
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Метод ближайших соседей в задаче классификации документов вуза
К простым методам классификации документов также относится метрический метод k -ближайших соседей [1, 3, 11, 12]. Суть метода заключается в том, что документу d присваивается тот класс c, к которому принадлежит большинство из k ближайших соседей документа, вычисленных с помощью какой-либо метрики расстояния. Использование при классификации документов метода k -ближайших соседей, как и в случае использования наивного байесовского классификатора, предполагает использование машинных методов обучения с учителем. Следовательно, при решении задачи классификации можно использовать обучающее множество документов, для которых уже известен класс, к которому они принадлежат. Документ d будем относить к тому классу, элементов которого окажется больше среди k ближайших соседей [13]:
где d – документ, который необходимо классифицировать; Следует отметить, что при k = 1 алгоритм не устойчив к выбросам – если в обучающей выборке есть документ, окруженный документами чужого класса, то этот документ будет классифицирован неверно. И, напротив, если за значение k взять число всех документов из обучающей выборки, то алгоритм становится чрезвычайно устойчивым и вырождается в константу. Учитывая изложенное, можно сказать, что использование крайних значений в алгоритме нежелательно. Поэтому оптимальное значение критерия k лучше рассчитывать. Для его определения на практике часто используют критерий скользящего контроля с исключением объектов по одному (leave-one-out, LOO) [13]:
где k – число ближайших соседей документа Для нахождения k ближайших соседей документа d необходимо рассчитать расстояние Серьезным недостатком метода k -ближайших соседей является неоднозначность классификации – документ может быть отнесен к нескольким классам одновременно. Поэтому для увеличения качества классификации можно ввести веса
где d – документ, который необходимо классифицировать; Чтобы полностью устранить неоднозначность классификации, можно взять нелинейно убывающую последовательность весов, например, геометрическую прогрессию, которую также как и параметр k можно подобрать с помощью критерия LOO. В методе k -ближайших соседей качество классификации напрямую зависит от количества обучающих документов: для хорошего качества классификации документов требуется экспоненциально большее число обучающих документов. Вследствие этого метод чрезмерно приспосабливается к обучающей выборке и в дальнейшем плохо работает с обучающими документами, выдавая низкие показатели классификации. Кроме того, в исследовании [23] отмечается, что вычисление соответствующих расстояний между всеми тестовыми и обучающими документами делает метод- k ближайших соседей вычислительно затратным при применении к зашумленным текстовым данным, которых в вузе имеется большое количество. Таким образом, относительная производительность метода k -ближайших соседей, как и в случае наивного байесовского классификатора, ниже для более длинных текстов. В связи с этим для больших текстовых документов вуза лучше использовать другие методы классификации. Однако этот же метод может быть использован для коротких текстовых документов вуза, таких как служебные записки, где можно выделить «сильные» ключевые слова.
|
||
|
|
Последнее изменение этой страницы: 2021-03-09; просмотров: 68; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.222.67.251 (0.005 с.) |
 , (5)
, (5)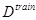 – обучающая выборка документов; k – число ближайших соседей; c – класс документа.
– обучающая выборка документов; k – число ближайших соседей; c – класс документа. , (6)
, (6) ; l – количество всех документов из обучающей выборки;
; l – количество всех документов из обучающей выборки; 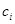 – класс документа
– класс документа  от документа d до каждого из документов
от документа d до каждого из документов  обучающей выборки. При расчете расстояния в методе k -ближайших соседей могут быть использованы разные метрики расстояния [12, 14, 15]: евклидова метрика, манхэттенская метрика, метрика Минковского, косинусная мера и др. Выбор метрики зависит от решаемой задачи. На практике редко удается сразу определить нужную метрику, поэтому часто используют несколько метрик, а затем по результатам классификации выбирают ту, что для решаемой задачи дает лучший результат классификации.
обучающей выборки. При расчете расстояния в методе k -ближайших соседей могут быть использованы разные метрики расстояния [12, 14, 15]: евклидова метрика, манхэттенская метрика, метрика Минковского, косинусная мера и др. Выбор метрики зависит от решаемой задачи. На практике редко удается сразу определить нужную метрику, поэтому часто используют несколько метрик, а затем по результатам классификации выбирают ту, что для решаемой задачи дает лучший результат классификации. , задающие вклад каждого i -го соседа в классификацию:
, задающие вклад каждого i -го соседа в классификацию: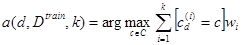 , (7)
, (7)


