Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Структура программы на ассемблере
Программа на ассемблере представляет собой совокупность блоков памяти, называемых сегментами. Программа может состоять из одного или нескольких таких блоков-сегментов. Сегменты программы имеют определенное назначение, соответствующее типу сегментов: кода, данных и стека. Названия типов сегментов отражают их назначение. Деление программы на сегменты отражает сегментную организацию памяти процессоров Intel (архитектура IA-32). Каждый сегмент состоит из совокупности отдельных строк, в терминах теории компиляции называемых предложениями языка. В описании предложений ассемблера могут быть компоненты, которые могут быть пропущены. Из принято заключать в квадратные скобки. Для языка ассемблера предложения, составляющие программу, могут представлять собой синтаксические конструкции четырех типов. · Команды (инструкции) представляют собой символические аналоги машинных команд. В процессе трансляции инструкции ассемблера преобразуются в соответствующие команды системы команд процессора. · Макрокоманды — это оформляемые определенным образом предложения текста программы, замещаемые во время трансляции другими предложениями. · Директивы - указание транслятору ассемблера на выполнение некоторых действий. У директив нет аналогов в машинном представлении. · Комментарии содержат любые символы, в том числе и буквы русского алфавита. Комментарии игнорируются транслятором. · Понятие о метасинтаксических языках Для распознавания транслятором ассемблера этих предложений их нужно формировать по определенным синтаксическим правилам. Для формального описания синтаксиса языков программирования используются различные метасинтаксические языки, которые представляют собой совокупность условных знаков, образующих нотацию метасинтаксического языка, и правил формирования из этих знаков однозначных описаний синтаксических конструкций целевого языка. В учебных целях для описания синтаксиса Ассемблера удобно использовать синтаксические диаграммы. В них компоненты предложения отображены блоками. Синтаксическая диаграмма предложения ассемблера.
Синтаксическая диаграмма команд и микрокоманд.
Синтаксическая диаграмма директив.
Компоненты диаграмм:
· Имя метки – символьный идентификатор, значением которого является адрес первого байта того предложения исходного текста программы, которое он обозначает. · Имя — идентификатор, отличающий данную директиву от других одноименных директив. Его значением является адрес в таблице сиволов. В результате обработки ассемблером определенной директивы этому имени могут быть присвоены определенные характеристики; · КОП и директива - это мнемоническое обозначения соответствующей машинной команды, макрокоманды или дирекивы ассемблера. · Операнды - объекты, над которыми производятся действия. Операнды ассемблера описываются выражениями с числовыми и текстовыми константами, метками и идентификаторами переменных с использованием знаков операций и некоторых зарезервированных слов. · Комментарий. · Разделитель точка с запятой (;). За ним следует комментарий. · Разделитель запятая (,). Применятся в списке операдов.. · Разделитель вертикальное даоеточие (:). Следует после метки, с его помощью идентифицируется метка. · Лексемы ассемблера Предложения ассемблера формируются из лексем, представляющих собой синтаксически неразделимые последовательности допустимых символов языка, имеющие смысл для транслятора. Вначале определим алфавит ассемблера, то есть допустимые для написания текста программ символы: · Символы АSCII (American Standard Code for Information Interchange – американский стандартный код для обмена информацией). Это все латинские буквы А - Z, а – z. В языке ассеммблера прописные и строчные буквы считаются эквивалентными. · Десятичные цифры от 0 до 9. · специальные знаки _,?, @, $, &. · разделители: „., [ ] () < > { } + / * %! "? \ = #. Лексемами языка ассемблера являются ключевые слова, идентификаторы, цепочки символов и целые числа. Ключевые слова — это служебные символы языка ассемблера. По умолчанию регистр символов ключевых слов не имеет значения. К ключевым словам относятся: · названия регистров - AL, АН, BL, ВН, CL, СН, DL, ОН, АХ, ЕАХ, ВХ, ЕВХ, СХ, ЕСХ, DX, EDX, ВР, EBP, SP, ESP, DI, EDI, SI, ESI, CS, DS, ES, FS, GS, SS, CRO, CR2, CR3, DRO, DRl, DR2, DR3, DR6, DR7. · операторы - BYTE, SBYTE, WORD, SWORD, DWORD, SDWORD, FWORD, QWORD, TBYTE, REAL4, REALS, REAL10, NEAR16, NEAR32, FAR16, FAR32, AND, NOT, HIGH, LOW, HIGHWORD, LOWWORD, OFFSET, SEG, LROFFSET, TYPE, THIS, PTR, WIDTH, MASK, SIZE, SIZEOF, LENGTH, LENGTHOF, ST, SHORT, TYPE, OPATTR, MOD, NEAR, FAR, OR, XOR, EQ, NE, LT, LE, GT, GE, SHR, SHL и др..
· Названия команд (КОП) ассемблера, префиксов. Лексемами являются: · Идентификаторы. · Комментарии. · Зарезервированные слова. · Цепочки символов. · Целые числа. Идентификаторы. Идентификатором называется любое имя, назначенное программистом некоторому объекту программы (переменной, константе или метке). При выборе имен идентификаторов необходимо учитывать правила. · Длина идентификатора до 255 символов, хотя транслятор воспринимает лишь первые 32, а остальные игнорирует. · Первым символом идентификатора должна быть одна из букв латинского алфавита (А.. z или а.. z) либо символы подчеркивания (_), коммерческого "эт" (@) или знак доллара ($). Последующие символы могут быть также цифрами. · Идентификатор не должен совпадать с одним из зарезервированных слов языка ассемблера. Комментарии. Комментарии очень важны для документирования программы. По сути, они являются средством общения разработчика программы с тем, кто булет сопровождать эту программу впоследствии. В начало листинга программы обычно помешается перечисленная ниже информация: · короткое описание назначения программы; · фамилия и имя программиста, кто написал программу или внес в нее изменения; · дата создания программы, а также даты всех последующих изменений в ней. Комментарии в программах бываютдвух видов: · Однострочные, начинающиеся с символа точки с запятой (;). При этом все символы. расположенные после точки с запятой и до конца текущей строки, игнорируюгся компилятором и поэтому могут быть использованы для размещения комментариев к программе. · Блочные, начинающиеся с директивы COMMENT, за которой следует символ комментария, определяемый прграммистом. При этом компилятор игнорирует все строки, расположенные между директивой COMMENT и символом, указанным программистом. Например: COMMENT & Это строка комментария. А вот еще одна строка комментария & Зарезервированные слова. В языке ассемблера существует специальный список так называемых зарезервированных слов. Каждое из этих слов несет определенный смысл и поэтому может использоваться только в заранее оговоренном контексте. Резервными являются слова, перечисленные ниже: · Мнемоники команд, такие как MOV, ADD или MUL, которые соответствуют встроенным командам языка ассемблера, напрямую связанными с машинными командами процессоров семейства IA-32. · Директивы компилятора, которые определяют порядок ассемблирования программ. · Атрибуты, с помощью которых определяются характеристики используемых переменных и операндов, такие как размер, например: ВУТЕ или WORD. · Операторы, используемые в константных выражениях. · Встроенные идентификаторы ассемблера, такие как @data, · Операнды Операнды — это объекты, над которыми или при помощи которых выполняются действия, задаваемые инструкциями или директивами. Машинные команды могут либо совсем не иметь операндов, либо иметь 1 - 3 операнда. Большинство команд требует двух операндов, один из которых является источником, а другой — приемником (операндом назначения). В двухоперандной машинной команде возможны следующие сочетания операндов:
· регистр — регистр, · регистр — память, · память — регистр, · непосредственный операнд — регистр, · непосредственный операнд — память. Один операнд может располагаться в регистре или памяти, а второй операнд обязательно должен находиться в регистре или непосредственно в команде. Непосредственный операнд может быть только источником. Для приведенных ранее правил сочетания типов операндов есть исключения, которые касаются: · команд работы с цепочками, которые могут перемещать данные из памяти в память; · команд работы со стеком, которые могут переносить данные из памяти в стек, также находящийся в памяти; · команд типа умножения, которые, кроме операнда, указанного в команде, неявно используют еще и второй операнд. Операндами могут быть числа, регистры, ячейки памяти, символьные идентификаторы. При необходимости для расчета некоторого значения или определения ячейки памяти, на которую будет воздействовать данная команда или директива, используются выражения, то есть комбинации чисел, регистров, ячеек памяти, идентификаторов с арифметическими, логическими, побитовыми и атрибутивными операторами.Возможно провести следующую классификацию операндов: · постоянные, или непосредственные, операнды, · адресные операнды, · перемещаемые операнды, · счетчик адреса, · регистровый операнд, · стековый, · порт ввода-вывода, · базовый и индексный операнды, · структурные операнды, · записи Непосредственные операнды. Непосредственный операнд задается в самой команде. Это может быть число, строка, имя или выражение, имеющее некоторое фиксированное (константное) значение. Физически непосредственный операнд находится в коде команды, то есть является ее частью. Для его хранения в команде выделяется поле длиной до 32 битов. Непосредственный операнд может быть только вторым операндом (источником). Операнд-приемник может находиться либо в памяти, либо в регистре. Например: · Команда mov ax,0ffffh пересылает в регистр АХ 16-ричную константу Offffh. · Команда add sum,2 складывает содержимое поля по адресу sum с целым числом 2 и записывает результат по месту первого операнда, то есть в память. Если непосредственный операнд - имя, то оно не должно быть перемещаемым, то есть зависеть от адреса загрузки программы. Адресные операнды. Задают физическое расположение операнда в памяти с помощью указания двух составляющих адреса: сегмента (слева от символа вертикального двоеточия) и смещения (справа от него).
Перемещаемые операнды. Это любые символьные имена, представляющие некоторые адреса памяти. Эти адреса могут обозначать местоположение в памяти некоторых инструкции (если операнд — метка) или данных (если операнд — имя области памяти в сегменте данных). Перемещаемые операнды отличаются от адресных тем, что они не привязаны к конкретному адресу физической памяти. Сегментная составляющая адреса перемещаемого операнда неизвестна и будет определена после загрузки программы в память для выполнения. Счетчик адреса. Специфический вид операнда. Он обозначается знаком $. Специфика этого операнда в том, что когда транслятор ассемблера встречает в исходной программе этот символ, то он подставляет вместо него текущее значение счетчика адреса. Значение счетчика адреса представляет собой смещение текущей машинной команды относительно начала сегмента кода. При обработке транслятором очередной команды ассемблера счетчик адреса увеличивается на длину сформированной машинной команды. Обработка директив ассемблера не влечет за собой изменения счетчика. Директивы, в отличие от команд ассемблера, — это лишь указания транслятору на выполнение определенных действий по формированию машинного представления программы, и для них транслятором не генерируется никаких конструкций в памяти. Регистровый операнд. Это просто имя регистра. В программе на ассемблере можно использовать имена всех регистров общего назначения и большинства системных регистров: · 32-разрядные регистры ЕАХ, ЕВХ, ЕСХ, EDX, ESI, EDI, ESP, EBP; · 16-разрядные регистры АХ, ВХ, СХ, DX, SI, DI, SP, ВР; · 8-разрядные регистры АН, AL, BH, BL, CH, CL, DH, DL; · сегментные регистры CS, DS, SS, ES, FS, GS; · системные регистры CRO, CR2, CR3, CR4, DRO, DR1, DR2, DR3, DR6, DR7. Стековый операнд находится в стеке. Стек – раздел памяти для хранения промежуточных значений. Он использует алгоритм доступа LIFO (Last In First Out – последним пришел, первым ушел). Стек в IF-32 растет в сторону младших адресов. Порт ввода-вывода. Помимо адресного пространства оперативной памяти процессор поддерживает адресное пространство ввода-вывода, которое используется для доступа к устройствам ввода-вывода. Объем адресного пространства ввода-вывода составляет 64 Кбайт. Для любого устройства компьютера в этом пространстве выделяются адреса. Конкретное значение адреса в пределах этого пространства называется портом ввода-вывода. Физически портуввода-вывода соответствует аппаратный регистр (не путать с регистром процессора), доступ к которому осуществляется с помощью специальных команд ассемблера IN и OUT. Регистры, адресуемые с помощью порта ввода-вывода, могут иметь разрядность 8,16 или 32 бита, но для конкретного порта разрядность регистра фиксирована. Команды IN и OUT работают с фиксированной номенклатурой объектов. В качестве источника информации или получателя применяются так называемые регистры -аккумуляторы ЕАХ, АХ, AL. Выбор регистра определяется разрядностью порта. Номер порта может задаваться непосредственным операндом в командах IN и OUT или значением в регистре DX. Последний способ позволяет динамически определить номер порта в программе.
Базовый и индексный операнды. Эти типы операндов используется для реализации косвенной базовой, косвенной индексной адресации или их комбинаций и расширений. Структурные операнды. Используются для доступа к конкретному элементу сложного типа данных, называемого структурой. Записи. Аналогично структурному типу используются для доступа к битовому полю некоторой записи. Операторы. Операнд команды может быть выражением, представляющим собой комбинацию операндов и операторов ассемблера. Транслятор ассемблера рассматривает выражение как единое целое и преобразует его в числовую константу. Логически значением этой константы может быть адрес некоторой ячейки памяти или некоторое абсолютное значение. Арифметические операторы. Синтаксис описания:
Индексный оператор. Скобки тоже являются оператором, и транслятор их наличие воспринимает как указание сложить значение выражение_1 за этими скобками с выражение_2, заключенным в скобки. Его синтаксис:
Логические операторы. выполняют над выражениями побитовые операции. Выражения должны быть абсолютными, то есть такими, численное значение которых может быть вычислено транслятором
Операторы сдвига. Выполняют сдвиг выражения на указанное количество разрядов
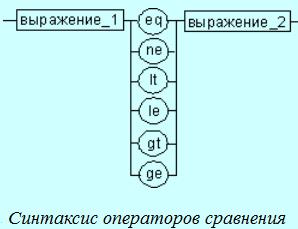
Операторы сравнения. Возвращают значение True (истина) или False (ложь) предназначены для формирования логических выражений. Логическое значение “истина” соответствует цифровой единице, а “ложь” — нулю.
Операторы опций.
Специальные операторы.
Операторы выборки.
Операторы адресности.
Операторы для структур.
Оператор получения сегментной составляющей адреса выражения. возвращает физический адрес сегмента для выражения, в качестве которого могут выступать метка, переменная, имя сегмента, имя группы или некоторое символическое имя
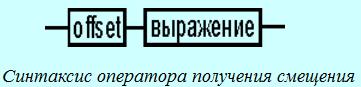
Оператор получения смещения выражения. позволяет получить значение смещения выражения (рис. 13) в байтах относительно начала того сегмента, в котором выражение определено.
Оператор переопределения типа. Оператор переопределения типа ptr применяется для переопределения или уточнения типа метки или переменной, определяемых выражением. Тип может принимать одно из следующих значений: byte, word, dword, qword, tbyte, near, far. Позволяет вызвать не весь операнд, а только его часть.
Оператор переопределения сегмента. Оператор переопределения сегмента: (двоеточие) заставляет вычислять физический адрес относительно конкретно задаваемой сегментной составляющей: “имя сегментного регистра”, “имя сегмента” из соответствующей директивы SEGMENT или “имя группы”.
Приоритеты операторов. Как и в языках высокого уровня, выполнение операторов ассемблера при вычислении выражений осуществляется в соответствии с их приоритетами (см. таблицу). Операции с одинаковыми приоритетами выполняются последовательно слева направо. Изменение порядка выполнения возможно путем расстановки круглых скобок, которые имеют наивысший приоритет.
Команды. В языке ассемблера командой называется оператор программы, который непосредственно выполняется процессором после того, как программа будет скомпилирована в машинный код, загружена в память и запущена на выполнение (т.е. на этапе выполнения программы). Любая команда состоит из четырех основных частей: · необязательной метки; · мнемоники команды, которая присутствует всегда; · одного или нескольких операндов (как правило, они присутствуют в любой команде, хотя есть ряд команд, для которых операнды не требуются); · необязательного комментария. Любая строка исходного кода программы может также содержать только метку или только комментарий. Стандартный формат команды ассемблера
Метка. Метка является обычным идентификатором, с помошью которого в программе помечается некоторый участок кода или данных. В процессе обработки исходного текста программы ассемблер назначает каждому оператору программы числовой адрес. Таким образом, метке, размешенной непосредственно перед командой, также назначается адрес этой команды. Аналогично, если разместить метку перед переменной, ей будет назначен адрес этой переменной. Для чего вообще нужны метки? Ведь в программах на языке ассемблера можно непосредственно использовать числовые адреса. Например, приведенная ниже команда загружает 16-разрядное число, расположенное по адресу0020, в регистр ax. mov ах,[0020] Очевидно, что при вставке в программу новой переменной, адреса всех последующих за ней переменных автоматически изменятся. Поэтому программист в каждом подобном случае должен вручную скорректировать в программе ссылки наподобие [0020]. Разумеется, что подобный стиль программирования создает массу неудобств и эффективность его крайне низкая. Следовательно, если присвоить переменной, расположенной по адресу 0020h, метку, то ассемблер будет автоматически подставлять ее значение при компиляции. Теперь приведенную выше команду можно переписать так: myVariable BYTE 4; myVariable = 4 mov ax,myVariable; myVariable загружена в регистр ax Метки кода. Метки, расположенные в коде программы (т.е. в сегменте кода, где размешаются команды процессора), должны заканчиваться символом вертикального двоеточия (:). Подобные метки обычно используются для указания участка программы, которому будет передано управление в командах перехода или организации циклов. Например, приведенная ниже команда безусловного перехода JMP (от англ. "jump") передает управление команде, помеченной кaк target, в результате чего в программе создается цикл: target: mov ax,bx … jmp target Метка в коде программы может находиться на одной строке с командой, либо занимать самостоятельную строку: target: mov ax,bx либо так: target: mov ax,bx Метки данных. При использовании метки в сегменте данных программы (т.е. там, где размещаются и определяются переменные), она не должна заканчиваться символом вертикального двоеточия. Ниже приведен пример определения переменной под именем first: first BYTE 10 При выборе имен меток следует учитывать общие правила для имен идентификаторов. Кроме того, имя, выбранное для метки, должно быть уникальным в пределах одного исходного файла программы. Например, если в файле с исходным кодом вашей программы уже есть метка с именем first, вы не можете присвоить это же имя другой метке, расположенной в том же файле. Типы данных При программировании на языке ассемблера используются данные следующих типов. Непосредственные данные, представляющие собой числовые или символьные значения, являющиеся частью команды. Данные простого типа. Они описываются с помощью ограниченного набора директив резервирования памяти, позволяющих выполнить самые элементарные операции по размещению и инициализации числовой и символьной информации. При обработке этих директив ассемблер сохраняет в своей таблице символов информацию о местоположении данных (значения сегментной составляющей адреса и смещения) и типе данных, то есть единицах памяти, выделяемых для размещения данных в соответствии с директивой резервирования и инициализации данных. Данные сложного типа, которые были введены в язык ассемблера с целью облегчения разработки программ. Сложные типы данных строятся на основе базовых типов, которые являются как бы кирпичиками для их построения. Введение сложных типов данных позволяет несколько сгладить различия между языками высокого уровня и ассемблером. У программиста появляется возможность сочетания преимуществ языка ассемблера и языков высокого уровня (в направлении абстракции данных), что в конечном итоге повышает эффективность конечной программы. Простые типы данных. Понятие простого типа данных носит двойственный характер. С точки зрения размерности (физическая интерпретация), микропроцессор аппаратно поддерживает следующие основные типы данных: · Байт. · Слово. · Двойное слово. · Учетверное слово.
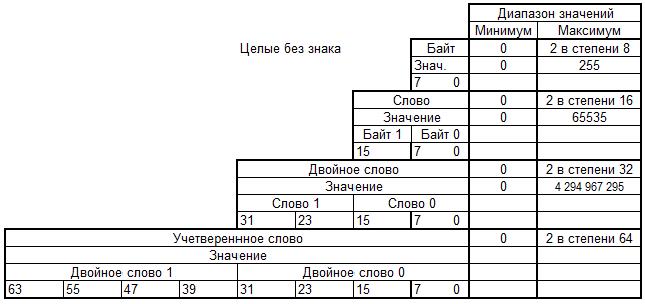
Байт — 8 последовательно расположенных битов, пронумерованных от 0 до 7, при этом бит 0 является самым младшим значащим битом; Слово — последовательность из 2 байт, имеющих последовательные адреса. Размер слова — 16 бит; биты в слове нумеруются от 0 до 15. Байт, содержащий нулевой бит, называется младшим байтом, а байт, содержащий 15-й бит - старшим байтом. Микропроцессоры Intel имеют важную особенность — младший байт всегда хранится по меньшему адресу. Адресом слова считается адрес его младшего байта. Адрес старшего байта может быть использован для доступа к старшей половине слова. Двойное слово — последовательность из 4 байт (32 бита), расположенных по последовательным адресам. Нумерация этих бит производится от 0 до 31. Слово, содержащее нулевой бит, называется младшим словом, а слово, содержащее 31-й бит, - старшим словом. Младшее слово хранится по меньшему адресу. Адресом двойного слова считается адрес его младшего слова. Адрес старшего слова может быть использован для доступа к старшей половине двойного слова. Учетверенное слово — последовательность из 8 байт (64 бита), расположенных по последовательным адресам. Нумерация бит производится от 0 до 63. Двойное слово, содержащее нулевой бит, называется младшим двойным словом, а двойное слово, содержащее 63-й бит, — старшим двойным словом. Младшее двойное слово хранится по меньшему адресу. Адресом учетверенного слова считается адрес его младшего двойного слова. Адрес старшего двойного слова может быть использован для доступа к старшей половине учетверенного слова. Кроме трактовки типов данных с точки зрения их разрядности, микропроцессор на уровне команд поддерживает логическую интерпретацию этих типов. Двоичные числа. Целый тип без знака — двоичное значение без знака, размером 8, 16, 32 и 64 бита.
Целый тип со знаком — двоичное значениесо знаком в старшем бите, размеры 8, 16, 32 и 64 бита. Ноль в знаковом бите в операндах соответствует положительному числу, а единица — отрицательному. Отрицательные числа представляются в дополнительном коде.
BCD – двоично-десятичное представление. Оно использует двочное представление десятичных цифр 0 – 9. Одна десятичная цифра в двоичном коде требует 4 бита (полбайта). Различают подтипы: · Неупакованный. Неупакованные десятичные числа хранятся как байтовые значения без знака по одной цифре в каждом байте. Значение цифры определяется младшим полубайтом. Старший полубайт содержит 0000. · Упакованный. Каждая цифра хранится в своем полубайте. Цифра в старшем полубайте (биты 4–7) является старшей
Указатели на память. Различаются у казатели на память двух типов: · ближнего типа (NEAR)— 32-разрядный логический адрес, представляющий собой относительное смещение в байтах от начала сегмента. Эти указатели могут также использоваться в сплошной (плоской) модели памяти, где сегментные составляющие одинаковы; · дальнего типа (FAR) — 48-разрядный логический адрес, состоящий из двух частей: 16-разрядной сегментной части — селектора, и 32-разрядного смещения.
Цепочка. Цепочка представляет собой некоторый непрерывный набор байтов, слов или двойных слов максимальной длины до 4 Гбайт. Цепочка может содержать набор байтов, слов и двойных слов.
Битовое поле. Представляет собой непрерывную последовательность бит, в которой каждый бит является независимым и может рассматриваться как отдельная переменная. Битовое поле может начинаться с любого бита любого байта и содержать до 32 бит.
Непосредственные данные и данные простого типа являются элементарными, или базовыми; работа с ними поддерживается на уровне системы команд микропроцессора. Используя данные этих типов, можно формализовать и запрограммировать практически любую задачу. Но насколько это будет удобно — вот вопрос. Обработка информации, в общем случае, процесс очень сложный. Это косвенно подтверждает популярность языков высокого уровня. Одно из несомненных достоинств языков высокого уровня — поддержка развитых структур данных. При их использовании программист освобождается от решения конкретных проблем, связанных с представлением числовых или символьных данных, и получает возможность оперировать информацией, структура которой в большей степени отражает особенности предметной области решаемой задачи. В то же самое время, чем выше уровень такой абстракции данных от конкретного их представления в компьютере, тем большая нагрузка ложится на компилятор с целью создания действительно эффективного кода. Ведь нам уже известно, что в конечном итоге все написанное на языке высокого уровня в компьютере будет представлено на уровне машинных команд, работающих только с базовыми типами данных. Таким образом, самая эффективная программа — программа, написанная в машинных кодах, но писать сегодня большую программу в машинных кодах — занятие не имеющее слишком большого смысла. Директивы резервирования и инициализации данных TASM и MASM. В TASM и MASM определены несколько директив резервирования и инициализации данных. Машинного эквивалента этим директивам нет. Очень важно уяснить себе порядок размещения данных в памяти. Он напрямую связан с логикой работы микропроцессора с данными. Микропроцессоры Intel требуют следования данных в памяти по принципу: младший байт по младшему адресу. Директивы резервирования и инициализации данных простых типов имеют формат.
На рисунке использованы следующие обозначения: ·? показывает, что содержимое поля не определено, то есть при задании директивы с таким значением выражения содержимое выделенного участка физической памяти изменяться не будет. Фактически, создается неинициализированная переменная; · Значение инициализации — значение элемента данных, которое будет занесено в память после загрузки программы. Фактически, создается инициализированная переменная, в качестве которой могут выступать константы, строки символов, константные и адресные выражения в зависимости от типа данных. Подробная информация приведена в приложении 1;
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2017-02-07; просмотров: 502; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.134.90.44 (0.105 с.) |