Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Основные показатели корпоративных сетей компьютеровСтр 1 из 19Следующая ⇒
Три компоненты КИС • 1. Корпоративные сети компьютеров • 2. Технологии и средства организации и обработки корпоративных данных • 3. Безопасность информационных ресурсов
Основные показатели корпоративных сетей компьютеров Производственные информационные ресурсы, обеспечивающие деятельность крупных организаций и предприятий, имеющих развитые инфраструктуры организационного управления, являются, как правило, корпоративными. Компьютерные сети, построенные для информатизации деятельности подобных организаций, называются корпоративными сетями (Enterprise Networks) и характеризируется следующими особенностями: • Во-первых, это большое количество объединяемых в общую сеть компьютеров, в том числе - файловых серверов, серверов баз данных и приложений. • Во-вторых, гетерогенный характер сети: различные протоколы, разнородные среды передачи данных, компьютерные платформы и средства коммутации, произведенные разными компаниями, различные операционные системы и т.п. • В-третьих, корпоративность сети полагает, что функциональные задачи отдельных подсистем могут быть существенно различными, хотя в целом сеть ориентируется на решение единой задачи крупной системы организационного управления. • Наконец, корпоративные сети характеризуются, как правило, наличием многих производственных площадок, распределенных в определенном региональном масштабе. • Наряду с этим корпоративные сети должны обладать расширяемостью и масштабируемостью, что однозначно определяется функциональными возможностями выбранных сетевых аппаратно - программных средств.
Механизмы маршрутизации: прямое соединение Прямое соединение - это маршрут, который является локальным по отношению к маршрутизатору. Если один из интерфейсов маршрутизатора соединен, с какой либо сетью напрямую, то при получении пакета, адресованного такой подсети, маршрутизатор сразу отправляет пакет на интерфейс к которому она подключена, не используя протоколы маршрутизации (Рисунок 2.4).
Прямые соединения всегда являются наилучшим способом маршрутизации. Поскольку маршрутизатору всегда известна непосредственно присоединенная к нему сеть, пакеты, предназначенные для нее, направляются из первых рук, и маршрутизатор не полагается на другие средства определения маршрутов, например на статические или динамические механизмы маршрутизации.
Внутренние (Interior Gateway Protocol) Длина префикса сети Маршруты выбираются и встраиваются в таблицу маршрутизации на основе административного расстояния протокола маршрутизации. Маршруты с наименьшим административным расстоянием, полученные от протокола маршрутизации, устанавливаются в таблицу маршрутизации. Если к одному месту назначения существует несколько путей, основанных на одном протоколе маршрутизации, эти будут иметь одинаковые административные расстояния. В этом случае оптимальный путь будет выбираться на основе метрики. Метрики — это значения, привязанные к определенным маршрутам, и классифицирующие их от наиболее предпочтительных до наименее предпочтительных. Параметры, используемые для расчета метрик, зависят от протокола маршрутизации. Путь с самой низкой метрикой выбирается в качестве оптимального пути и устанавливается в таблицу маршрутизации. Если к одному месту назначения существует несколько путей с одинаковыми метриками, нагрузка распределяется по этим путям. В алгоритмах маршрутизации используется много различных показателей. Сложные алгоритмы маршрутизации при выборе маршрута могут базироваться на множестве показателей, комбинируя их таким образом, что в результате получается один отдельный (гибридный) показатель. Ниже перечислены показатели, которые используются в алгоритмах маршрутизации: 1. Длина маршрута 2. Надежность 3. Задержка 4. Ширина полосы пропускания 5. Нагрузка 6. Стоимость связи Длина маршрута Длина маршрута является наиболее общим показателем маршрутизации. Некоторые протоколы маршрутизации позволяют администраторам сети назначать произвольные цены на каждый канал сети. В этом случае длиной тракта является сумма расходов, связанных с каждым каналом, который был траверсирован. Другие протоколы маршрутизации определяют "количество пересылок", т.е. показатель, характеризующий число проходов, которые пакет должен совершить на пути от источника до пункта назначения через изделия об'единения сетей (такие как роутеры).
Надежность Надежность, в контексте алгоритмов маршрутизации, относится к надежности каждого канала сети (обычно описываемой в терминах соотношения бит/ошибка). Некоторые каналы сети могут отказывать чаще, чем другие. Отказы одних каналов сети могут быть устранены легче или быстрее, чем отказы других каналов. При назначении оценок надежности могут быть приняты в расчет любые факторы надежности. Оценки надежности обычно назначаются каналам сети администраторами сети. Как правило, это произвольные цифровые величины. Задержка Под задержкой маршрутизации обычно понимают отрезок времени, необходимый для передвижения пакета от источника до пункта назначения через об'единенную сеть. Задержка зависит от многих факторов, включая полосу пропускания промежуточных каналов сети, очереди в порт каждого роутера на пути передвижения пакета, перегруженность сети на всех промежуточных каналах сети и физическое расстояние, на которое необходимо переместить пакет. Т.к. здесь имеет место конгломерация нескольких важных переменных, задержка является наиболее общим и полезным показателем. Полоса пропускания Полоса пропускания относится к имеющейся мощности трафика какого-либо канала. При прочих равных показателях, канал Ethernet 10 Mbps предпочтителен любой арендованной линии с полосой пропускания 64 Кбайт/сек. Хотя полоса пропускания является оценкой максимально достижимой пропускной способности канала, маршруты, проходящие через каналы с большей полосой пропускания, не обязательно будут лучше маршрутов, проходящих через менее быстродействующие каналы. Протокол OSPF OSPF (англ. Open Shortest Path First) — протокол динамической маршрутизации, основанный на технологии отслеживания состояния канала (link-state technology) и использующий для нахождения кратчайшего пути Алгоритм Дейкстры (Dijkstra’s algorithm). Протокол OSPF был разработан IETF в 1988 году. Последняя версия протокола представлена в RFC 2328. Протокол OSPF представляет собой протокол внутреннего шлюза (Interior Gateway Protocol — IGP). Протокол OSPF распространяет информацию о доступных маршрутах между маршрутизаторами одной автономной системы. 1. Маршрутизаторы обмениваются hello-пакетами через все интерфейсы, на которых активирован OSPF. Маршрутизаторы, разделяющие общий канал передачи данных, становятся соседями, когда они приходят к договоренности об определённых параметрах, указанных в их hello-пакетах. 2. На следующем этапе работы протокола маршрутизаторы будут пытаться перейти в состояние смежности со своими соседями. Переход в состояние смежности определяется типом маршрутизаторов, обменивающихся hello-пакетами, и типом сети, по которой передаются hello-пакеты. OSPF определяет несколько типов сетей и несколько типов маршрутизаторов. Пара маршрутизаторов, находящихся в состоянии смежности, синхронизирует между собой базу данных состояния каналов. 3. Каждый маршрутизатор посылает объявления о состоянии канала маршрутизаторам, с которыми он находится в состоянии смежности. 4. Каждый маршрутизатор, получивший объявление от смежного маршрутизатора, записывает передаваемую в нём информацию в базу данных состояния каналов маршрутизатора и рассылает копию объявления всем другим смежным с ним маршрутизаторам.
5. Рассылая объявления внутри одной OSPF-зоны, все маршрутизаторы строят идентичную базу данных состояния каналов маршрутизатора. 6. Когда база данных построена, каждый маршрутизатор использует алгоритм «кратчайший путь первым» для вычисления графа без петель, который будет описывать кратчайший путь к каждому известному пункту назначения с собой в качестве корня. Этот граф — дерево кратчайших путей. 7. Каждый маршрутизатор строит таблицу маршрутизации из своего дерева кратчайших путей. Преимущества OSPF: 1. Для каждого адреса может быть несколько маршрутных таблиц, по одной на каждый вид IP-операции (TOS). 2. Каждому интерфейсу присваивается безразмерная цена, учитывающая пропускную способность, время транспортировки сообщения. Для каждой IP-операции может быть присвоена своя цена (коэффициент качества). 3. При существовании эквивалентных маршрутов OSFP распределяет поток равномерно по этим маршрутам. 4. Поддерживается адресация субсетей (разные маски для разных маршрутов). 5. При связи точка-точка не требуется IP-адрес для каждого из концов. (Экономия адресов!) 6. Применение мультикастинга вместо широковещательных сообщений снижает загрузку не вовлеченных сегментов. Недостатки: 1. Трудно получить информацию о предпочтительности каналов для узлов, поддерживающих другие протоколы, или со статической маршрутизацией. 2. OSPF является лишь внутренним протоколом. Примечание Существует и четвертый тип области – магистральная. Но магистраль автономной системы OSPF на самом деле не является областью в том же смысле, как три основных типа. Магистраль просто создается из всех маршрутизаторов, не вошедших ни в одну из областей. Назначение магистрали состоит в соединении областей АС друг с другом и с любыми внешними сетями. Прежде чем перейти к рассмотрению того, что делает область каждого типа и как они влияют на общую производительность сети OSPF, следует хорошо представлять себе смысл образования областей. Область диктует правила, полностью определяющие работу содержащихся в ней маршрутизаторов. Маршрутизаторы области имеют достоверную информацию (полученную из первоисточника) только друг о друге. Хотя бы один маршрутизатор области должен заниматься обеспечением связи области с другими областями или с магистралью (магистраль – это множество маршрутизаторов, оставшихся вне основных областей).
Такой маршрутизатор называется пограничным маршрутизатором области (ABR). Маршрутизаторы области имеют прямой доступ к сведениям только друг о друге. При необходимости отправить информацию в другую область они могут переслать пакеты на ABR, который доставит их за пределы области, при этом пакеты будут снабжены косвенными данными о среде маршрутизации. Используя эти данные, маршрутизаторы области могут правильно адресовать пакеты, направляемые в другие области той же АС. Если области необходима связь с магистралью автономной системы, но она находится за другой областью, можно сконфигурировать виртуальный канал. Виртуальный канал – это канал, идущий от ABR к промежуточному ABR и завершающийся в магистральной области. (При создании виртуальных каналов необходимо придерживаться нескольких важных правил, о которых будет рассказано в разделе «Конфигурирование OSPF».) Примечание При конфигурировании виртуального канала транзитная область не может быть тупиковой. Маршрутизаторы области получают информацию о внешних маршрутах посредством такого процесса, как объявление маршрутов. Шлюз автономной области, используя EGP, собирает LSA_информацию от внешних автономных систем. Затем шлюз пересылает эту информацию через магистраль на пограничные маршрутизаторы области. ABR ретранслируют информацию о маршрутах всем маршрутизаторам области, которые используют ее для отправки данных за пределы автономной системы. Рассылка маршрутов может быть обременительной для области из_за дополнительного трафика и множества сообщений LSA. Поэтому, если область непосредственно связана с магистралью АС, вы можете уберечь ее от лишнего трафика, связанного с объявлениями маршрутов, сделав область тупиковой. Тупиковые области Тупиковая область – это область, которая специально предназначена для того, чтобы не принимать информацию о маршрутах от областей, находящихся вне АС. Создание тупиковых областей может уменьшить трафик и освободить ресурсы, занятые под обработку дополнительных обновлений. Основным критерием при формировании тупиковой области является то, что она должна быть напрямую связана с магистралью автономной системы. Маршрутизаторы магистрали имеют неявные сведения о внешних для автономной системы маршрутах. Поэтому маршрутизаторы тупиковой области, которым нужно отправить информацию по внешнему маршруту, могут пересылать такие пакеты в магистральную область, что может привести к дополнительной нагрузке на некоторые из наиболее занятых маршрутизаторов АС. Не совсем тупиковые области (NSSA) NSSA – это тупиковая область, в которой запрограммированы пряме пути к внешним автономным системам. Как и в тупиковых областях, маршрутизаторы внутри NSSA освобождены от дополнительного трафика по распространению информации о маршрутах. Однако они могут достичь некоторых внешних маршрутов, используя предопределенные маршруты. При конфигурировании маршрутизатора задается информация, необходимая для достижения некоторых внешних по отношению к АС маршрутов.
NSSA не должны быть прямо связаны с магистралью автономной системы. Так как маршрутизаторы обладают информацией, необходимой для правильной адресации пакетов, эти пакеты могут пересылаться через другие области. Но недостаток NSSA в том, что входящие в такую область маршрутизаторы могут достичь не любого внешнего маршрута, а только того, о котором у них имеются заранее введенные сведения. Примечание Несмотря на то что область, не соединенная непосредственно с магистралью, может функционировать, не рекомендуется создавать такие области. Многие документы Cisco настойчиво советуют не делать этого. Чертой, отличающей тупиковые и не совсем тупиковые области от остальных, является их неспособность получать и обрабатывать информацию о маршрутах. Автономные системы передают сведения о своїй внутренней структуре другим областям посредством процесса, носящего название «перераспределение маршрутов». Это процесс делает возможной связь между АС. Области OSPF В link-state протоколах маршрутизации, все маршрутизаторы должны иметь копии LSDB. Чем больше маршрутизаторов (и больше каналов между ними), тем больше база LSDB. С одной стороны знание обо всех маршрутах можно отнести к преимуществу, но такой подход не применим к масштабированию в больших сетях. Подход с использованием зон - это компромис. Маршрутизаторы внутри зоны содержат детальную информацию обо всех каналах и маршрутизаторах этой зоны. OSPF можно настроить так, чтобы только общая или суммированная информация о маршрутизаторах и каналах других областей была в БД на маршрутизаторах этой области. Если OSPF настроен правильно и отказывает канал и маршрутизатор, информация распространяется соседям в пределах этой зоны. Маршрутизаторы за зоной не получают эту информацию. Придерживаясь иерархической структуры и ограничивая число маршрутизаторов в зоне, можно масштабировать OSPF AS до очень больших размеров. Транзитная область (Backbone area). Промежуточный тип OSPF-области внутри одного домена, главной функцией которого является быстра и эффективная пересылка пакетов. В транзитной области нет конечных пользователей. Она связана с другими типами зон. Область 0 является транзитной областью или ядром. § Обычная область (Regular area). Соединяет пользователей и ресурсы. Обычные области, как правило, устанавливаются по функциональному или географическому принципу. По умолчанию, обычная область не передает трафик от одной области к другой. Такой трафик должен передаваться через транзитную область. Обычная (немагистральная) область имеет ряд разновидностей: standard area, stub-area, totally stubby area (или totally NSSA, или totally stub NSSA, not-so-stubby area (NSSA). OSPF усиливает эту жесткую двухуровневую иерархию. Структура физических соединение должна быть отображена на двухуровневую иерархию областей, где все немагистральные области должны подключаться непосредственно к области 0.
Примеры конфигураций протокола OSPF Маршрутизатор R1: R1(config)#routerospf 1 R2(config)#routerospf 1 R3(config)#routerospf 1 R1(config-router)#end Заголовок пакета OSPF · Version — номер версии протокола OSPF, текущая версия OSPF для сетей IPv4 — 2; · Type — тип OSPF-пакета; · Packet length — длина пакета, включая заголовок; · Router ID — идентификатор маршрутизатора, уникальное 32-битное число, идентифицирующее маршрутизатор в пределах автономной системы; · Area ID — 32-битный идентификатор зоны; · Checksum — поле контрольной суммы, подсчитывается для всего пакета, включая заголовок; · Authentication type — тип используемой схемы аутентификации, возможные значения: · 0 — аутентификация не используется · 1 — аутентификация открытым текстом · 2 — MD5-аутентификация · Authentication — поле данных аутентификации. Существует 5 типов пакета OSPF: 1. Hello. Отправляется через регулярные интервалы времени для установления и поддержания соседских взаимоотношений. 2. Database Description. Описание базы данных. Описывает содержимое базы данных; обмен этими пакетами производится при инициализации смежности. 3. Link-State Request Запрос о состоянии канала. Запрашивает части топологической базы данных соседа. Обмен этими пакетами производится после того, как какой-нибудь роутер обнаруживает, (путем проверки пакетов описания базы данных), что часть его топологической базы данных устарела. 4. Link-State Update Корректировка состояния канала. Отвечает на пакеты запроса о состоянии канала. Эти пакеты также используются для регулярного распределения LSA. В одном пакете могут быть включены несколько LSA. 5. Link-State Acknowledgement Подтверждение состояния канала. Подтверждает пакеты корректировки состояния канала. Пакеты корректировки состояния канала должны быть четко подтверждены, что является гарантией надежности процесса лавинной адресации пакетов корректировки состояния канала через какую-нибудь область.
Hello-пакет Hello-пакет предназначен для установления и поддержания отношений с соседями. Пакет периодически посылается на все интерфейсы маршрутизатора. · Network mask — сетевая маска интерфейса, через который отправляется hello-пакет; · Hello interval — интервал задающий частоту рассылки приветственных сообщений для обнаружения соседей в автономной системе, для LAN значение по умолчанию равно 10 секундам; · Options — 8-битное поле опций, описывает возможности маршрутизатора; · Router priority — приоритет маршрутизатора, 8-битное число, символизирующее приоритет маршрутизатора при выборе DR (англ. Designated router) и BDR (англ. Backup designated router); · Router dead interval — период времени, в течение которого маршрутизатор ожидает ответа соседей; · Designated router (DR) — IP-адрес DR; · Backup designated router (BDR) — IP-адрес BDR; · Neighbor ID — идентификатор соседа. Список составляется из идентификаторов соседей, от которых маршрутизатор получил hello-пакеты в течение времени, заданного в поле router dead interval; Database Description Пакет Database Description описывает содержание базы данных состояния канала. Обмен пакетами производится при установлении состояния смежности. · Interface MTU — размер в байтах наибольшей IP дейтаграммы, которая может быть послана через данный интерфейс без фрагментации; · I-бит — устанавливается для первого пакета в последовательности; · M-бит — указывает наличие последующих дополнительных пакетов; · MS-бит — устанавливается для ведущего, сбрасывается для ведомого; · DD sequence number — в начальном пакете устанавливается на уникальное значение, при передаче каждого последующего пакета увеличивается на единицу, пока не будет передана вся база данных; · LSA headers — массив заголовков базы данных состояния каналов. Link State Request Пакет Link State Request предназначен для запроса части базы данных соседнего маршрутизатора. · LS Type — тип объявления о состоянии канала; · Link State ID — идентификатор домена маршрутизации; · Advertising Router — идентификатор маршрутизатора, создавшего объявление о состоянии канала. Link State Update Пакет Link State Update предназначен для рассылки объявлений о состоянии канала. Пакет посылается по групповому адресу на один транзитный участок. · Number of LSA — количество объявлений в пакете. Link State Acknowledgment Подтверждает получение пакета Link State Update. Состояние маршрутизаторов Маршрутизаторы, использующие протоколы состояния канала, периодически отправляют друг другу обновления. Эти обновления, называемые LSA (link state advertisements – объявления состояния канала), сообщают каждому маршрутизатору статус (состояние) каждого маршрутизатора (канала) среды. New - состояние когда процесс установления соседства только начинается. Маршрутизатор переходит в это состояние в момент загрузки или при настройке начальной конфигурации протокола. One-Way - маршрутизатор переходит в это состояние после Hello. Машрутизатор находится в этом состоянии пока не будет получен Hello пакет содержащий адрес локального маршрутизатора в качестве соседа. Initializing - состояние в которое переходит маршрутизатор при получении Hello пакета в котром указан его собственный локальный адрес в качестве соседа. Это состояние означает, что была установлена двунаправленная связь. Up - состояние полного функционирования отношений. Это состояние означает, что были сформированы отношения соседства и произошла синхронизация баз данных маршрутизаторов. Down - состояние утерянного соседства. Маршрутизатор переходит в это состояние по одной из нескольких причин: несоответствие зоны (area), окончание таймаута удержания или ошибка аутентификации. Reject - состояние маршрутизатора после сбоя проверки подлинности. Маршрутизатор будет постоянно менять свое состояние между этим и состоянием Down. Данные против Информации
Многомерная модель данных Реляционные СУБД предназначались для информационных систем оперативной обработки информации и в этой области весьма эффективны. В системах аналитической обработки они показали себя несколько неповоротливыми и недостаточно гибкими. Более эффективными здесь оказываются многомерные СУБД. Многомерные СУБД являются узкоспециализированными СУБД, предназначенными для интерактивной аналитической обработки информации. Основные понятия, используемые в этих СУБД: агрегируемость, историчность и прогнозируемость. Агрегируемость данных означает рассмотрение информации на различных уровнях ее обобщения. В информационных системах степень детальности представления информации для пользователя зависит от его уровня: аналитик, пользователь, управляющий, руководитель. Историчность данных предполагает обеспечение высокого уровня статичности собственно данных и их взаимосвязей, а также обязательность привязки данных ко времени. Прогнозируемость данных подразумевает задание функций прогнозирования и применение их к различным временным интервалам.Многомерность модели данных означает не многомерность визуализации цифровых данных, а многомерное логическое представление структуры информации при описании и в операциях манипулирования данными. По сравнению с реляционной моделью многомерная организация данных обладает более высокой наглядностью и информативностью. Измерение – это множество однотипных данных, образующих одну из граней гиперкуба. В многомерной модели измерения играют роль индексов, служащих для идентификации конкретных значений в ячейках гиперкуба. Ячейка – это поле, значение которого однозначно определяется фиксированным набором измерений. Тип поля чаще всего определен как цифровой. В зависимости от того, как формируются значения некоторой ячейки, она может быть переменной (значения изменяются и могут быть загружены из внешнего источника данных или сформированы программно) либо формулой (значения, подобно формульным ячейкам электронных таблиц, вычисляются по заранее заданным формулам). Основным достоинством многомерной модели данных является удобство и эффективность аналитической обработки больших объемов данных, связанных со временем. Недостатком многомерной модели данных является ее громоздкость для простейших задач обычной оперативной обработки информации. Примерами систем, поддерживающими многомерные модели данных, является Essbase, MediaMulti — matrix, OracleExpressServer, Cache. Существуют программные продукты, например Media / MR, позволяющие одновременно работать с многомерными и с реляционными БД.
MOLAP технология MOLAP (Multidimensional OLAP) — многомерноеконцептуальноепредставление. Являетсобоймножественную систему, состоящуюизнесколькихнезависимыхизмерений, вдолькоторыхмогутбытьпроанализированыопределенныесовокупностиданных. Одновременныйанализ по несколькимизмерениямопределяетсякакмногомерныйанализ. MOLAP — это классическая форма OLAP, так что её часто называют просто OLAP. Она использует суммирующую БД, специальный вариант процессора пространственных БД и создаёт требуемую пространственную схему данных с сохранением как базовых данных, так и агрегатов. Преимущества MOLAP: -высокая производительность. Поиск и выборка данных производятся намного быстрее, чем в реляционных базах данных -структура и интерфейсы наилучшим образом соответствуют структуре аналитических запросов -многомерные СУБД легко справляются с интеграцией в информационную модель разнообразных дополнительных функций Недостатки MOLAP: -MOLAP могут работать только со своими собственными многомерными БД и основываются на патентованных лицензионных решениях для многомерных СУБД, что отражается на цене. Такие технологии обеспечивают полный цикл OLAP-обработки и либо включают в себя, помимо серверного модуля, собственный интегрированный клиентский интерфейс, либо используют для связи с пользователем внешние программы работы с электронными таблицами -низкие показатели эффективности использования внешней памяти, худшие, по сравнению с реляционными, БД механизмы транзакций -Отсутствуют единые стандарты на интерфейс, языки описания и управления данными -Не поддерживают репликацию данных, часто используемую в качестве механизма загрузки
ROLAP технология ROLAP (реляционная OLAP) — OLAP-системы, которыеимеютпрямой доступ к существующим базам данныхилииспользуютданные, выгруженные в собственныелокальныетаблицы. ROLAP работает напрямую с реляционным хранилищем, факты и таблицы с измерениями хранятся в реляционных таблицах, и для хранения агрегатов создаются дополнительные реляционные таблицы. ROLAP-системы имеют свои преимущества и недостатки в сравнении с многомерными системами. Достоинства · реляционные СУБД могут работать с очень большими БД и имеют развитые функции администрирования. При использовании ROLAP размер хранилища не является настолько важным параметром, как в случае с MOLAP · при оперативной аналитической обработке содержимого хранилища данных инструменты ROLAP позволяют производить анализ непосредственно над хранилищем, ведь обычно корпоративные хранилища данных реализуются с помощью реляционных СУБД · при изменяющейся размерности задачи, когда изменения в структуру измерений вносятся достаточно часто, ROLAP системы с динамическим представлением размерности предстают наилучшим решением, так как в них такие манипуляции не требуют физической реорганизации БД. · Системы ROLAP могут функционировать на гораздо менее мощных клиентских станциях, поскольку основная вычислительная нагрузка приходится на сервер, где выполняются сложные аналитические SQL-запросы, формируемые системой · реляционные СУБД обеспечивают значительно более высокий уровень защиты данных и хорошие возможности разграничения прав доступа Недостатки · Ограниченные возможности расчета значений функционального типа. · Меньшая производительность, чем у MOLAP. Для обеспечения сравнимой с MOLAP производительности реляционные системы требуют тщательной проработки схемы БД и специальной настройки индексов. Но в результате такой работы производительность хорошо настроенных реляционных систем при использовании схемы «звезда» сравнима с производительностью систем на основе многомерных БД.
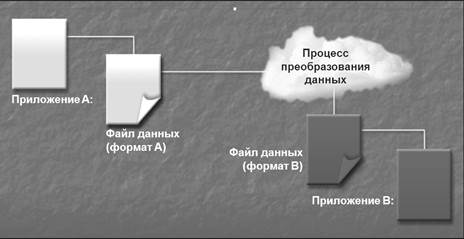
HOLAP технология HOLAP (Hybrid OLAP) используетреляционныетаблицы для хранениябазовыхданных и многомерныетаблицы для агрегатов HOLAP использует реляционные таблицы для хранения базовых данных и многомерные таблицы для агрегатов. Уровнипринятиярешений EAI, B2B, BPA EnterpriseApplicationIntegration (EAI) — это технологии и приложения, задача которых вовлечь несколько приложений, используемых в одной организации, в единый процесс и осуществлять преобразование форматов данных между ними. Необходимость в интеграции приложений обычно возникает, если информационные системы разработаны различными производителями. А также если количество информационных систем достаточно велико, так что осуществлять интеграцию между каждой парой из них ресурсозатратно. B2B -системы обычнобываютдвухтипов - открытые (public) и закрытые, иликорпоративные (private). Этапы интеграции Интеграция данных включает объединение данных, находящихся в различных источниках и предоставление данных пользователям в унифицированном виде. Этот процесс становится существенным как в коммерческих задачах (когда двум похожим компаниям необходимо объединить их базы данных), так и в научных (комбинирование результатов исследования из различных биоинформационных репозиториев, для примера). Роль интеграции данных возрастает, когда увеличивается объём и необходимость совместного использования данных Информационные системы многих компаний представляют собой набор приложений, автоматизирующих отдельные бизнес-задачи. Эти системы, как правило, почти не связаны друг с другом на технологическом уровне, а данные в них часто не согласованы между собой. Автоматизация и управление бизнес процессами (Business Process Automation (BPA) состоит из EAI (Интеграция приложений внутри предприятия) и B2B (Взаимодействие с партнерами по бизнесу).
Enterprice Application Integration (EAI) Интеграция приложений внутри предприятия
Этапы EAI:
Взаимодействие с партнерами по бизнесу (Business To Business (B2B))
Пример структуры информационно-аналитической системы: общая схема
Пример структуры информационно-аналитической системы: подсистема мониторинга
Пример. Подсистема учета производства инженерных изысканий
Подсистема учета производства инженерных изысканий предназначена для автоматизации функций регистрации разрешений на производство инженерных изысканий, выдачи исходных данных (картматериалов) для производства инженерных изысканий, приема отчетов по инженерных изысканиям.
Подсистема выполняет следующие функции: · ввод информации о разрешении на производство инженерных изысканий (пространственные и реестровые данные); · поиск и отображение разрешений на производство инженерных изысканий; · формирование разрешений на производство инженерных изысканий; · сохранение и отображение документов – разрешений на производство инженерных изысканий; · формирование документа – перечень планшетов, выданных изыскательской организации для производства инженерных изысканий; · поиск и отображение планшетов, выданных изыскательской организации; · учет изменений, вносимых на планшете (история исправлений); · ввод информации об отчетах по инженерным изысканиям (реквизиты отчета); · поиск и отображение информации по отчетам по инженерным изысканиям. Подсистема позволяет вести следующие реестры: · реестр входящих обращений (заявок); · реестр разрешений на производство инженерных изысканий; · реестр планшетов (картматериалов); · реестр отчетов по инженерным изысканиям.
Пример структуры информационно-аналитической системы: аналитическая подсистема
Пример. Информационно-аналитическая подсистема АСУ Чеченской Республики (ИАП АСУ ЧР)
· сбор, предварительная обработка, накопление и хранение информационных ресурсов, характеризующих различные сферы жизнедеятельности Республики; · анализ информации и прогноз развития сфер жизнедеятельности Республики;
|
|||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2017-02-10; просмотров: 284; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.222.117.109 (0.139 с.) |