Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Декомпозиция данных и соответствующие расширения диаграмм потоков данных
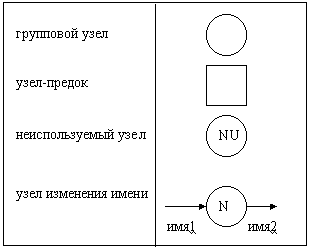
Индивидуальные данные в системе часто являются независимыми. Однако иногда необходимо иметь дело с несколькими независимыми данными одновременно. Например, в системе имеются потоки ЯБЛОКИ, АПЕЛЬСИНЫ и ГРУШИ. Эти потоки могут быть сгруппированы с помощью введения нового потока ФРУКТЫ. Для этого необходимо определить формально поток ФРУКТЫ как состоящий из нескольких элементов-потомков. Такое определение задается с помощью формы Бэкуса-Наура (БНФ) в словаре данных (см. главу 3). В свою очередь поток ФРУКТЫ сам может содержаться в потоке-предке ЕДА вместе с потоками ОВОЩИ, МЯСО и др. Такие потоки, объдиняющие несколько потоков, получили название групповых. Обратная операция, расщепление потоков на подпотоки, осуществляется с использованием группового узла (рис. 2.2), позволяющего расщепить поток на любое число подпотоков. При расщеплении также необходимо формально определить подпотоки в словаре данных (с помощью БНФ).
Рис 2.2. Расширения диаграммы потоков данных Аналогичным образом осуществляется и декомпозиция потоков через границы диаграмм, позволяющая упростить детализирующую DFD. Пусть имеется поток ФРУКТЫ, входящий в детализируемый процесс. На детализирующей этот процесс диаграмме потока ФРУКТЫ может не быть вовсе, но вместо него могут быть потоки ЯБЛОКИ и АПЕЛЬСИНЫ (как будто бы они переданы из детализируемого процесса). В этом случае должно существовать БНФ-определение потока ФРУКТЫ, состоящего из подпотоков ЯБЛОКИ и АПЕЛЬСИНЫ, для целей балансирования. Применение этих операций над данными позволяет обеспечить структуризацию данных, увеличивает наглядность и читабельность диаграмм. Для обеспечения декомпозиции данных и некоторых других сервисных возможностей к DFD добавляются следующие типы объектов:
Возможный способ изображения этих узлов приведен на рис. 2.2.
Построение модели Главная цель построения иерархического множества DFD заключается в том, чтобы сделать требования ясными и понятными на каждом уровне детализации, а также разбить эти требования на части с точно определенными отношениями между ними. Для достижения этого целесообразно пользоваться следующими рекомендациями:
В соответствии с этими рекомендациями процесс построения модели разбивается на следующие этапы:
ГЛАВА 3 СЛОВАРЬ ДАННЫХ Диаграммы потоков данных обеспечивают удобное описание функционирования компонент системы, но не снабжают аналитика средствами описания деталей этих компонент, а именно, какая информация преобразуется процессами и как она преобразуется. Для решения первой из перечисленных задач предназначены текстовые средства моделирования, служащие для описания структуры преобразуемой информации и получившие название словарей данных. Словарь данных представляет собой определенным образом организованный список всех элементов данных системы с их точными определениями, что дает возможность различным категориям пользователей (от системного аналитика до программиста) иметь общее понимание всех входных и выходных потоков и компонент хранилищ. Определения элементов данных в словаре осуществляются следующими видами описаний:
Содержимое словаря данных Для каждого потока данных в словаре необходимо хранить имя потока, его тип и атрибуты. Информация по каждому потоку состоит из ряда словарных статей, каждая из которых начинается с ключевого слова - заголовка соответствующей статьи, которому предшествует символ “ @ ”.
По типу потока в словаре содержится информация, идентифицирующая:
Атрибуты потока данных включают:
БНФ - нотация БНФ-нотация позволяет формально описать расщепление/ объединение потоков. Поток может расщепляться на собственные отдельные ветви, на компоненты потока-предка или на то и другое одновременно. При расщеплении/объединении потока существенно, чтобы каждый компонент потока-предка являлся именованным. Если поток расщепляется на подпотоки, необходимо, чтобы все подпотоки являлись компонентами потока-предка. И наоборот, при объединении потоков каждый компонент потока-предка должен по крайней мере однажды встречаться среди подпотоков. Отметим, что при объединении подпотоков нет необходимости осуществлять исключение общих компонент, а при расщеплении подпотоки могут иметь такие общие (одинаковые) компоненты. Важно понимать, что точные определения потоков содержатся в словаре данных, а не на диаграммах. Например, на диаграмме может иметься групповой узел с входным потоком X и выходными подпотоками Y и Z. Однако это вовсе не означает, что соответствующее определение в словаре данных обязательно должно быть X=Y+Z. Это определение может быть следующим: X=A+B+C; Y=A+B; Z=B+C Такие определения хранятся в словаре данных в так называемой БНФ-статье. БНФ-статья используется для описания компонент данных в потоках данных и в хранилищах. Ее синтаксис имеет вид:
@БНФ = <простой оператор>! <БНФ-выражение>, где <простой оператор> есть текстовое описание, заключенное в " / ", а <БНФ-выражение> есть выражение в форме Бэкуса-Наура, допускающее следующие операции отношений:
Итерационные скобки могут иметь нижний и верхний предел, например:
БНФ-выражение может содержать произвольные комбинации операций:
Ниже приведен пример описания потока данных с помощью БНФ:
Посмотрим, как некоторые потоки, присутствующие на вышеприведенных диаграммах потоков данных, представляются в словаре данных.
ГЛАВА 4 МЕТОДЫ ЗАДАНИЯ СПЕЦИФИКАЦИЙ ПРОЦЕССОВ Спецификация процесса (СП) используется для описания функционирования процесса в случае отсутствия необходимости детализировать его с помощью DFD (т.е. если он достаточно невелик, и его описание может занимать до одной страницы текста). Фактически СП представляют собой алгоритмы описания задач, выполняемых процессами: множество всех СП является полной спецификацией системы. СП содержат номер и/или имя процесса, списки входных и выходных данных и тело (описание) процесса, являющееся спецификацией алгоритма или операции, трансформирующей входные потоки данных в выходные. Известно большое число разнообразных методов, позволяющих задать тело процесса, соответствующий язык может варьироваться от структурированного естественного языка или псевдокода до визуальных языков проектирования (типа FLOW-форм и диаграмм Насси-Шнейдермана) и формальных компьютерных языков. Независимо от используемой нотации спецификация процесса должна начинаться с ключевого слова (например, @СПЕЦПРОЦ). Требуемые входные и выходные данные должны быть специфицированы следующим образом:
@ВХОД = <имя символа данных> Эти ключевые слова должны использоваться перед определением СП, например, @ВХОД = СЛОВА ПАМЯТИ Ситуация, когда символ данных является одновременно входным и выходным, может быть описана двумя способами: либо символ описывается два раза с помощью @ВХОД и @ВЫХОД, либо один раз с помощью @ВХОДВЫХОД. Иногда в СП задаются пред- и пост-условия выполнения данного процесса. В пред-условии записываются объекты, значения которых должны быть истинны перед началом выполнения процесса, что обеспечивает определенные гарантии безопасности для пользователя. Аналогично, в случае наличия пост-условия гарантируется, что значения всех входящих в него объектов будут истинны при завершении процесса. Спецификации должны удовлетворять следующим требованиям:
Ниже рассматриваются некоторые наиболее часто используемые методы задания спецификаций процессов.
|
|||||||||
|
|
Последнее изменение этой страницы: 2021-04-04; просмотров: 87; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.119.192.100 (0.021 с.) |