Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Автоматы с магазинной памятью – распознаватели КС-языков
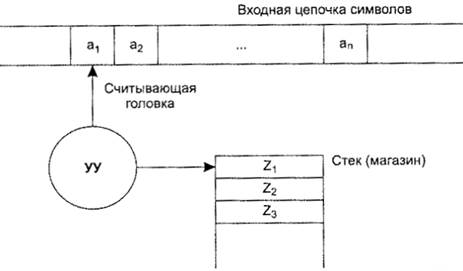
Распознаватели, определяющие КС-языки, моделируются автоматами с магазинной памятью (МПА). Дадим строгое определение такого автомата. Автомат с магазинной памятью (МПА) – это семерка P=(Q,V,Z,d,q0,z0,F), где § Q – множество состояний УУ автомата; § V – конечный входной алфавит (множество допустимых символов); § Z – специальный конечный алфавит магазинных символов автомата (обычно в него входят терминальные и нетерминальные символы грамматики, но могут использоваться и другие символы), VÍZ; § d – функция переходов, отображающая множество Q´(VÈ{e})´Z на конечное множество подмножеств множества (Q´Z*); § q0 – начальное состояние автомата: q0ÎQ; § z0 – начальный символ магазина: z0ÎZ; § F – множество конечных состояний автомата: FÍQ, F¹Æ. Схема автомата с магазинной памятью приведена на рисунке.
В отличие от конечного автомата (КА), рассмотренного в предыдущей главе, МП-автомат имеет «стек» магазинных символов, который играет роль дополнительной, или внешней памяти. Переход МПА из одного состояния в другое зависит не только от входного символа и текущего состояния, но и от содержимого стека. Таким образом, конфигурация МПА определяется уже тремя параметрами: состоянием автомата, текущим символом входной цепочки и содержимым стека. Итак, конфигурация, или мгновенное описание (МО) МПА – это тройка (q,w,a)ÎQ´V*´Z*, где q – текущее состояние УУ, w – непрочитанная часть входной цепочки, a – содержимое магазина. Если w=e, считается, что цепочка прочитана; если a=e, то магазин считается пустым. Начальная конфигурация МПА определяется как (q0,w,z0), wÎV*. Множество конечных конфигураций – как (q, e,z), где qÎF, zÎZ*. Такт работы МП-автомата будем обозначать отношением ├─ на множестве конфигураций и описывать в виде (q,aw,ta)├─ (q¢,w,ga), если (q¢,g)Îd(q,a,t), где q,q¢ÎQ, aÎVÈ{e}, wÎV*, tÎZ, g,a ÎZ*. При выполнении такта автомат, находясь в состоянии q, считывает символ входной цепочки ‘a’ и сдвигает входную головку на одну ячейку вправо, а из магазина удаляет верхний символ, соответствующий условию перехода, и заменяет цепочкой согласно правилу перехода. Первый символ цепочки становится вершиной стека. Состояние автомата изменяется на q¢. Допускаются переходы, при которых считывающая головка не сдвигается и входной символ игнорируется, тогда он становится входным символом при следующем такте, но состояние УУ и содержимое стека может измениться. Такие переходы называются e –тактами. Автомат может проделывать e–такты, когда уже прочёл входную цепочку или же в процессе её прочтения; но, если магазин пуст, следующий такт невозможен.
Итак, находясь в состоянии q и наблюдая символ входной ленты x, МПА на одном такте работы может проделать со стеком в зависимости от правил перехода одно из следующих действий: 1) Дописать в стек c верхним символом a символ x: d(q,x,a)={(q,xa)}. В общем случае может быть дописан другой символ, отличный от прочитанного. 2) Удалить из стека верхний символ a: d(q,x,a)={(q, e)}. 3) Оставить содержимое стека без изменений: d(q,x,a)={(q,a)}. МПА допускает цепочку символов w, если, получив эту цепочку на вход, он может перейти в одну из конечных конфигураций, когда по окончании цепочки автомат находится в одном из конечных состояний: (q0,w,z0)├─*(q, e,z), где qÎF, zÎZ*. После окончания цепочки автомат может проделать некоторое количество e–тактов. Язык, определяемый МП-автоматом P – это множество всех цепочек символов, допускаемых этим автоматом: L(P). Два автомата P1 и P2 эквивалентны, если они определяют один и тот же язык: L(P1)=L(P2). Говорят, что МПА допускает цепочку символов с опустошением магазина, если при окончании разбора цепочки автомат находится в одном из своих конечных состояний, а стек пуст, т.е. получена конфигурация (q, e,e), qÎF. Язык, заданный автоматом P, допускающим цепочки с опустошением стека, обозначается как Le (P). Для любого МП-автомата всегда можно построить эквивалентный ему МПА, допускающий цепочки с опустошением стека: " МПА P $ МПА P¢ ½ L(P)=Le (P¢). Кроме обычного МПА, существует понятие расширенного МПА. Расширенный МПА может заменять не один символ в вершине стека, а цепочку символов конечной длины, на некоторую другую цепочку символов. Для любого расширенного МПА всегда можно построить эквивалентный ему обычный МП-автомат. Следовательно, классы МПА и расширенных МПА эквивалентны.
Пример 1. Построим МПА с опустошением стека, определяющий язык L={0n1n½n³0} – множество цепочек, в которых сначала подряд стоит некоторое количество нулей, а затем так же подряд столько же единиц. Работа данного МП-автомата P должна состоять в том, что он копирует в магазин начальную часть входной цепочки, состоящую из нулей, а затем (как только на входе начнут появляться единицы) устраняет из магазина по одному нулю на каждую прочитанную единицу. Если нули в магазине и единицы на входе закончились одновременно, это означает, что их количества равны. Заметим, что в общем случае символы магазина могут отличаться от символов входной цепочки – например, на каждый прочитанный на входе 0 в магазин может записываться символ ‘a’. Построим этот МПА. P=({q0,q1},{0,1},{Z,0},d,q0,Z,{q0}), где функция переходов имеет вид:
Следует отметить, что при появлении во входной цепочке первой единицы после последовательности нулей состояние МПА должно измениться для того чтобы исключить возможность прочтения нулей вперемешку с единицами. Т.е. одно состояние – то, в котором читаются все нули и записываются в стек (q0), другое (q1)– при котором эти нули из стека удаляются. Пусть входная цепочка имеет вид w=’0011’. Тогда смена конфигураций выглядит следующим образом: (q0,0011,Z)├─(q0,011,0Z)├─(q0,11,00Z)├─(q1,1,0Z)├─(q1, e,Z)├─(q0, e,e). Цепочка допущена заданным автоматом. Утверждение 1. Для произвольной КС-грамматики всегда можно построить МП-автомат, распознающий задаваемый этой грамматикой язык. 2. Для произвольного МП-автомата всегда можно построить КС-грамматику, которая будет задавать язык, распознаваемый этим автоматом. МПА называется недетерминированным, если из одной и той же его конфигурации возможен более чем один следующий переход. МПА называется детерминированным, если из любой его конфигурации возможно не более одного следующего такта. Класс ДМП-автоматов и соответствующих языков заметно уже, чем весь класс КС-языков и соответственно, МП-автоматов. В отличие от КА, не для каждого МПА возможно построить эквивалентный ему ДМП-автомат. ДМП-автоматы определяют особый подкласс среди КС-языков, называемый детерминированными КС-языками. Все языки, относящиеся к этому классу, могут быть построены с помощью однозначных КС-грамматик, следовательно, они играют особую роль в теории языков программирования. Поэтому ДМПА необходимы при создании компиляторов. На основе ДМПА может быть построен синтаксический распознаватель любого языка программирования. Свойства КС-языков Основное свойство КС-языков: Класс КС-языков замкнут относительно операции подстановки. Это означает, что, если в каждую цепочку символов КС-языка вместо некоторого символа подставить цепочку символов из другого КС-языка, то полученная цепочка также будет принадлежать КС-языку. Класс КС-языков замкнут относительно операций объединения, конкатенации, итерации, изменения имен символов. Замечание: Класс КС-языков не замкнут относительно операции пересечения и операции дополнения. Пример 2. Пусть есть два языка L1={anbnci½n>0, i>0} и L2={aibncn½n>0, i>0}. Оба эти языка являются КС, но, если взять их пересечение, то получим язык L=L1ÇL2={anbncn½n>0}, который уже не является КС-языком.
Для КС-языков разрешимы проблемы пустоты языка и принадлежности заданной цепочки языку – для их решения достаточно построить МПА, распознающий данный язык. Но проблема эквивалентности двух произвольных грамматик является неразрешимой. Неразрешима и более узкая проблема – эквивалентности заданной произвольной КС-грамматики и произвольной регулярной грамматики. Тем не менее, для некоторых КС-грамматик можно построить эквивалентную им однозначную грамматику. Детерминированные КС-языки представляют собой более узкий класс в семействе КС-языков. Этот класс не замкнут относительно операций объединения и пересечения, хотя, в отличие от всех КС-языков в целом, замкнут относительно операции дополнения. Для класса детерминированных КС-языков разрешима проблема однозначности. Доказано, что, если язык может быть распознан с помощью ДМПА, он может быть описан с помощью однозначной КС-грамматики. Поэтому данный класс используется для построения синтаксических конструкций языков программирования. Как и в случае с регулярными языками, для проверки того факта, что некоторый язык не принадлежит классу КС-языков, служит лемма о разрастании КС-языков. Она выполняется для любого КС-языка. Если лемма не выполняется, то это означает, что язык не относится к типу контекстно-свободных. Лемма о разрастании КС-языков: Если взять достаточно длинную цепочку символов, принадлежащую произвольному КС-языку, то в ней всегда можно выделить две подцепочки, длина которых в сумме больше нуля, таких, что, повторив их сколь угодно большое число раз, можно получить новую цепочку символов, принадлежащую данному языку. Формальная запись: Если L – это КС-язык, то $ k>0, kÎN ½если ½a½³ k и aÎL, то a=bdgjm, где dj¹e, ½dgj½£ k и bdigj imÎL " i ³0. Пример 3. Проверим, является ли язык L={anbncn½n>0} КС-языком. Пусть это так, тогда для него должна выполняться лемма о разрастании КС-языков. Значит, существует некоторая константа k, о которой идет речь в этой лемме. Возьмем цепочку этого языка a=akbkck, ½a½> k. Если её записать в виде a=bdgjm, то по условиям леммы ½dgj½£ k, следовательно, цепочка dgj не может содержать вхождения всех трех символов ‘a’, ‘b’, ‘c’, т.е. в ней нет или ‘a’, или ‘c’. Рассмотрим цепочку bd0gj0m=bgm. По условиям леммы, она должна принадлежать языку L, но она содержит либо k символов ‘a’, либо k символов ‘c’. Но ½bgm½< 3k, следовательно, какие-то из символов языка входят в цепочку меньшее число раз, чем другие. Такая цепочка не может принадлежать заданному языку. Следовательно, язык L не является КС-языком.
4.2.1.3. Контрольные вопросы 1. Чем отличается автомат с магазинной памятью от конечного автомата и что у них общего? 2. В чём особенность такта работы МПА в случае, когда не принимается во внимание входной символ? 3. Чем отличается конфигурация МПА от конфигурации КА? 4. Может ли МПА работать при пустом стеке? А при пустой входной цепочке? 5. Что такое расширенный МПА? 6. Какие МПА являются эквивалентными? 7. К каким способам задания языка относится МПА? 8. Языки какого типа задают автоматы с магазинной памятью? 9. Какие действия со стеком может выполнять МПА на одном такте работы? 10. Построить ДМП-автоматы с опустошением стека, допускающие следующие языки: а) {0 k 1 n ½ k ³ n > 0}; б) {0 k 1 n ½ 0 < k £ n}; в) {w½wÎ{a, b}* и количество символов ’а’ и ’b’ одинаково}; г) {0 n 1 n 0 k 1 k}; д) {w½wÎ{a, b}* и количество символов ’а’ и ’b’ четно}. 11. Как можно установить, относится ли язык к контекстно-свободному типу? 12. В чём отличие леммы о разрастании КС-языков от соответствующей леммы для регулярных языков? 4.2.2. Преобразование КС-грамматик 4.2.2.1. Цели преобразований грамматик В общем случае для КС-грамматик невозможно проверить их однозначность и эквивалентность. Но для конкретных случаев бывает можно и нужно привести заданную грамматику к некоторому определённому виду таким образом, чтобы получить грамматику, эквивалентную исходной. Заранее определённый вид зачастую позволяет упростить работу с языком и построение распознавателей для него. Итак, преобразования грамматик могут преследовать две цели: 1) упрощение правил грамматики; 2) облегчение создания распознавателя языка. Не всегда эти цели удается совместить, тогда необходимо исходить из того, что является главным в конкретной задаче. В теории языков программирования основой является создание компилятора для языка, поэтому главной становится вторая цель. Следовательно, можно пренебречь упрощением правил (и даже смириться с некоторым их усложнением), если при этом удастся упростить построение распознавателя языка. Все преобразования грамматик условно разбиваются на две группы: 1. исключение из грамматики тех правил и символов, без которых она может существовать (позволяет упростить правила); 2. изменение вида и состава правил грамматики. При этом могут появиться новые правила и нетерминальные символы (упрощений правил нет). Приведённые грамматики Приведёнными (или грамматиками в каноническом виде) называются грамматики, которые не содержат недостижимых и бесплодных символов, циклов и пустых правил (e-правил). Рассмотрим некоторую грамматику G(VT,VN,P,S) и дадим необходимые определения. Нетерминальный символ AÎVN называется бесплодным (или бесполезным), если из него нельзя вывести ни одной цепочки терминальных символов, т.е. {a½AÞ*a, aÎVT*}=Æ.
В простейшем случае символ является бесплодным, если во всех правилах, где он находится в левой части, он встречается также и в правой части. В более сложных случаях бесполезные символы могут находиться в некоторой взаимной зависимости, порождая друг друга. Если из правил грамматики удалить такие символы, то эти правила станут проще. Символ x Î(VTÈVN) называется недостижимым, если он не встречается ни в одной сентенциальной форме грамматики G. Это значит, что он не может появиться ни в одной цепочке вывода. Для исключения всех недостижимых символов не обязательно рассматривать все сентенциальные формы грамматики, достаточно воспользоваться специальным алгоритмом удаления недостижимых символов. После удаления таких символов правила также упрощаются. e -правилами, или правилами с пустой цепочкой, называются все правила грамматики вида A®e, AÎVN. Грамматика G называется грамматикой без e -правил, если в ней нет правил вида (A®e), AÎVN, A¹S, и существует только одно правило (S®e)ÎP, если eÎL(G) и при этом S не встречается в правой части ни одного правила грамматики G. Для упрощения процесса построения распознавателя цепочек языка L(G) любую грамматику целесообразно привести к виду без e-правил. Циклом в грамматике G называется вывод вида AÞ*A, AÎVN. Очевидно, что такой вывод бесполезен, поэтому в распознавателях КС-языков рекомендуется избегать возможности появления циклов. Циклы возможны в случае существования в грамматике цепных правил вида A®B, A,BÎVN. Достаточно устранить цепные правила из набора правил грамматики, чтобы исключить возможность появления циклов. Для того чтобы преобразовать произвольную КС-грамматику к каноническому виду, необходимо выполнить следующие действия (причём именно в том порядке, каком они перечислены): § удалить все бесплодные символы; § удалить все недостижимые символы; § удалить e-правила; § удалить цепные правила. Для каждого из названных действий существует свой алгоритм. Рассмотрим эти алгоритмы в том порядке, каком требуется их реализовывать.
|
|||||||||||||||
|
|
Последнее изменение этой страницы: 2021-03-09; просмотров: 504; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.225.31.159 (0.044 с.) |