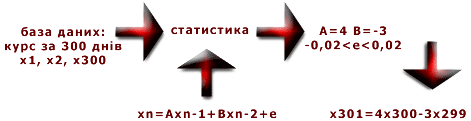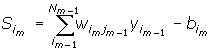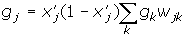Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Тема 1. Перспективні дослідження і розробки по інтелектуальних системахСтр 1 из 28Следующая ⇒
Тема 1. Перспективні дослідження і розробки по інтелектуальних системах
Комп'ютерні системи стають банальністю. Дійсно, вони майже повсюдні. Вони є найважливим компонентом у функціонуванні бізнесу, урядового, військового, навколишнього середовища, установах охорони здоров'я і є частиною багатьох освітніх програм навчання. Ці комп'ютерні системи, все більш і більш впливаючи на наше життя мають бути спроможними швидко адаптуватися, змінюватись та допомагати нам і нашим установам справлятися з непередбаченими можливостями світу. Національна конкурентноздатність залежить від можливостей доступу, обробки та аналізу інформації. Аналіз і передача даних за допомогою комп'ютера надали нам велику кількість інформації. Однак, щоб досягти повного співробітництва, комп'ютерні системи повинні вміти більше, ніж обробляти інформацію, але і мати інтелект. Вони повинні кваліфіковано зберігати й використовувати великі обсяги інформації й ефективно допомагати людям знаходити нові шляхи рішення проблем, використовуючи більш природні засоби комунікації. Щоб перебороти обмеження існуючих систем, потрібно зрозуміти шляхи і способи взаємодії людей між собою і зі світом, розробити методи для з'єднання людського інтелекту і комп'ютерних систем. Для вирішення цього призначені аналітичні технології. Аналітичні технології - це методики, які на основі певних моделей, алгоритмів, математичних теорем дозволяють по відомих даних оцінити значення невідомих характеристик і параметрів. Найпростіший приклад аналітичної технології - теорема Піфагора, що дозволяє по довжинах сторін прямокутника визначити довжину його діагоналі. Ця технологія заснована на відомій формулі с2=а2+b2. Іншим прикладом аналітичної технології є способи, за допомогою яких людський мозок обробляє інформацію. Навіть мозок дитини може вирішувати задачі, непідвласні сучасним комп'ютерам, такі як розпізнавання знайомих облич у юрбі, чи ефективне керування декількома десятками м'язів при грі у футбол. Унікальність мозку полягає в тому, що він здатен навчатися рішенню нових задач - грі в шахи, водінню автомобіля і т.д. Проте, мозок погано пристосований до обробки великих обсягів числової інформації - людина не зможе знайти навіть квадратний корінь з числа 463761, не використовуючи калькулятора або алгоритму обчислення в стовпчик. На практиці ж часто зустрічаються задачі про числа, набагато більш складні, ніж витяг кореня. Таким чином, людині для рішення таких задач необхідні додаткові методики й інструменти.
Традиційні технології Детерміновані технології Аналітичні технології типу теореми Піфагора використовуються людиною вже багато століть. За цей час була створена величезна кількість формул, теорем і алгоритмів для рішення класичних задач - визначення об'ємів, рішення систем лінійних рівнянь, пошуку коренів багаточленів. Розроблено складні й ефективні методи для рішення задач оптимального керування, рішення диференційних рівнянь і т.д. Всі ці методи діють по однієї і тій же схемі.
Для застосування алгоритму необхідно, щоб дана задача цілком описувалася визначеною детермінованою моделлю (деяким набором відомих функцій і параметрів). У такому випадку алгоритм дає точну відповідь. Наприклад, для застосування теореми Піфагора потрібно перевірити, що трикутник - прямокутний.
Імовірнісні технології На практиці часто зустрічаються задачі, пов'язані зі спостереженням випадкових величин - наприклад, задача прогнозування курсу акцій. Для подібних задач не можна побудувати детерміновані моделі, тому застосовується принципово інший, імовірнісний підхід. Параметри імовірнісних моделей - це розподіли випадкових величин, їхні середні значення, дисперсії і т.д. Як правило, ці параметри заздалегідь невідомі, а для їхньої оцінки використовуються статистичні методи, що застосовуються до вибірок спостережених значень (історичних даних).
Такого роду методи припускають, що відомо деяка імовірнісна модель задачі. Наприклад, у задачі прогнозування курсу можна припустити, що завтрашній курс акцій залежить тільки від курсу за останні 2 дні (авторегресійна модель). Якщо це вірно, то спостереження курсу протягом декількох місяців дозволяють досить точно оцінити коефіцієнти цієї залежності і прогнозувати курс у майбутньому.
Приклади реальних задач Прогнозування курсу акцій Задача. Трейдеру фондового ринку потрібно щоденний прогноз поведінки курсу акцій енергетичного підприємства. Дано. Значення котувань і різних ринкових індикаторів за останній рік. Також відомі котування нафтових і вугільних компаній, а також міських компаній-енергоспоживачів, що тісно зв'язані з курсом акцій ЄЕС. Традиційне рішення. Використовуються методики технічного аналізу, кореляційного аналізу, статистика. Нові технології В останні 10 років іде активний розвиток аналітичних систем нового типу. В їх основі - технології штучного інтелекту, що імітують природні процеси, наприклад, такі як діяльність нейронів мозку процес або природного відбору. Інтелектуальні аналітичні системи містять у собі:
Розуміння цих можливостей у людях і втілення їх при розробці програм є центральним у створеннях новітніх аналітичних технологій, що здатні здобувати знання та керувати ними. Національна конкурентноздатність залежить від зростання потужностей для проведення інформаційного аналізу, прийняття рішення, гнучкого проектування та виробництва. Зусилля в цих областях були обмежені недостатніми даними, відсутністю обчислювальної потужності або неадекватними контролюючими механізмами. Багато з цих обмежень можуть бути усунені тільки при додаванні інтелекту до систем. Визначення Data Mining Data Mining переводиться як "видобуток" чи "розкопка даних". Нерідко поруч з Data Mining зустрічаються слова "інтелектуальний аналіз даних". Справа в тому, що людський розум сам по собі не пристосований для сприйняття великих масивів різнорідної інформації. Людина до того ж не здатна уловлювати більш двох-трьох взаємозв'язків навіть у невеликих вибірках. Але і традиційна математична статистика, яка довгий час претендувала на роль основного інструмента аналізу даних, також нерідко пасує при рішенні задач з реального складного життя. Вона оперує усередненими характеристиками вибірки, що часто є фіктивними величинами (типу середньої температури пацієнтів по лікарні, середньої висоти будинку на вулиці, що складається з палаців і халуп і т.п.). Тому методи математичної статистики виявляються корисними, головним чином, для перевірки заздалегідь сформульованих гіпотез. Data Mining і OLAP У професіоналів обробки даних часто виникає питання про різницю між засобами інтелектуального аналізу і засобами OLAP (On-Line Analytical Processing) - засобами оперативної аналітичної обробки. OLAP - це частина технологій, скерованих на підтримку ухвалення рішення. Звичайні засоби формування запитів і звітів описують саму базу даних. Технологія OLAP використовується для відповіді на задані питання. При цьому користувач сам формує гіпотезу про дані чи відношення між даними і після цього використовує серію запитів до бази даних для підтвердження чи відхилення цих гіпотез. Засоби Data Mining відрізняються від засобів OLAP тим, що замість перевірки передбачуваних взаємозалежностей, вони на основі наявних даних можуть робити моделі, що дозволяють кількісно оцінити ступінь впливу досліджуваних факторів. Крім того, засоби інтелектуального аналізу дозволяють робити нові гіпотези про характер невідомих, але реально існуючих відношень у даних.
Сучасні технології інтелектуального аналізу перелопачують інформацію з метою автоматичного пошуку шаблонів (патернів), характерних для яких-небудь фрагментів неоднорідних багатомірних даних. На відміну від оперативної аналітичної обробки даних у Data Mining тягар формулювання гіпотез і виявлення незвичайних шаблонів перекладено з людини на комп'ютер. Data Mining і сховища даних Для успішного проведення всього процесу знаходження нового знання необхідною умовою є наявність сховища даних. Принципи побудови сховищ - це дуже велика тема, що заслуговує окремого курсу лекцій. Обмежимося лише основними принципами побудови сховища даних. Отже, сховище даних - це предметно-орієнтований, інтегрований, прив'язаний до часу, незмінний збір даних для підтримки процесу прийняття керівних рішень. Предметна орієнтація означає, що дані об'єднані в категорії і зберігаються відповідно до тих областей, що вони описують, а не до застосувань, що їх використовують. Інтегрованість означає, що дані задовольняють вимогам усього підприємства (у його розвитку), а не єдиної функції бізнесу. Тим самим сховище даних гарантує, що однакові звіти, згенеровані для різних аналітиків, будуть містити однакові результати. Прив'язка до часу означає, що сховище можна розглядати як сукупність "історичних" даних: можна відновити картину на будь-який момент часу. Атрибут часу завжди є явно присутнім у структурах сховища даних. Незмінність означає, що, потрапивши один раз у сховище, дані вже не змінюються на відміну від оперативних систем, де дані зобов'язані бути присутніми тільки в останній версії, оскільки постійно змінюються. У сховище дані лише долучаються. Для рішення переліченого ряду задач, що неминуче виникають при організації й експлуатації інформаційного сховища, повинно існувати спеціалізоване програмне забезпечення. Сучасні засоби адміністрування сховища даних мають забезпечити ефективну взаємодію з інструментарієм знаходження нового знання.
Історія нейронних мереж Вивченню людського мозку - тисячі років. З появою сучасної електроніки, почались спроби апаратного відтворення процесу мислення. Перший крок був зроблений у 1943 р. з виходом статті нейрофізіолога Уоррена Маккалоха (Warren McCulloch) і математика Уолтера Піттса (Walter Pitts) про роботу штучних нейронів і представлення моделі нейронної мережі на електричних схемах.
Ранні успіхи, були підставою того, що люди перебільшили потенціал нейронних мереж, зокрема в світлі обмеженої на ті часи електроніки. Надмірне сподівання, яке квітнуло у академічному та технічному світах, заразило загальну літературу цього часу. Побоювання у тому, як ефект "мислячої машини" відіб'ється на людині весь час підігрівався письменниками, зокрема, серія книг Азімова про роботів показала наслідки на моральних цінностях людини, у випадку спроможності інтелектуальних роботів виконувати функції людини. Ці побоювання, об'єднані з невиконаними обіцянками, викликали множину розчарувань фахівців, які критикували дослідження нейронних мереж. Результатом було припинення більшості фінансування. Цей період спаду продовжувався до 80-х років.
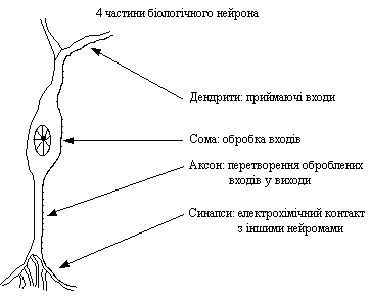
Сьогодні, обговорення нейронних мереж відбуваються скрізь. Перспектива їх використання видається досить яскравою, в світлі вирішення нетрадиційних проблем і є ключем до цілої технології. На даний час більшість розробок нейронних мереж принципово працюючі, але можуть існувати процесорні обмеження. Дослідження скеровані на програмні та апаратні реалізації нейромереж. Компанії працюють над створенням трьох типів нейрочіпів: цифрових, аналогових та оптичних, що обіцяють бути хвилею близького майбутнього. Аналогія з мозком Точна робота мозку людини - все ще таємниця. Проте деякі аспекти цього дивовижного процесора відомі. Базовим елементом мозку людини є специфічні клітини, відомі як нейрони, що здатні запам'ятовувати, думати і застосовувати попередній досвід до кожної дії, що коренево відрізняє їх від решта клітин тіла. Кора головного мозку людини є протяжною, утвореною нейронами поверхнею товщиною від 2 до 3 мм із площею близько 2200 см2, що вдвічі перевищує площу поверхні стандартної клавіатури. Кора головного мозку містить близько 1011 нейронів, що приблизно дорівнює числу зірок Чумацького шляху. Кожен нейрон зв'язаний з 103 - 104 іншими нейронами. У цілому мозок людини містить приблизно від 1014 до 1015 взаємозв'язків. Сила людського розуму залежить від числа базових компонент, різноманіття з'єднань між ними, а також від генетичного програмування й навчання. Індивідуальний нейрон є складним, має свої складові, підсистеми та механізми керування і передає інформацію через велику кількість електрохімічних зв'язків. Налічують біля сотні різних класів нейронів. Разом нейрони та з'єднання між ними формують недвійковий, нестійкий та несинхронний процес, що різниться від процесу обчислень традиційних комп'ютерів. Штучні нейромережі моделюють лише найголовніші елементи складного мозку, що надихає науковців та розробників до нових шляхів розв'язування проблеми. Біологічний нейрон Нейрон (нервова клітка) складається з тіла клітини - соми (soma), і двох типів зовнішніх деревоподібних відгалужень: аксона (axon) і дендритів (dendrites). Тіло клітини вміщує ядро (nucleus), що містить інформацію про властивості нейрона, і плазму, яка продукує необхідні для нейрона матеріали. Нейрон отримує сигнали (імпульси) від інших нейронів через дендрити (приймачі) і передає сигнали, згенеровані тілом клітки, вздовж аксона (передавач), що наприкінці розгалужується на волокна (strands). На закінченнях волокон знаходяться синапси (synapses).
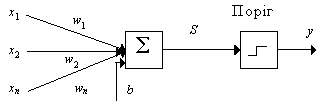
Рис. 1. Схема біологічного нейрона Синапс є функціональним вузлом між двома нейронами (волокно аксона одного нейрона і дендрит іншого). Коли імпульс досягає синаптичного закінчення, продукуються хімічні речовини, названі нейротрансмітерами. Нейротрансмітери проходять через синаптичну щілину, збуджуючи або гальмуючи, у залежності від типу синапсу, здатність нейрона-приймача генерувати електричні імпульси. Результативність синапсу налаштовується минаючими через нього сигналами, тому синапси навчаються в залежності від активності процесів, у яких вони приймають участь. Нейрони взаємодіють за допомогою короткої серії імпульсів. Повідомлення передається за допомогою частотно-імпульсної модуляції. Останні експериментальні дослідження доводять, що біологічні нейрони структурно складніші, ніж спрощене пояснення, наведене вище і значно складніші, ніж існуючі штучні нейрони, які є елементами сучасних штучних нейронних мереж. Оскільки нейрофізіологія надає науковцям розширене розуміння дії нейронів, а технологія обчислень постійно вдосконалюється, розробники мереж мають необмежений простір для вдосконалення моделей біологічного мозку. Штучний нейрон Базовий модуль нейронних мереж штучний нейрон моделює основні функції природного нейрона (рис. 2).
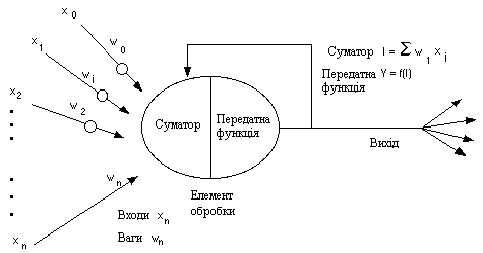
Рис. 2. Базовий штучний нейрон Вхідні сигнали xn зважені ваговими коефіцієнтами з'єднання wn додаються, проходять через передатну функцію, генерують результат і виводяться. У наявних на цей час пакетах програм штучні нейрони називаються "елементами обробки" і мають набагато більше можливостей, ніж простий штучний нейрон, описаний вище. На рис. 3 зображена детальна схема спрощеного штучного нейрону.
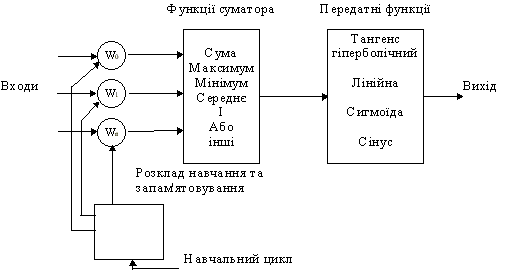
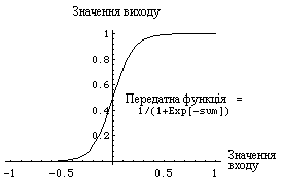
Рис. 3. Модель "елементу обробки" Модифіковані входи передаються на функцію сумування, яка переважно тільки сумує добутки. Проте можна обрати багато різних операцій, такі як середнє, найбільше, найменше, OR, AND, тощо, які могли б виробляти деяку кількість різних значень. Окрім того, більшість комерційних програм дозволяють інженерам-програмістам створювати власні функції суматора за допомогою підпрограм, закодованих на мові високого рівня (C, С++, TurboPascal). Інколи функція сумування ускладнюється додаванням функції активації, яка дозволяє функції сумування оперувати в часі. В любому з цих випадків, вихід функції сумування надсилається у передатну функцію і скеровує весь ряд на дійсний вихід (0 або 1, -1 або 1, або яке-небудь інше число) за допомогою певного алгоритму. В існуючих нейромережах в якості передатних функцій можуть бути використані сигмоїда, синус, гіперболічний тангенс та ін. Приклад того, як працює передатна функція показаний на рис. 4.
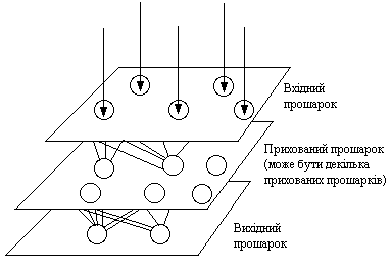
Рис. 4. Сигмоїдна передаточна функція Після обробки сигналу, нейрон на виході має результат передатної функції, який надходить на входи інших нейронів або до зовнішнього з'єднання, як це передбачається структурою нейромережі. Всі штучні нейромережі конструюються з базового формуючого блоку - штучного нейрону. Існуючі різноманітності і фундаментальні відмінності, є підставою мистецтва талановитих розробників для реалізації ефективних нейромереж. Штучні нейронні мережі Інша частина створення і використання нейромереж стосується нескінченої кількості зв'язків, що пов'язують окремі нейрони. Групування у мозку людини відбувається так, що інформація обробляється динамічним, інтерактивним та самоорганізуючим шляхом. Біологічні нейронні мережі створені у тривимірному просторі з мікроскопічних компонент і здатні до різноманітних з'єднань. Але для створеної людиною мережі існують фізичні обмеження. Існуючі на даний час, нейромережі є групуванням штучних нейронів. Це групування обумовлено створенням з'єднанних між собою прошарків.
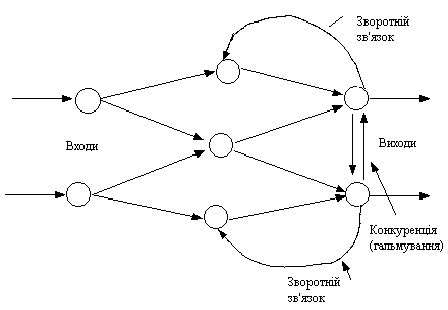
Рис. 5. Діаграма простої нейронної мережі На рис. 5 показана типова структура штучних нейромереж. Хоча існують мережі, які містять лише один прошарок, або навіть один елемент, більшість застосувань вимагають мережі, які містять як мінімум три нормальних типи прошарків - вхідний, прихований та вихідний. Прошарок вхідних нейронів отримує дані або з вхідних файлів, або безпосередньо з електронних давачів. Вихідний прошарок пересилає інформацію безпосередньо до зовнішнього середовища, до вторинного комп'ютерного процесу, або до інших пристроїв. Між цими двома прошарками може бути багато прихованих прошарків, які містять багато нейронів у різноманітних зв'язаних структурах. Входи та виходи кожного з прихованих нейронів просто йдуть до інших нейронів. Напрямок зв'язку від одного нейрону до іншого є важливим аспектом нейромереж. У більшості мереж кожен нейрон прихованого прошарку отримує сигнали від всіх нейронів попереднього прошарку та звичайно від нейронів вхідного прошарку. Після виконання операцій над сигналами, нейрон передає свій вихід до всіх нейронів наступних прошарків, забезпечуючи шлях передачі вперед (feedforward) на вихід. При зворотньому зв'язку, вихід нейронів прошарку скеровується до нейронів попереднього прошарку (рис. 6).
Шлях, яким нейрони з'єднуються між собою має значний вплив на роботу мережі. Більшість пакетів професіональної розробки програмного забезпечення дозволяють користувачу додавати, вилучати та керувати з'єднаннями як завгодно. Постійно коректуючі параметри, зв'язки можна робити як збуджуючими так і гальмуючими. Компоненти штучного нейрона Незалежно від розташування та функціонального призначення, всі штучні нейронні елементи мають спільні компоненти. Розглянемо сім основних компонент штучного нейрона. Компонента 4. Масштабування Після передатної функції вихідний сигнал проходить додаткову обробку масштабування, тобто результат передатної функції множиться на масштабуючий коефіцієнт і додається зміщення. Контрольоване навчання Величезна більшість рішень отримана від нейромереж з контрольованим навчанням, де біжучий вихід постійно порівнюється з бажаним виходом. Ваги на початку встановлюються випадково, але під час наступних ітерацій коректуються для досягнення близької відповідності між бажаним та біжучим виходом. Створені методи навчання націлені на мінімізації біжучих похибок всіх елементів обробки, яке створюється за якийсь час неперервною зміною синаптичних ваг до досягнення прийнятної точності мережі. Перед використанням, нейромережа з контрольованим навчанням повинна бути навченою. Фаза навчання може тривати багато часу, зокрема, у прототипах систем, з невідповідною процесорною потужністю навчання може займати декілька годин. Навчання вважається закінченим при досягненні нейромережею визначеного користувачем рівня ефективності. Цей рівень означає, що мережа досягла бажаної статистичної точності, оскільки вона видає бажані виходи для заданої послідовності входів. Після навчання ваги з'єднань фіксуються для подальшого застосування. Деякі типи мереж дозволяють під час використання неперервне навчання, з набагато повільнішою оцінкою навчання, що допомагає мережі адаптуватись умов, що повільно змінюються. Навчальні множини повинні бути досить великими, щоб містити всю необхідну інформацію для виявлення важливих особливостей і зв'язків. Але і навчальні приклади повинні містити широке різноманіття даних. Якщо мережа навчається лише для одного прикладу, ваги старанно встановлені для цього прикладу, радикально змінюються у навчанні для наступного прикладу. Попередні приклади при навчанні наступних просто забуваються. В результаті система повинна навчатись всьому разом, знаходячи найкращі вагові коефіцієнти для загальної множини прикладів. Наприклад, у навчанні системи розпізнавання піксельних образів для десяти цифр, які представлені двадцятьма прикладами кожної цифри, всі приклади цифри "сім" не доцільно представляти послідовно. Краще надати мережі спочатку один тип представлення всіх цифр, потім другий тип і так далі. Головною компонентою для успішної роботи мережі є представлення і кодування вхідних і вихідних даних. Штучні мережі працюють лише з числовими вхідними даними, отже, необроблені дані, що надходять із зовнішнього середовища повинні перетворюватись. Додатково необхідне масштабування, тобто нормалізація даних відповідно до діапазону всіх значень. Нормалізація виконується шляхом ділення кожної компоненти вхідного вектора на довжину вектора, що перетворює вхідний вектор в одиничний. Попередня обробка зовнішніх даних, отриманих за допомогою сенсорів, у машинний формат спільна для стандартних комп'ютерів і є легко доступною. Якщо після контрольованого навчання нейромережа ефективно опрацьовує дані навчальної множини, важливим стає її ефективність при роботі з даними, які не використовувались для навчання. У випадку отримання незадовільних результатів для тестової множини, навчання продовжується. Тестування використовується для забезпечення запам'ятовування не лише даних заданої навчальної множини, але і створення загальних образів, що можуть міститись в даних. Неконтрольоване навчання Неконтрольоване навчання може бути великим надбанням у майбутньому. Воно проголошує, що комп'ютери можуть самонавчатись у справжньому роботизованому сенсі. На даний час, неконтрольоване навчання використовується мережах відомих, як самоорганізовані карти (self organizing maps), що знаходяться в досить обмеженому користуванні, але доводячи перспективність самоконтрольованого навчання. Мережі не використовують зовнішніх впливів для коректування своїх ваг і внутрішньо контролюють свою ефективність, шукаючи регулярність або тенденції у вхідних сигналах та роблять адаптацію згідно навчальної функції. Навіть без повідомлення правильності чи неправильності дій, мережа повинна мати інформацію відносно власної організації, яка закладена у топологію мережі та навчальні правила. Алгоритм неконтрольованого навчання скерований на знаходження близькості між групами нейронів, які працюють разом. Якщо зовнішній сигнал активує будь-який вузол в групі нейронів, дія всієї групи в цілому збільшується. Аналогічно, якщо зовнішній сигнал в групі зменшується, це приводить до гальмуючого ефекту на всю групу. Конкуренція між нейронами формує основу для навчання. Навчання конкуруючих нейронів підсилює відгуки певних груп на певні сигнали. Це пов'язує групи між собою та відгуком. При конкуренції змінюються ваги лише нейрона-переможця. Оцінки навчання Оцінка ефективності навчання нейромережі залежить від декількох керованих факторів. Теорія навчання розглядає три фундаментальні властивості, пов'язані з навчанням: ємність, складність зразків і обчислювальна складність. Під ємністю розуміють, скільки зразків може запам'ятати мережа, і які межі прийняття рішень можуть бути на ній сформовані. Складність зразків визначає число навчальних прикладів, необхідних для досягнення здатності мережі до узагальнення. Обчислювальна складність напряму пов'язана з потужністю процесора ЕОМ. Правила навчання У загальному використанні є багато правил навчання, але більшість з цих правил є деякою зміною відомого та найстаршого правила навчання, правила Хеба. Дослідження різних правил навчання триває, і нові ідеї регулярно публікуються в наукових та комерційних виданнях. Представимо декілька основних правил навчання. Правило Хеба Опис правила з'явився у його книзі "Організація поведінки" у 1949 р. "Якщо нейрон отримує вхідний сигнал від іншого нейрону і обидва є високо активними (математично мають такий самий знак), вага між нейронами повинна бути підсилена". При збудженні одночасно двох нейронів з виходами (хj, уі) на t-тому кроці навчання вага синаптичного з'єднання між ними зростає, в інакшому випадку - зменшується, тобто D Wij (k)= r xj (k) yi (k), де r - коефіцієнт швидкості навчання. Може застосовуватись при навчанні "з вчителем" і "без вчителя". Правило Хопфілда Є подібним до правила Хеба за винятком того, що воно визначає величину підсилення або послаблення. "Якщо одночасно вихідний та вхідний сигнал нейрона є активними або неактивними, збільшуємо вагу з'єднання оцінкою навчання, інакше зменшуємо вагу оцінкою навчання". Правило "дельта" Це правило є подальшою зміною правила Хеба і є одним із найбільш загально використовуваних. Це правило базується на простій ідеї неперервної зміни синаптичних ваг для зменшення різниці ("дельта") між значенням бажаного та біжучого вихідного сигналу нейрона. D Wij = xj (di - yi). За цим правилом мінімізується середньоквадратична похибка мережі. Це правило також згадується як правило навчання Відрова-Хофа та правило навчання найменших середніх квадратів. У правилі "дельта" похибка отримана у вихідному прошарку перетворюється похідною передатної функції і послідовно пошарово поширюється назад на попередні прошарки для корекції синаптичних ваг. Процес зворотного поширення похибок мережі триває до досягнення першого прошарку. Від цього методу обчислення похибки успадкувала своє ім'я відома парадигма FeedForward BackPropagation. При використанні правила "дельта" важливим є невпорядкованість множини вхідних даних. При добре впорядкованому або структурованому представленні навчальної множини результат мережі може не збігтися до бажаної точності і мережа буде вважатись нездатною до навчання. Правило градієнтного спуску Це правило подібне до правила "дельта" використанням похідної від передатної функції для змінювання похибки "дельта" перед тим, як застосувати її до ваг з'єднань. До кінцевого коефіцієнта зміни, що діє на вагу, додається пропорційна константа, яка пов'язана з оцінкою навчання. І хоча процес навчання збігається до точки стабільності дуже повільно, це правило поширене і є загально використовуване. Доведено, що різні оцінки навчання для різних прошарків мережі допомагає процесу навчання збігатись швидше. Оцінки навчання для прошарків, близьких до виходу, встановлюються меншими, ніж для рівнів, ближчих до входу. Навчання методом змагання На відміну від навчання Хеба, у якому множина вихідних нейронів може збуджуватись одночасно, при навчанні методом змагання вихідні нейрони змагаються між собою за активізацію. Це явище, відоме як правило "переможець отримує все". Подібне навчання має місце в біологічних нейронних мережах. Навчання за допомогою змагання дозволяє кластеризувати вхідні дані: подібні приклади групуються мережею відповідно до кореляцій і представляються одним елементом. При навчанні модифікуються синаптичні ваги нейрона-переможця. Ефект цього правила досягається за рахунок такої зміни збереженого в мережі зразка (вектора синаптичних ваг нейрона-переможця), при якому він стає подібним до вхідного приклада. Нейрон з найбільшим вихідним сигналом оголошується переможцем і має можливість гальмувати своїх конкурентів і збуджувати сусідів. Використовується вихідний сигнал нейрона-переможця і тільки йому та його сусідам дозволяється коректувати свої ваги з'єднань. D Wij (k +1)= Wij (k)+ r [ xj - Wij (k)]. Розмір області сусідства може змінюватись під час періоду навчання. Звичайна парадигма повинна починатись з великої області визначення сусідства і зменшуватись під час процесу навчання. Оскільки елемент-переможець визначається по найвищій відповідності до вхідного зразку, мережі Коxонена моделюють розподіл входів. Це правило використовується в самоорганізованих картах. Перцептрон Розенбалата Першою моделлю нейромереж вважають перцептрон Розенбалата. Теорія перцептронів є основою для багатьох типів штучних нейромереж прямого поширення і вони є класикою для вивчення. Одношаровий перцептрон здатний розпізнавати найпростіші образи. Окремий нейрон обчислює зважену суму елементів вхідного сигналу, віднімає значення зсуву і пропускає результат через жорстку порогову функцію, вихід якої дорівнює +1 чи -1. В залежності від значення вихідного сигналу приймається рішення:
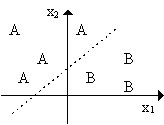
На рис. 1 показана схема нейронів, використовуваних в одношарових перцептронах, графік передатної функції і схема вирішальних областей, створених у багатовимірному просторі вхідних сигналів. Вирішальні області визначають, які вхідні образи будуть віднесені до класу A, які - до класу B. Перцептрон, що складається з одного нейрона, формує дві вирішальні області, розділені гіперплощиною. На рисунку показаний випадок, коли розмірність вихідного сигналу дорівнює 2. При цьому поділяюча поверхня уявляє собою пряму лінію на площині. Рівняння, що задає поділяючу пряму, залежить від значень синаптичних ваг і зсуву.
Рис. 1. Схема нейрона, графік передатної функції і поділяюча поверхня Алгоритм навчання мережі
yim = f (Sjm) im =1, 2,..., Nm, m =1, 2,..., L де S - вихід суматора, w - вага зв'язку, y - вихід нейрона, b - зсув, i - номер нейрона, N - число нейронів у прошарку, m - номер прошарку, L - число прошарків, f - передатна функція.
wij (t +1)= wij (t)+ rgjx'і де wij - вага від нейрона i або від елемента вхідного сигналу i до нейрона j у момент часу t, xi ' - вихід нейрона i, r - швидкість навчання, gj - значення похибки для нейрона j. Якщо нейрон з номером j належить останньому прошарку, тоді gj = yj (1- yj)(dj - yj) де dj - бажаний вихід нейрона j, yj - поточний вихід нейрона j. Якщо нейрон з номером j належить одному з прошарків з першого по передостанній, тоді
|
|||||||||
|
|
Последнее изменение этой страницы: 2017-02-05; просмотров: 411; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.133.108.241 (0.112 с.) |