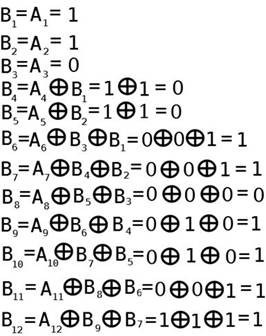Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Дифференциальный манчестерский (Differential Manchester) код.
Как это следует из его названия, является разновидностью манчестерского кодирования. Середину тактового интервала линейного сигнала он использует только для синхронизации, и на ней всегда происходит смена уровня сигнала. Логические 0 и 1 передаются наличием или отсутствием смены уровня сигнала в начале тактового интервала соответственно. Этот код обладает теми же самыми преимуществами и недостатками, что и манчестерский. Но, на практике используется именно дифференциальный манчестерский код. Не смотря на все недостатки код Манчестера раньше (когда высокоскоростные линии были большой роскошью для локальной сети)очень активно использовался в локальных сетях, из-за своей самосинхронизации и отсутствия постоянной составляющей. Он и сейчас находит широкое применение в оптоволоконных и электропроводных сетях. Но в последнее время разработчики пришли к выводу, что лучше все-таки применять потенциальное кодирование, ликвидируя его недостатки средствами, так называемого логического кодирования. Особенности построения цифровых систем передачи (3/3) Логическое кодирование Логическое кодирование выполняется до физического кодирования. Здесь следует подчеркнуть, что на этапе логического кодирования уже не формируется форма сигналов. Здесь просто борются с недостатками методов физического цифрового кодирования - отсутствие синхронизации, наличие постоянной составляющей. Таким образом, сначала с помощью средств логического кодирования формируются исправленные последовательности двоичных данных, которые потом с помощью методов физического кодирования они передаются по линиям связи. Логическое кодирование подразумевает замену бит исходной информации новой последовательностью бит, несущей ту же информацию, но обладающей, кроме этого, дополнительными свойствами, например возможностью для приемной стороны обнаруживать ошибки в принятых данных. Сопровождение каждого байта исходной информации одним битом четности - это пример очень часто применяемого способа логического кодирования при передаче данных с помощью модемов. Другим примером логического кодирования может служить шифрация данных, обеспечивающая их конфиденциальность при передаче через общественные каналы связи.
Разделяют два метода логического кодирования: · избыточные коды · скрэмблирование. Оба метода относятся к логическому, а не физическому кодированию, так как форму сигналов на линии они не определяют. Избыточные коды Избыточные коды основаны на разбиении исходной последовательности бит на порции, которые часто называют символами.Затем каждый исходный символ заменяется на новый, который имеет большее количество бит, чем исходный. Явный пример избыточного кода - логический код 4В/5В. Логический код 4В/5В заменяет исходные символы длиной в 4 бита на символы длиной в 5 бит. Так как результирующие символы содержат избыточные биты, то общее количество битовых комбинаций в них больше, чем в исходных. Таким образом, пяти-битовая схема дает 32 (два в пятой степени) двух разрядных буквенно-цифровых символа, имеющих значение в десятичном коде от 00 до 31. В то время как исходные данные могут содержать только четыре бита или 16 (два в четвертой степени) символов. Поэтому в результирующем коде можно подобрать16 таких комбинаций, которые не содержат большого количества нулей, а остальные считать запрещенными кодами (code violation). Очевидно, что в этом случае длинные последовательности нулей прерываются, и код становится самосинхронизирующимся для любых передаваемых данных. Исчезает также постоянная составляющая, а значит, еще более сужается спектр сигнала. Но этот метод снижает полезную пропускную способность линии, так как избыточные единицы пользовательской информации не несут. Избыточные коды позволяют приемнику распознавать искаженные биты. Если приемник принимает запрещенный код, значит,на линии произошло искажение сигнала. Давайте, еще раз рассмотрим работу логического кода 4В/5В. Преобразованный сигнал имеет 16 значений для передачи информации и 16 избыточных значений. В декодере приемника пять битов расшифровываются как информационные и служебные сигналы. Для служебных сигналов отведены девять символов, семь символов - исключены. Исключены комбинации, имеющие более трех нулей (01 - 00001, 02 - 00010, 03 - 00011, 08 - 01000, 16 - 10000). Такие сигналы интерпретируются символом V и командой приемника VIOLATION - сбой.Команда означает наличие ошибки из-за высокого уровня помех или сбоя передатчика. Единственная комбинация из пяти нулей (00 - 00000) относится к служебным сигналам, означает символ Q и имеет статус QUIET - отсутствие сигнала в линии.
Такое кодирование данных решает две задачи- синхронизации и улучшения помехоустойчивости. Синхронизация происходит за счет исключения последовательности более трех нулей, а высокая помехоустойчивость достигается приемником данных на пяти-битовом интервале. Цена за эти достоинства при таком способе кодирования данных - снижение скорости передачи полезной информации. К примеру, В результате добавления одного избыточного бита на четыре информационных, эффективность использования полосы частот в протоколах с кодом MLT-3 и кодированием данных 4B/5B уменьшается соответственно на 25%. Таблица 1.Схема кодирования 4В/5В
Соответственно этой таблице формируется код 4В/5В, затем передается по линии с помощью физического кодирования по одному из методов потенциального кодирования, чувствительному только к длинным последовательностям нулей - например, с помощью цифрового кода NRZI. Символы кода 4В/5В длиной 5 бит гарантируют, что при любом их сочетании на линии не могут встретиться более трех нулей подряд. Буква В в названии кода означает, что элементарный сигнал имеет 2 состояния (от английского binary – двоичный).Имеются также коды и с тремя состояниями сигнала, например, в коде 8В/6Т для кодирования 8 бит исходной информации используется код из 6 сигналов, каждый из которых имеет три состояния. Как мы говорили, логическое кодирование происходит до физического, следовательно, его осуществляют оборудование канального уровня сети: сетевые адаптеры и интерфейсные блоки коммутаторов и маршрутизаторов. Поскольку, как вы сами убедились, использование таблицы перекодировки является очень простой операцией, поэтому метод логического кодирования избыточными кодами не усложняет функциональные требования к этому оборудованию. Единственное требование - для обеспечения заданной пропускной способности линии передатчик, использующий избыточный код,должен работать с повышенной тактовой частотой. Так, для передачи кодов 4В/5Всо скоростью 100 Мб/с передатчик должен работать с тактовой частотой 125 МГц.При этом спектр сигнала на линии расширяется по сравнению со случаем, когда по линии передается чистый, не избыточный код. Тем не менее, спектр избыточного потенциального кода оказывается уже спектра манчестерского кода, что оправдывает дополнительный этап логического кодирования, а также работу приемника и передатчика на повышенной тактовой частоте. В результате выше изложенного можно сделать вывод: В основном для локальных сетей проще, надежней, качественней, быстро действенней - использовать логическое кодирование данных с помощью избыточных кодов, например, кода 4В/5В, которое устранит длительные последовательности нулей и обеспечит синхронизацию сигнала, потом на физическом уровне использовать для передачи быстрый цифровой код NRZI, нежели без предварительного логического кодирования использовать для передачи данных медленный, но самосинхронизирующийся манчестерский код.
Например, для передачи данных по линии с пропускной способностью 100М бит/с и полосой пропускания 100 МГц, кодом NRZI необходимы частоты 25 - 50 МГц, это без кодирования 4В/5В. А если применить для NRZI еще и кодирование 4В/5В, то теперь полоса частот расширится от 31,25 до62,5 МГц. Что входит в заданную полосу пропускания линии. А для манчестерского кода без применения всякого дополнительного кодирования необходимы частоты от 50 до 100 МГц, и это частоты основного сигнала, но они уже не будут пропускаться линией на 100 МГц. Скрэмблирование Перемешивание данных перед передачей их в линию с помощью потенциального кода является другим способом логического кодирования. Устройства, или блоки, выполняющие такую операцию, называются скремблерами (scramble - свалка, беспорядочная сборка). При скремблировании используется определенный алгоритм, поэтому приемник, получив двоичные данные, передает их на дескремблер, который восстанавливает исходную последовательность бит.Избыточные биты при этом по линии не передаются. Суть скремблирования заключается просто в побитном изменении проходящего через систему потока данных. Практически единственной операцией,используемой в скремблерах, является XOR - «побитное исключающее ИЛИ», или еще говорят - сложение по модулю 2. В таком методе, при сложении двух единиц исключающим ИЛИ отбрасывается старшая единица и результат записывается - 0. Метод скрэмблирования очень прост. Сначала придумывают скремблер. Другими словами придумывают по какому соотношению перемешивать биты в исходной последовательности с помощью «исключающего ИЛИ». Затем согласно этому соотношению из текущей последовательности бит выбираются значения определенных разрядов и складываются по XOR между собой. При этом все разряды сдвигаются на 1 бит, а только что полученное значение («0» или «1») помещается в освободившийся самый младший разряд. Значение, находившееся в самом старшем разряде до сдвига, добавляется в кодирующую последовательность, становясь очередным ее битом. Затем эта последовательность выдается в линию, где с помощью методов физического кодирования передается к узлу-получателю, на входе которого эта последовательность дескрэмблируется на основе обратного отношения.
Рассмотрим один из примеров скрэмблирования. Например, скремблер может реализовывать следующее соотношение:
где Bi - двоичная цифра результирующего кода, полученная на i-м такте работы скремблера, Ai - двоичная цифра исходного кода,поступающая на i-м такте на вход скремблера, Bi-з и Bi-5 - двоичные цифры результирующего кода, полученные на предыдущих тактах работы скремблера, соответственно на 3 и на 5 тактов ранее текущего такта. Члены выражения объединены знаком операции исключающего ИЛИ (сложение по модулю 2). Теперь давайте, определим закодированную последовательность, например, для такой исходной последовательности 110110000001. Скремблер, определенный выше даст следующий результирующий код: B1 = А1 = 1 (первые три цифры результирующего кода будут совпадать с исходным, так как еще нет нужных предыдущих цифр)
Таким образом, на выходе скремблера появится последовательность 110001101111. В которой нет последовательности из шести нулей, присутствовавшей в исходном коде! После получения результирующей последовательности приемник передает ее дескремблеру, который восстанавливает исходную последовательность на основании обратного соотношения.
Существуют другие различные алгоритмы скрэмблирования, они отличаются количеством слагаемых, дающих цифру результирующего кода, и сдвигом между слагаемыми. Как видим, устройство скремблера предельно просто. Более того, тот факт, что каждый бит выходной последовательности зависит только от одного входного бита, еще более упрочило положение скремблеров в защите потоковой передачи данных. Главная проблема кодирования на основе скремблеров - синхронизация передающего (кодирующего) и принимающего(декодирующего) устройств. При пропуске или ошибочном вставлении хотя бы одного бита вся передаваемая информация необратимо теряется. Поэтому, в системах кодирования на основе скремблеров очень большое внимание уделяется методам синхронизации. На практике для этих целей обычно применяется комбинация двух методов: а) добавление в поток информации синхронизирующих битов, заранее известных приемной стороне, что позволяет ей при не нахождении такого бита активно начать поиск синхронизации с отправителем, б) использование высокоточных генераторов временных импульсов, что позволяет в моменты потери синхронизации производить декодирование принимаемых битов информации «по памяти» без синхронизации. Существуют и более простые методы борьбы с последовательностями единиц, также относимые к классу скрэмблирования. Напомню,что все методы логического кодирования направлены на устранение недостатков методов физического цифрового кодирования. Для улучшения кода Bipolar AMI используются два метода, основанные на искусственном искажении последовательности нулей запрещенными символами.
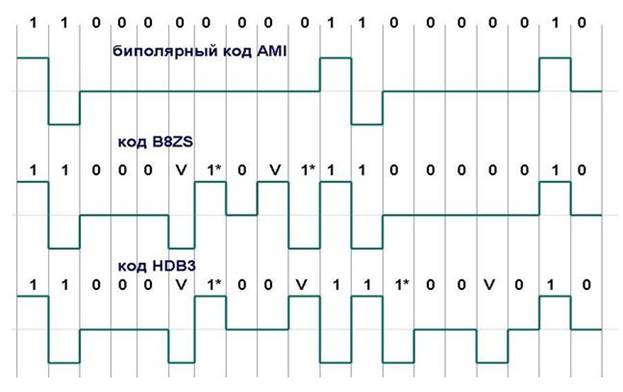
Рисунок 36. Использование метода B8ZS и метода HDB3 для корректировки кода AMI
Исходный код состоит из двух длинных последовательностей нулей: в первом случае - из 8, а во втором - из 5. Код B8ZS (Bipolar with 8-Zeros Substitution) исправляет только последовательности, состоящие из 8 нулей. Для этого он после первых трех нулей в место оставшихся пяти нулей вставляет пять цифр: V-1*-0-V-1*. V здесь обозначает сигнал единицы,запрещенной для данного такта полярности, то есть сигнал, не изменяющий полярность предыдущей единицы, 1* - сигнал единицы корректной полярности, а знак звездочки отмечает тот факт, что в исходном коде в этом такте была не единица, а ноль. В результате на 8 тактах приемник наблюдает 2 искажения - очень маловероятно, что это случилось из-за шума на линии или других сбоев передачи. Поэтому приемник считает такие нарушения кодировкой 8 последовательных нулей, и после приема заменяет их на исходные 8нулей. Код B8ZS построен так, что его постоянная составляющая равна нулю при любых последовательностях двоичных цифр. Код HDB3 (High-Density Bipolar 3-Zeros) исправляет любые четыре подряд идущих нуля в исходной последовательности. Правила формирования кода HDB3 более сложные, чем кода B8ZS. Каждые четыре нуля заменяются четырьмя сигналами, в которых имеется один сигнал V. Для подавления постоянной составляющей полярность сигнала V чередуется при последовательных заменах. Кроме того, для замены используются два образца четырех тактовых кодов. Если перед заменой исходный код содержал нечетное число единиц, то используется последовательность 000V, а если число единиц было четным - последовательность 1*00V. Улучшенные потенциальные коды обладают достаточно узкой полосой пропускания для любых последовательностей единиц и нулей, которые встречаются в передаваемых данных. В результате коды, полученные из потенциального путем логического кодирования, обладают более узким спектром,чем манчестерский, даже при повышенной тактовой частоте. Этим объясняется применение потенциальных избыточных и скрэмблированных кодов в современных технологиях вместо манчестерского и биполярного импульсного кодирования. Компрессия данных Компрессия (сжатие) данных применяется для сокращения времени их передачи. Так как на компрессию данных передающая сторона тратит дополнительное время, к которому нужно еще прибавить аналогичные затраты времени на декомпрессию этих данных принимающей стороной, то выгоды от сокращения времени на передачу сжатых данных обычно бывают заметны только для низкоскоростных каналов. Этот порог скорости для современной аппаратуры составляет около 64 Кбит/с. Многие программные и аппаратные средства сети способны выполнять динамическую компрессию данных в отличие от статической,когда данные предварительно компрессируются (например, с помощью популярных архиваторов типа WinZip, WinRAR и т.п.), а уже затем отсылаются в сеть. На практике может использоваться ряд алгоритмов компрессии, каждый из которых применим к определенному типу данных. Некоторые модемы (называемые интеллектуальными) предлагают адаптивную компрессию, при которой в зависимости от передаваемых данных выбирается определенный алгоритм компрессии. Рассмотрим некоторые из общих алгоритмов компрессии данных. Десятичная упаковка. Когда данные состоят только из чисел,значительную экономию можно получить путем уменьшения количества используемых на цифру бит с 7 до 4, используя простое двоичное кодирование десятичных цифр вместо кода ASCII. Просмотр таблицы ASCII показывает, что старшие три бита всех кодов десятичных цифр содержат комбинацию 011. Если все данные в кадре информации состоят из десятичных цифр, то, поместив в заголовок кадра соответствующий управляющий символ, можно существенно сократить длину кадра. Относительное кодирование. Альтернативой десятичной упаковке при передаче числовых данных с небольшими отклонениями между последовательными цифрами является передача только этих отклонений вместе с известным опорным значением. Такой метод используется, в частности, в методе цифрового кодирования голоса ADPCM, передающем в каждом такте только разницу между соседними замерами голоса. Символьное подавление. Часто передаваемые данные содержат большое количество повторяющихся байт. Например, при передаче черно-белого изображения черные поверхности будут порождать большое количество нулевых значений, а максимально освещенные участки изображения - большое количество байт, состоящих из всех единиц. Передатчик сканирует последовательность передаваемых байт и,если обнаруживает последовательность из трех или более одинаковых байт,заменяет ее специальной трехбайтовой последовательностью, в которой указывает значение байта, количество его повторений, а также отмечает начало этой последовательности специальным управляющим символом. Коды переменной длины. В этом методе кодирования используется тот факт, что не все символы в передаваемом кадре встречаются с одинаковой частотой. Поэтому во многих схемах кодирования коды часто встречающихся символов заменяют кодами меньшей длины, а редко встречающихся - кодами большей длины. Такое кодирование называется также статистическим кодированием. Из-за того, что символы имеют различную длину, для передачи кадра возможна только бит-ориентированная передача. При статистическом кодировании коды выбираются таким образом, чтобы при анализе последовательности бит можно было бы однозначно определить соответствие определенной порции бит тому или иному символу или же запрещенной комбинации бит. Если данная последовательность бит представляет собой запрещенную комбинацию, то необходимо к ней добавить еще один бит и повторить анализ. Например, если при неравномерном кодировании для наиболее часто встречающегося символа «Р» выбран код 1, состоящий из одного бита, то значение 0 однобитного кода будет запрещенным. Иначе мы сможем закодировать только два символа. Для другого часто встречающегося символа «О»можно использовать код 01, а код 00 оставить как запрещенный. Тогда для символа«А» можно выбрать код 001, для символа «П» - код 0001 и т. п. Вообще, неравномерное кодирование наиболее эффективно, когда неравномерность распределения частот передаваемых символов достаточна велика, как при передаче длинных текстовых строк. Напротив, при передаче двоичных данных, например кодов программ, оно малоэффективно, так как8-битовые коды при этом распределены почти равномерно. Одним из наиболее распространенных алгоритмов, на основе которых строятся неравномерные коды, является алгоритм Хаффмана, позволяющий строить коды автоматически, на основании известных частот символов. Существуют адаптивные модификации метода Хаффмана, которые позволяют строить дерево кодов «на ходу», по мере поступления данных от источника. Многие модели коммуникационного оборудования, такие как модемы, мосты, коммутаторы и маршрутизаторы, поддерживают протоколы динамической компрессии, позволяющие сократить объем передаваемой информации в 4, а иногда и в 8 раз. В таких случаях говорят, что протокол обеспечивает коэффициент сжатия 1:4 или 1:8. Существуют стандартные протоколы компрессии, например V.42bis, a также большое количество нестандартных, фирменных протоколов. Реальный коэффициент компрессии зависит от типа передаваемых данных, так, графические и текстовые данные обычно сжимаются хорошо, а коды программ - хуже.
|
|||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2021-03-10; просмотров: 685; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.117.186.92 (0.034 с.) |