Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
The Comparative Method. The reconstruction technique.Стр 1 из 4Следующая ⇒
Theme 1 Lecture # 1. General Methodsof Obtaining and Processing Linguistic Data Present-Day Linguistics. 1.Informants. 2. Recording. 3. Elicitation. 4. Experiments. 5. The comparative method. The reconstruction technique. 6. Quantitative methods. 7. Computer techniques. 8. Corpora. Методы исследования языка: эмпирический/дедуктивный, пассивный/активный, интроспективный/аналитический/экспериментальный, инструментальный, статистический, сравнительный. Метод включает в себя понятийный аппарат и определенные способы исследования и описания материала. Теория должна содержать сведения о свойствах, являющихся для человеческого языка необходимыми или высоко вероятными, т. е. верными для каждого отдельного языка или для большинства языков. Key words: kinship (спорідненість); kindred (споріднений); nomenclature (the terminology used in a particular science) Method in a science presupposes the nomenclature and definite means of research and description of the material within the framework of a certain theory. A theory should contain the data about the properties which are necessary and highly likely for a l-ge, are true of a certain l-ge and majority of l-ges.
Present-Day Linguistics The development of linguistics has been particularly conspicuous in recent decades. There has been increased popular interest in the role of language in relation to human beliefs and behaviour, and an accompanying awareness of the need for a separate academic discipline to deal adequately with the range and complexity of linguistic phenomena. The university teaching of Linguistics emerged during the XIX century and since then several branches of linguistic enquiry have been established. Different dimensions of the subject can be distinguished, depending on the focus and interests of the linguist. Diachronic (or historical) and synchronic types of linguistics have developed as a result of the distinction introduced by Saussure (1857-1913, a Swiss linguist and semiotician); the former is the study of language change, the latter the study of language states regardless of their history. When linguists try to establish general principles for the study of all languages, they are said to be practising Theoretical (or General) Linguistics. When they concentrate on establishing the facts of a particular language system, they practise Descriptive Linguistics. And when the focus is on the similarities and differences between languages, the subject is often referred to as Comparative (or Typological) Linguistics. Linguistics (the scientific study of language) shares with other sciences a concern to be objective, systematic, consistent, and explicit in its account of language. Like other sciences, Linguistics aims to collect data, test hypotheses, design models, and construct theories. Its subject-matter, however, is unique: on the one hand it overlaps with such "natural" sciences as physics and anatomy; on the other hand, it involves such traditional "arts" subjects as philosophy and literary criticism. Many methods are available for obtaining and processing data about a language. They range from a carefully planned intensive field investigation in a foreign country to casual introspection about one's mother tongue. 1. Informants – an empirical, active method In all cases someone has to act as a source of language data - an informant or consultant. Informants are ideally native speakers of a language who provide utterances for analysis and other kinds of information about the language (e.g. translations, comment about correctness or judgements on usage). Often, when studying their mother tongue, linguists act as their own informants, judging the ambiguity, acceptability, or other properties of utterances against their own intuitions. The convenience of this approach makes it widely used, and it is considered a primary datum in the generative approach to Linguistics. But a linguist's personal judgements are often uncertain, or disagree with the judgements of other linguists, at which point recourse is needed to more objective inquiry, using non-linguists as informants. The latter procedure is unavoidable when working on foreign languages, or in such mother-tongue fields as child speech or language variation.
Many factors must be considered when selecting informants - whether one is working with single speakers (a common situation when languages have not been described before), two people interacting, small groups, or large-scale samples. Important factors are: age, sex, social background, and other aspects of identity, as these factors are known to influence the kind of language used. The topic of the conversation and the characteristics of the social setting (e.g. the level of formality) are also highly relevant, as are the personal qualities of the informants (e.g. their fluency and consistency). For larger studies, scrupulous attention has to be paid to the sampling theory employed. And in all cases decisions have to be made about the best investigative techniques to use. 2. Recording – an empirical, active, instrumental method Today, data from an informant are often recorded. This enables the linguist's claims about the language to be checked, and provides a way of making those claims more accurate ("difficult" pieces of speech can be listened to repeatedly). But obtaining naturalistic, good quality data is never easy. People talk abnormally when they know they are being recorded. A variety of recording procedures have thus been devised to minimize the effects of the "observer's paradox" (how to observe the behaviour of people when they are not being observed – the term Observer’s Paradox was coined by William Labov, who stated with regards to the term: the aim of linguistic research in the community must be to find out how people talk when they are not being systematically observed; yet we can only obtain this data by systematic observation). Some recordings are made without the speakers being aware of the fact - a procedure that obtains very natural data, though ethical objections must be anticipated. Alternatively, attempts can be made to make the speaker forget about the recording, such as by keeping the recorder out of sight, or using radio microphones. A useful technique is to introduce a topic that quickly involves the speaker, and stimulates a natural language style (e.g. asking older informants to talk how times have changed in their locality). Audio recording does not solve all the linguist's problems, however. Speech is often unclear or ambiguous. Where possible therefore, the recording has to be supplemented with the observer's notes about the non-verbal behaviour of the participants, and about the context in general. A facial expression, for example, can dramatically alter the meaning of what is said. Video recordings avoid these problems to a large extent, but even they have limitations (the camera can be highly intrusive, and cannot be everywhere), and transcriptions always benefit from any additional commentary provided by an observer. 3. Elicitation ( встановлення (правди); виявлення ) Linguists also make great use of structured sessions, in which they systematically ask their informants for utterances that describe certain actions, objects or behaviours. With a bilingual informant, or through the use of an interpreter, it is possible to use translation techniques ("How do you say table in your language?" "What does gua mean?"). A large number of points can be covered in a short time, using interview worksheets and questionnaires. Often, the researcher wishes to obtain information about just a single variable, in which case a restricted set of questions may be used: a particular feature of pronunciation, for example, can be elicited by asking the informant to say a restricted set of words. There are also several indirect methods of elicitation, such as asking informants to fill the blanks in a substitution frame (e.g. I – (can) see a car), or feeding them with the wrong stimulus for correction ("Is it possible to say I no can see?").
Experiments Experimental techniques are widely used in Linguistics, namely, Phonetics, Cognitive Linguistics; Psycholinguistics, Sociolinguistics, child language acquisition and language pathology. In grammar and semantics experimental studies usually take the form of controlled methods for eliciting judgements about sentences or the elements they contain. Informants can be asked to identify errors, to rate the acceptability of sentences, to make judgements of perception or comprehension, and to carry out a variety of analytical procedures. Computer Techniques Alongside with the "routine" use of computers in such areas as numerical counting, statistical analysis and pattern matching, Linguistics provides a range of opportunities for the manipulation of non-numerical data, using natural language texts. Some of these tasks are indexing and concordancing; speech recognition and synthesis, machine translation and language learning. Since the 1980s the chief focus of computational linguistic research has been in the area known as natural language processing (NLP). Here the aim is to devise techniques which will automatically analyze large quantities of spoken (transcribed) or written text in ways broadly parallel to what happens when humans carry out this task. NLP deals with the computational processing of text - both its understanding and its generation in natural human language s. It thus forms a major part of the domain of Computational Linguistics; but it is not to be identified with it, as computers can also be used for many other purposes in Linguistics, such as the processing of statistical data in authorship studies. The field of NLP emerged out of machine translation in the 1950s and was later much influenced by work on artificial intelligence. There was a focus on devising "intelligent programs" (or "expert systems") which aimed to stimulate aspects of human behaviour, such as the way people can infer meaning from what has been said, or use their knowledge of the world to reach a conclusion. Most recently particular attention has been paid to the nature of discourse (in the sense of text beyond the sentence) and there has been confrontation with the vast size of the lexicon, using the large amounts of lexical data now available in machine-readable form from commercial dictionary projects. Progress has been considerable, but successful programs are still experimental in character, largely dealing with restricted tasks in well-defined settings. There is still a long way to go before computer systems can get anywhere near the flexible and creative world of real conversation, with its often figurative expression and ill-formed conversation.
8. Corpora – the method of Corpus analysis is the most modern method of obtaining linguistic data. A corpus – a large collection of written and spoken texts – is a representative sample, compiled for the purpose of linguistic analysis.A corpus enables the linguist to make objective statements about frequency of usage, and it provides accessible data for the use of different researches. Its range and size are variable. Some corpora attempt to cover the language as a whole, taking extracts from many kinds of text; others are extremely selective, providing a collection of material that deals only with a particular linguistic feature. The size of a corpus depends on practical factors such as the time available to collect, process, and store the data: it can take up to several hours to provide an accurate transcription of a few minutes of speech. Sometimes a small sample of data will be enough to decide a linguistic hypothesis; corpora in major research projects can total millions of running words. A standard corpus is a large collection of data available for use by many researchers. In English Linguistics all computer corpora are in a machine-readable form, and thus, available anywhere in the world.
Theme 2 General Notes An initial report appeared in 1991, and a substantially revised and expanded version in early 1994. Lead partner in consortium [[kən'sɔːtɪəm]] (an association of companies, esp. one formed for a particular purpose): Oxford University Press The general benefits of the corpus method: – The material collected in large computerized corpora represents authentic rather than invented language. – Computers can process enormous amounts of data. – The method of retrieving the data is objective rather than intuitive, which implies that studies can be replicated by other researches using the same or different corpora. – Specific corpora selected from particular types of texts allow for comparisons of the use and frequency of certain features in different text-types, provided that the corpora are large enough. Purpose
The uses originally envisaged for the British National Corpus were set out in a working document called Planned Uses of the British National Corpus BNCW02 (11 April 91). This document identified the following as likely application areas for the corpus: • reference book publishing • academic linguistic research • language teaching • artificial intelligence • natural language processing • speech processing • information retrieval Particularly, the database provided by the Corpus may be used: 1) as a source of examples of “real life” language usage in teaching English; 2) for finding new tendencies in language development; 3) for the investigation of a speaker’s role in language production; 4) for determining peculiarities of different registers; 5) for contrastive analysis of English as a Native Language and English as a Foreign Language; 6) for theory and practice of translation using so called “translation and parallel corpora”. The same document identified the following categories of linguistic information derivable from the corpus: • lexical • semantic/pragmatic • syntactic • morphological • graphological/written form/orthographical The example of the contrastive analysis: the research in the sphere of infinitive and gerundial constructions usage has demonstrated the overuse of the infinitive construction after the word «possibility» by the students learning English as their second language. At the same time the speakers for whom English is a mother-tongue use the gerundial construction only. General definitions The British National Corpus is: • a sample corpus: composed of text samples generally no longer than 45,000 words. • a synchronic corpus: the corpus includes imaginative texts from 1960, informative texts from 1975. • a general corpus: not specifically restricted to any particular subject field, register or genre. • a monolingual British English corpus: it comprises text samples which are sub-stantially the product of speakers of British English. • a mixed corpus: it contains examples of both spoken and written language. Design of the corpus There is a broad consensus among the participants in the project and among corpus linguists that a general-purpose corpus of the English language would ideally contain a high proportion of spoken language in relation to written texts. However, it is significantly more expensive to record and transcribe natural speech than to acquire written text in computer-readable form. Consequently the spoken component of the BNC constitutes approximately 10 per cent (10 million words) of the total and the written component 90 per cent (90 million words). These were agreed to be realistic targets, given the constraints of time and budget, yet large enough to yield valuable empirical statistical data about spoken English. The BNC World Edition contains 4054 texts and occupies 1,508,392 Kbytes, or about 1.5 Gb. In total, it comprises just over 100 million orthographic words (specifically, 100,467,090), but the number of w-units is slightly less: 97,619,934. The total number of s-units is just over 6 million (6,053,093). • S-units (segment-units): number of <s> elements – more or less equivalent to sentences • W-units: number of <w> elements – more or less equivalent to words. The percentage is calculated with reference to the relevant portion of the corpus, for example, in the table for "written text domain", with reference to the total number of written texts. These reference totals are given in the first table below. Table 1. Composition of the BNC World Edition
All texts are also classified according to their date of production. For spoken texts, the date was that of the recording. For written texts, the date used for classification was the date of production of the material actually transcribed, for the most part; in the case of imaginative works, however, the date of first publication was used. Informative texts were selected only from 1975 onwards, imaginative ones from 1960, reflecting their longer “shelf-life”, though most (75 per cent) of the latter were published no earlier than 1975.
Table 2. Date of production
Selection features Texts were chosen for inclusion according to three selection features: domain (subject field), time (within certain dates) and medium (book, periodical, etc.). The purpose of these selection features was to ensure that the corpus contained a broad range of different language styles, for two reasons. The first was so that the corpus could be regarded as a microcosm of current British English in its entirety, not just of particular types. The second was so that different types of text could be compared and contrasted with each other. 3.1. Sample size and method For books, a target sample size of 40,000 words was chosen. No extract included in the corpus exceeds 47,000 words. Text samples normally consist of a continuous stretch of discourse from within the whole. Only one sample was taken from any one text. Samples were taken randomly from the beginning, middle or end of longer texts. (In a few cases, where a publication included essays or articles by a variety of authors of different nationalities, the work of non-UK authors was omitted.) As far as possible, the individual stories in one issue of a newspaper were grouped according to domain, for example as “Business” articles, “Leisure” articles, etc. The following subsections discuss each selection criterion, and indicate the actual numbers of words in each category included. Domain Classification according to subject field seems hardly appropriate to texts which are fictional or which are generally perceived to be literary or creative. Consequently, these texts are all labelled imaginative and are not assigned to particular subject areas. All other texts are treated as informative and are assigned to one of the eight domains listed in Tab. 3. Table 3. Written domain
The labels we have adopted represent the highest levels of a fuller taxonomy of text medium. Table 4. Written medium
The ‘Miscellaneous published’ category includes brochures, leaflets, manuals, advertise-ments. The ‘Miscellaneous unpublished’ category includes letters, memos, reports, minutes, essays. The ‘written-to-be-spoken’ category includes scripted television material, play scripts etc. 3. Selection procedures employed – Books Roughly half the titles were randomly selected from available candidates identified in Whitaker’s Books in Print (BIP), 1992, by students of Library and Information Studies at Leeds City University. Each text randomly chosen was accepted only if it fulfilled certain criteria: it had to be published by a British publisher, contain sufficient pages of text to make its incorporation worthwhile, consist mainly of written text, fall within the designated time limits, and cost less than a set price. The final selection weeded out texts by non-UK authors. Half of the books having been selected by this method, the remaining half were selected systematically. Sampling procedure 124 adults (aged 15+) were recruited from across the United Kingdom. Recruits were of both sexes and from all age groups and social classes. The intention was, as far as possible, to recruit equal numbers of men and women, equal numbers from each of the six age groups, and equal numbers from each of four social classes. Recording procedure All conversations were recorded as unobtrusively as possible, so that the material gathered approximated closely to natural, spontaneous speech. In many cases the only person aware that the conversation was being taped was the person carrying the recorder.
Sampling procedure For the most part, a variety of text types were sampled within three geographic regions. However, some text types, such as parliamentary proceedings, and most broadcast categories, apply to the country as a whole and were not regionally sampled. Different sampling strategies were required for each text type, and these are: Educational and informative domain (area): Lectures, talks, educational demonstrations Within each sampling area a university (or college of further education) and a school were selected. A range of lectures and talks was recorded, varying the topic, level, and speaker gender. News commentaries Regional sampling was not applied, but both national and regional broadcasting companies were sampled. The topic, level, and gender of commentator was varied. Classroom interaction Schools were regionally sampled and the level (generally based on student age) and topic were varied. Home tutorials were also included. Business: Company talks and interviews Sampling took into account company size, areas of activity, and gender of speakers. Trade union talks Talks to union members, branch meetings and annual conferences were all sampled. Sales demonstrations A range of topics was included. Business meetings Companies were selected according to size, area of activity, and purpose of meeting. Consultations These included medical, legal, business and professional consultations. All categories under this heading were regionally sampled. Public/ or institutional: Political speeches Regional sampling of local politics, plus speeches in both the House of Commons and the House of Lords. Sermons Different denominations were sampled. Public/government talks Regional sampling of local inquiries and meetings, plus national issues at different levels. Council meetings Regionally sampled, covering parish, town, district, and county councils. Religious meetings domain Includes church meetings, group discussions, and so on. Parliamentary proceedings Sampling of main sessions and committees, House of Commons and House of Lords. Legal proceedings Royal Courts of Justice, and local Magistrates and similar courts were sampled. Leisure: Speeches Regionally sampled, covering a variety of occasions and speakers. Sports commentaries Exclusively broadcast, sampling a variety of sports, commentators, and TV/radio channels. Talks to clubs Regionally sampled, covering a range of topics and speakers. Broadcast chat shows and phone-ins Only those that include a significant amount of unscripted speech were selected from both television and radio. Club meetings Regionally sampled, covering a wide range of clubs. How to search Using the BNC one can search for a lexeme by entering a word form (or a part of this word form plus wildcards). In corpora via the Internet it is also possible to search on lemma (a word or phrase treated in a glossary or similar listing = словарная форма слова - форма, представляющая лексему в словаре; a word considered as its citation form together with all the inflected forms. For example, the lemma go consists of go together with goes, going, went, and gone) and part of speech. The restriction of searching on wordform only entails problems related to, for example, homographs, which have different parts of speech. It is possible to conduct the search, presupposing one-to-five-element distance between the units as is useful in case of phrasal verbs. The retrieval-program then shows the frequency of the word form (= keyword). Subsequently, the concordances (keywords in restricted textual contexts; a book that indexes the principal words in a literary work, often with the immediate context and an account of the meaning – алфавітний покажчик слів у книзі з цитатами (у яких ці слова трапляються)) may be retrieved. The largest context is a bit longer than a paragraph. The results one gets are from the whole corpus. So, if needed it is possible to refer to the list of works excerpted where besides the author and the title, the domain and year are indicated and select only those concordances you have interest in.
How it looks on the screen: Theme 3. Structuralism. Lecture # 3. Structuralism.Methods of structural analysis. 1. Structural grammatical theories. 2. N. Chomsky's Linguistic Conception. Competence and performance.Basic rules of Generative Grammar (= phrase structure rules). Structuralism, from which Structural Analysis derives, is the methodological principle that human culture is made up of systems in which a change in any element produces changes in the others. Four basic types of theoretical or critical activities have been regarded as structuralist: the use of language as a structural model, the search for universal functions or actions in texts, the explanation of how meaning is possible, and the post-structuralist denial of objective meaning. 1. Structural grammatical theories. Two main streams dominated linguistics in the 20th century. The first is structuralism represented by the Prague School that created functional linguistics, the Copenhagen School which created Glossematics (the same as Suassure’s but more abstract – their system of the difference between l-ge and speech is four-member: scheme/norm/usage/act), and the American School that created descriptive linguistics. The second stream of linguistic thinking is structuralism inseparably connected with the name of Noam Chomsky whose work meant a fundamental breakthrough in the development of linguistic theory in the second half of the XX century. The essence of Structural Linguistics is in the tenet (belief) that every element has its place in the integrity of language structure and it is important to establish its place, its relation to other elements and consequently to function. Structural Linguistics deals with a real language structure and a scholar's task is to reveal it with the aim of a fuller cognition of language nature and laws of its functioning. Thus, structural grammarians are to a large degree concerned with studying patterns of organization, or structures. They hold the view that linguistics, like physics and chemistry or, say, geology or astronomy, must be preoccupied with structure. Central to structuralism is the notion of opposition and oppositional analysis which is connected with the Prague School, founded in 1929 by Czech and Russian linguists Vilem Mathesius, Nikolay Trubetzkoy, Roman Jakobson and others. Oppositional analysis was first introduced by Nikolay Trubetzkoy (1890-1938) who presented an important survey of the problem of phonology in his Grundzuge der Phonologie (' The Fundamentals of Phonology) published in Prague in 1939. In terms of N.S. Trubetzkoy's theory, opposition is defined as a functionally relevant relationship of partial difference between two partially similar elements of language. The common features of the members of the opposition make up its basis, the features that serve to differentiate them are distinctive features. For example, /b/ and /p/ are members of a phonological opposition: in English the phoneme /b/ is characterized by voicing, stop articulation (that is, it involves a complete closure), and it is oral, that is non-nasal, whereas /p/ shares all of those characteristics except voicing. Girl and girlish are members of a morphemic opposition. They are similar as the root morpheme girl- is the same. Their distinctive feature is the suffix –ish. Man and boy are members of a lexical opposition which is defined as the semantically relevant relationship of partial difference between two partially similar words The distinctive feature in the opposition is the semantic component of age. Morphological (formal) opposition may be well illustrated by the pair play vs plays which represents the opposition between the third person singular present tense, on the one hand, and the other persons or the singular plus those of the plural, on the other, Oppositional relations on the sentence level are most obvious in the correlation between Peter plays and Peter does not play which gives the opposition affirmation vs negation. Correlation between Peter plays and Does Peter play? illustrates the opposition declarative vs interrogative sentence. The main contribution of the American Descriptive School to the study of grammar is the elaboration of techniques of linguistic analysis. The main methods are: 1) the distributional analysis; 2) the Immediate Constituent (IC) analysis (phrase-structure grammar). American Descriptive School began with the works of Edward Sapir (1884-1939) and Leonard Bloomfield (1887-1949). American linguistics developed under the influence of these two prominent scientists. The ideas laid down in Bloomfield’s book Language (1933) were later developed by Z.S. Harris, R.S. Wells, Ch.F. Hockett, Ch.C. Fries, E.A. Nida. Descriptive linguistics developed in the United States from the necessity of studying half-known and unknown languages of the American Indian tribes. The Indian languages had no writing and, therefore, had no history. The comparative historical method was of little use here, and the first step of work was to be keen observation and rigid registration of linguistic forms. The American Indian languages belong to a type that has little in common with the Indo-European languages; they are incorporating languages, devoid of morphological forms of separate words and of corresponding grammatical meanings. Descriptive linguists had therefore to give up analyzing sentences in terms of traditional parts of speech; it was by far more convenient to describe linguistic forms according to their position and their co-occurrence in sentences. American descriptive linguists began by criticizing the Prague School oppositional method and claiming a more objective — distributional — approach to linguistic analysis. 1) Distributional analysis aims at analyzing linguistic elements in terms of their distribution. The term distribution is used to denote the possible variants of the immediate lexical, grammatical, and phonetic environment of a linguistic unit (phoneme, morpheme, word, etc.). It implies the position of an element and its combinability with other elements in this or that particular context. According to Z. Harris [1961: 15-16], the distribution of an element is the total of all environments in which it occurs, i.e. the sum of all the (different) positions (or occurrences) of an element relative to the occurrence of other elements. Distribution is the matter of speech, it is describable in terms of positions and in terms of positional classes (distributional classes) of fillers for these positions. Therefore, the distribution of an element is given by the distributional formula which is the contextual pattern of the environment characteristic of the concrete occurrence of a linguistic unit. The distributional value of the verb get, for instance, may be shown by the following examples: get + N (notional verb) get a book get + A (copula-type verb) get cool get + Vinf (semi-auxiliary verb of aspect) get to think get + Ving (semi-auxiliary verb of aspect) get thinking get + prep + Ving (semi-auxiliary verb of aspect) get to thinking get + N + Vinf (causative verb) get him to work get + N + Ving (causative verb) get the watch going get + N + Ven (causative verb) get it done get + Ven (the so-called passive auxiliary) get killed have got + Vinf (modal verb) it has got to be done get + Ven (function verb of an analytical lexical unit) get rid
2) Immediate Constituent analysis = phrase-structure grammar. The concept of IC analysis was first introduced by Leonard Bloomfield and later on developed by Rulon S. Wellsand other linguists— K.L. Pike, S. Chatman, E.A. Nida, R.S. Pittman. (IC) analysis was originally elaborated as an attempt to show how small constituents (or components) in sentences go together to form larger constituents. It was discovered that combinations of linguistic units are usually structured into hierarchically arranged sets of binary constructions, e.g., in the word-group a black dress in severe style we do not relate a to black, black to dress, dress to in, etc. but set up a structure which may be represented as a black dress / in severe style. An Immediate Constituent (IC) is a group of linguistic elements which functions as a unit in some larger whole. The division of a construction begins with the larger elements and continues as far as possible. Successive segmentation results in Ultimate Constituents (UC), i.e. two-facet units that cannot be segmented into smaller units having both sound-form and meaning. The Ultimate Constituents of the word-group analyzed above are: a / black / dress / in / severe / style. So, the fundamental aim of IC analysis is to segment each utterance into (two) maximally independent sequences or ICs, thus revealing the hierarchical structure of this utterance. The analysis of the constituent structure of the sentence can be represented in different types of diagrams: 1) the following diagram (a table) simply shows the distribution of the constituents at different levels, it can be used to show the types of forms which can substitute for each other at different levels of constituent structure
2) a candelabra diagram – The man hit the ball I_ I I I ___ I I I_____I 3) Another type of diagram uses slashes (/) to show the groupings of ICs: My younger brother / left all his things there. My // younger brother / left all his things // there. My // younger /// brother / left /// all his things // there. My // younger /// brother / left /// all //// his things // there. My // younger /// brother / left /// all //// his ///// things // there.
4) A labeled brackets diagram: the first step is to put brackets (one on each side) around each constituent, and then more brackets around each combination of constituents [Yule 1996: 94]. [[The] [dog]] [[followed] [[the] [boy]] 5) A derivation tree diagram – we can label each constituent with grammatical terms such as Det (article), N (noun), NP (noun phrase), V (verb), VP (verb phrase), S (sentence). S / \ NP VP / \ / \ Det N V NP The dog ate / \ Det N the bone The resulting sentence could be The dog ate the bone. Such a tree diagram is also called a phrase marker. The IC theory (or grammar) or the phrase theory (grammar) was the first modern grammar fit for generating sentences. When the IC model was created and diagrammed there was left only one step to its understanding as a generative model, a model by which sentences can be built (or generated). The most striking figure here is Noam Chomsky with his theory of Generative- Transformational Grammar and the starting-point his book Syntactic Structures (1957). He sought a simple linguistic theory which would generate all the sequences of morphemes (or words) that constitute grammatical English sentences.
2. N. Chomsky's Linguistic Conception. Competence and performance. Basic rules of Generative Grammar (= phrase structure rules). Basic notions of Chomsky's psycholinguistic conception are: language; language faculty (мовна здатність); cognize a language (пізнати мову); cognition (пізнання); language acquisition (оволодіння мовою); language acquisition device (механізм оволодіння мовою); knowledge of language (знання мови); mind/brain (свідомість/мозок); innateness (природженість); productivity/creativity (продуктивність/креативність); acceptable utterances (прийнятні висловлювання); marginal acceptability (прийнятність на грані припустимості); competence (компетенція); performance (уживання); grammaticality (граматичність мови); Generative / Universal Grammar (генеративна/універсальна граматика); language/linguistic universals (мовні/лінгвістичні універсали).
Chomsky pleaded for a dynamic approach as represented by his theory of Transformational and Generative Grammar, emphasizing that linguistic theory is mentalistic, concerned with discovering a mental reality underlying actual behaviour. Linguistic theory should contribute to the study of human mental processes and intellectual capacity. Chomsky called for the grammar of a particular language to be supplemented by a Universal Grammar that is principles valid for all (or majority of) languages. The description of a language should refer to a linguistic competence of a native speaker. Linguistic theory must be, however, concerned primarily with an ideal speaker-hearer in a completely homogeneous community, who knows his language perfectly, and is unaffected by such grammatically irrelevant conditions as memory limitations, shifts of attention, interest, and errors in applying his knowledge of language in actual performance.
In his work "Syntactic Structures" which proved to be a turning point in the 20th-century Linguistics and subsequent publications he developed the conception of a Generative Grammar, which departed radically from the structuralism of the previous decades. A major aim of Generative Grammar was to provide a means of analysing sentences that took account of this underlying level of structure. N. Chomsky has shifted the focus of linguistic theory from the study of observed behaviour to the investigation of the knowledge that underlies that behaviour. The primary objective of Generative Grammar is to model a speaker's linguistic knowledge. N.Chomsky characterises linguistic knowledge using the concepts of competence and performance. Competence is a person's implicit knowledge of the rules of a language that makes the production and understanding of an indefinitely large number of new utterances possible while performance is the actual use of language in real situations. Chomsky proposed that competence, rather than performance, is the primary object of linguistic inquiry. Put simply, knowledge of a language entails mastery of an elaborate system of rules that enables a person to encode and decode a limitless number of utterances in that language. If knowing a language essentially involves mastering a system of rules, how do humans fulfil this task? Chomsky claims that the linguistic capacity of humans is innate. The general character of linguistic knowledge is determined by the nature of the mind which is provided with a specialised language faculty. This faculty is determined by the biology of the brain. The human child is born with a blueprint (проект) of language which is called Universal Grammar. The term generative has two meanings for Chomsky. On the one hand, a Generative Grammar is the one that projects any given set of sentences upon the infinite set of sentences that constitute the language being described; this is the property of the grammar that reflects the creative aspect of human knowledge. The second sense of generative implies that the rules of the grammar and the conditions under which they operate must be precisely specified. They should be as precisely specified, i.e. formalized, as the rules of arithmetics. Thus, using the IC model, N. Chomsky worked out the system ofrigid rules for generating (building up) sentences. They are called phrase structure rules. Such rules and the structures they generate, are called recursive. Here S stands for Sentence, NP for Noun Phrase, VP for Verb Phrase, Det for Determiner, Aux for Auxiliary (verb), N for Noun, and V for Verb stem (Scheme 1):
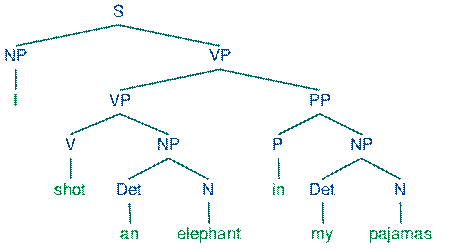
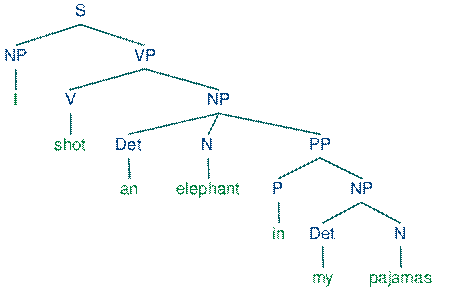
The rules are: every sentence (S) or syntactic construction is built up of two immediate constituents: the noun phrase (NP) and verb phrase (VP). The noun phrase consists of two IC: the determiner (Det) and noun or its equivalent (N). The verb phrase consists of the verb (V) and its noun phrase (NP). Noun Phrase, Verb Phrase, Prepositional Phrase (PP=Prep+NP – e.g. on the bed) are called “ phrasal categories ” (nodes in a tree diagram). A phrasal category corresponds to each of the major lexical categories – N(oun), V(erb), Prep(osition). These phrasal categories are constructed so that a particular phrasal category will dominate the corresponding lexical category, perhaps along with other material: so NP will dominate {... N...}; VP. {... V...} etc. It will be clear that if lexical items are assigned to lexical categories, and if there is this special relationship between lexical and phrasal categories, we will in this way explicitly define the range of possible phrasal categories: there will be as many phrasal categories as there are major lexical categories. An immediate consequence of this assumption about the relationship between lexical items and lexical and phrasal categories is that all analyses will necessarily be hierarchical in structure. Lexical categories will be grouped into phrasal categories which will themselves be grouped into yet other phrasal categories and so on. So, the nodes in the tree are labelled with the names of "categories”, like noun, or noun phrase. None of the labels involves the names of grammatical 'functions', like “subject” or “object”. The decision to exclude functional information of this sort from the analyses does not mean that it is irrelevant, but it does mean that it has been decided that structural information is primary, and functional information is of secondary importance. If we need such information, we will have to find a way of deriving it from the trees. For some functions this is straightforward: for example, we can identify the 'subject' as the NP which is dominated by S, and the “object” as the NP dominated by the VP. If we follow these rules and choose the girl for the first NP, and the dog for the second, we generate the girl chased the dog; but if the choices are made the other way round, we generate the sentence the dog chased the girl. By the simple device of adding a few more words to the rules, suddenly a vast number of sentences can be generated: V —> chased, saw, liked... Det —> the, a N —> girl, man, horse... the girl chased the horse the man saw the girl the horse saw the man etc. However, if went were introduced into the rules, as a possible V, ungrammatical sentences would come to be generated, such as *the girl went the man. In working out a generative grammar, therefore, a means has to be found to block the generation of this type of sentence, at the same time permitting such sentences as the man went to be generated. IC analysis is important in case the info expressed by the sentence may be dubious. Let’s consider the sentence: I shot an elephant in my pajamas. This grammar permits the sentence to be analyzed in two ways, depending on whether the prepositional phrase in my pajamas describes the elephant or the shooting event.
The history of generative syntax since 1957 is the study of the most efficient ways of writing rules, so as to ensure that a grammar will generate all the grammatical sentences of a language and none of the ungrammatical ones. This tiny fragment of a Generative Grammar from the 1950s suffices only to illustrate the general conception underlying the approach. "Real" grammars of this kind contain many rules of considerable complexity and of different types. One special type of rule that was proposed in the first formulations became known as a transformational rule. These rules enabled the grammar to show the relationship between sentences that had the same meaning but were of different grammatical form. We will speak about transformational rules in detail a bit later on. Theme 4. Lecture # 4. Methods ofFUNCTIONAL Analysis. 1. Syntagmatic functional relations: dependency and coordination 2. The verb and its dependants. Thus far we have been looking at linguistic units pr i marily in 'categorial' terms. We have identified categories, like noun or noun phrase, in terms of their internal structure and their distribution within other structures. This is not the only way in which sentence constituents can be viewed, and in this lecture we will consider a different approach. This time we will be concentrating primarily on the functional relationships that can be contracted between constituents. Here we will look at two approaches to description: 1) one describing the various relations established with labels like 'agent' and 'patient' and 2) the other with labels like subject and object. Functional approaches can be considered to be the inverse of the categorial (structural) approach we have adopted thus far. This time, although we shall of course still be interested in constituent structure, we shall consider functional relationships as primary and constituent structure as interpretive of functional structure. Let us first consider the general question of grammatical relations. A traditional view distinguishes between “paradigmatic” and "syntagmatic" relations, and we can exemplify the difference between the functional and the categorial approaches by contrasting the way in which they approach this distinction. Paradigmatic relations are essentially relationships of substitutability, the relation between an item in a particularsyntactic position and other items that might have been chosen in that syntactic position but were not: e.g. speaks, is speaking, was speaking, will speak, will be speaking. Syntagmatic relations are essentially relationships of со - occurrence, the relations contracted between an item in aparticular position in the sentence and other items that occur in other positions in the same sentence, forexample, a verb is transitive or intransitive depending on whether it does or does not need a following NP. The relations are clearly interdependent and all syntactic categories need to be classified in terms of both kinds of relation. In this lecture we shall be primarily interested in syntagmatic functional relations (dependency and coordination). In this case, instead of being concerned with the distribution of constituents, we will be interested in the “dependency” of one constituent on another. In almost all constructions one constituent can be considered to be the "head” and the others 'dependants' of the head. The head will "govern” its dependants and mark this government in various ways. Let’s look at some examples of dependency in the English noun phrase. In noun phrases with the categorial structure [Det (Adj) N (PP)], like the large cat or the cat on the mat the noun is the "head" of the construction and the adjective, determiner and preposition phrase are its 'modifiers'. The modifiers are dependent on and governed by the head. Semantically the head is the salient (= the most prominent) constituent. With adjectives like large the semantic dependency of the adjective on the noun is particularly marked since the interpretation of 'sc a lar' [ei] adjectives crucially depends on the noun modified: 'large' for a cat is larger than 'large' for a mouse, but smaller than 'large' for an elephant. Syntactically the dependency is shown in a number of ways. Tо begin with, the head is obligatory, whereas modifiers are normally optional. So we can find NPs with only a head noun as in Cats sit on mats, but we will not find NPs consisting only of modifiers, as in *The sits on the mat, or *The large sits on the mat (except in the latter case in special circumstances, where a head noun is 'understood'). Dependencies of this kind are often also overtly (відкрито) marked, and when they are, it is the head that governs the marking. Three kinds of dependency marking are typically found: 1) morphological marking; 2) the use of special particles or other words like prepositions and 3) marking by word order. 1) Morphological marking in the NP is usually in the form of 'concord' or agreement': a particular grammatical category of the head is copied on to the dependants. English has few concordial constructions, but where they do exist it is clearly the head that determines the concord. So, those determiners that vary for number (that:those: this:these) take their number from the head noun: those cats not * that cats. 2) English has few special particles reserved as markers of dependency apart from (besides) the 'apostrophe s' used to mark the dependent 'genitive' in structures like John's book or the man next door's car. The language does, however, make extensive use of prepositions for this purpose, as in the other 'genitive' structure in English, pint of milk or President of the United States, and in 'postnominal' PP modifiers like man in the moon and holidays in Greece. 3) The third important marker of dependency is word order, and here again the head is the determining factor. The order of the modifiers is relative to the head. In English determiners and adjectives generally precede the head and PP modifiers invariably follow it. In other languages the order may be different. Characteristically, nouns function as heads and adjectives as modifiers, e.g. a new station – it is the modifier-head pattern (the modifier coming first and the head following it). But this is not invariably the case, and it is interesting to see what happens in atypical constructions. When we meet an NP consisting of two or more nouns the pressure of the modifier-head pattern invites us to interpret the last as head and the others as modifiers: so a bus station is a type of station and a station bus is a type of bus. Similarly if we encounter an NP with two adjectives and no noun, as in the undeserving poor, it too will be interpreted as a modifier-head construction, poor being construed (=interpreted) as the head and undeserving as its modifier. Indeed, in order to maintain the form-function correlation between head and noun, and modifier and adjective, linguists frequently say about an NP like the filthy rich, either that the adjective rich has been 'recategorized' as a noun, or that there is an 'understood' noun. But this confuses category and function, and it is interesting to observe that it is generally the dependency structure and not the lexical class that determines the interpretation and analysis. Coordination (“and”) is an important criterion for class membership. It is equally important when we are discussing dependencies. We know that conjuncts are normally of the same category: nouns coordinate (= conjoin) with nouns (one can say man and women), verbs with verbs, NPs with NPs, VPs with VPs and so on. 'Cross-category' coordination, noun with verb, NP with VP and so on, is usually unacceptable (* men and up). Dependency structures show similar restrictions, and cross-dependency coordination (e.g. subj./obj. +adv.mod.: John bought a car and in the morning instead of subj.+subj. or obj.+obj.) is usually as infelicitous (= unfortunate) as cross-category coordination. So, we can coordinate subject expressions (John and his brother bought a house) or object expressions (John bought a car and a house) but not John bought a car and in the morning. Cross - category coordination is permissible when unlike categories have the same dependency. So, for example, it is possible to coordinate adjectives and PPs providing they are both 'complements': The baby is in bed and asleep (PP and adj), I am going home and tobed (N and PP). In text, cross- dependency coordination is sometimes exploited for a particular rhetorical effect known as ‘zeugma’, as in Mr Pickwick took his hat and his leave. ↓ ↓ material obj. non-material obj. The verb and its dependants Now we will be concerned with what has traditionally been regarded as one of the most important sets of functional relationships to be found in any language: those between a verb and the various NP and PP constituents with whic
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2021-03-10; просмотров: 135; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.221.190.253 (0.345 с.) |