Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Кафедра вычислительной техникиСтр 1 из 4Следующая ⇒
МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ РФ Филиал ФЕДЕРАЛЬНОГО ГОСУДАРСТВЕННОГО БЮДЖЕТНОГО ОБРАЗОВАТЕЛЬНОГО УЧРЕЖДЕНИЯ ВЫСШЕГО ПРОФЕССИОНАЛЬНОГО ОБРАЗОВАНИЯ
Кафедра вычислительной техники
Доклад По курсу Компьютерные технологии в науке и производстве «Компьютерные методы анализа и интерпретации данных. Компьютерные системы поддержки принятия решений»
Смоленск Содержание 1 ПРОБЛЕМА ОБРАБОТКИ ДАННЫХ.. 3 2 ИНТЕЛЛЕКТУАЛЬНЫЙ АНАЛИЗ ДАННЫХ (DATA MINING) 5 2.1 Введение в Data Mining. 5 2.2 Понятие Data Mining. 6 2.3 Методы анализа данных. 7 2.4 Классификация методов анализа данных. 9 2.5 Проблемы и ограничения Data Mining. 10 2.6 Перспективы технологии Data Mining. 11 2.7 Внедрение Data Mining В СППР. 12 3 СИСТЕМЫ ПОДДЕРЖКИ ПРИНЯТИЯ РЕШЕНИЙ.. 14 3.1 Понятие и основные компоненты СППР. 14 3.2 Классификация СППР. 16 3.3 Архитектура СППР. 17 Список использованных источников. 22
ПРОБЛЕМА ОБРАБОТКИ ДАННЫХ Современное состояние человеческого общества характеризуется высоким развитием уровня техники, сложностью используемых технологических процессов, эффективностью различных видов связи и коммуникаций. Поэтому в целом состояние человеческого общества характеризуется наличием интенсивных потоков информации, которые воздействуют на составные части и элементы структуры человеческой цивилизации, и связывают их в единое целое. В 60-х годах XX века появился термин «информационный взрыв», смысл которого состоит в том, что бурное развитие техники, технологии и связи привело к необходимости обрабатывать данные такого большого объема и в такие ограниченные сроки по времени, что требуемая скорость переработки информации и принятия решений в ряде случаев оказалась на пределе человеческих возможностей. С другой стороны, научный прогресс достиг стадии развития, когда фундаментальные естественнонаучные закономерности были открыты и исследованы, а новые взгляды на природу оказались столь сложны, что организация исследований и разработка теории стали решаться лишь на уровне больших исследовательских коллективов.
С практическим применением ЭВМ возникла возможность в первую очередь резко ускорить процесс переработки информации. Это сразу перевело в разряд практических многие теоретические задачи, исследование которых ранее было просто невозможно из-за большого объема вычислений. Ориентация на вычисления с помощью ЭВМ дала толчок новому этапу в развитии различных разделов научной теории и, прежде всего, вычислительной математики. Использование ЭВМ позволило справиться не только с большим объемом вычислений, но и с большим объемом поступающих на простую обработку данных. Тем самым снималась угроза «информационного взрыва» и в обычной, ненаучной жизни человеческого общества. В свою очередь, совершенствование математических методов обработки экспериментальных данных в направлении увеличения их объема и скорости их обработки с одной стороны, и все более сильная интеграция и взаимосвязь различных составных частей структуры человеческого общества с другой стороны, привели к использованию математических методов обработки данных не только в технических областях, но и в нетрадиционных сферах – медицине, биологии, экономике, экологии, социологии. Возросшая сложность процессов в технике и технологии, сложность научных теорий и большая интенсивность информационных потоков в современном обществе привели к необходимости учитывать как можно больше информации об изучаемом явлении для того, чтобы адекватно описать его с учетом всей совокупности взаимосвязей и мешающих воздействий. Такая необходимость приводит к тому, что в ходе экспериментов приходится накапливать большие объемы информации или, другими словами, большие массивы данных, а также применять специальные методы их обработки. В связи с необходимостью обработки больших массивов экспериментальных данных исследователи обратили внимание на следующие обстоятельства, которым раньше просто не придавали значения. Во-первых, экспериментальные данные, как правило, не содержат в явном виде информации о наиболее существенных свойствах изучаемого явления. Как правило, экспериментальные данные накапливаются при измерении некоторых величин на объекте исследования. В то же время наиболее существенные свойства изучаемого явления оказываются, как правило, его внутренними, глубинными характеристиками, недоступными для непосредственного измерения.
Во-вторых, возникает вопрос о том, что является полезной информацией в большом массиве данных. Поэтому возникает необходимость в специальных процедурах формирования массива данных и его обработке с целью выделения полезной информации. В-третьих, экспериментальные данные и результат их обработки могут иметь самое разное представление. Например, массив данных может иметь традиционный вид матрицы, или может быть представлен в виде графа или кривой. Тогда возникает необходимость либо преобразования в более традиционную форму, либо разработки специфических методов обработки. Часто результат исследования выражается не в виде численных значений существенных свойств изучаемого явления, а в виде информации о типах его возможных состояний. Таким образом, целью обработки является получение типологии. Необходимость решения задач построения и анализа типологий самого разного вида привела к появлению, в отличие от традиционных методов обработки количественных данных, новых методов обработки качественных данных [1]. Большое распространение, начиная с 90-х годов XX века, получил интеллектуальный анализ данных (Data Mining).
Введение в Data Mining В прошлом процесс добычи золота в горной промышленности состоял из выбора участка земли и дальнейшего ее просеивания большое количество раз. Иногда искатель находил несколько ценных самородков или мог натолкнуться на золотоносную жилу, но в большинстве случаев он вообще ничего не находил и шел дальше к другому многообещающему месту или же вовсе бросал добывать золото, считая это занятие напрасной тратой времени. Сегодня появились новые научные методы и специализированные инструменты, сделавшие горную промышленность намного более точной и производительной. Data Mining для данных развилась почти таким же способом. Старые методы, применявшиеся математиками и статистиками, отнимали много времени, чтобы в результате получить конструктивную и полезную информацию [2]. Традиционная математическая статистика, долгое время претендовавшая на роль основного инструмента анализа данных, откровенно спасовала перед лицом возникших проблем. Главная причина – концепция усреднения по выборке, приводящая к операциям над фиктивными величинами. Методы математической статистики оказались полезными главным образом для проверки заранее сформулированных гипотез и для «грубого» разведочного анализа, составляющего основу оперативной аналитической обработки данных (online analytical processing, OLAP). В основу современной технологии Data Mining положена концепция шаблонов (паттернов), отражающих фрагменты многоаспектных взаимоотношений в данных. Эти шаблоны представляют собой закономерности, свойственные подвыборкам данных, которые могут быть компактно выражены в понятной человеку форме. Поиск шаблонов производится методами, не ограниченными рамками априорных предположений о структуре выборке и виде распределений значений анализируемых показателей.
Важное положение Data Mining – нетривиальность разыскиваемых шаблонов. Это означает, что найденные шаблоны должны отражать неочевидные, неожиданные регулярности в данных, составляющие так называемые скрытые знания. К обществу пришло понимание, что сырые данные содержат глубинный пласт знаний, при грамотной раскопке которого могут быть обнаружены настоящие самородки. Data Mining появилась в 1989 г. и используется во многих областях, где обрабатываются большие наборы данных: астрономия, биология, медицина, физика, банковское дело, телекоммуникации и т.д. Технология Google и других поисковых систем в Интернете основана на методах Data Mining. Современные виды информации – не только числа, но и тексты, звук, изображения, видео. Одно из наиболее развивающихся направлений Data Mining с применением в разных областях – это анализ связей между данными, который особенно актуален для биоинформатики, цифровых библиотек и защиты от терроризма [3].
Понятие Data Mining Термин Data Mining получил свое название из двух понятий: поиска ценной информации в большой базе данных (data) и добычи горной руды (mining). Оба процесса требуют или просеивания огромного количества сырого материала, или разумного исследования и поиска искомых ценностей. Термин Data Mining часто переводится как добыча данных, извлечение информации, раскопка данных, интеллектуальный анализ данных, средства поиска закономерностей, извлечение знаний, анализ шаблонов, «извлечение зерен знаний из гор данных», раскопка знаний в базах данных, информационная проходка данных, «промывание» данных. Понятие «обнаружение знаний в базах данных» можно считать синонимом Data Mining. Что же такое Data Mining? Data Mining – мультидисциплинарная область, возникшая и развивающаяся на базе таких наук как прикладная статистика, распознавание образов, искусственный интеллект, теория баз данных и др. Технологию Data Mining достаточно точно определяет Григорий Пиатецкий-Шапиро – один из основателей этого направления: «Data Mining – это процесс обнаружения в сырых данных ранее неизвестных, нетривиальных, практически полезных и доступных интерпретации знаний, необходимых для принятия решений в различных сферах человеческой деятельности». Суть и цель технологии Data Mining можно охарактеризовать так: это технология, которая предназначена для поиска в больших объемах данных неочевидных, объективных и полезных на практике закономерностей.
Неочевидных – это значит, что найденные закономерности не обнаруживаются стандартными методами обработки информации или экспертным путем. Объективных – это значит, что обнаруженные закономерности будут полностью соответствовать действительности, в отличие от экспертного мнения, которое всегда является субъективным. Практически полезных – это значит, что выводы имеют конкретное значение, которому можно найти практическое применение. Приведем еще несколько определений понятия Data Mining. Data Mining – это процесс выделения из данных неявной и неструктурированной информации и представления ее в виде, пригодном для использования. Data Mining – это процесс выделения, исследования и моделирования больших объемов данных для обнаружения неизвестных до этого структур (patterns) с целью достижения преимуществ в бизнесе (определение SAS Institute). Data Mining – это процесс, цель которого – обнаружить новые значимые корреляции, образцы и тенденции в результате просеивания большого объема хранимых данных с использованием методик распознавания образцов плюс применение статистических и математических методов (определение Gartner Group).
Методы анализа данных В технологии Data Mining гармонично объединились строго формализованные методы и методы неформального анализа, т.е. количественный и качественный анализ данных. Основу методов Data Mining составляют всевозможные методы классификации, моделирования и прогнозирования. К методам Data Mining нередко относят статистические методы (дескриптивный анализ, корреляционный и регрессионный анализ, факторный анализ, дисперсионный анализ, компонентный анализ, дискриминантный анализ, анализ временных рядов). Такие методы, однако, предполагают некоторые априорные представления об анализируемых данных, что несколько расходится с целями Data Mining (обнаружение ранее неизвестных нетривиальных и практически полезных знаний). Одно из важнейших назначений методов Data Mining состоит в наглядном представлении результатов вычислений, что позволяет использовать инструментарий Data Mining людьми, не имеющих специальной математической подготовки. В то же время, применение статистических методов анализа данных требует хорошего владения теорией вероятностей и математической статистикой. Знания, добываемые методами Data mining, принято представлять в виде моделей. Методы построения таких моделей принято относить к области искусственного интеллекта. К методам и алгоритмам Data Mining относятся: 1. искусственные нейронные сети;
Большинство аналитических методов, используемые в технологии Data Mining – это известные математические алгоритмы и методы. Новым в их применении является возможность их использования при решении тех или иных конкретных проблем, обусловленная появившимися возможностями технических и программных средств. Следует отметить, что большинство методов Data Mining были разработаны в рамках теории искусственного интеллекта. Различные методы Data Mining характеризуются определенными свойствами, которые могут быть определяющими при выборе метода анализа данных. Методы можно сравнивать между собой, оценивая характеристики их свойств. Основные свойства и характеристики методов Data Mining: точность, масштабируемость, интерпретируемость, проверяемость, трудоемкость, гибкость, быстрота и популярность. Масштабируемость – свойство вычислительной системы, которое обеспечивает предсказуемый рост системных характеристик, например, быстроты реакции, общей производительности и пр., при добавлении к ней вычислительных ресурсов. Каждый из методов имеет свои сильные и слабые стороны. Но ни один метод, какой бы не была его оценка с точки зрения присущих ему характеристик, не может обеспечить решение всего спектра задач Data Mining [4].
Классификация СППР По взаимодействию с пользователем выделяют три вида СППР:
По способу поддержки различают:
По сфере использования выделяют общесистемные и настольные СППР. Общесистемные работают с большими системами хранения данных и применяются многими пользователями. Настольные являются небольшими системами и подходят для управления с персонального компьютера одного пользователя.
Архитектура СППР На сегодняшний день можно выделить четыре наиболее популярных типа архитектур систем поддержки принятия решений:
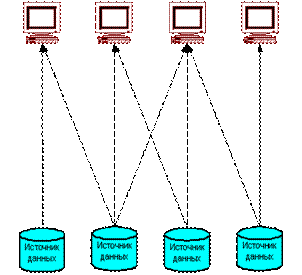
Функциональная СППР (рисунок 1) является наиболее простой с архитектурной точки зрения. Такие системы часто встречаются на практике, в особенности в организациях с невысоким уровнем аналитической культуры и недостаточно развитой информационной инфраструктурой.
Рисунок 1 – Функциональная СППР Характерной чертой функциональной СППР является то, что анализ осуществляется с использованием данных из оперативных систем. Преимущества:
Недостатки:
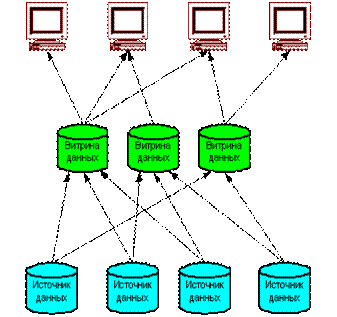
СППР с использованием независимых витрин данных. Независимые витрины данных (рисунок 2) часто появляются в организации исторически и встречаются в крупных организациях с большим количеством независимых подразделений, зачастую имеющих свои собственные отделы информационных технологий.
Рисунок 2 – Независимые витрины данных
Преимущества:
Недостатки:
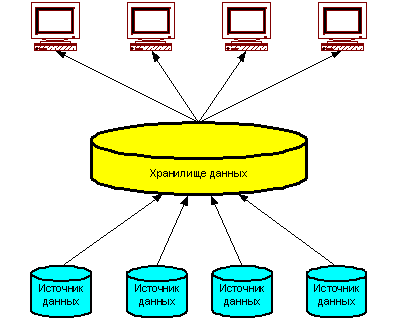
СППР на основе двухуровневого хранилища данных. Двухуровневое хранилище данных (рисунок 3) строится централизованно для предоставления информации в рамках компании. Для поддержки такой архитектуры необходима выделенная команда профессионалов в области хранилищ данных.
Рисунок 3 – Двухуровневое хранилище данных
Это означает, что вся организация должна согласовать все определения и процессы преобразования данных. Преимущества:
Недостатки:
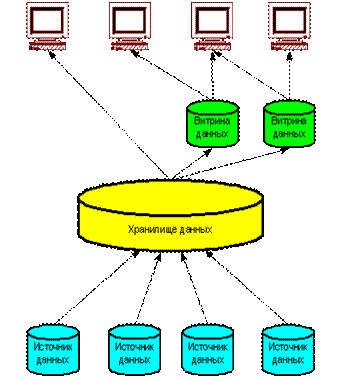
СППР на основе трёхуровневого хранилища данных. Хранилище данных представляет собой единый централизованный источник корпоративной информации. Витрины данных представляют подмножества данных из хранилища, организованные для решения задач отдельных подразделений компании. Конечные пользователи имеют возможность доступа к детальным данным хранилища, в случае если данных в витрине недостаточно, а также для получения более полной картины состояния бизнеса.
Рисунок 4 – Трёхуровневое хранилище данных
Преимущества:
Недостатки:
Независимо от архитектуры, любая СППР позволяет облегчить работу руководителям предприятий и повысить ее эффективность. Они значительно ускоряют решение проблем в бизнесе. СППР способствуют налаживанию межличностного контакта. На их основе можно проводить обучение и подготовку кадров. Данные информационные системы позволяют повысить контроль над деятельностью организации. Наличие четко функционирующей СППР дает большие преимущества по сравнению с конкурирующими структурами. Благодаря предложениям, выдвигаемым СППР, открываются новые подходы к решению повседневных и нестандартных задач [6].
МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ РФ Филиал ФЕДЕРАЛЬНОГО ГОСУДАРСТВЕННОГО БЮДЖЕТНОГО ОБРАЗОВАТЕЛЬНОГО УЧРЕЖДЕНИЯ ВЫСШЕГО ПРОФЕССИОНАЛЬНОГО ОБРАЗОВАНИЯ
Кафедра вычислительной техники
Доклад
|
|||||||||||||||
|
|
Последнее изменение этой страницы: 2017-02-10; просмотров: 329; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.217.109.151 (0.059 с.) |