Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Модели данных, используемые для построения хранилищ
Задачи, решаемые аналитическими системами, существенн различаются, поэтому их БД тоже построены на разных приич пах. Критерием эффективности для таких систем обычно я ется скорость выполнения сложных запросов и прозрачно структуры хранения информации для пользователей. Многомерный OLAP (MOLAP). В специализированных СУБД, иных на многомерном представлении данных, данные организованы не в форме реляционных таблиц, а в виде упорядоченных многомерных массивов: • гиперкубов (все хранимые в БД ячейки должны иметь одинаковую мерность, т. е. находиться в максимально полном базисе измерений); • поликубов (каждая переменная хранится с собственным набором измерений, и все связанные с этим сложности обработки перекладываются на внутренние механизмы системы). Использование многомерных БД в системах оперативной аналитической обработки имеет следующие достоинства. В случае использования многомерных СУБД поиск и выборка данных осуществляются значительно быстрее, чем при многомерном концептуальном взгляде на реляционную базу данных, так как многомерная база данных содержит заранее агрегированные показатели и обеспечивает оптимизированный доступ к запрашиваемым ячейкам. Многомерные СУБД легко справляются с задачами включения в информационную модель разнообразных встроенных функций, тогда как объективно существующие ограничения языка SQL делают выполнение этих задач на основе реляционных СУБД достаточно сложным, а иногда и невозможным. С другой стороны, имеются существенные ограничения: • многомерные СУБД не позволяют работать с большими объемами данных. К тому же за счет денормализации и предварительно выполненной агрегации объем данных в многомерной базе, как правило, соответствует в 2,5—100 раз меньшему объему исходных детализированных данных; • многомерные СУБД по сравнению с реляционными очень неэффективно используют внешнюю память, о подавляющем большинстве случаев информационный гиперкуб является сильно разреженным, а поскольку данные хранятся в упорядоченном виде, неопределенные значения удается удалить только за счет выбора оптимального порядка сортировки, позволяющего организовать данные в аксимально большие непрерывные группы. Но даже в том случае проблема решается только частично.
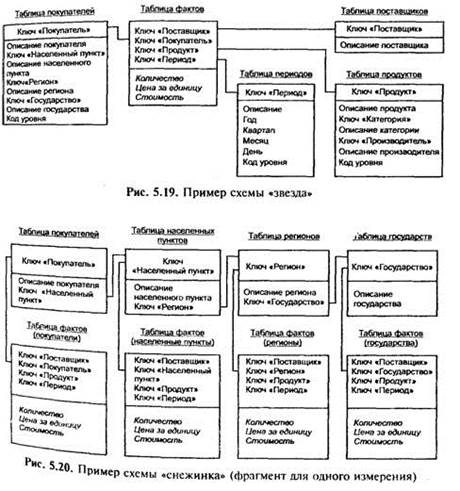
Следовательно, использование многомерных СУБД оправдано только при следующих условиях: • объем исходных данных для анализа не слишком велик более нескольких гигабайт), т. е. уровень агрегации данн достаточно высок; • набор информационных измерений стабилен (посколь любое изменение в их структуре почти всегда требует полной перестройки гиперкуба); • время ответа системы на нерегламентированные запроск является наиболее критичным параметром; • требуется широкое использование сложных встроенных функций для выполнения кроссмерных вычислений над ячейками гиперкуба, в том числе возможность написания пользовательских функций. Реляционный OLAP (ROLAP). Непосредственное использование реляционных БД в системах оперативной аналитической обработки имеет следующие достоинства. В большинстве случаев корпоративные хранилища данных реализуются средствами реляционных СУБД, и инструменты ROLAP позволяют производить анализ непосредственно над ними. При этом размер хранилища не является таким критичным параметром, как в случае MOLAP. В случае переменной размерности задачи, когда изменения в структуру измерений приходится вносить достаточно часто, ROLAP-системы с динамическим представлением размерности являются оптимальным решением, так как в них такие модификации не требуют физической реорганизации БД. Реляционные СУБД обеспечивают значительно более высокий уровень защиты данных и хорошие возможности разграничения прав доступа. Главный недостаток ROLAP по сравнению с многомерными СУБД — меньшая производительность. Для обеспечения производительности, сравнимой с MOLAP, реляционные системы требуют тщательной проработки схемы базы данных и настроик индексов, т. е. больших усилий со стороны администраторов БД. Только при использовании звездообразных схем производитель ность хорошо настроенных реляционных систем может приближена к производительности систем на основе много ных баз данных. Идея схемы звезды (star schema) заключается в том, имеются таблицы для каждого измерения, а все факты помеодну таблицу, индексируемую множественным ключом, составленным из ключей отдельных измерений (рис. 5.19). Каждый луч схемы звезды задает (в терминологии Кодда) направление консолидации данных по соответствующему измерению.
В сложных задачах с многоуровневыми измерениями имеет мысл обратиться к расширениям схемы звезды — схеме созвездия (fact constellation schema) и схеме снежинки (snowflake schema). В этих случаях отдельные таблицы фактов создаются для возможных сочетаний уровней обобщения различных измерений (рис. 5.20). Это позволяет добиться лучшей производительности, но часто приводит к избыточности данных и к значительным усложнениям в структуре базы данных, в которой оказывается огромное количество таблиц фактов.
В любом случае, если многомерная модель реализуете виде реляционной базы данных, следует создавать длинные В «узкие» таблицы фактов и сравнительно небольшие и «широки И таблицы измерений. Таблицы фактов содержат численные значения ячеек гиперкуба, а остальные таблицы определяют содержащий их многомерный базис измерений. Часть информации можно получать с помощью динамической агрегации данных распределенных по незвездообразным нормализованным структурам, хотя при этом следует помнить, что включающие агрегацию запросы при высоконормализованной структуре БД могут выполняться довольно медленно. Ориентация на представление многомерной информации с помощью звездообразных реляционных моделей позволяет избавиться от проблемы оптимизации хранения разреженных матриц, остро стоящей перед многомерными СУБД (где проблема разреженности решается специальным выбором схемы). Хотя для хранения каждой ячейки используется целая запись, которая помимо самих значений включает вторичные ключи, — ссылки на таблицы измерений, несуществующие значения просто не включаются в таблицу фактов. Возможны гибридные системы (Hybrid OLAP — HOLAP), цель которых — совмещение достоинств и минимизация недостатков, присущих предыдущим классам. Архитектуры хранилищ данных Виртуальное хранилище данных. В его основе — репозитории метаданных, которые описывают источники информации (БД транзакционных систем, внешние файлы и др.), SQL-запросы для их считывания и процедуры обработки и предоставления информации. Непосредственный доступ к последним обеспеч вает ПО промежуточного слоя. В этом случае избыточной данных нулевая. Конечные пользователи фактически работают транзакционными системами напрямую со всеми вытекаюши отсюда плюсами (доступ к «живым» данным в реальном времени) и минусами (интенсивный сетевой трафик, снижение производительности OLTP-систем и реальная угроза их работоспособности вследствие неудачных действий пользователей-аналитиков) Витрина данных. Витрина данных (Data Mart) — это набор тематически связанных баз данных, которые содержат информацию, относящуюся к отдельным аспектам предметной области (рис. 5 21). По сути дела, витрина данных — это облегченный вариант хранилища данных, содержащий только тематически объединенные данные. Витрина данных существенно меньше по объему, чем корпоративное хранилище данных, и для его реализации не требуется особо мощная вычислительная техника.
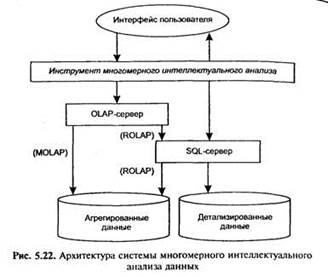
Глобалъное хранилище данных. Все более популярной становится идея совместить концепции хранилища и витрины данных в одной реализации и использовать хранилище данных в качестве единственного источника интегрированных данных для всех витрин данных. Тогда естественной становится такая трехуровневая архитектура системы (рис. 5.22):
• сфера детализированных данных. Это область действия большинства систем, нацеленных на поиск информации.
В большинстве случаев реляционные СУБД отлично справляются с возникающими здесь задачами. Общепризнанным стандартом языка манипулирования реляционными данными является SQL. Информационно-поисковые системы, обеспечивающие интерфейс конечного пользователя в задачах поиска детализированной информации, могут использоваться в качестве надстроек как над отдельными базами данных транзакционных систем, так и над общим хранилищем данных; • сфера агрегированных показателей. Комплексный взгляд на собранную в хранилище данных информацию, ее обобщение и агрегация, гиперкубическое предста ление и многомерный анализ являются задачами систем оперативной аналитической обработки данных (OLA Р). Здесь можно или ориентироваться на специальные мно мерные СУБД, или оставаться в рамках реляционных т нологий. Во втором случае заранее агрегированные дан могут собираться в БД звездообразного вида либо агрегация информации может производиться на лету в процессе сканирования детализированных таблиц реляционной • сфера закономерностей. Интеллектуальная обработка производится методами интеллектуального анализа данных (ИАД, Data Mining), главными задачами которых являются поиск функциональных и логических закономерностей в накопленной информации, построение моделей и правил, которые объясняют найденные аномалии и/или прогнозируют развитие некоторых процессов. Метаданные должны содержать описание структур данных хранилища, структур данных, импортируемых из разных источников, сведения о периодичности импортирования, методах загрузки и обобщения данных, средствах доступа и правилах представления информации, оценки приблизительных затрат времени на получение ответа на запрос. Доставка данных в хранилище. Данные должны поступать в хранилище в нужном формате и с требуемой регулярностью. Как правило, составляется расписание пополнения хранилища, в соответствии с которым специальные программы организуют передачу данных на склад и их первичную обработку. Передача данных на склад может также осуществляться при возникновении заранее определенных внешних событий.
Процесс загрузки данных обычно подразумевает решение следующих задач: • приведение данных к единому формату (унификация типов данных и их представления, исключение управляющих кодов); • предобработка данных (исключение дубликатов, устранение ошибочных значений, восстановление пропущенных значений); • агрегирование данных (вычисление обобщенных статистических показателей). Ингеграция OLAP и ИАД Оперативная аналитическая обработка и интеллектуальный пяти данных – две составные части процесса поддержки принятия решений. Однако большинство систем OLAP заостряет внимание только на обеспечении доступа к многомерным данным, а большинство средств ИАД, работающих в сфере закономерностей, имеют дело с одномерными перспективами данных. Эти анализа должны быть тесно объединены, т. е. системы ОLAP должны фокусироваться не только на доступе на поиске закономерностей (рис. 5.22). Как заметил N. Raden, «многие компании создали... прекрасные хранилища данных, идеально разложив по полочкам горы неиспользуемой информации, которая сама по себе не обеспечивает ни быстрой, ни достаточно грамотной реакции на рыночные события». В последнее время появилось обобщенное понятие «OLAP Data Mining» (многомерный интеллектуальный анализ) или «OLAP Mining» для обозначения такого объединения, причем определились несколько вариантов интеграции двух технологий: • cubing then mining. Возможность выполнения интеллектуального анализа должна обеспечиваться над любым результатом запроса к многомерному концептуальному представлению, т. е. над любым фрагментом любой проекции гиперкуба показателей; • mining then cubing. Подобно данным, извлеченным из хранилища, результаты интеллектуального анализа должны представляться в гиперкубической форме для последующего многомерного анализа; • cubing while mining. Этот гибкий способ интеграции позволяет автоматически активизировать однотипные механизмы интеллектуальной обработки над результатом каждого шага многомерного анализа (перехода между уровнями обобщения, извлечения нового фрагмента гиперкуба и т. д.). К сожалению, очень немногие производители предоставляют сегодня достаточно мощные средства интеллектуального анализа многомерных данных в рамках систем OLAP. Проблема также заключается в том, что некоторые методы ИАД (байесовские сети, метод k -ближайшего соседа) неприменимы для задач многомерного интеллектуального анализа, так как основаны на определении сходства детализированных примеров и не способны работать с агрегированными данными. Контрольные вопросы 1. Перечислите функции файловых систем. 2. Какова общая организация ФС NTFS? 3. Какие атрибуты файлов вам известны? 4. Охарактеризуйте разновидности размещения файлов в NTFS. 5 Каким образом осуществляется сжатие данных в NTFS? 6. Дайте определение понятия «База данных».
7. Перечислите преимущества и недостатки использования баз данных. 8. Определите основные функции и назначение СУБД. 9. Дайте основные характеристики моделей данных. 10. Что такое реляционное исчисление? 11. Перечислите основные компоненты логической и физической структуры БД. 12. Что такое транзакции? 13. Назовите отличительные особенности использования баз данных в ИС. 14. Перечислите основные требования, предъявляемые к базам данных. 15. Определите назначение и организацию инвертированного списка. 16. В чем заключается страничная организация данных? 17. Что такое хранилища данных? 18. Перечислите основные свойства OLAP-технологий. 19. В чем различие ROLAP и MOLAP? Глава 6 СЕТЕВЫЕ ИНФОРМАЦИОННЫЕ ТЕХНОЛОГИИ. INTERNET В исторической перспективе, с появлением в первой половине 1970-х гг. видеотерминалов, первоначально возникли структуры «терминал — хост» (локальный или удаленный). Чуть раньше и независимо развивались глобальные сети (пакетной коммутации), используемые как для функций связи общего назначения, так и для коммуникаций «хост—хост» с целью (в то время) выравнивания использования вычислительных мощностей по часовым поясам (подобно тому, как это осуществляется в сетях энергопередачи). Это были именно вычислительные сети. Структуры «терминал — хост» вносят сюда дополнительную динамику. Эта ситуация сохраняется до середины 1980-х гг., когда появление и взрывообразное распространение ПК (как выразился один из тогдашних научных острословов «карлики-млекопитающие на планете вычислительных динозавров») изменило положение. Появляются локальные сети, интегрирующие прежде всего информационные ресурсы (файл-сервер), редкие или дорогостоящие технические средства (принт-сервер) и т. п. Изучение трафика (потоков данных) в развивающихся сетях показало смещение акцентов с распределенных вычислений на обмен информацией — доступ к удаленным базам данных, о мен сообщениями по электронной почте и пр. Вырисовываются, таким образом, информационные сети. Наконец, в 1980—1990-е гг. широко распространяется технология TCP/IP, обеспечивая рост и развитие «сети сетей» Internet, которая представляет собой глобальную информационно-вычислительную сеть. 6.1 Некоторые основные понятия Системы терминал—хост Первые системы совместной эксплуатации информационных вычислительных ресурсов (системы коллективного пользования) появляются в 1960—1970-е гг. и относятся к вычислительным системам с разделением времени. Первоначально операционные системы ЭВМ (ОС) были рассчитаны на пакетную обработку информации, затем с созданием интерактивных терминальных устройств появляется возможность совместной работы пользователей в реальном масштабе времени. Основные этапы развития систем доступа к информационным ресурсам представлены на рис. 6.1 и включают следующие схемы. 1. Взаимодействие терминала (конечный пользователь, источник запросов и заданий) и хоста (центральная ЭВМ, держатель всех информационных и вычислительных ресурсов) — рис. 6.1 а, б. Может осуществляться как в локальном, так и в удаленном режиме, во втором случае, как правило, некоторая совокупность пользователей (дисплейный класс) размещается в так называемом абонентском пункте — комплексе, снабженном котроллером (устройством управления), принтером, концентратором и обеспечивающим параллельную работу пользователей удаленным хостом. Связь между хостом и абонентским пунктом в этом случае осуществлялась с помощью модемов, по телефонным каналам [26].
2. На следующем этапе (рис. 6.1, в) формируются сети передачи данных (из существующих общих и специальных цифровых каналов), позволяющие как осуществлять более тесное взаимодействие терминал—хост, так и обмен хост—хост для реализации распределенных баз данных и децентрализации процессов обработки информации. 3. Появление и массовое распространение персональных компьютеров выводит на первый план (для массового пользователя) проблему связи ПК— ПК (рис. 6.1, г) для быстрого резервирования и копирования информации (в том числе с использованием модемов) и локальные сети (рис. 6.1, д) — для совместной эксплуатации баз данных (файл—сервер) и дорогостоящего оборудования. В дальнейшем локальные сети потеряли самостоятельное значение вследствие интеграции с глобальными в двухуровневые сети, строящиеся по единому принципу в рамках Internet (рис. 6.1, е). В последующем перечисленные конфигурации не претерпели существенных изменений, однако понятия хост и терминал из чисто аппаратурных трансформировались в аппаратурно-программные и даже сугубо программные (например, эмуляторы терминала и эмуляторы хоста на однотипных ПК [23, 26]). Кроме того, в 80-е гг. в обиход входит понятие интеллектуального терминала (smart terminal) — сателлитной машины, которая берет на себя часть функций по обработке информации пользователя (например, синтаксический анализ запроса или программы). Системы клиент—сервер Таким образом, по мере развития представлений о распределенных вычислительных процессах и процессах обработки данных складывается концепция архитектуры «клиент — сервер» обобщенное представление о взаимодействие двух компонент информационной технологии (технического и/или программного обеспечения) в вычислительных системах и сетях, и которых логически или физически могут быть выделены: • активная сторона (источник запросов, клиент); • пассивная сторона (сервер, обслуживание запросов, источник ответов). Взаимодействие клиент—сервер в сети осуществляется в соответствии с определенным стандартом, или протоколом — совокупностью соглашений об установлении/прекращении связи и обмене информацией. Обычно клиент и сервер работают в рамках единого протокола – telnet, ftp, gopher, http и пр., однако в связи с недостаточностью такого подхода появляются мультипротокольные клиенты и серверы, например браузер Netscape Navigator. Основные разновидности функциональных структур клиент—сервер рассмотрены в следующей главе.
|
|||||||||
|
|
Последнее изменение этой страницы: 2021-04-05; просмотров: 150; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.15.237.255 (0.047 с.) |