
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Постановка задачи к лабораторной работе № 4
Разработать программное средство, автоматизирующее процесс эквивалентного преобразования КС-грамматик. Программное средство должно выполнять следующие функции: 1) организация ввода грамматики и проверка ее на принадлежность к классу КС-грамматик; 2) проверка существования языка КС-грамматики; 3) реализация эквивалентных преобразований грамматики, направленных на удаление: а) бесполезных символов; б) недостижимых символов; в) e-правил; г) цепных правил; д) левой факторизации правил; е) прямой левой рекурсии. Варианты индивидуальных заданий представлены в таблице 4.1.
Таблица 4.1 – Варианты индивидуальных заданий к лабораторной работе № 4 и 5
Продолжение таблицы 4.1 – Варианты индивидуальных заданий к лабораторной работе № 4 и 5
5 Лабораторная работа № 5. Построение автомата с магазинной памятью по контекстно-свободной грамматике
Цель: - закрепить понятия «автомат с магазинной памятью (МП-автомат)», «расширенный МП-автомат», «конфигурация МП-автомата»; «строка и язык, допускаемые МП-автоматом»;
- сформировать умения и навыки построения МП-автомата и расширенного МП-автомата по КС-грамматике, разбора входной строки с помощью МП-автомата.
Основы теории
КС-языки можно распознавать с помощью автомата с магазинной памятью (МП-автомата). Определение 5.1. МП-автомат можно представить в виде семерки:
где Q – конечное множество состояний автомата; T – конечный входной алфавит; N – конечный магазинный алфавит; F – магазинная функция, отображающая множество во множество всех подмножеств множества
q 0 – начальное состояние автомата, q 0 Î Q; N 0– начальный символ магазина, N 0 Î N; Z – множество заключительных состояний автомата, Z Í Q.
Определение 5.2. Конфигурацией МП-автомата называется тройка вида:
где q - текущее состояние автомата, q Î Q; w - часть входной строки, первый символ которой находится под входной головкой,
Общая схема МП-автомата представлена на рисунке 5.1.
Рисунок 5.1 – Схема МП-автомата
Алгоритм 5.1. Функционирование МП-автомата
Начальной конфигурацией МП-автомата является конфигурация (q 0, Шаг работы МП-автомата будем представлять в виде отношения непосредственного следования конфигураций (обозначается «|=») и отношения достижимости конфигураций (обозначается «|=*»). Если одним из значений магазинной функции 1) Случай t Î T. Автомат находится в текущем состоянии q, читает входной символ t, имеет в вершине стека символ S. Он переходит в очередное состояние 2) Случай Заключительной конфигурацией МП-автомата является конфигурация (q,
Определение 5.3. МП-автомат допускает входную стоку Определение 5.4. Язык L, распознаваемый (принимаемый) МП-автоматом М определяется как множество вида:
Определение 5.5. МП-автомат с магазинной функцией
Существуют КС-языки, МП-автоматы и расширенные МП-автоматы, определяющие один и тот же язык.
Алгоритм 5.2. Построение МП-автомата по КС-грамматике
Построим МП-автомат, выполняющий левосторонний разбор. Данный автомат обладает только одним состоянием и принимает входную строку опустошением магазина. Стек используется для размещения текущей сентенции, первоначально это начальный символ грамматики. Очередная сентенция получается заменой верхнего нетерминала стека.
Вход: КС-грамматика Выход: МП-автомат
Шаг 1. Положить Q = { q }, q 0 = q, Z = Æ, N = VT È VN, T = VT, N 0 = S. Шаг 2. Для каждого правила вида (А ® Шаг 3. Для каждого t
Пример 5.1. Дана КС-грамматика: G ({+, (,), a }, { S, A }, { S ® S + A | A, A ®(S) | a },{ S }). Последовательность построения МП-автомата будет иметь вид. 1) Q = { q }, q 0 = q, T = {+, (,), a }, N = {+, (,), a, S, A }, N 0 = S, Z = Æ. 2) F (q, 3) F (q, t, t) = (q,
Распознавание строки (а) построенным МП-автоматом представлено в таблице 5.1. Полученный МП-автомат является недетерминированным. Таблица 5.1 – Распознавание МП-автоматом строки (а)
Алгоритм 5.3. Построение расширенного МП-автомата по КС-грамматике
Построим МП-автомат, выполняющий правосторонний разбор. Данный автомат имеет единственное текущее состояние и одно заключительное состояние, в котором стек пуст. Стек содержит левую часть текущей сентенции. Первоначально в стек помещается специальный магазинный символ, маркер пустого стека #. На каждом шаге автомат по правилу грамматики замещает нетерминалом строку верхних символов стека или дописывает в вершину входной символ.
Вход: КС-грамматика Выход: расширенный МП-автомат
Шаг 1. Положить Q = { q, r }, q 0 = q, Z = { r }, N = VT È VN È {#}, T = VT, N 0 = #. Шаг 2. Для каждого правила вида Шаг 3. Для каждого терминала
Шаг 4. Предусмотреть магазинную функцию для перевода автомата в заключительное состояние
Пример 5.2. Для грамматики из примера 5.1 построить расширенный МП-автомат. Последовательность построения МП-автомата будет иметь вид. 1) Q = { q, r }, q 0 = q, T = {+, (,), a }, N = {+, (,), a, S, A }, N 0 = #, Z = r. 2) F (q, 3) F (q, t, 4) F (q,
Распознавание строки (а) расширенным МП-автоматом представлено в таблице 5.2. Полученный МП-автомат является детерминированным.
Таблица 5.2 – Распознавание расширенным МП-автоматом строки (а)
Постановка задачи к лабораторной работе № 5
Разработать программное средство, реализующее следующие функции: а) ввод произвольной формальной грамматики и проверка ее на принадлежность к классу КС-грамматик; б) построение МП-автомата по КС-грамматике; в) построение расширенного МП-автомата по КС-грамматике. Продемонстрировать разбор некоторой входной строки с помощью построенных автоматов для случая: а) входная строка принадлежит языку исходной КС-грамматики и допускается МП-автоматом; б) входная строка не принадлежит языку исходной КС-грамматики и не принимается МП-автоматом. Индивидуальные варианты заданий представлены в таблице 4.1. 6 Лабораторная работа № 6. Моделирование функционирования распознавателя для LL (1) - грамматик
Цель: - закрепить понятие «LL (k) –грамматика», необходимые и достаточные условия LL (k) –грамматики; - сформировать умения и навыки построения множеств FIRST (k, a) и FOLLOW (k, a), распознавателя для LL (1) - грамматик. Основы теории Определение 6.1. КС-грамматика обладает свойством LL (k) для некоторого k >0, если на каждом шаге вывода для однозначного выбора очередной альтернативы МП-автомату достаточно знать символ на верхушке стека и рассмотреть первые k символов от текущего положения считывающей головки во входной строке. Определение 6.2. КС-грамматика называется LL (k) - грамматикой, если она обладает свойством LL (k) для некоторого k >0. В основе распознавателя LL (k) - грамматик лежит левосторонний разбор строки языка. Исходной сентенциальной формой является начальный символ грамматики, а целевой – заданная строка языка. На каждом шаге разбора правило грамматики применяется к самому левому нетерминалу сентенции. Данный процесс соответствует построению дерева разбора цепочки сверху вниз (от корня к листьям). Отсюда и произошла аббревиатура LL (k): первая «L» (от слова «left») означает левосторонний ввод исходной цепочки символов, вторая «L» - левосторонний вывод в процессе работы распознавателя.
Определение 6.3. Для построения распознавателей для LL (k) - грамматик используются два множества: - FIRST (k, a) – множество терминальных цепочек, выводимых из цепочки a Î(VT È VN)*, укороченных до k символов; - FOLLOW (k, A) – множество укороченных до k символов терминальных цепочек, которые могут следовать непосредственно за A Î VN в цепочках вывода. Формально эти множества можно определить следующим образом: - FIRST (k, a) = { w Î VT* | $ вывод a Þ* w и | w | £ k или $ вывод a Þ* wx и | w | = k; x, a Î (VT È VN)*, k > 0}; - FOLLOW (k, A) = { w Î VT * | $ вывод S Þ* aAg и w Î FIRST (k, g); a, g Î V*, A Î VN, k >0}.
Теорема 6.1. Необходимое и достаточное условие LL (1) - грамматики Для того чтобы грамматика G (VN, VT, P, S) была LL (1) - грамматикой необходимо и достаточно, чтобы для каждого символа А Î VN, у которого в грамматике существует более одного правила вида А ®a1 | a2 |…| a n, выполнялось требование:
FIRST (1, a iFOLLOW (1, A)) Ç FIRST (1, a jFOLLOW (1, A)) = Æ, " i ¹ j,0< i £ n, 0< j £ n.
Т.е. если для символа А отсутствует правило вида А ®e, то все множества FIRST (1, a1), FIRST (1, a2),…, FIRST (1, a n) должны попарно не пересекаться, если же присутствует правило А ®e, то они не должны также пересекаться с множеством FOLLOW (1, A). Для построения распознавателей для LL (1) - грамматик необходимо построить множества FIRST (1, x) и FOLLOW (1, A). Причем, если строка х будет начинаться с терминального символа а, то FIRST (1, x)= a, и если она будет начинаться с нетерминального символа А, то FIRST (1, x)= FIRST (1, A). Следовательно, достаточно рассмотреть алгоритмы построения множеств FIRST (1, A) и FOLLOW (1, A) для каждого нетерминального символа А. Алгоритм 6.1. Построение множества FIRST (1, A)
Для выполнения алгоритма необходимо предварительно преобразовать исходную грамматику G в грамматику G ¢, не содержащую e-правил (см. лабораторную работу № 4). Алгоритм построения множества FIRST (1, A) использует грамматику G ¢. Шаг 1. Первоначально внести во множество первых символов для каждого нетерминального символа А все символы, стоящие в начале правых частей правил для этого нетерминала, т.е.
" А Î VN FIRST 0(1, A) = { X | A ® X a Î P, X Î(VT È VN),aÎ(VT È VN)*}.
Шаг 2.Для всех А Î VN положить: FIRSTi +1(1, A) = FIRSTi (1, A) È FIRSTi (1, B), " В Î(FIRST (1, A)Ç VN).
Шаг 3. Если существует А Î VN, такой что FIRSTi +1(1, A) ¹ FIRSTi (1, A), то присвоить i = i +1 и вернуться к шагу 2, иначе перейти к шагу 4. Шаг 4.Исключить из построенных множеств все нетерминальные символы, т.е.
" A Î VN FIRST (1, A) = FIRSTi (1, A) \ N .
Алгоритм 6.2. Построение множества FOLLOW (1, A)
Алгоритм основан на использовании правил вывода грамматики G.
Шаг 1.Первоначально внести во множество последующих символов для каждого нетерминального символа А все символы, которые в правых частях правил вывода встречаются непосредственно за символом А, т.е. " A Î VN FOLLOW 0(1, A) = { X | $ B ® a AX b Î P, B Î VN, X Î (VT È VN), a, b Î(VT È VN)*}.
Шаг 2.Внести пустую строку во множество FOLLOW (1, S), т.е.
FOLLOW (1, S) = FOLLOW (1, S)È{ e }.
Шаг 3.Для всех А Î VN вычислить: FOLLOW ¢ i (1, A)= FOLLOWi (1, A)È FIRST (1, B)," B Î(FOLLOWi (1, A)Ç VN).
Шаг 4.Для всех А Î VN положить: FOLLOW²i (1, A)= FOLLOW¢i (1, A)È FOLLOW¢i (1, B), " B Î(FOLLOW¢i (1, A)Ç VN), если $ правило B ®e.
Шаг 5.Для всех А Î VN определить: FOLLOWi +1(1, A) = FOLLOW²i (1, A)È FOLLOW²i (1, B), для всех нетерминальных символов BÎVN, имеющих правило вида B ® aA, a Î(VT È VN)*.
Шаг 6.Если существует A Î VN такой, что FOLLOWi +1(1, A)¹ FOLLOWi (1, A), то положить i:= i +1 и вернуться к шагу 3, иначе перейти к шагу 7. Шаг 7.Исключить из построенных множеств все нетерминальные символы, т.е. " A Î VN FOLLOW (1, A) = FOLLOWi (1, A)\ N .
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2019-04-30; просмотров: 482; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.138.122.4 (0.132 с.) |


 , (5.1)
, (5.1)
 , т.е.
, т.е.
 ®
®  ;
; , (5.2)
, (5.2)
 - содержимое магазина,
- содержимое магазина, 

 , N 0).
, N 0). является
является  , то записывается
, то записывается  . При этом возможны следующие варианты.
. При этом возможны следующие варианты. , сдвигает входную головку на ячейку вправо и заменяет верхний символ S строкой
, сдвигает входную головку на ячейку вправо и заменяет верхний символ S строкой  магазинных символов. Вариант
магазинных символов. Вариант  означает, что S удаляется из стека.
означает, что S удаляется из стека. . Отличается от первого случая тем, что входной символ t просто не принимается во внимание, и входная головка не сдвигается. Такой шаг работы МП-автомата называется
. Отличается от первого случая тем, что входной символ t просто не принимается во внимание, и входная головка не сдвигается. Такой шаг работы МП-автомата называется  -шагом, который может выполняться даже после завершения чтения входной строки.
-шагом, который может выполняться даже после завершения чтения входной строки. для некоторых q Î Z и
для некоторых q Î Z и  .
.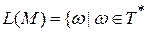 и
и  для некоторых q Î Z и
для некоторых q Î Z и  называется расширенным МП-автоматом, т.е. автоматом, который может заменять цепочку символов конечной длины в верхушке стека на другую цепочку символов конечной длины.
называется расширенным МП-автоматом, т.е. автоматом, который может заменять цепочку символов конечной длины в верхушке стека на другую цепочку символов конечной длины. .
. такой, что L (M) = L (G).
такой, что L (M) = L (G). )
)  , где
, где  сформировать магазинную функцию вида
сформировать магазинную функцию вида  . Эти функции предписывают замещать нетерминал в вершине стека по правилу грамматики.
. Эти функции предписывают замещать нетерминал в вершине стека по правилу грамматики. сформировать магазинную функцию вида
сформировать магазинную функцию вида  , которая выталкивает из стека символ, совпадающий с входным, и перемещает читающую головку. Эти функции обеспечивают опустошение стека.
, которая выталкивает из стека символ, совпадающий с входным, и перемещает читающую головку. Эти функции обеспечивают опустошение стека. ) для каждого t Î{+, (,), a }.
) для каждого t Î{+, (,), a }.

 .
. такой, что L (M) = L (G).
такой, что L (M) = L (G). , где
, где  , сформировать магазинную функцию вида
, сформировать магазинную функцию вида  , предписывающую заменять правую часть правила в вершине стека нетерминалом из левой части, независимо от текущего символа входной строки.
, предписывающую заменять правую часть правила в вершине стека нетерминалом из левой части, независимо от текущего символа входной строки. сформировать магазинную функцию вида
сформировать магазинную функцию вида 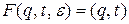 , которая помещает символ входной строки в вершину стека, если там нет правой части правила, и перемещает читающую головку.
, которая помещает символ входной строки в вершину стека, если там нет правой части правила, и перемещает читающую головку. .
. , S + A) = (q, S), F (q,
, S + A) = (q, S), F (q,  , a) =(q, A).
, a) =(q, A). , # S) = (r,
, # S) = (r, 


