
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Сортировка методом попарной перестановки (“метод пузырька”).Стр 1 из 5Следующая ⇒
Основные понятия сортировки и поиска. Одной из составляющих частей Автоматизированных Информационных Систем (АИС) являются данные и сведения, циркулирующих в АИС или хранящихся в памяти ЭВМ, и которые структурируется в информационные массивы. Структуры немашинных информационных массивов отражают представление реального мира, в то время как машинные информационные массивы отражают абстрактное (логическое) и физическое представление данных. Для понимания процессов обработки информации необходимы следующие категории данных. Файл представляет собой совокупность записей, имеющих одинаковое смысловое содержание. Это может быть, например, файл цен на изделия, содержащий перечень всех изделий и их цены. Список это область хранения файла в памяти ЭВМ. Число ячеек в списке больше или равно числу записей в файле. Одна запись отражает один объект предметной области и содержит поля, число которых равно числу атрибутов, описывающих объект. Сущность решения многих информационно-логических задач, возникающих при функционировании АИС, сводится к классификации объектов, т.е. разделению их на виды, типы, классы и т.п., в зависимости от их свойств и признаков. Такие задачи характеризуются большим объемом запоминаемой информации и частым обращением к хранимой информации. При решении подавляющего большинства задач применяются общие, повторяющиеся процессы обработки информации. Широко распространенными являются: упорядочивание массивов, поиск информации и др. Сортировка. Одним из наиболее важных и распространенных процессов обработки информации является сортировка, под которой понимается упорядочение элементов информационного массива по определенному признаку в возрастающем или убывающем порядке. Сортировка стала важным предметом вычислительной математики в основном потому, что она занимает до 25% всего времени вычислений. Сортировка применяется при трансляции программ, когда составляются таблицы символов; она также является важным средством для ускорения работы практически любого алгоритма, в котором часто нужно обращаться к определенным элементам. Если в качестве элемента сортировки выступают записи, то сортировка выполняется в соответствии со значениями их полей, специально введенными в записи и предназначенными для их идентификации. Совокупность полей (или одно поле), идентифицирующих запись, называется ключевым полем. Поле ключа содержит положительное число, обычное целое и записи упорядочиваются по значению ключа.
Пусть надо упорядочить N записей a1, a2, …, aN. Совокупность N записей назовем файлом. Каждая запись ai имеет ключ Кi, который управляет процессом сортировки. Отношение порядка “<” на множестве ключей необходимо вводить таким образом, чтобы для любых трех значений ключей а, b, c выполнялись следующие условия: 1. Справедливо одно и только лишь одно из соотношений a<b, a=b, b<a (закон трихотомии). 2. Если a<b и b<с, то a<с (закон транзитивности). Эти два свойства определяют математическое понятие линейного упорядочения. Под задачей сортировки следует понимать нахождение такой перестановки записей a1, a2, …, aN, после которой ключи расположились бы в неубывающем порядке: К1£ К2£ …£ КN. Сортировка называется устойчивой, если в результате сортировки записи с одинаковыми ключами остаются в прежнем порядке, т.е. ai £ aj, если Кi = Кj и i<j. В ряде случаев может потребоваться физическое перемещение записи в памяти так, чтобы их ключи были упорядочены; в других случаях достаточно создать вспомогательную таблицу, которая некоторым образом описывает перестановку и обеспечивает доступ к записям в соответствии с порядком их ключей. Сортировка применяется, например, в следующих ситуациях: а) решение задачи “группировки”, когда нужно собрать вместе все элементы с одинаковым значением некоторого признака; б) если два или более файла отсортировать в одном и том же порядке, то можно отыскать в них все общие элементы за один последовательный просмотр всех файлов, без возвратов; в) сортировка существенно помогает при поиске информации. Организация сортировки существенно зависит от количества элементов в массивах и от того, какая память используется для хранения и преобразования массивов в процессе сортировки. Будем условно называть “малыми” такие массивы, объем которых не превосходит емкость оперативной памяти (ОЗУ). Сортировку таких массивов внутри ОЗУ называют внутренней сортировкой.
При сортировке “больших” массивов необходимо применять внешние ЗУ ЭВМ. Такая сортировка называется внешней и состоит из нескольких этапов. Весь массив разбивается на несколько подмассивов, не превышающих емкость ОЗУ, каждый из которых упорядочивается в ОЗУ методом внутренней сортировки, а затем производится различными методами слияние отсортированных подмассивов в один массив. Таким образом, внутренняя сортировка помимо самостоятельного применения, является необходимым этапом большинства известных методов сортировки. Поэтому в лабораторных работах более подробно рассматриваются методы внутренней сортировки. В качестве основной характеристики процесса сортировки выделяется быстродействие. Так как при сортировке необходимо производить сравнение признаков (например, ключей) и изменять относительное расположение элементов массива, то основными операциями являются сравнения и обращения к памяти. Число других операций (переадресации, пересылки, условного перехода и др.) пропорционально количеству основных операций. Следовательно, производительность методов внутренней сортировки (при прочих фиксированных условиях) определяется количеством операций сравнения и обращения к памяти, необходимых для сортировки массива (см. таблицу 1.1). Таблица 1.1.
где C – количество необходимых сравнений ключей; М – количество пересылок элементов; Min, Max, Средн. – значения для всех n! перестановок элементов. Эти формулы дают лишь приблизительную оценку эффективности как функции от n. Они допускают классификацию алгоритмов сортировки на простые (n2) и усовершенствованные, или “логарифмические” (n log n). Как правило, для выполнения внутренней сортировки помимо памяти, занятой программой сортировки и сортируемым массивом, требуется дополнительный объем памяти – резерв памяти. Его объем, в зависимости от методов сортировки, колеблется в широких пределах и существенно влияет на объем оперативной памяти, используемой для внутренней сортировки. Таким образом, критерий быстродействия для оценки внутренней сортировки может быть сведен к следующим показателям: необходимое число сравнений и обращений к памяти; необходимый объем памяти. С другой стороны, необходимо иметь в виду, что подсчет числа сравнений – не единственный способ измерить эффективность метода сортировки. Введем значения: N (записей) – емкость массива, подлежащего внутренней сортировке; S (записей) – емкость памяти, требуемой для сортировки. DS = S – N - резерв памяти; С – среднее количество попарных сравнений, необходимых для сортировки массива; D – среднее количество обращений к памяти (чтение или запись элемента массива). Величина С зависит от метода сортировки и при рациональном выборе достигает некоторого минимума Сmin. Для минимального числа сравнений, достаточного для сортировки N элементов, имеется следующее соотношение:
где [x] – ближайшее целое, большее или равное х. Соотношение (1.1) часто называют “теоретико-информационной нижней оценкой”. По формуле Стирлинга
где О(1) – обозначение остатка. При выполнении попарных сравнений, каждое из которых имеет два исхода, необходимое число сравнений для полного упорядочения совокупности из N случайных чисел с достаточной для практика точности можно считать равным:
Идеальным можно считать такой метод сортировки, при котором
Для оценки эффективности конкретных алгоритмов сортировок проводятся специальные исследования (см. список литературы). Следует иметь в виду, что требование 1.4. противоречиво. Действительно, пусть для внутренней сортировки применяется алгоритм, требующий минимального С, причем в процессе сортировки производятся непосредственные пересылки элементов массива. Тогда, если на некотором этапе сортировки для какого-либо элемента массива найден адрес, соответствующий положению этого элемента внутри упорядоченного массива, то либо найденный адрес занят – требуются дополнительные пересылки информации для освобождения его, либо свободен, для чего необходим резерв памяти. Если в процессе сортировки не производятся непосредственные пересылки элементов сортируемого массива, то резерв памяти необходим для построения вспомогательных таблиц, шкал и т.д. Существует большое множество алгоритмов внутренней сортировки, причем каждый метод имеет свои собственные, одному ему присущие достоинства и недостатки. Эффективность алгоритма сортировки может зависеть от множества факторов: от числа сортируемых элементов; все ли элементы могут быть помещены в доступную оперативную память; степени отсортированности элементов; каковы диапазон и распределение значений сортируемых элементов; каковы длина, сложность и требования к памяти алгоритма сортировки; предполагается ли, что элементы будут периодически исключаться или добавляться; можно ли элементы сравнивать параллельно и т.д. Выделим следующие шесть основных методов внутренней сортировки: 1. Метод вставки. Элементы просматриваются по одному, на i-том этапе i-тый элемент помещается на подходящее место между (i-1) уже отсортированных элементов.
2. Обменная сортировка. Если два элемента расположены не по порядку, то они меняются местами. Этот процесс повторяется до тех пор, пока элементы не будут упорядочены. 3. Метод выбора. На i-том этапе из неотсортированных элементов выбирается i-тый наибольший (или наименьший) элемент и помещается на соответствующее место. 4. Распределение. Элементы распределяются по группам, и содержимое групп затем объединяются таким образом, чтобы частично отсортировать все множество элементов. Процесс повторяется до тех пор, пока множество не будет отсортировано полностью. 5. Сортировка подсчетом. Каждый элемент сравнивается со всеми остальными; окончательное положение элемента определяется подсчетом числа меньших ключей. 6. Слияние. Множество элементов разбивается на группы, которые сортируются и затем объединяются в одну группу. Многие алгоритмы сортировки могут быть отнесены одновременно к нескольким из основных методов, т.е. они являются гибридными. Поиск. Одним из наиболее важных и широко распространенных процессов обработки информации является поиск. Задача поиска в информационном массиве (ИМ) состоит из нахождения элемента, который удовлетворяет некоторому заданному условию. Предположим, что в памяти хранится ИМ из N элементов. Если в качестве элементов выступают записи, тогда имеем файл из N записей. Каждая запись содержит поле ключа, причем все N значений ключей различны, т.е. записи определяются ключом однозначно. В алгоритмах поиска присутствует так называемый аргумент поиска z, который является ключом искомой записи. Задача поиска состоит в отыскании записи, имеющей ключ Z. Поиск может осуществляться по первичному ключу, который однозначно определяет запись в файле. Но иногда необходимо вести поиск, основываясь не на первичных ключах, а на значениях других полей записи, которые называются атрибутами или вторичными ключами записи. Выборка по вторичным ключам соответствует вторичным методам доступа и допускает одинаковые значения вторичных ключей для нескольких записей, т.е. из файла выбираются записи с одинаковыми значениями атрибутов. Например, из файла СЛУЖАЩИЕ выбираются служащие одного года рождения. Существует две возможности окончания поиска: поиск удачен, т.е. положение записи, содержащей z, определено, или поиск неудачен, т.е. аргумент z не может быть найден ни в одной из записей. Классификацию методов поиска можно осуществлять различными способами. Существуют методы поиска, использующие истинные ключи, и методы, использующие преобразованные ключи. К первой группе следует отнести: I. Метод последовательного поиска. Элементы ИМ просматриваются последовательно в соответствии с отношением следования, определенном на данном множестве элементов. II. Метод бинарного поиска. Аргумент поиска (ключ) сравнивается со средним элементом из упорядоченной последовательности. Выделяется один интервал из двух, в котором должен содержаться искомый элемент. Для выбранного интервала изложенный способ повторяется.
Ко второй группе следует отнести: I. Метод позиционной адресации, основанный на непосредственной выборке по номеру, определяемому функцией преобразования ключей. Эта функция реализует взаимооднозначное соответствие 1:1 между множеством ключей и множеством адресов записей. II. Метод вычисления адреса, предполагающий преобразование ключа элемента в адрес или номер в памяти с помощью хеш-функции, которая реализует соответствие типа М:1 между множеством ключей и множеством адресов записей. Выбор стратегии поиска существенно зависит от структуры данных, способа их организации и условий, по которым осуществляется выбор элементов. Качество процедуры поиска характеризуется быстродействием. При выполнении многих программ большая часть времени их исполнения тратится на поиск. Замена плохого метода поиска на лучший часто ведет к существенному увеличению скорости работы. Целью цикла предложенных лабораторных работ является более подробное изучение алгоритмов некоторых из вышеупомянутых методов внутренней сортировки и поиска в информационных массивах. Лабораторная работа № 1. Методические указания. Сортировка данным методом выполняется путем многократного просмотра множества ключей. Мы будем рассматривать числовые ключи, поэтому в дальнейшем будут рассматриваться массивы чисел. При каждом последовательном просмотре массива сравниваются соседние числа (ключи). Если числа в паре расположены в порядке возрастания, оставляем их без изменения; в противном случае меняем их местами. Затем (в любом случае) переходим к следующей паре. Сортировка считается оконченной, если в ходе просмотра не была произведена ни одна перестановка. В результате на первом шаге процесса (после 1-го просмотра) на последнее место в массиве из N чисел ставится самое большое число и при следующем просмотре чисел массива анализируется (N-1) чисел, при третьем просмотре (N-2) чисел и т.д. Таким образом, сокращается время упорядочения. Этот метод называют иначе “метод пузырька”: большие элементы (записи с большими ключами), подобно пузырькам, “всплывают” на соответствующую позицию. Приведем пример сортировки массива из 6 чисел: Исходный массив 1 7 6 4 2 5 6 7 4 7 2 7 5 7 после первого просмотра 1 6 4 2 5 7 4 6 2 6 5 6 после второго просмотра 1 4 2 5 6 7 2 4 после третьего просмотра 1 2 4 5 6 7. Сортировка окончена, так как во время четвертого просмотра не было совершено ни одной перестановки. Количество сравнений определяется максимальным количеством инверсий:
где
Если k=N-1, то формула принимает вид
Среднее количество сравнений может быть подсчитано по формуле, исходя из того, что среднее количество инверсий равно
Приведенные формулы указывают на возможную оценку количества сравнений при использовании метода пузырька. Блок-схема сортировки представлена в Приложении 1. Порядок выполнения работы. 1. Ознакомится с общими методическими указаниями и с описаниями данной лабораторной работы. Ознакомиться по литературе с основными понятиями обработки информационных массивов, алгоритмами внутренней сортировки и требованиями к ним. 2. Изучить блок-схему сортировки “методом пузырька”. 3. Каждому студенту получить номер варианта и из таблицы 2.1. выбрать соответствующий неупорядоченный массив из N = 8 чисел. Этот массив чисел используется для сортировки различными методами в лабораторных работах 1…4. Таблица 2.1
4. Написать последовательность упорядочения заданного массива методом пузырька (см. пример сортировки). 5. Произвести подсчет числа сравнений и количества пересылок, необходимых при сортировке вашего варианта массива, и провести сравнение с теоретическими данными. Дать оценку эффективности рассматриваемого алгоритма сортировки. 6. Провести сортировку заданного массива на ЭВМ. Содержание отчета. 1. Краткое изложение задачи внутренней сортировки, рассматриваемого метода сортировки, целей и задач лабораторной работы. 2. Блок-схема алгоритма рассмотренной сортировки. 3. Таблица последовательности сортировки заданного массива чисел с указанием номеров просмотров (сортировка вручную). 4. Анализ эффективности рассмотренного алгоритма сортировки с подсчетом числа сравнений и количества пересылок при ручной сортировке. 5. Результаты сортировки на ЭВМ (распечатка с комментариями). Контрольные вопросы. 1. Что понимается под обработкой информационных массивов? 2. Дайте определение массива. Приведите примеры. 3. Дайте определение файлу, записи, полю, ключу. 4. Чем отличается файл от списка? 5. Что такое упорядочение информационного массива? 6. Чем отличается внутренняя и внешняя сортировка? 7. Каковы критерии качества процесса внутренней сортировки массива? 8. Каковы требования к идеальному алгоритму внутренней сортировки? 9. Какие алгоритмы внутренней сортировки вам известны? 10. Что такое отношение порядка? 11. Чем определяется устойчивость сортировки? Проанализируйте с этой точки зрения метод пузырька. Лабораторная работа № 2. Методические указания Этот метод основан на том, что j-ый ключ в окончательно упорядоченной последовательности превышает ровно (j-1) из остальных ключей. Идея состоит в том, чтобы сравнить попарно все ключи и подсчитать, сколько из них меньше каждого отдельного ключа. Очевидный способ выполнить сравнение: сравнить Kj c Ki при 1 £ j £ N и при 1 £ i £ N, но легко видеть, что более половины этих действий излишне, поскольку не нужно сравнивать ключ сам с собой и после сравнения Ka c Kb уже не надо сравнивать Kb с Кa. Поэтому достаточно сравнить Kj c Ki при 1 £ j £ i и при 1 £ i £ N. Приведем пример сортировки массива из 6 чисел: Исходный массив 23 4 49 8 12 5 Начальные значения счетчиков Ch(i) 0 0 0 0 0 0 Значения счетчиков после 1-го цикла 1 0 1 1 1 1 Значения счетчиков после 2-го цикла 2 0 2 1 3 Значения счетчиков после 3-го цикла 3 0 3 2 Значения счетчиков после 4-го цикла 3 0 5 Значения счетчиков после 5-го цикла 4 0 Результат: 4 0 5 2 3 1 Заметим, что в этом алгоритме записи не перемещаются, а создается массив Ch(i), определяющий конечное расположение записей. Блок-схема внутренней сортировки методом подсчета представлена в Приложении 2. Порядок выполнения работы. 1. Ознакомится с общими методическими указаниями и с описанием лабораторной работы. 2. Изучить блок-схему сортировки методом подсчета. 3. Написать последовательность упорядочения заданного массива методом подсчета (см. пример сортировки). 4. Провести сортировку заданного массива на ЭВМ. Содержание отчета. 1. Краткое изложение задачи внутренней сортировки, рассматриваемого метода сортировки, целей и задач лабораторной работы. 2. Блок-схема алгоритма рассмотренной сортировки. 3. Таблица последовательности сортировки заданного массива чисел с указанием номеров просмотров (сортировка вручную). 4. Результаты сортировки на ЭВМ (распечатка с комментариями). 5. Сравнительный анализ (конкретный по полученным данным) метода подсчетом и метода пузырька. Обобщение анализа на большие массивы данных. Контрольные вопросы. 1. В чем особенность сортировки методом подсчета? 2. Проанализируйте с точки зрения устойчивости метод сортировки подсчетом. Является ли он устойчивым? Лабораторная работа № 3. Методические указания Одно из важнейших семейств методов сортировки основано на использовании следующей идеи: предполагается, что перед рассмотрением записи aj предыдущие записи a1, …, aj-1 уже упорядочены, и aj вставляется в соответствующее место. На основе этой схемы возможны несколько вариаций. В лабораторной работе изучается разновидность, которая называется методом простых вставок. Алгоритм сортировки методом простых вставок заключается в следующем. Пусть Удобно совмещать операции сравнения и перемещения, перемежая их друг с другом. Поскольку запись aj как бы “проникает на положенный ей уровень”, этот способ называют “просеиванием” или “погружением”. Приведем пример сортировки массива из 5 чисел: Исходный массив 5 2 4 1 3
Массив упорядочен 1 2 3 4 5 Знак “: ” означает сравнение. Стрелкой показана пересылка элемента. Эффективность алгоритма зависит от числа сравнений и пересылок. Грубую оценку среднего числа сравнений можно произвести очень просто. Действительно, когда обрабатывается j-я запись, ее ключ сравнивается в среднем примерно с j/2 ранее отсортированными ключами; поэтому общее число сравнений приблизительно равно
Можно более точно оценить количество сравнений, используя понятие инверсии. Число проверок условий Кi<Kj зависит от числа инверсий в сортируемом множестве. Количество сравнений
где aj – число инверсий (число элементов, больших Кj и стоящих слева от него). Так число инверсий aj и аj связано с номером следующим соотношением:
Пусть
Минимальное количество сравнений определяется формулой
где aj = 0, т.е. массив упорядочен. Среднее количество сравнений определяется из предположения, что среднее количество инверсий равно
Тогда среднее количество сравнений задается формулой
Усовершенствованиями метода простых вставок являются методы: бинарных вставок, двухпутевые вставки, метод Шелла, вставки в список и др. Познакомиться с этими методами и их сравнительными оценками можно по литературе. Блок-схема данного метода представлена в Приложении 3. Порядок выполнения работы. 1. Ознакомится с описанием лабораторной работы №3. Изучить алгоритм сортировки методом вставки и познакомиться по литературе с алгоритмами, использующими метод вставки. 2. Изучить блок-схему сортировки методом вставки. 3. Написать последовательность упорядочения заданного массива методом вставки (см. пример сортировки). 4. Произвести подсчет числа сравнений и количества пересылок, полученных при сортировке вашего варианта массива методом вставки. Сравните полученные данные при сортировке этим методом с сортировками методом пузырька (лабораторная работа №1) по эффективности. 5. Дать сравнительный анализ результатов сортировки вручную с теоретическими результатами расчетов, которые необходимо провести. 6. Провести сортировку заданного массива на ЭВМ. Содержание отчета. 1. Краткое изложение рассматриваемого метода сортировки, целей и задач лабораторной работы. 2. Блок-схема алгоритма рассмотренной сортировки. 3. Таблица последовательности сортировки вручную заданного массива чисел. 4. Анализ эффективности алгоритма метода вставок с подсчетом числа сравнений и количества пересылок при ручной сортировке. 5. Сравнительный анализ с теоретическими данными и с методами пузырька и выбора. 6. Результаты сортировки на ЭВМ (распечатка с комментариями). Контрольные вопросы. 1. Является ли метод сортировки простыми вставками устойчивым? 2. Сравните сложность программы для методов пузырька и вставок. 3. Требуется ли при использовании метода вставок резерв памяти? 4. Что такое число инверсий? 5. Зависит ли число сравнений и пересылок от исходного массива чисел? 6. Для чего необходима сортировка? 7. Что такое “бинарные вставки” и “двухпутевые вставки”? Лабораторная работа № 4. Методические указания. В данной лабораторной работе, последней из цикла, на примере сортировки Шелла вы получите представление о том, как можно на базе основного метода значительно усовершенствовать способ сортировки. Для алгоритма сортировки, который каждый раз перемещает запись только на одну позицию (как в методе простых вставок), среднее время работы будет в лучшем случае пропорционально N2. Поэтому если мы хотим получить метод, существенно превосходящий по скорости простые вставки, то необходим некоторый механизм, с помощью которого записи могли бы перемещаться большими скачками, а не короткими шажками. Такой метод впервые был предложен Л.Шеллом в 1959г. Метод Шелла часто называют “сортировкой с убывающим шагом”. Метод Шелла заключается в том, что сортируемый массив разбивается на группы, а затем каждая группа сортируется методом простых вставок. Процесс разбиения массива на группы уже большего размера и сортировка элементов в них, будут продолжаться до тех пор, пока все элементы не будут объединены в одну группу. Алгоритм метода Шелла можно определить следующим образом. Для управления процессом сортировки используется вспомогательная последовательность убывающих шагов he, e = t, t-1, t-2,…,1; причем последний шаг h1 всегда равен единице h1=1. Весь процесс сортировки разбивается на отдельные просмотры массива. При первом просмотре методом простых вставок сортируются элементы, отстоящие друг от друга на ht позиций. В результате получаем упорядоченные подгруппы элементов, значения ключей которых удовлетворяют соотношению
При 2-м просмотре методом простых вставок сортируются элементы, отстоящие друг от друга на ht-1 позиций. В результате получаем упорядоченные подгруппы элементов, в каждой из которых ключи упорядочены, т.е. удовлетворяют соотношению При последнем просмотре устанавливается шаг h1 и производится сортировка массива простыми вставками, которая ничем не отличается от сортировки, рассмотренной в лабораторной работе №3. Если назвать каждый просмотр “h – сортировкой”, то сортировка методом Шелла состоит из ht сортировки, за которой следует ht-1 сортировка, …, за которой следует h1 сортировка. Подфайл, в котором Ki £ Ki+h при 1 £ i £ N-h, будем называть h-упорядоченным. Эффективность сортировки методом Шелла достигается за счет того, что в каждом из промежуточных процессов сортировки участвуют либо сравнительно короткие подфайлы, либо уже сравнительно хорошо упорядоченные подфайлы, поэтому записи довольно быстро достигают своего конечного положения. Последовательность шагов he может быть любой, в которой последний шаг h1=1. От выбранной последовательности шагов зависит время работы алгоритма. Для примеров будем пользоваться последовательностью: 8, 4, 2, 1. Лучшие результаты получаются при шагах: 7, 5, 3, 1. Если шаги выбирать из соотношения
то максимальное время работы алгоритма Шелла (оценка) есть N3/2. Преимущества алгоритма Шелла проявляются при больших массивах. Число сравнений и перемещений снижается примерно до C = N1,3 для тех значений N, которые встречаются на практике; при Nॠэто число можно сократить до порядка C = N(log2N)2. Приведем пример сортировки массива из 8 чисел (he=4, 2, 1): Исходный массив: 7 3 5 1 2 8 4 6
ht = h4 – разбиение 7 3 5 1 2 8 4 6
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2021-01-08; просмотров: 280; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.141.200.180 (0.15 с.) |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
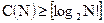
 (1.1)
(1.1) (1.2)
(1.2)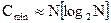 (1.3)
(1.3) (1.4)
(1.4)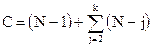 (2.1)
(2.1)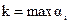 ,
, 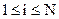 . Определение инверсий, относящихся к описанию комбинаторных свойств перестановок, можно найти в [1]. Если
. Определение инверсий, относящихся к описанию комбинаторных свойств перестановок, можно найти в [1]. Если 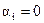 для
для 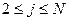 (массив упорядочен), то минимальное количество сравнений
(массив упорядочен), то минимальное количество сравнений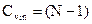 (2.2)
(2.2)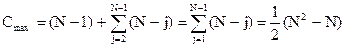 (2.3)
(2.3)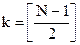 :
: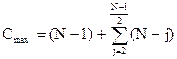 (2.4)
(2.4)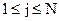 и записи a1, …, aj-1 уже размещены так, что
и записи a1, …, aj-1 уже размещены так, что 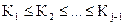 . Будем сравнивать по очереди Кj c Кj-1, Кj-2, … до тех пор, пока не обнаружим, что запись aj следует вставить между ai и ai+1; тогда подвинем записи ai+1,…, aj+1 на одно место вправо и поместим новую запись в позицию i+1.
. Будем сравнивать по очереди Кj c Кj-1, Кj-2, … до тех пор, пока не обнаружим, что запись aj следует вставить между ai и ai+1; тогда подвинем записи ai+1,…, aj+1 на одно место вправо и поместим новую запись в позицию i+1. Первое сравнение 5: 2
Первое сравнение 5: 2 2 5: 4
2 5: 4 2 4 5: 1
2 4 5: 1 1 2 4 5: 3
1 2 4 5: 3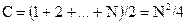 (2.5)
(2.5)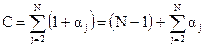 (2.6)
(2.6)
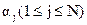 независимы, тогда максимальное количество сравнений определяется формулой
независимы, тогда максимальное количество сравнений определяется формулой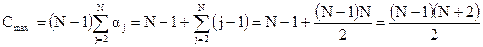 (2.7)
(2.7)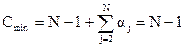 (2.8)
(2.8)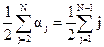 (2.9)
(2.9)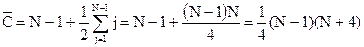 (2.10)
(2.10) при
при 
 при
при 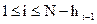 и так далее.
и так далее. при 1 £ e £ t = [log2N] (2.11)
при 1 £ e £ t = [log2N] (2.11)

 1-й просмотр (4-сортировка)
1-й просмотр (4-сортировка) 7: 2
7: 2


