
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Имитационное моделирование бизнес-процессовСтр 1 из 15Следующая ⇒
Имитационное моделирование бизнес-процессов
Пенза, ПГТА, 2012 г.
Оглавление 1. Лабораторная работа №1. Обработка результатов имитационного моделирования на основе моделей кривых роста…………………………...3 2. Лабораторная работа №2. Анализ и прогнозирование с учётом ведущих факторов на основе результатов имитационного моделирования………..11 3. Лабораторная работа №3. Моделирование систем массового обслуживания(СМО)…………………………………………………………16 4. Лабораторная работа №4. Планирование экспериментов…………………26 5. Лабораторная работа №5. Моделирование случайных величин и оценка датчика случайных чисел (ДСН) языка GPSS средствами Microsoft Excel V.5.0 и выше…………………………………………………………………..31 6. Лабораторная работа №6. Изучение функционирования одноканальной разомкнутой системы массового обслуживания (СМО) с простейшими потоками………………………………………………………………………56 7. Лабораторная работа №7. Изучение функционирования одноканальной разомкнутой системы массового обслуживания (СМО) с равномерными потоками…………………………………........................................................70 8. Лабораторная работа №8. Изучение функционирования многоканальной разомкнутой системы массового обслуживания (СМО) с простейшими потоками………………………………………………………………………78 9. Лабораторная работа №9. Изучение функционирования многоканальной разомкнутой системы массового обслуживания (СМО) со смешанными потоками………………………………………………………………………88 10. Цель курсового проекта, общее задание и тематика работ………………..98 11. Содержание курсового проекта……………………………………………..98 12. Требования к оформлению курсового проекта и содержанию разделов…99 13. Варианты заданий…………………………………………………………..106 14. Литература…………………………………………………………………..113 15. Приложения…………………………………………………………………114 Лабораторная работа № 1. Обработка результатов имитационного моделирования на основе моделей кривых роста Цель работы Прогнозирование результатов имитационного моделирования на основе линейной модели. Задание на лабораторную работу 1. для зависимой переменной Y(t) построить линейную модель, параметры модели оценить с помощью метода наименьших квадратов.
2. Оценить качество построенной модели (провести исследования адекватности и точности модели). Порядок выполнения работы 1. для отражения тенденции изменения исследуемого показателя воспользуемся простейшей моделью вида:
Параметры кривой роста оцениваются по методу наименьших квадратов (МНК). Для линейной модели:
- среднее значение фактора времени; - среднее значение исследуемого показателя. Примечание: В Excel математическое ожидание (среднее значение) определяется с помощью функции СРЗНАЧ (значения чисел) в категории Статистические. Среднее квадратическое отклонение, обозначаемое 3адание. По данным о курсе акций за девять недель построить линейную модель.
Таблица 1. Оценка параметров уравнения прямой.
Таким образом, линейная модель имеет вид:
Отклонения расчетных значений от фактических наблюдений вычисляются как
2. Оценить качество модели, исследовав ее адекватность и точность. Качество модели определяется ее адекватностью исследуемому процессу, которая характеризуется выполнением определенных статистических свойств, и точностью, т. е, степенью близости к фактическим данным. Модель считается хорошей со статистической точки зрения, если она адекватна и достаточно точна. Модель является адекватной, если ряд остатков обладает свойствами случайности, независимости последовательных уровней. нормальности распределения и равенства нулю средней ошибки.
Результаты исследования адекватности отражены в таблице. Таблица 2. Оценка адекватности модели 2.1. Проверку случайности уровней ряда остатков проведем на основе критерия поворотных точек. В соответствии с ним каждый уровень ряда сравнивается с двумя рядом стоящими. Если он больше или меньше их, то эта точка считается поворотной. далее подсчитывается сумма поворотных точек “р”. В случайном ряду чисел должно выполняться строгое неравенство:
Квадратные скобки здесь означают, что от результата вычислений берется целая часть числа (не путать с процедурой округления!). При N= 9 в правой части неравенства имеем: [2,4]=2. Следовательно, свойство случайности выполняется. 2.2. При проверке независимости (отсутствия автокорреляции) определяется отсутствие в ряду остатков систематической составляющей. Это проверяется с помощью d – критерия Дарбина - Уотсона, в соответствии с которым определяется коэффициент d:
Вычисленная величина этого критерия сравнивается с двумя табличными уровнями (нижним Если
Если В нашем примере d = 1,31. Для линейной модели при 9 наблюдениях можно взять в качестве критических табличных уровней величины Так как рассчитанная величина попала в зону между Воспользуемся первым коэффициентом автокорреляции: r (l) = 7,58 / 48,93 = 0,154. Следовательно, по этому критерию также подтверждается выполнение свойства независимости уровней остаточной компоненты. 2.3. Соответствие ряда остатков нормальному закону распределения определим при помощи RS - критерия:
где
Если значение этого критерия попадает между табулированными границами с заданным уровнем вероятности, то гипотеза о нормальном распределении ряда остатков принимается. Для N = 10 и 5% го уровня значимости этот интервал равен (2,7 - 3,7). В нашем примере:
RS = 2, 99 Расчетное значение попадает в интервал. Следовательно, свойство нормальности распределения выполняется, что позволяет строить доверительный интервал прогноза. Для характеристики точности воспользуемся среднеквадратическим отклонением и средней относительной ошибкой:
Ее величина менее 5% свидетельствует об удовлетворительном уровне точности модели (ошибка в 10 и более процентов является очень большой).
3. Точечный прогноз на k шагов вперед получается путем подстановки в модель параметра t=N+1,…,N+k. При прогнозировании на два шага имеем:
Доверительный интервал прогноза будет иметь следующие границы: Верхняя граница прогноза Нижняя граница прогноза Величина U(k) для линейной модели имеет вид:
Коэффициент U (1) = 3, 21 U (2) = 3, 40 Таблица З. Прогнозные оценки по линейной модели
Если построенная модель адекватна, то с выбранной пользователем вероятностью можно утверждать, что при сохранении сложившихся закономерностей развития прогнозируемая величина попадет в интервал, образованный нижней и верхней границами. Варианты заданий Номер Вашего варианта соответствует последним двум цифрам зачетной книжки. В соответствии с ним из таблицы выберите показатель Y(t). Если число, которое образуют последние две цифры номера Вашей зачетной книжки, превышает 50, то предварительно вычтете из него эту величину, а затем выберите соответствующие данные указанным выше способом. N показателя |
Значения Y(t) при t | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 1 | 10 | 14 | 21 | 24 | 33 | 41 | 44 | 47 | 49 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 2 | 43 | 47 | 50 | 48 | 54 | 57 | 61 | 59 | 65 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 3 | 3 | 7 | 10 | 11 | 15 | 17 | 21 | 25 | 23 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 4 | 30 | 28 | 33 | 37 | 40 | 42 | 44 | 49 | 47 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 5 | 5 | 7 | 10 | 12 | 15 | 18 | 20 | 23 | 26 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 6 | 12 | 15 | 16 | 19 | 17 | 20 | 24 | 25 | 28 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 7 | 20 | 27 | 30 | 41 | 45 | 51 | 53 | 55 | 61 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 8 | 8 | 13 | 15 | 19 | 25 | 27 | 33 | 35 | 40 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 9 | 45 | 43 | 40 | 36 | 38 | 34 | 31 | 28 | 25 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 10 | 33 | 35 | 40 | 41 | 45 | 47 | 45 | 51 | 53 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 11 | 10 | 15 | 21 | 23 | 25 | 34 | 32 | 37 | 41 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 12 | 16 | 20 | 22 | 20 | 25 | 23 | 25 | 28 | 30 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 13 | 12 | 17 | 20 | 21 | 25 | 27 | 24 | 28 | 31 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 14 | 20 | 22 | 24 | 26 | 25 | 29 | 35 | 38 | 43 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 15 | 25 | 30 | 36 | 41 | 38 | 43 | 47 | 45 | 50 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 16 | 80 | 75 | 78 | 72 | 69 | 70 | 64 | 61 | 59 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 17 | 24 | 22 | 26 | 29 | 33 | 31 | 28 | 33 | 36 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 18 | 30 | 34 | 40 | 38 | 42 | 48 | 50 | 52 | 53 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 19 | 88 | 85 | 84 | 86 | 81 | 80 | 83 | 78 | 76 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 20 | 50 | 52 | 54 | 59 | 57 | 60 | 63 | 68 | 70 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 21 | 25 | 27 | 30 | 31 | 35 | 41 | 42 | 45 | 47 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 22 | 75 | 77 | 73 | 70 | 66 | 63 | 67 | 63 | 61 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 23 | 28 | 34 | 32 | 36 | 39 | 42 | 45 | 41 | 46 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 24 | 15 | 20 | 24 | 30 | 33 | 37 | 36 | 40 | 42 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 25 | 70 | 74 | 76 | 75 | 78 | 78 | 83 | 85 | 87 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 26 | 82 | 79 | 78 | 72 | 69 | 70 | 64 | 61 | 59 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 27 | 25 | 27 | 26 | 29 | 32 | 32 | 30 | 33 | 35 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 28 | 32 | 34 | 38 | 40 | 42 | 46 | 50 | 52 | 53 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 29 | 90 | 87 | 85 | 86 | 82 | 80 | 81 | 78 | 76 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 30 | 55 | 57 | 54 | 59 | 57 | 60 | 63 | 66 | 64 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 31 | 12 | 15 | 18 | 22 | 25 | 31 | 32 | 37 | 41 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 32 | 26 | 30 | 32 | 30 | 35 | 33 | 35 | 38 | 40 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 33 | 62 | 67 | 80 | 81 | 85 | 87 | 84 | 88 | 91 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 34 | 18 | 21 | 24 | 26 | 25 | 29 | 34 | 38 | 41 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 35 | 289 | 32 | 36 | 40 | 38 | 43 | 45 | 48 | 50 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 36 | 82 | 77 | 78 | 72 | 69 | 70 | 67 | 64 | 62 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 37 | 28 | 24 | 26 | 29 | 33 | 31 | 28 | 33 | 35 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 38 | 32 | 34 | 41 | 38 | 42 | 48 | 50 | 52 | 55 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 39 | 90 | 88 | 84 | 86 | 82 | 80 | 81 | 78 | 76 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 40 | 56 | 58 | 60 | 63 | 67 | 66 | 70 | 72 | 74 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 41 | 35 | 37 | 40 | 41 | 45 | 51 | 52 | 55 | 57 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 42 | 65 | 67 | 63 | 60 | 56 | 53 | 57 | 53 | 51 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 43 | 29 | 33 | 32 | 36 | 38 | 41 | 44 | 42 | 46 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 44 | 35 | 40 | 44 | 50 | 53 | 57 | 56 | 60 | 62 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 45 | 72 | 74 | 76 | 75 | 79 | 78 | 82 | 85 | 89 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 46 | 85 | 81 | 78 | 72 | 69 | 70 | 64 | 61 | 56 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 47 | 23 | 27 | 26 | 29 | 32 | 34 | 36 | 41 | 45 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 48 | 30 | 34 | 36 | 40 | 41 | 46 | 49 | 52 | 53 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 49 | 95 | 89 | 85 | 86 | 82 | 80 | 81 | 76 | 73 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 50 | 52 | 54 | 55 | 59 | 60 | 62 | 63 | 66 | 70 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
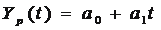
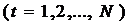
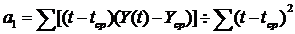 ,
,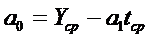 ,
,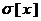 определяет разброс значений случайной величины относительно ее математического ожидания. Заметим, что в Excel эта величина называется стандартное отклонение - СТАНДОТКЛОН (значения чисел) по зависимости
определяет разброс значений случайной величины относительно ее математического ожидания. Заметим, что в Excel эта величина называется стандартное отклонение - СТАНДОТКЛОН (значения чисел) по зависимости
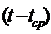
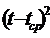
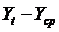
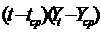
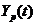
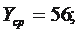
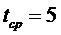
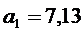
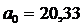
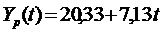
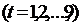
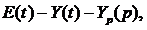

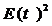

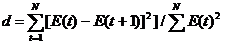
 и верхним
и верхним 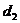 )
)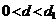 - то уровни остатков сильно автокоррелированы, а модель неадеквата;
- то уровни остатков сильно автокоррелированы, а модель неадеквата; 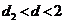 - то уровни ряда являются независимыми; d > 2 - то это свидетельствует об отрицательной корреляции и перед входом в таблицу необходимо выполнить преобразование: d = 4 – d;
- то уровни ряда являются независимыми; d > 2 - то это свидетельствует об отрицательной корреляции и перед входом в таблицу необходимо выполнить преобразование: d = 4 – d; - то однозначного вывода сделать нельзя и необходимо применение других критериев, например, первого коэффициента автокорреляции r (1), который вычисляется по формуле:
- то однозначного вывода сделать нельзя и необходимо применение других критериев, например, первого коэффициента автокорреляции r (1), который вычисляется по формуле: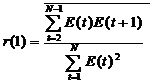
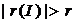 (табл.) (при N < 15r (табл.) = 0,36), то присутствие в остаточном ряду существенной автокорреляции подтверждается.
(табл.) (при N < 15r (табл.) = 0,36), то присутствие в остаточном ряду существенной автокорреляции подтверждается.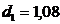 и
и 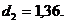
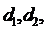 то однозначного вывода сделать нельзя и необходимо применение других критериев.
то однозначного вывода сделать нельзя и необходимо применение других критериев.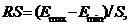
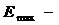 максимальный уровень ряда остатков;
максимальный уровень ряда остатков;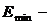 минимальный уровень ряда остатков;
минимальный уровень ряда остатков;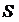 - среднее квадратическое отклонение.
- среднее квадратическое отклонение.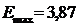 и
и 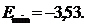
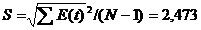
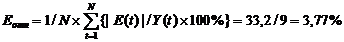
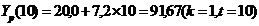
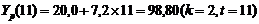
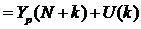
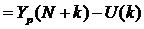
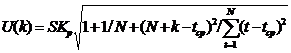
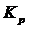 является табличным значением t -статистики Стьюдента. Если исследователь задает уровень вероятности попадания прогнозируемой величины внутрь доверительного интервала, равный 70%, то
является табличным значением t -статистики Стьюдента. Если исследователь задает уровень вероятности попадания прогнозируемой величины внутрь доверительного интервала, равный 70%, то  = 1,05.
= 1,05.
Контрольные вопросы
|
|
1. В чем заключается методика оценки качества математических моделей?
2. Что включает в себя понятие адекватности математических моделей прогнозирования?
Какова методика ее определения?
З. Что такое точность математических моделей? Приведите основные характеристики. Может ли модель быть достаточно точной, но не адекватной?
4. Что представляет собой ретроспективный прогноз? Какова его роль для оценки точности математических моделей?
Лабораторная работа № 2.
Цель работы
Анализ и прогнозирование результатов имитационного моделирования на основе моделей регрессии
Задание на лабораторную работу
1. Для зависимой переменной Y(t) построить линейную однопараметрическую модель регрессии, параметры которой оценить с помощью метода наименьших квадратов.
2. Оценить качество построенной модели (провести исследования адекватности и точности модели).
З. Рассчитать парный коэффициент корреляции переменных, коэффициент эластичности и бета-коэффициент.
4. Отобразить на графике результаты аппроксимации и прогнозирования по модели регрессии.
Порядок выполнения работы
1.Для исследования динамики курса ценной бумаги построим однофакторную линейную регрессионную модель 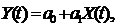 t = 1,2,…,N.
t = 1,2,…,N.
Таблица. Оценка параметров уравнения регрессии
| t | Y(t) | X(t) | 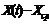
| 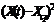
| 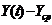
| 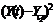
| 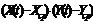
| Расчет 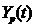
| Отклонение E (t) |
| 1 2 3 4 5 6 7 8 9 | 25 34 42 51 55 67 73 76 81 | 45 47 50 48 54 57 61 59 65 | -9 -7 -4 -6 0 3 7 5 11 | 81 49 16 36 0 9 49 25 121 | -31 -22 -14 -5 -1 11 17 20 25 | 961 484 196 25 1 121 289 400 625 | 279 154 56 30 0 33 119 100 275 | 31,61 37,03 45,16 39,74 56,0 64,13 74,97 69,55 85,81 | -6,61 -3,03 -3,16 11,26 -1,0 2,87 -1,97 6,45 -4,81 |
· 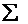
| 504 | 486 | 0 | 386 | 0 | 3102 | 1046 | 504 | 0 |
Оценка параметров модели регрессии осуществляется по МНК на основе следующих формул:
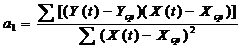
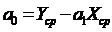
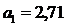
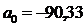
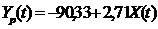
2. Оценка качества модели на основе остаточной компоненты E(t) дает следующие результаты: p = 7; d = 2,27 (d = 1,74); RS = 3,09.
Сопоставив эти значения с критическими уровнями, можно констатировать, что все свойства выполняются и, следовательно, построенная модель адекватна.
Характеристики точности S = 5,78; 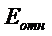 = 9,8% дают не очень хорошие результаты.
= 9,8% дают не очень хорошие результаты.
Модель можно использовать для анализа, она эффективна для получения прогнозных оценок.
3. На основании данных (табл.) о динамике изменения двух показателей (Y(t) - характеристика эффективности ценной бумаги, X(t) - показатель - фактор эффективности рынка ценных бумаг) за девять периодов оценим величину влияния фактора на исследуемый показатель при помощи коэффициента парной корреляции.
|
|
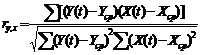
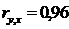
Значение коэффициента корреляции свидетельствует о сильной прямой зависимости двух исследуемых показателей.
Коэффициент детерминации:
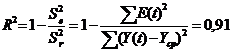
Коэффициент детерминации показывает, что более 91% вариации зависимой переменной учтено в модели и обусловлено влиянием исключенного фактора.
Коэффициент эластичности:
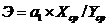
Э = 2,61
Коэффициент эластичности показывает, что при изменении эффективности рынка на один процент эффективность нашей ценной бумаги увеличится на 2,6%.
Бета-коэффициент:
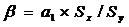
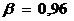
Бета-коэффициент свидетельствует о том, что при возрастании эффективности рынка будет возрастать эффективность исследуемой ценной бумаги, но риск инвестиций в нее несколько меньше среднерыночного
4. Прогнозные значения фактора X(t) определим на основе величины его среднего прироста по соотношению:
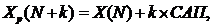
САП = (X(N) – X(1)) / (N-1)
САП = 2,5
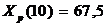
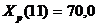
Для получения прогнозных оценок зависимостей переменной по модели подставим в нее найденные прогнозные значения фактора:
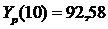 (t = 10)
(t = 10)
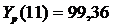 (t = 11)
(t = 11)
Доверительный интервал прогноза будет иметь следующие границы:
верхняя граница прогноза: 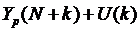
нижняя граница прогноза: 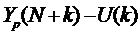
Для линейной модели регрессии величина U(k) имеет вид:
Для прогноза на два шага имеем:
U (1) = 7, 64
U (2) = 8, 09
Таблица. Прогнозные оценки по Модели Брауна.
| Время t | Шаг k | 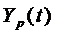
| Нижняя граница | Верхняя граница |
| 10 11 | 1 2 | 92,58 99,36 | 84,94 91,27 | 100,22 107,45 |
Таблица. Свободная таблица результатов исследования
| Модель | Остаточная компоненты | Адекватность |
|
| ||
| Независи-мость | Случай-ность | Нормаль-ность | ||||
| Y(t)=20,33+7,13t Y(t)=82,23+6,1t Y(t)=90,33+2,71(t) | Да Нет Да | Да Да да | Да Да Да | Да Да Да | 2,4 2,35 5,8 | 3,7 3,55 9,8 |
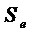
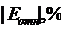
Вывод:
Сравнивая, точечные прогнозные оцени, модели регрессии с оценками по линейной временной модели, можно отметить их явную близость, однако доверительный интервал регрессионной модели заметно шире, что снижает ее практическую значимость.
Адаптивная модель статистически полностью адекватна и имеет достаточно высокие точностные характеристики. Ее результаты можно взять в качестве прогноза.
Варианты заданий
Номер Вашего варианта выбирается в соответствии с вариантом задания в лабораторной работе № 6. В соответствии с ним из таблицы выберите показатель Y(t), а данные фактора Х(t) возьмите из следующей по порядку строки.
Контрольные вопросы
1. Какие ограничения накладываются на количество факторов, включаемых, в регрессионную модель и чем они вызваны?
2. Является ли высокое значение парного коэффициента корреляции свидетельством тесной взаимосвязи переменных?
3. Охарактеризуйте назначение коэффициентов регрессии. эластичности, бета - и дельта - коэффициентов и их роль в содержательном анализе.
4. Какими средствами оценивается качество построенных регрессионных моделей?
5. Почему регрессионные модели, являющиеся более мощным инструментом исследования, на практике не всегда дают лучшие результаты по сравнению с временными экстраполяционными моделями?
6. Каким образом на основе регрессионной модели получается прогноз зависимой переменной?
Лабораторная работа №3.
Цель работы
Приобретение навыков моделирования систем массового обслуживания на языке GPSS (General Purpose Simulation System).
Задание на лабораторную работу
1. Написать программу на языке GPSS, которая моделирует систему массового обслуживания.
2. Отладить программу и запустить на выполнение, получить и проанализировать результат.
Порядок выполнения работы
В сжатом виде порядок выполнения работы представлен на рисунке 1.
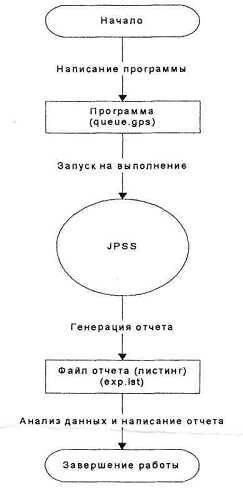
Рисунок 1 – Порядок выполнения работы
Теоретические сведения
В производственной деятельности и повседневной жизни часто возникают ситуации, когда появляется необходимость в обслуживание требований или заявок поступающих в систему. Зачастую системы обслуживания обладают ограниченными возможностями для удовлетворения спроса, что приводит к образованию очередей. Примерами подобных явлений могут быть очереди в магазинах, поликлиниках и. т. д.
Всякой системе массового обслуживания (СМО) характерна структура, которая определяется составом элементов и функциональными связями. Основные элементы системы: входящий поток требований (заявок), приборы (каналы) обслуживания, очередь требований и выходящий поток требований.
Каждой из систем массового обслуживания свойственна определенная организация. Опираясь на различные признаки классификации, выделяют одноканальные и многоканальные СМО, системы с отказами, с потерями, с неограниченным временем ожидания или длиной очереди, с приоритетами на обслуживание смешанного типа и. т.д.
Процесс поступления в систему массового обслуживания потока требований является вероятностным. Он представляет поток однородных или неоднородных событий, поступающих через случайные промежутки времени. В данной работе принято допущение, что распределение интервалов между событиями носит экспоненциальный характер с интенсивностью л.
Время обслуживания - одна из важнейших характеристик обслуживающих аппаратов (приборов), определяющая пропускную способность системы. Обслуживание заявки при наличии свободного канала длится случайный интервал времени, распределенный по некоторому закону с интенсивностью µ.
Этот закон определяется из опыта путем статистических испытаний. На практике чаще всего исходят из гипотезы о показательном законе распределения обслуживания.
Постановка задачи
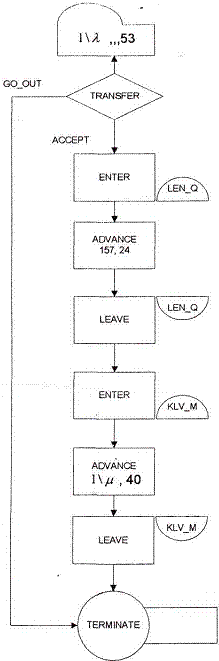
Ограничимся рассмотрением в данной работе системы массового обслуживания на следующем примере:
В частной парикмахерской работают три мастера. Многодневные исследования показали, что распределение заявок носит экспоненциальный характер с интенсивностью 0,06 (л =0,06). Значит среднее время прихода заявок т3=1/л3=1/0,06. Обслуживание каждого заказа, в зависимости от типа, происходит равномерно (±40) с интенсивностью 0,02, тоб =1/лоб=1/0,02. При полной загруженности работников образуется очередь, среднее время пребывания в которой 157 ± 24-мин, причем длина очереди ограничена и не превышает 10 требований.
За день, как правило, удается обслужить около 53 клиентов.
Необходимо построить модель, описывающую функционирование мастерской и определить эффективность ее работы за день.
Метод построения модели
В задаче мы сталкиваемся с многоканальной СМО замкнутого типа (поток заявок ограничен) с предельной длиной очереди. Если мест в очереди нет, то происходит отказ от обслуживания.
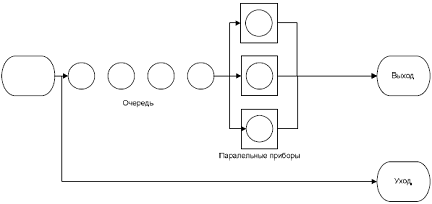
Процесс функционирования модели можно представить в виде движения сообщений, генерируемых в блоке GENERATE и проходящих последовательно все остальные блоки до тех пор, пока они, не достигнут последнего блока TERMINATE, в котором происходит уничтожение сообщений и вывод его из модели.
Результаты моделирования
1. Емкость прибора равна 3, т.е. параллельно работают три мастера.
2. В среднем одно из устройств было в состоянии занятости.
3. В среднем три прибора загружены на 60%.
4. Общее число занятий приборов (входов) было 52. Получили отказ 1 требований (53-52=1).
5. Среднее время на одно занятие было 49,96 единицы.
6. Ни один из приборов не находился в занятом состоянии на момент остановки моделирования.
7. В процессе моделирования были моменты, когда все 3 прибора были в состоянии занятости одновременно.
По этим данным можно рассчитать показатели эффективности СМО:
a) приведенная плотность потока 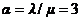 ;
;
b) вероятность того, что обслуживанием заняты все п каналов (n = к =3);
c) вероятность того, что обслуживаемые каналы свободны.
Получаем Р0=0,077
 ;
;
d) среднее значение занятых каналов: Nk=1,964≈2
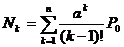 ;
;
e) число свободных каналов: N0=0,308≈0
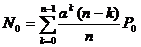 ;
;
f) коэффициент простоя: kn=0,103
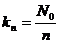 ;
;
g) вероятность отказов:
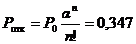 .
.
Результаты проведенных вычислений сведены в таблицу 1.
Таблица 1 – Результаты вычислений
| λ | 0,06 | α | Pk | P0 | Nk | N0 | kn | Pотк |
| μ | 0,02 | 3 | 0,346 | 0,077 | 1,964 | 0,308 | 0,103 | 0,347 |
| n=k | 3 |
| ≈2 | ≈0 |
| |||
Выводы
В ходе выполнения данной лабораторной работы были приобретены навыки моделирования систем массового обслуживания на языке GPSS. На основе разработанных примеров были построены блок-схемы моделей с привлечением специальных карт, имитирующих входной поток заявок, организацию ожидания в очереди, занятие и обслуживание прибором, вывод требований из модели т. е всех необходимых элементов систем массового обслуживание. Кроме этого был проведен аналитический расчет главных показателей эффективности функционирования обслуживающих систем.
Результаты работы программы

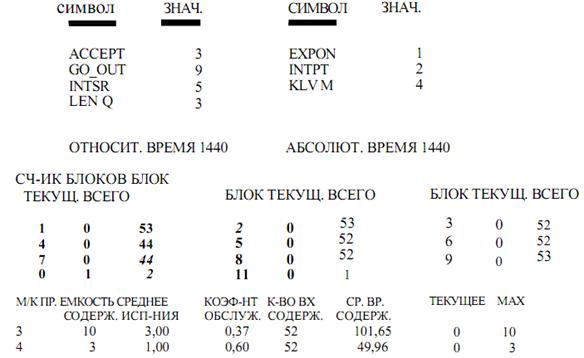
Емкость – наибольшее значение содержимого очереди, зарегистрированной в течение моделирования.
Среднее содержание – среднее значение содержимого очереди.
Коэффициент использования – коэффициент загрузки приборов.
Кол-во вх. – общее число входов в очередь.
Среднее время обслуживания – средняя продолжительность одного обслуживания
Блок схема программы
Варианты заданий
Номер вашего варианта соответствует последним двум цифрам зачетной книжки. В соответствии с ним из таблицы выберите вариант. Если число, которое образуют последние две цифры номера вашей зачетной книжки, превышает 50, то предварительно вычтете из него эту величину, а затем выберите соответствующие данные указанным выше способом.
| Вариант | λ | t | µ | St1 | St2 |
| 1 | 0,06 | 102±15 | 0,02 | 3 | 10 |
| 2 | 0,05 | 150±20 | 0,03 | 3 | 9 |
| 3 | 0,04 | 148±25 | 0,04 | 3 | 8 |
| 4 | 0,05 | 180±30 | 0,05 | 3 | 7 |
| 5 | 0,07 | 160±32 | 0,01 | 3 | 9 |
| 6 | 0,08 | 145±30 | 0,02 | 3 | 11 |
| 7 | 0,09 | 165±32 | 0,03 | 3 | 12 |
| 8 | 0,06 | 170±33 | 0,04 | 3 | 13 |
| 9 | 0,07 | 171±34 | 0,05 | 3 | 6 |
| 10 | 0,08 | 172±35 | 0,04 | 3 | 8 |
λ– интенсивность заявок;
t – время пребывания в очереди
µ – интенсивность обслуживания;
St1 – кол-во параллельных приборов;
St2 – предельная длина очереди.
Лабораторная работа №4. Планирование экспериментов
Цель работы
Изучение методов планирования машинных экспериментов с моделями системы; приобретение навыков решения задач данного класса; проведение имитационного эксперимента.
Постановка задачи
Смоделировать процесс обслуживания на автомойке средствами языка моделирования GPSS. Заявки поступают в систему по равномерному закону распределения с интервалом в 5 минут. Среднее время обслуживания – 4 минуты. Размер очереди ограничен тремя элементами. Работа системы должна быть промоделирована в течение 8 часов.
Порядок выполнения работы
В качестве объекта моделирования используется Q-схема, структура которой приведена на рисунке 1, где U – источник заявок, Н – накопитель для хранения заявок, μ – интенсивность обслуживания, L –емкость накопителя
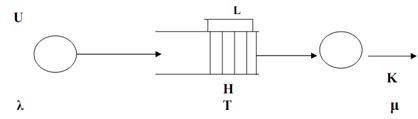
Рисунок 1 – Q-схема модели
Путь требуется провести машинный эксперимент по исследованию характеристик Q-схемы, построить план эксперимента, описать модель планирования, получить оценки коэффициентов модели и провести планируемый имитационный эксперимент с моделью Q-схемы. Исследуется однофазная одноканальная Q-схема со следующими параметрами:
- интенсивность обслуживания - µ = ¼ мин -1
- интенсивность поступления заявки - λ = 1/5 мин -1
- емкость накопителя - 3.
Оценить среднее время задержки в системе Т при минимальных затратах машинных ресурсов. При проведении эксперимента для оценки Т в Q-схеме необходимо определить влияние факторов, находящихся в функциональной связи с искомым фактором. Для этого произведем отбор факторов, опишем функциональную зависимость, определим уровни выбранных факторов, фиксированный набор которых определяет одно из возможных состояний Q-схемы. Каждому фиксированному набору уровней факторов соответствует определенная точка в многомерном пространстве. Выделим факторы: X1 = λ; X2=μ; X3=L
Определяем локальную область эксперимента путем выбора основного уровня Xiо и интервалов варьирования (таблица 1).
Таблица 1 – Уровни факторов и интервалы варьирования
| Факторы | Уровни факторов | Интервалы варьирования | ||
| -1(-1/2) | 0 | +1(+1/2) | ||
| Х1 | 150 | 300 | 450 | 150 |
| Х2 | 120 | 240 | 360 | 120 |
| Х3 | 3 | 3 | 3 | 0 |
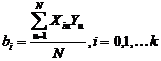 ,
,
Где N – число опытов, k – число факторов.
b 0 =218, b1 =98, b2 =-77, b3 =-382.



