели, а именно параметров регуляризации, функции потерь и количества итераций применяем метод GridSearchCV и сохраняем модель с её оптимальными показателями. Используем кросс-валидацию, чтобы положение тестовой (20%) и тренировочной выборок не были статичны.
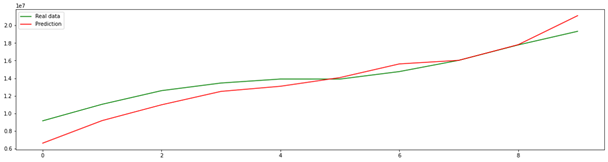
Для оценки зрелости модели оценим среднюю абсолютную ошибку и коэффициент детерминации, которые при одном из самых удачных предсказаний на тестовой выборке дают следующие показатели: MAE = 895474.7, R2 = 0.81. Таким образом, модель обладает достаточной зрелостью, однако выборка из источников данных недостаточна.
Рис. Спрогнозированные и реальные данные __________________ * Источник: составлено авторами на основе проведенных расчетов
Исходя из результатов запрограммированной модели, можно сказать, что модели машинных обучений целесообразно использовать как предиктивные модели для понимания взаимозависимости и грамотного использования экономических показателей, в целях определения плановых показателей или же оценки экономической ситуации. В настоящее время треть отечественных предприятий уже используют машинное обучение для различных целей: однако, в государственной сфере данное явление не развито на должном уровне. Этим объясняется отсутствие единого Data Lake, каналов своевременной передачи данных и уровня цифровизации общества, а также принципы организации работы государственных статистических служб, предоставляющих устаревшие данные в разрезе года, а не месяцев. Такой подход усложняет вероятность достоверного предсказания на столь большой период: предсказать наиболее успешно больше шансов один месяц на основе предыдущих 12.
Вместе с тем использование технологии HANA для интеграции потоков данных и создания соединения в реальном времени могло бы решить эту проблему. Более того, количество показателей зачастую недостаточно, что ухудшает механизм обучения машины и качество предсказания. На макроэкономическом уровне машинное обучение может использоваться для предиктивного предсказания и сравнения показателей модели на основе стабильных данных с реальными для оценки ключевых показателей эффективности. С учетом изменения уклада жизни, в связи с пандемией COVID-19, велика вероятность того, что данные, которые модель предсказала бы на 2020 год могли бы серьезно отличаться от реально сложившейся картины экономической действительности в условиях внешних вызовов. Таким образом, авторы приходят к выводу о целесообразности использования машинного обучения для прогнозных оценок экономической ситуации, как на макро, так и на микроуровнях, при указанных выше условиях и допущениях в целях определения взаимозависимости долгосрочных трендов экономического развития.
Список литературы 1. Вьюгин, В. В. Математические основы машинного обучения и прогнозирования: учебное пособие для студентов и аспирантов / В. В. Вьюгин – М., 2013 – Разд.2 Метод опорных векторов. – С. 88 –158. 2. Касперович, С. А. Прогнозирование и планирование экономики: курс лекций для студентов / С. А. Касперович. – Минск: УО «БГТУ», 2007. – 171 с. 3. Харченко, М. А. Корреляционный анализ: учебное пособие для вузов / М. А. Харченко. - Издательско-полиграфический центр ВГУ, 2008. – 30 с. 4. Библиотека для анализа и обработки данных [Электронный ресурс] - Режим доступа: https://pandas.pydata.org/ (дата обращения 13.01.2021) 5. Федеральная служба государственной статистики [Электронный ресурс] - Режим доступа: https://rosstat.gov.ru/ (дата обращения 13.01.2021) Шумаков А. Ю. Научный руководитель: Антонова В.М. МГТУ им. Н.Э.Баумана
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2021-07-18; просмотров: 49; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.225.10.116 (0.007 с.) |