Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Основные этапы проектирования баз данных
1) Концептуальное (инфологическое) проектирование – построение формализованной модели предметной области. Такая модель строится с использованием стандартных языковых средств, обычно графических, например ER-диаграмм (диаграмм «Сущность-связь»). Такая модель строится без ориентации на какую-либо конкретную СУБД. Основные элементы данной модели: · Описание объектов предметной области и связей между ними. · Описание информационных потребностей пользователей (описание основных запросов к БД). · Описание алгоритмических зависимостей между данными. · Описание ограничений целостности, т.е. требований к допустимым значениям данных и к связям между ними.
2) Логическое (даталогическое) проектирование – отображение инфологической модели на модель данных, используемую в конкретной СУБД, например на реляционную модель данных. Для реляционных СУБД даталогическая модель – набор таблиц, обычно с указанием ключевых полей, связей между таблицами. Если инфологическая модель построена в виде ER-диаграмм (или других формализованных средств), то даталогическое проектирование представляет собой построение таблиц по определённым формализованным правилам, а также нормализацию этих таблиц. Этот этап может быть в значительной степени автоматизирован. 3) Физическое проектирование – реализация даталогической модели средствами конкретной СУБД, а также выбор решений, связанных с физической средой хранения данных: выбор методов управления дисковой памятью, методов доступа к данным, методов сжатия данных и т.д. – эти задачи решаются в основном средствами СУБД и скрыты от разработчика БД. На этапе инфологического проектирования в ходе сбора информации о предметной области требуется выяснить: · основные объекты предметной области (объекты, о которых должна храниться информация в БД); · атрибуты объектов; · связи между объектами; · основные запросы к БД. Серверные базы данных. Наиболее эффективную работу с централизованной БД обеспечивает архитектура " клиент-сервер ". Централизация хранения и обработки данных является базовым принципом этой компьютерной архитектуры. На сервере сети размещается БД и устанавливается мощная серверная СУБД – сервер баз данных. Сервер БД – это программный компонент, обеспечивающий хранение больших объемов информации, ее обработку и представление пользователям в сетевом режиме.
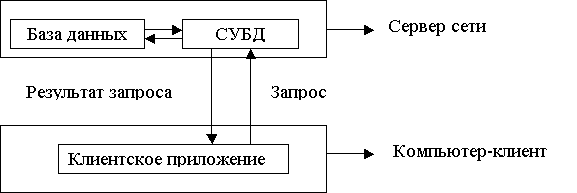
На компьютере-клиенте приложение-клиент формирует запрос к БД. Серверная СУБД обеспечивает интерпретацию запроса, его выполнение, формирование результата запроса и пересылку его по сети на клиентский компьютер. Клиентский компьютер интерпретирует его необходимым образом и представляет пользователю. Клиентское приложение может также посылать запрос на обновление БД, и серверная СУБД внесет необходимые изменения в БД. Схема архитектуры "клиент-сервер" показана на рис. 1.
Рис. 1. Архитектура "клиент-сервер"
В архитектуре "клиент-сервер" функции клиентского приложения и серверной СУБД разделены. При клиент/серверной обработке уменьшается сетевой трафик, так как через сеть передаются только результаты запросов. Груз файловых операций ложится в основном на сервер, который мощнее клиентов и поэтому способен быстрее обслуживать запросы. Как следствие этого, уменьшается потребность клиентских приложений в оперативной памяти. Поскольку серверы способны хранить большое количество данных, то на компьютерах-клиентах освобождается значительный объем дискового пространства для других приложений. Существенно повышается степень безопасности БД, так как правила целостности данных определяются в серверной СУБД и являются едиными для всех приложений, использующих эту БД. Технология клиент/сервер имеет огромный потенциал, способный повлиять на расширение возможностей прикладных программ в бизнесе. Современные серверные СУБД: · существуют в нескольких версиях для различных платформ, как правило, для различных коммерческих версий UNIX – Solaris, HP/UX и др. Многие производители также выпускают версии своих серверов баз данных для Windows NT, а в последнее время – также версии для Linux; · в подавляющем большинстве поставляются с удобными административными утилитами; · осуществляют резервное копирование данных и журналов транзакций; · поддерживают несколько сценариев репликаций (копирование информации из одной БД в несколько других). Репликации используются для разделения нагрузки между серверами в сети и многих других целей;
· позволяют параллельную обработку данных в многопроцессорных системах. Серверы, допускающие параллельную обработку, разрешают нескольким процессорам обращаться к одной БД, что обеспечивает высокую скорость обработки транзакций; ● поддерживают создание хранилищ данных и OLAP. Хранилище данных – это совокупность данных, полученных прямо или косвенно из информационных систем, которые содержат текущую и деловую информацию, а также из некоторых внешних источников. OLAP (On Line Analytical Processing) – это технология построения многомерных хранилищ данных, являющихся результатом обработки набора данных, нередко состоящего из нескольких таблиц. Такие хранилища данных в последнее время широко используются в системах поддержки принятия решений; ● выполняют распределенные запросы и транзакции (т.к. наличие нескольких серверов баз данных в одной организации стало обычным явлением). Эти возможности поддерживаются почти всеми серверными СУБД; ● дают возможность использовать различные средства проектирования схем данных – универсальные или ориентированные на конкретную СУБД; ● имеют средства разработки клиентских приложений и генераторы отчетов; ● поддерживают как минимум публикацию баз данных в Internet; ● обладают широкими возможностями управления пользовательскими привилегиями и правами доступа к различным объектам БД. На рынке СУБД лидируют серверные СУБД, сведения о производителях которых приведены ниже в соответствии с рис.2:
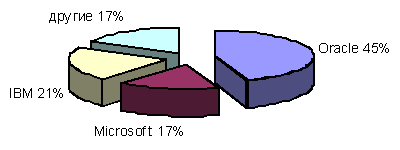
Рис.2 Сведения о производителях серверных СУБД Основными производителями таких систем обработки и хранения данных являются 3 корпорации: Oracle, Microsoft и IBM. Диаграмма соотношения объемов продаж соответствующих систем (источник: https://tagline.ru/database-management-systems-rating/ 2016) приводится на рис. 3.
Наиболее распространенными клиент-серверными системами здесь соответственно являются системы Oracle (разработчик компания Oracle), MS SQL Server (разработчик компания Microsoft), DB2, Informix Dynamic Server (компания IBM).
|
||||||||||||||||||
|
|
Последнее изменение этой страницы: 2021-05-12; просмотров: 214; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.145.163.58 (0.007 с.) |