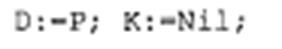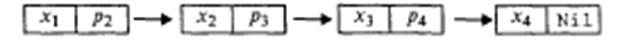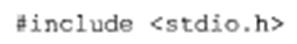Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Тема 2.9 Указатели и динамическая память.
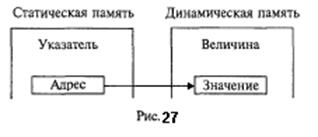
До сих пор мы рассматривали программирование, связанное с обработкой только статических данных. Статическими называются такие величины, память под которые выделяется во время компиляции и сохраняется в течение всей работы программы. В Паскале существует и другой способ выделения памяти под данные, который называется динамическим. В этом случае память под величины отводится во время выполнения программы. Такие величины будем называть динамическими. Раздел оперативной памяти, распределяемый статически, называется статической памятью; динамически распределяемый раздел памяти называется динамической памятью. Использование динамических величин предоставляет программисту ряд дополнительных возможностей. Во-первых, подключение динамической памяти позволяет увеличить объем обрабатываемых данных. Во-вторых, если потребность в каких-то данных отпала до окончания программы, то занятую ими память можно освободить для другой информации. Втретьих, использование динамической памяти позволяет создавать структуры данных переменного размера. Работа с динамическими величинами связана с использованием еще одного типа данных — ссылочного. Величины, имеющие ссылочный тип, называют указателями. Указатель содержит адрес поля в динамической памяти, хранящего величину определенного типа. Сам указатель располагается в статической памяти (рис. 27).
Адрес величины — это номер первого байта поля памяти, в котором располагается величина. Размер поля однозначно определяется типом. Величина ссылочного типа (указатель) описывается в разделе описания переменных следующим образом: Var <идентификатор>:<ссылочный тип> В стандарте Паскаля каждый указатель может ссылаться на величину только одного определенного типа, который называется базовым для указателя. Имя базового типа и указывается в описании в следующей форме: <ссылочный тип>:= А <имя типа> Вот примеры описания указателей:
Здесь Pi — указатель на динамическую величину целого типа; Р2 — указатель на динамическую величину символьного типа; РМ — указатель на динамический массив, тип которого задан в разделе Туре. Сами динамические величины не требуют описания в программе, поскольку во время компиляции память под них не выделяется. Во время компиляции память вьщеляется только под статические величины. Указатели — это статические величины, поэтому они требуют описания. Каким же образом происходит выделение памяти под динамическую величину? Память под динамическую величину, связанную с указателем, вьщеляется в результате выполнения стандартной процедуры NEW. Формат обращения к этой процедуре выглядит так:
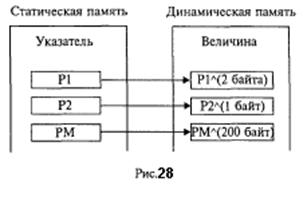
NEW(<указатель>); Считается, что после выполнения этого оператора создана динамическая величина, имя которой имеет следующий вид: <имя динамической величины>::=<указатель> л. Пусть в программе, в которой имеется приведенное выше описание, присутствуют операторы NEW(Pl); NEW(P2); NEW(PM); После их выполнения в динамической памяти оказывается выделенным место под три величины (две скалярные и один массив), которые имеют идентификаторы Р1^, Р2^, РМ^.
Например, обозначение Р1^ можно расшифровать так: динмическая переменная, на которую ссылается указатель Р1. На схеме, представленной на рис. 28, показана связь между динамическими величинами и их указателями.
Дальнейшая работа с динамическими переменными происходит точно так же, как со статическими переменными соответствующих типов. Им можно присваивать значения, их можно использовать в качестве операндов в выражениях, параметров подпрограмм и т.п. Например, если переменной Р1^ нужно присвоить значение 25, переменной Р2 ^ присвоить значение символа ' W, а массив РМ ^ заполнить по порядку целыми числами от 1 до 100, то это делается так:
Кроме процедуры NEW значение указателя может определяться оператором присваивания: <указатель>:=<ссылочное выражение>; В качестве ссылочного выражения можно использовать: • указатель; • ссылочную функцию (т. е. функцию, значением которой является указатель); • константу Nil. Nil — это зарезервированная константа, обозначающая пустую ссылку, т.е. ссылку, которая ни на что не указывает. При присваивании базовые типы указателя и ссылочного выражения должны быть одинаковыми. Константу Nil можно присваивать указателю с любым базовым типом.
До присваивания значения ссылочной переменной (с помощью оператора присваивания или процедуры NEW) она является неопределенной. Ввод и вывод указателей не допускается. Рассмотрим пример. Пусть в программе описаны следующие указатели:
Тогда допустимыми являются операторы присваивания
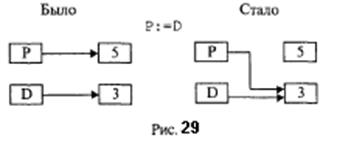
поскольку соблюдается принцип соответствия типов. Оператор к: =D ошибочен, так как базовые типы у правой и левой части разные. Если динамическая величина теряет свой указатель, то она становится «мусором». В программировании под этим словом понимают информацию, которая занимает память, но уже не нужна. Представьте себе, что в программе, в которой присутствуют описанные выше указатели, в разделе операторов записано следующее:
Таким образом, динамическая величина, равная 5, потеряла свой указатель и стала недоступной. Однако место в памяти она занимает. Это и есть пример возникновения «мусора». На схеме, представленной на рис. 29, показано, что произошло в результате выполнения оператора p: =D.
В Паскале имеется стандартная процедура, позволяющая освобождать память отданных, потребность в которых отпала. Ее формат: DISPOSE(<указатель>); Например, если динамическая переменная Р^ больше не нужна, то оператор DISPOSE(P) удалит ее из памяти. После этого значение указателя Р становится неопределенным. Особенно существенным становится эффект экономии памяти при удалении больших массивов. В версиях Турбо Паскаля, работающих под управлением операционной системы MS DOS, под данные одной программы выделяется 64 килобайта памяти. Это и есть статическая область памяти. При необходимости работать с большими массивами информации этого может оказаться мало. Размер динамической памяти намного больше (сотни килобайт). Поэтому использование динамической памяти позволяет существенно увеличить объем обрабатываемой информации. Следует отчетливо понимать, что работа с динамическими данными замедляет выполнение программы, поскольку доступ к величине происходит в два шага: сначала ищется указатель, затем по нему — величина. Как это часто бывает, действует «закон со хранения неприятностей»: выигрыш в памяти компенсируется проигрышем во времени. Пример 1. Создать вещественный массив из 10000 чисел, заполнить его случайными числами в диапазоне от 0 до 1. Вычислить среднее значение массива. Очистить динамическую память. Создать целый массив размером 10 000, заполнить его случайными целыми числами в диапазоне от -100 до 100 и вычислить его среднее значение.
Связанные списки. Обсудим вопрос о том, как в динамической памяти можно создать структуру данных переменного размера. Разберем следующий пример. В процессе физического эксперимента многократно снимаются показания прибора (допустим, термометра) и записываются в компьютерную память для дальнейшей обработки. Заранее неизвестно, сколько измерений будет произведено. Если для обработки таких данных не использовать внешнюю память (файлы), то разумно расположить их в динамической памяти. Вопервых, динамическая память позволяет хранить больший объем информации, чем статическая. А во-вторых, в динамической памяти эти числа можно организовать в связанный список, который не требует предварительного указания количества чисел, подобно массиву. Что же такое связанный список? Схематически он выглядит так:
Каждый элемент списка состоит из двух частей: информационной части (х,, х 2 и т.д.) и указателя на следующий элемент списка (р 2, р г и т.д.). Последний элемент имеет пустой указатель Nil. Связанный список такого типа называется однонаправленной цепочкой. Для сформулированной выше задачи информационная часть представляет набор вещественных чисел: х х — результат первого измерения, х 2 — результат второго измерения и т.д., х, — результат последнего измерения. Связанный список обладает тем замечательным свойством, что его можно дополнять по мере поступления новой информации. Добавление происходит путем присоединения нового элемента к концу списка. Значение Nil в последнем элементе заменяется ссылкой на новый элемент цепочки:
Связанный список не занимает лишней памяти. Память расходуется в том объеме, который требуется для поступившей информации. В программе для представления элементов цепочки используется комбинированный тип (запись). Для нашего примера тип та кого элемента может быть следующим: Туре Ре= Л Е1ет; Elem = Record Т: Real; Р: Ре End; Здесь Ре — ссылочный тип на переменную типа Elem. Этим именем обозначен комбинированный тип, состоящий из двух полей: т — вещественная величина, хранящая температуру, р — указатель на динамическую величину типа Elem. В таком описании нарушен один из основных принципов Пас каля, согласно которому на любой программный объект можно ссылаться только после его описания. В самом деле, тип Ре определяется через тип Elem, а тот, в свою очередь, определяется через тип Ре. Однако в Паскале допускается единственное исключение из этого правила, связанное со ссылочным типом. Приведенный фрагмент программы является правильным. Пример 2. Рассмотрим программу формирования связанного списка в ходе ввода данных.
Здесь ссылочная переменная Beg используется для сохранения адреса начала цепочки. Всякая обработка цепочки начинается с ее первого элемента. В программе показано, как происходит продвижение по цепочке при ее обработке (в данном примере — распечатке информационной части списка по порядку). Однонаправленная цепочка — простейший вариант связанного списка. В практике программирования используются двунаправленные цепочки (когда каждый элемент хранит указатель на следующий и на предыдущий элементы списка), а также двоичные деревья. Подобные структуры данных называются динамическими структурами. Пример 3. Задача о стеке. Одной из часто употребляемых в программировании динамических структур данных является стек. Стек — это связанная цепочка, начало которой называется вер шиной. Состав элементов постоянно меняется. Каждый вновь по ступающий элемент размещается в вершине стека. Удаление элементов из стека также производится с вершины. Стек подобен детской пирамидке, в которой на стержень надеваются кольца. Всякое новое кольцо оказывается на вершине пирамиды. Снимать кольца можно только сверху. Принцип изменения содержания стека часто формулируют так: «Последним пришел — первым вышел». Составим процедуры добавления элемента в стек (INSTEK) И исключения элемента из стека (OUTSTEK). При этом будем считать, что элементы стека — символьные величины. В процедурах используется тип Ре, который должен быть глобально объявлен в основной программе.
В процедуре INSTEK аргументом является параметр Sim, содержащий включаемый в стек символ. Ссылочная переменная Beg содержит указатель на вершину стека при входе в процедуру и при выходе из нее. Следовательно, этот параметр является и аргументом, и результатом процедуры. В случае, когда стек пустой, указатель Beg равен Nil.
В процедуре OUTSTEK параметр Beg играет ту же роль, что и в предыдущей процедуре. После удаления последнего символа его значение станет равным Nil. Ясно, что если стек пустой, то удалять из него нечего. Логический параметр Flag позволяет распознать этот случай. Если на выходе из процедуры Flag=True, то, значит, удаление произошло; если Flag=False, значит, стек был пуст и ничего не изменилось. Процедура не оставляет после себя «мусора», освобождая па мять из-под удаленных элементов.
Тема 2.10 Модули.
Стандартный Паскаль не располагает средствами разработки и поддержки библиотек программиста (в отличие, скажем, от Фортрана и других языков программирования высокого уровня), которые компилируются отдельно и в дальнейшем могут быть использованы не только самим разработчиком. Если программист имеет достаточно большие наработки и те или иные подпрограммы могут быть использованы при написании новых приложений, то приходится эти подпрограммы целиком включать в новый текст. В Турбо Паскале это ограничение преодолевается за счет, во-первых, введения внешних подпрограмм, во-вторых, разработки и использования модулей. В данном разделе мы рассмотрим оба способа. Организация внешних подпрограмм. Начнем с внешних подпрограмм. В этом случае исходный текст каждой процедуры или функции хранится в отдельном файле и при необходимости с помощью специальной директивы компилятора включается в текст создаваемой программы.
Проиллюстрируем этот прием на примере задачи целочисленной арифметики. Условие задачи: дано натуральное число п. Найти сумму первой и последней цифр этого числа. Для решения будет использована функция, вычисляющая количество цифр в записи натурального числа. Вот ее возможный вариант:
Сохраним этот текст в файле с расширением inc (это расширение внешних подпрограмм в Турбо Паскале), например digits.inc. Опишем еще одну функцию: возведение натурального числа в натуральную степень (а").
А теперь составим основную программу, решающую поставленную задачу. В ней будут использованы описанные выше функции
{$l <имя файла>} — это директива компилятора (псевдо комментарий), позволяющая в данное место текста программы вставить содержимое файла с указанным именем. Файлы с расширением inc можно накапливать на магнитном диске, формируя таким образом личную библиотеку подпрограмм. Внешние процедуры создаются и внедряются в использующие их программы точно так же, как и функции в рассмотренном примере. Создание и использование модулей. Далее речь пойдет о модулях: их структуре, разработке, компиляции и использовании. Модуль — это набор ресурсов (функций, процедур, констант, переменных, типов и т.д.), разрабатываемых и хранимых независимо от использующих их программ. В отличие от внешних подпрограмм модуль может содержать достаточно большой набор процедур и функций, а также других ресурсов для разработки программ. В основе идеи модульности лежат принципы структурного программирования. Существуют стандартные модули Турбо Паскаля (SYSTEM, CRT, GRAPH и т.д.), справочная информация по которым дана в приложении. Модуль имеет следующую структуру:
После служебного слова Unit записывается имя модуля, которое (для удобства дальнейших действий) должно совпадать с именем файла, содержащего данный модуль. Поэтому (как принято в MS DOS) имя не должно содержать более 8 символов. В разделе interface объявляются все ресурсы, которые будут в дальнейшем доступны программисту при подключении модуля. Для подпрограмм здесь лишь указывается полный заголовок. В разделе implementation описываются все подпрограммы, которые были ранее объявлены. Кроме того, в нем могут содержаться свои константы, переменные, типы, подпрограммы и т.д., которые носят вспомогательный характер и используются для написания основных подпрограмм. В отличие от ресурсов, объявленных в разделе interface, все, что дополнительно объявляется в Implementation, уже не будет доступно при подключении модуля. При описании основной подпрограммы достаточно указать ее имя (т.е. не требуется полностью переписывать весь заголовок), а затем записать тело подпрограммы. Наконец, раздел инициализации (часто отсутствующий) содержит операторы, которые должны быть выполнены сразу же после запуска программы, использующей модуль. Приведем пример разработки и использования модуля. Поскольку рассмотренная ниже задача достаточно элементарна, ограничимся распечаткой текста программы с подробными комментариями. Рассмотрим следующую задачу. Реализовать в виде модуля на бор подпрограмм для выполнения следующих операций над обыкновенными дробями вида P/Q (Р — целое, Q — натуральное): 1) сложение; 2) вычитание; 3) умножение; 4) деление; 5) сокращение дроби; 6) возведение дроби в степень N (N — натуральное); 7) функции, реализующие операции отношения (равно, не равно, больше или равно, меньше или равно, больше, меньше). Дробь представить следующим типом:
Используя этот модуль, решить задачи: 1. Дан массив А, элементы которого — обыкновенные дроби. Найти сумму всех элементов и их среднее арифметическое; результаты представить в виде несократимых дробей. 2. Дан массив А, элементы которого — обыкновенные дроби. Отсортировать его в порядке возрастания.
При разработке модуля рекомендуется такая последовательность действий: 1. Спроектировать модуль, т.е. определить основные и вспомогательные подпрограммы и другие ресурсы. 2. Описать компоненты модуля. 3. Каждую подпрограмму целесообразно отладить отдельно, после чего «вклеить» в текст модуля. Сохраним текст разработанной программы в файле DROBY. PAS и откомпилируем наш модуль. Для этого можно воспользоваться внешним компилятором, поставляемым вместе с Турбо Паскалем. Команда будет выглядеть так: ТРС DROBY. PAS. Если в тексте нет синтаксических ошибок, получим файл DROBY.три, иначе будет выведено соответствующее сообщение с указанием строки, содержащей ошибку. Другой вариант компиляции: в меню системы программирования Турбо Паскаль выбрать Compile/Destination Disk, затем — Compile/Build. Теперь можно подключить модуль к программе, где планируется его использование. Решим первую задачу — выполним суммирование массива дробей.
Вторую задачу читателю предлагается решить самостоятельно. Как видно из примера, для подключения модуля используется служебное слово Uses, после которого указывается имя модуля. Данная строка записывается сразу же после заголовка программы. Если необходимо подключить несколько модулей, они перечисляются через запятую. При использовании ресурсов модуля программисту совсем не обязательно иметь представление о том, как работают вызываемые подпрограммы. Достаточно знать назначение подпрограмм и их спецификации, т.е. имена и параметры. По такому принципу осуществляется работа со всеми стандартными модулями. Поэтому если программист разрабатывает модули не только для личного пользования, ему необходимо выполнить полное описание всех доступных при подключении ресурсов.
Раздел 3. Программирование на языке С++. Тема 3.1 Лексика языка С++.
История языка программирования C++. Вторым языком программирования, который предлагается для изучения в данном пособии, является язык Си (в английском варианте его название обозначается одной заглавной буквой латинского алфавита — С). Язык Си был создан в 1972 г. сотрудником фирмы Bell Laboratories в США Денисом Ритчи. По замыслу автора, язык Си должен был обладать противоречивыми свойствами. С одной стороны, это язык программирования высокого уровня, поддерживающий методику структурного программирования (подобно Паскалю). С другой стороны, этот язык должен обеспечивать возможность создавать такие системные программы, как компиляторы и операционные системы. До появления Си подобные программы писались исключительно на языках низкого уровня — Ассемблерах, Автокодах. Первым системным программным продуктом, разработанным с помощью Си, стала операционная система UNIX. Из-за упомянутой выше двойственности свойств нередко в литературе язык Си называют языком среднего уровня. Стандарт Си был утвержден в 1983 г. Американским национальным институтом стандартов (ANSI) и получил название ANSI С. В начале 1980-х гг. в той же фирме Bell Laboratories ее сотрудни ком Бьерном Строуструпом было разработано расширение языка Си, предназначенное для объектно-ориентированного программирования. По сути дела, был создан новый язык, первоначально названный «Си с классами», а позднее (в 1983 г.) получивший название Си++ (Си-плюс-плюс). Язык Си++ принято считать языком объектно-ориентированного программирования. Однако этот язык как подмножество включает в себя Си и попрежнему сохраняет свойства языка для системного программирования. Все существующие версии трансляторов для Си++ поддерживают стандарт ANSI С. Из сказанного выше следует, что язык Си++ поддерживает как процедурную, так и объектно-ориентированную парадигмы программирования. Последующий материал пособия в большей степени посвящен процедурному программированию на Си++ и лишь в приводится краткое введение в ООП на Си++,. Примеры программ. Для того чтобы получить первоначальное представление о программировании на Си/Си++, рассмотрим несколько примеров. В литературе по программированию стало традицией приводить в качестве примера первой программы на Си следующий текст.
Здесь первая строка представляет собой комментарий. Начало и конец комментария ограничиваются парами символов /* и */ Все, что расположено между этими символами, компилятор игнорирует. Вторая строка программы содержит директиву препроцессора:
Она сообщает компилятору информацию о необходимости подключить к тексту программы содержимое файла stdio. h, в котором находится описание (прототип) библиотечной функции printf () — функции вывода на экран. Вся последующая часть программы называется блоком описания главной функции. Она начинается с заголовка главной функции: void main () Любая программа на Си обязательно содержит главную функцию, имя которой — main. Слово void обозначает то, что главная функция не возвращает никаких значений в результате своего выполнения, а пустые скобки обозначают отсутствие аргументов. Тело главной функции заключается между парой фигурных скобок, следующих после заголовка. Текст программы содержит всего лишь один исполняемый оператор — это оператор вывода на экран. Вывод осуществляется путем обращения к стандартной библиотечной функции printf (). В результате его выполнения на экран выведется текст: Здравствуй, Мир! Впереди данной строки и после нее будет пропущено по одной пустой строке, что обеспечивается наличием управляющих символов \n. Следующий пример содержит программу, выполняющую те же самые действия, но написанную на Си++.
Первое отличие от программы из примера 1 состоит в форме комментария. В Си++ можно использовать строчный комментарий, который начинается с символов //и заканчивается концом строки. Для организации вывода на экран к программе подключается специальная библиотека объектов, заголовочный файл которой имеет имя iostream.h. Вывод осуществляется посредством объекта cout из этой библиотеки. В примере 1 используется механизм форматного ввода/вывода. характерный для Си. В примере 2 работает механизм потокового ввода/вывода, реализованный в Си++. Преемственность Си++ по отношению к Си выражается в том, что программа из примера 1 будет восприниматься компилятором Си++, т. е. эта программа исполнима в любой системе программирования, ориентированной на Си++. Рассмотрим еще один пример программы на Си/Си++. Сопоставим ее с аналогичной программой на Паскале. Пример 3. Деление простых дробей:
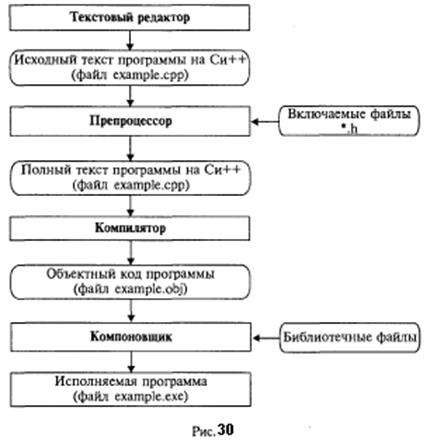
В этом примере появился целый ряд новых элементов по сравнению с предыдущим. Первая строка в теле главной функции является объявлением пяти переменных целого типа — int. Далее наряду с уже знакомым оператором форматного вывода на экран используется оператор форматного ввода с клавиатуры — scanf (). Это также стандартная функция из библиотеки ввода/вывода, подключаемая к программе с помощью файла stdio. h. Первый аргумент этой функции %d является спецификацией формата вводимых значений. В данном случае он указывает на то, что с клавиатуры будет вводиться целое число. Перед именем вводимой переменной принято писать символ &. Это необходимо делать для правильной работы функции scanf (). Смысл данного символа будет пояснен позже. В отличие от Паскаля в качестве знака присваивания используется символ =. Однако читать его надо как «присвоить». Спецификации формата %d используются и при организации вывода на экран целых чисел с помощью функции printf (). Этапы работы с программой на Си++ в системе программирования (рис. 30— прямоугольниками отображены системные про граммы, а блоки с овальной формой обозначают файлы на входе и на выходе этих программ).
1. С помощью текстового редактора формируется текст программы и сохраняется в файле с расширением срр. Пусть, например, это будет файл с именем example, срр. 2. Осуществляется этап препроцессорной обработки, содержание которого определяется директивами препроцессора, расположенными перед заголовком программы (функции). В частности, по директиве #include препроцессор подключает к тексту программы заголовочные файлы (*.h) стандартных библиотек. 3. Происходит компиляция текста программы на Си++. В ходе компиляции могут быть обнаружены синтаксические ошибки, которые должен исправить программист. В результате успешной компиляции получается объектный код программы в файле с расширением obj. Например, example.obj. 4. Выполняется этап компоновки с помощью системной программы Компоновщик (Linker). Этот этап еще называют редактированием связей. На данном этапе к программе подключаются библиотечные функции. В результате компоновки создается исполняемая программа в файле с расширением ехе. Например, example.exe.
Элементы языка С++ Алфавит. В алфавит языка Си++ входят: • латинские буквы: от а до г (строчные) и от А до Z (прописные); • десятичные цифры: 0, 1, 2, 3, 4, 5, 6, 7, 8, 9; • специальные символы:" { }, I []()+-/% \; ':?< = >__! &#~ Л. * К специальным символам относится также пробел. В комментариях, строках и символьных константах могут использоваться и другие знаки (например, русские буквы). Комбинации некоторых символов, не разделенных пробелами, интерпретируются как один значимый символ. К ним относятся: ++ — == && || «» >= <= += -= *= /=?: /* */ // В Си++ в качестве ограничителей комментариев могут использоваться как пары символов /* и */, принятые в языке Си, так и символы //, используемые только в Си++. Признаком конца та кого комментария является невидимый символ перехода на новую строку. Примеры: /* Это комментарий, допустимый в Си и Си++ */ //Это строчный комментарий, используемый только в Си++
Из символов алфавита формируются лексемы — единицы текста программы, которые при компиляции воспринимаются как единое целое и не могут быть разделены на более мелкие элементы. К лексемам относятся идентификаторы, служебные слова, константы, знаки операций, разделители. Идентификаторы. Последовательность латинских букв, цифр, символов подчеркивания (_), начинающаяся с буквы или символа подчеркивания, является идентификатором. Например: В12 rus hard_RAM_disk MAX ris_32 В отличие от Паскаля в Си/Си++ различаются прописные и строчные буквы. Это значит, что, например, flag, FLAG, Flag, FlAg — разные идентификаторы. Ограничения на длину идентификатора могут различаться в разных реализациях языка. Компиляторы фирмы Borland позволяют использовать до 32 первых символов имени. В некоторых других реализациях допускаются идентификаторы длиной не более 8 символов. Служебные (ключевые) слова. Как и в Паскале, служебные слова в Си — это идентификаторы, назначение которых однозначно определено в языке. Они не могут быть использованы как свобод но выбираемые имена. Полный список служебных слов зависит от реализации языка, т. е. различается для разных компиляторов. Однако существует неизменное ядро, которое определено стандартом Си++. Вот его список:
Дополнительные к этому списку служебные слова приведены в описаниях конкретных реализаций Си++. Некоторые из них начинаются с символа подчеркивания, например: _export, _ds, _AH и др. Существуют служебные слова, начинающиеся с двойного подчеркивания. В связи с этим программисту не рекомендуется использовать в своей программе идентификаторы, начинающиеся с одного или двух подчеркиваний, во избежание совпадения со служебными словами.
|
|||||||||
|
|
Последнее изменение этой страницы: 2021-04-05; просмотров: 236; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.218.234.83 (0.084 с.) |