Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Направления развития ВТ. Понятие ИТ. Этапы развития ИТ. Свойства ИС. Данные и эвм, системы обработки файлов.Стр 1 из 22Следующая ⇒
Направления развития ВТ. Понятие ИТ. Этапы развития ИТ. Свойства ИС. Данные и ЭВМ, системы обработки файлов.
Основные направления развития ВТ
Несложные вычисления позволяют установить тот факт, что неограниченный рост тактовых частот работы микропроцессоров невозможен, он неумолимо приближается к своему максимуму. Уже несколько лет компания Intel ведет работы над процессором с тактовой частотой 20 ГГц, произведенным по технологии 0,065мкм. Логическим продолжением наращивания вычислительных мощностей является технология распараллеливания вычислений между несколькими процессорами, или несколькими компьютерами. Кроме того, бурный рост сетевых технологий и глобальных компьютерных, сетей с колоссальной скоростью увеличивающих армию пользователей, позволит создать единое информационно-коммуникационное пространство для общения и обмена различного рода информацией. Использование технологий Web 2.0 и Web 3.0 позволит превратить всемирную паутину из «глобальной мусорки» в источник знаний. Разработка принципиально новых программных продуктов, использующих методы искусственного интеллекта, такие как семантические и нейронные сети, онтологии позволит совершить прорыв в ранее не доступные для человека сферы науки и техники.
Понятие ИТ ИТ – это совокупность методов, производственных процессов и программно-технических средств, объединенных в технологическую цепочку, обеспечивающие обработку, сбор, хранении, распространение и отображение информации с целью снижения трудоемкости процессов использования инф. ресурса, а также повышения их надежности и оперативности.
Этапы развития ИТ
Признак деления – проблемы, стоящие на пути информатизации общества 1-й этап (до конца 60-х гг.) характеризуется проблемой обработки больших объемов данных в условиях ограниченных возможностей аппаратных средств. 2-й этап (до конца 70-х гг.) связывается с распространением ЭВМ серии IBM / 360. Проблема этого этапа – отставание программного обеспечения от уровня развития аппаратных средств. 3-й этап (с начала 80-х гг.) – компьютер становится инструментом непрофессионального пользователя, а информационные системы – средством поддержки принятия его решений. Проблемы – максимальное удовлетворение потребностей пользователя и создание соответствующего интерфейса работы в компьютерной среде.
4-й этап (с начала 90-х гг.) – создание современной технологии межорганизационных связей и информационных систем. Проблемы этого этапа весьма многочисленны. Наиболее существенными из них являются:
Свойства ИС
Информационные системы (ИС) могут очень сильно различаться по своим функциям, архитектуре, реализации в зависимости от конкретной области применения. Однако можно выделить по крайней мере два свойства, которые являются общими для всех информационных систем.
Во-первых, любая информационная система предназначена для сбора, хранения и обработки информации. Поэтому в основе любой информационной системы лежит среда переработки, хранения и доступа к данным. Среда должна обеспечивать уровень надежности хранения и эффективность доступа, соответствующие области применения информационной системы. Заметим, что в обычных вычислительных программных системах наличие такой среды не является обязательным. Во-вторых, информационные системы ИС должна обладать простым, удобным, легко осваиваемым интерфейсом, который должен предоставить пользователю все необходимые функции и в то же время не позволить ему выполнять лишние действия.
Данные и ЭВМ Восприятие реального мира можно соотнести с последовательностью разных, хотя иногда и взаимосвязанных, явлений. С давних времен люди пытались описать эти явления (даже тогда, когда не могли их понять). Такое описание называют данными. Традиционно фиксация данных осуществляется с помощью конкретного средства общения (например, с помощью естественного языка или изображений) на конкретном носителе (например, камне или бумаге). Обычно данные (факты, явления, события, идеи или предметы) и их интерпретация (семантика) фиксируются совместно, так как естественный язык достаточно гибок для представления того и другого. Примером может служить утверждение "Стоимость авиабилета 128". Здесь "128" – данное, а "Стоимость авиабилета" – его семантика.
Применение ЭВМ для ведения* и обработки данных обычно приводит к еще большему разделению данных и интерпретации. ЭВМ имеет дело главным образом с данными как таковыми. Большая часть интерпретирующей информации вообще не фиксируется в явной форме. Почему же это произошло? Существует по крайней мере две исторические причины, по которым применение ЭВМ привело к отделению данных от интерпретации. Во-первых, ЭВМ не обладали достаточными возможностями для обработки текстов на естественном языке – основном языке интерпретации данных. Во-вторых, стоимость памяти ЭВМ была первоначально весьма велика. Память использовалась для хранения самих данных, а интерпретация традиционно возлагалась на пользователя. Пользователь закладывал интерпретацию данных в свою программу, которая "знала", например, что шестое вводимое значение связано с временем прибытия самолета, а четвертое – с временем его вылета. Это существенно повышало роль программы, так как вне интерпретации данные представляют собой не более чем совокупность битов на запоминающем устройстве. Жесткая зависимость между данными и использующими их программами создает серьезные проблемы в ведении данных и делает использования их менее гибкими. Системы обработки файлов Лучший способ уяснить общую природу и свойства современных баз данных – рассмотреть характеристики систем, существовавших до появления технологии баз данных. При эксплуатации такого рода систем возникал ряд проблем, которые технология баз данных помогла решить. В первых деловых информационных системах группы записей хранились в отдельных файлах; такие системы назывались системами обработки файлов (пример: одна система обрабатывает данные клиента, другая система – информацию о заказах). Хотя системы обработки файлов являются огромным усовершенствованием по сравнению с ведением записей вручную, у них есть значительные ограничения: · данные разделены и изолированы (нужно выбрать опр. инф. из системы данных клиента, определить инф. из системы заказов – сформировать из них третий файл); · значительная часть данных дублируется (данные о клиенте в системы данных клиентов записываются один раз, в систему заказов – каждый раз при заказе; при измени данных клиента требуется обновить данные в системе заказов); · прикладные программы зависят от форматов файлов (если в записи о клиенте в поле почт. индекса изменить с 5 на 6 символов, то все программы, работающие с этой записью необходимо будет изменить, даже если они не работают с этим полем); · зачастую файлы несовместимы друг с другом (чтобы скомбинировать файлы, написанные на разных языках, требуется преобразовать формат файлов к некоторому общему формату); · данные представлены в неудобном для пользователя виде (связи между записями не представлены в явной форме).
Определения и классификация баз данных и СУБД. Типовая организация современных СУБД.
Словарь данных Фундаментальное различие между БД и файловыми системами заключается в способе доступа к данным.
Программы, использующие БД, обращаются к данным через механизмы самой БД (без непосредственной зависимости от фактического источника данных). Такая независимость данных возможна благодаря словарю данных. Словарь данных представляет собой системные таблицы и объекты, которые хранятся в БД и содержат метаинформацию (информацию об информации) для всех объект БД. Доступ к этим объектам ведется ядром СУБД. Метаинформация включает: описание БД, информация о предметной области, информация о пользователях системах и др. Информация в словаре данных предназначена для подтверждения существования объектов, обеспечения доступа к ним, описание фактического физического расположения в памяти. Классификация БД: По области применения: · Деловые БД · Научные · Военные… По форме представления информации:
Понятие изображения включает в себя:
По типу хранимой информации: · Документальные БД (библиографические, реферативные, полнотекстовые) · Фактографические · Лексикографические (различные словари (классификаторы, многоязычные словари, словари основ слов и т.д.)) По характеру организации хранения данных и обращения к ним:
По охватываемому уровню организации: · БД уровня предприятия (информация охватывает деятельность предприятия в целом) · БД уровня подразделения (информация не выходит за рамки деятельности подразделения) · БД уровня рабочей группы (для небольших коллективов) По степени структурированности: · Неструктурированные (семантические сети) · Частично структурированные (обычный текст или гипертекстовый документ) · Структурированные (организованные в соответствии с одной из моделей данных) · По типу модели данных: · Иерархические (навигационные) (низкий уровень зависит от высшего, EX: Организация –Подразделение -Отдел) · Сетевые (навигационные) · Реляционные (информация в форме таблиц, в отличие от сетевых связи могут не описываться. Ограничение рел.моделей в таких системах, как система принятия решений – к таким темам лучше подходит ОбОрМод) · Объектно-ориентированные модель Мультимодельные (БД, в которых поддерживается много моделей, например Oracle, в которых можно задавать таблички, связи, формулы и будет поддерживаться несколько связей)
СУБД (Система Управления Базами Данных) – это программное обеспечение, с помощью которого пользователи могут определять, создавать и поддерживать БД, а также осуществлять к ней контролируемый доступ. Классификация СУБД По языкам общения: Ø Открытые системы — системы, в которых для обращения к базам данных используются универсальные языки программирования. Ø Замкнутые системы — имеют собственные языки общения с пользователями. Ø Смешанные системы — поддерживают как универсальные, так и собственные языки программирования.
По числу уровней в архитектуре: Ø Одноуровневые Ø Двухуровневые Ø Трехуровневые Под архитектурным уровнем СУБД понимают функциональный компонент, механизмы которого служат для поддержки некоторого уровня абстракции данных: Ø Физический уровень — описывает структуры, используемые для хранения различной информации. Ø Логический уровень — описывает объекты, создаваемые в базе данных, а также различные свойства, которые влияют на работу приложения с базой данных. Ø Внешний уровень — описывает структуру представления хранящейся в базе данных информацию для конечного пользователя.
По выполняемым функциям: Ø Информационные— позволяют организовать хранение Ø Операционные — выполняют достаточно сложную обработку, например, автоматически позволяют получать показатели, не хранящиеся непосредственно в базе данных, могут изменять алгоритмы обработки и т.д.
По сфере возможного применения: Ø Универсальные Ø Специализированные
По используемым наборам типов данных: Ø Нерасширяемые— используют базовый набор типов данных. Ø Расширяемые— позволяют разработчику добавлять новые типы данных и новые операции над этими данными. Структура модели Дерево состоит из узлов, которые представляют интересующие нас объекты. Связи между узлами называются дугами или ребрами. Связи определяют зависимости между объектами предметной области. Самый верхний узел называется корневым узлом. Корневой узел может иметь нуль или несколько дочерних узлов которые, в свою очередь, также могут иметь нуль или несколько дочерних узлов. Все узлы дерева, за исключением корня, должны иметь родительский узел. Любая часть дерева, исходящая из одного узла (помимо корня дерева), называется поддеревом. С практической точки зрения, каждый узел может быть представлен либо в виде некоторого типа записи (сущности), где каждая связь представляется встроенным указателем (или адресом), либо с помощью некоторого физического упорядочения записей.
В структуре дерева типы записей и их экземпляры обычно физически располагаются рядом друг с другом, причем, как правило, слева направо.
Методы доступа к типам записей внутри дерева: • Прямой (нисходящий) порядок обхода дерева Начинается с доступа к корню с последующей обработкой всего дерева с просмотром поддеревьев в порядке слева направо. • Обратный (восходящий) порядок обхода дерева Начинается с доступа к самым нижним узлам с постепенным восходящим переходом от одного поддерева к другому слева направо и с завершением обработки в корне.
Представление связей типа M:N Объект недвижимости рекламируется в нескольких газетах, а в одной газете рекламируется сразу несколько объектов недвижимости. Решение проблемы Сохранение данных в двух местах: Запись с описанием объекта недвижимости дублируется для каждой газеты, в которой рекламируется данный объект и наоборот.
Особенности иерархических систем Модель реализуется с помощью древовидной структуры. • Записи, связаны с помощью указателей или путем их физически смежного расположения. • Доступ к данным осуществляется путем "перемещения" (навигации) от корня дерева к дочерним узлам (прямой обход) или наоборот (обратный обход). • Дочерние экземпляры не могут существовать без наличия родительских экземпляров. • Автоматическая поддержка ссылочной целостности между записями, когда зависимые данные полностью участвует в связи со своим родителем. • Невозможность хранения экземпляров записей, которые не имеют никаких родительских записей.
Недостатки иерархических систем • При моделировании связей типа "многие ко многим" (M:N) или других, более сложных неиерархических связей данные дублируются (избыточность данных) и повышается уровень накладных расходов на их сопровождение. • Отсутствие гибкости при изменении требований к данным и методам доступа. • Проектирование могут выполнить только опытные специалисты-эксперты. • Отсутствие единого стандарта для модели.
Сетевые модели данных.
Ядром любой базы данных является модель данных, которая определяет взаимосвязь данных на логическом уровне. С помощью модели данных могут быть представлены объекты предметной области, взаимосвязи между ними. Модель данных — совокупность структур данных и операций их обработки Сетевая модель данных состоит из набора типов записей и связей между этими типами записей. Все связи указываются явно и хранятся в виде части БД. Второе название модели — CODASYL присвоено в честь Конференции по языкам информационных систем (Conference on Data Systems Languages), установившей стандарт для модели. В качестве основы определения модели можно использовать существующую теорию графов. Термин "сетевая" подчеркивает тот факт, что компоненты этой модели данных могут иметь установленные между ними связи.
Сетевые модели данных являются расширенной версией иерархической модели, однако основным отличием является то, что в сетевых моделях данных имеются указатели в обоих направлениях, которые соединяют родственную информацию.
Инфологическое моделирование. Требования, предъявляемые к инфологической модели. Компоненты инфологической модели. Построение модели «объект-свойство-отношение».
В базе данных отображается некоторая часть реального мира. Естественно, что полнота ее описания будет зависеть от целей создаваемой информационной системы. Часть реального мира, представляющая интерес для данного исследования, называется предметной областью (ПО). Для того чтобы база данных адекватно отражала предметную область, проектировщик должен хорошо представлять себе все нюансы, присущие ей, и уметь отобразить их в базе данных. Предметная область должна быть предварительно описана. Для этого, в принципе, может использоваться и естественный язык, но его применение имеет много недостатков, основные из которых - громоздкость описания и неоднозначность его трактовки. Поэтому обычно для этих целей используют искусственные формализованные (чаще всего - графические) языковые средства. Формализованное описание предметной области называется концептуальной (КМ), или инфологической (ИЛМ), моделью. Предметные области могут быть различными, и для их моделирования могут потребоваться специфические средства, соответствующие особенностям этих областей.
Основными компонентами инфологической модели ПО являются: · описание объектов ПО и связей между ними; · описание информационных потребностей пользователей · описание алгоритмических зависимостей показателей; · описание ограничений целостности; · описание функциональной структуры системы, для которой создается АИС; · требования к ИС и существующие ограничения.
К концептуальной модели предъявляются следующие требования: · адекватное отображение предметной области (язык для представления ИЛМ должен обладать достаточными выразительными возможностями для отображения явлений, имеющих место в предметной области); · непротиворечивость (не должна допускаться неоднозначная трактовка модели); · легкая расширяемость границ ИЛМ (ИЛМ должна обеспечивать ввод новых данных без изменения ранее определенных); · возможность композиции и декомпозиции модели; · применимость языка спецификации ИЛМ как при ручном, так и при автоматизированном проектировании информационных систем.
Автоматизированное проектирование предъявляет дополнительные требования к языку: · вычисляемость (язык должен восприниматься и обрабатываться ЭВМ); · использование “дружелюбных” пользователю интерфейсов, в частности, графических; · независимость от оборудования и других ресурсов, которые подвержены частым изменениям; · использование средства тестирования ИЛМ, а также аппарата для указания того, что спецификация завершена и по ней может быть выполнена генерация структур баз данных; · легкое восприятие модели разными категориями пользователей.
Построение модели “объект-свойство-отношение”
В предметной области в процессе ее обследования и анализа выделяют классы объектов. Классом объектов называют совокупность объектов, обладающих одинаковым набором свойств. Например, если в качестве предметной области рассмотреть вуз, то в ней можно выделить следующие классы объектов: учащиеся, преподаватели, аудитории и т. д. Объекты могут быть реальными, как названные выше, а могут быть и абстрактными, как, например, предметы, которые изучают студенты.
При отражении в информационной системе каждый объект представляется своим идентификатором, который отличает один объект класса от другого, а каждый класс объектов представляется именем этого класса. Идентификатор должен быть уникальным.
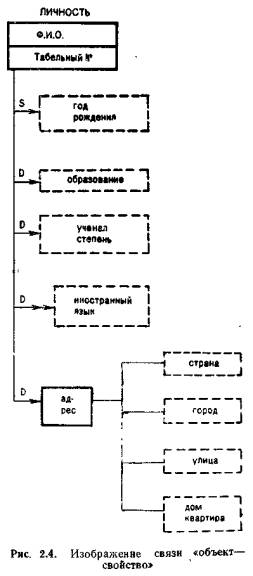
Каждый объект обладает определенным набором свойств. Для объектов одного класса набор этих свойств одинаков, а их значения, естественно, могут различаться. Например, для объектов класса «СТУДЕНТ» таким набором свойств, описывающим объекты класса, может быть «ГОД РОЖДЕНИЯ», «ПОЛ» и др. При описании предметной области надо изобразить каждый из существующих классов объектов и набор свойств, фиксируемый для объектов данного класса.
Каждому классу объектов в инфологической модели присваивается уникальное имя. Помимо имени класса объектов в ИЛМ может использоваться его короткое кодовое обозначение. При построении инфологической модели желательно дать словесную интерпретацию каждой сущности, особенно если возможно неоднозначное толкование понятия.
При описании предметной области надо отразить связи между объектом и характеризующими его свойствами. Это изображается просто в виде линии, соединяющей обозначение объекта и его свойств. Связь между объектом и его свойством может быть различной. Объект может обладать только одним значением какого-то свойства. Например, каждый человек может иметь только одну дату рождения. Такие свойства называются единичными (одинарная стрелка). Для других свойств возможно существование одновременно нескольких значений у одного объекта. Например, сотрудник знает несколько иностранных языков, такое свойство называется множественным (двойная стрелка). Кроме того, некоторые свойства являются постоянными, их значение не может измениться с течением времени – статические (S над соответствующей линией) свойства. А те свойства, значение которых может изменяться со временем, динамические (D).
Другой характеристикой связи между объектом и его свойством является признак того, присутствует ли это свойство у всех объектов данного класса либо отсутствует у некоторых объектов. Например, для отдельных служащих может иметь место свойство «УЧЕНАЯ СТЕПЕНЬ», а другие объекты этого класса могут не обладать, указанным свойством. Такие свойства называют условными (пунктирная линия). Иногда в инфологической модели бывает полезно ввести понятие «составное свойство». Примерами таких свойств могут быть «АДРЕС», состоящий из «ГОРОДА», «УЛИЦЫ», «ДОМА» и «КВАРТИРЫ»/ Для обозначения составного свойства используют квадрат, из которого исходят линии, соединяющие его с обозначениями составляющих его элементов.
Кроме связи между объектом и его свойствами, в инфологической модели фиксируются связи между объектами разных классов. Различают связи типа «один к одному» (1:1), «один ко многим» (1:М), «многие к одному» (М:1) и «многие ко многим» (М: М). Иногда эти типы связей называются степенью связи. Кроме степени связи в инфологической модели для характеристики связи между разными сущностями надо указывать так называемый «класс принадлежности», который показывает, может ли отсутствовать связь объекта данного класса с каким-либо объектом другого класса. Класс принадлежности сущности должен быть либо обязательным, либо необязательным (факультативный).
Также между объектами могут быть установлены рекурсивные связи — один и тот же объект является и родительским и дочерним одновременно: • иерархическая рекурсия (hierarchical recursion) — задает связь, когда экземпляр родительского объекта может иметь множество экземпляров дочернего объекта, но экземпляр дочернего объекта имеет только один экземпляр родительского объекта (начальник-подчиненный); • сетевая рекурсия (network recursion) — руководитель может иметь множество подчиненных и, наоборот, подчиненный может иметь множество руководителей (родственные отношения).
Связи между объектами Между типами объектов могут существовать зависимости (типы связей), которые «материализуются» в виде связей между экземплярами объектов соответствующих типов (экземпляров связей данного типа). Каждая связь может именоваться глаголом или глагольной фразой, характеризующей отношение между двумя сущностями. Виды связей между объектами Ø По степени связи: «один к одному» (1:1), «один ко многим» (1:m), «многие ко многим» (m:m)(три типа бинарных связей) Ø По типу мощности (обозначение отношения числа экземпляров родительского объекта к числу экземпляров дочернего для первых двух степеней связи): • общий случай — одному экземпляру родительского объекта соответствуют 0, 1 или много экземпляров дочернего объекта (не помечается); • одному экземпляру родительского объекта соответствуют 1 или много экземпляров дочернего объекта (символ P); • одному экземпляру родительского объекта соответствуют 0 или 1 экземпляр дочернего объекта (символ Z); • точное соответствие — одному экземпляру родительского объекта соответствует заранее заданное число экземпляров дочернего объекта (помечается цифрой). По классу принадлежности (показывает, может ли отсутствовать связь объекта данного типа с каким-либо объектом другого типа): • обязательный класс принадлежности; • факультативный (необязательный). Рекурсивные связи — один и тот же объект является и родительским и дочерним одновременно: • иерархическая рекурсия (hierarchical recursion) — задает связь, когда экземпляр родительского объекта может иметь множество экземпляров дочернего объекта, но экземпляр дочернего объекта имеет только один экземпляр родительского объекта (начальник-подчиненный); • сетевая рекурсия (network recursion) — руководитель может иметь множество подчиненных и, наоборот, подчиненный может иметь множество руководителей (родственные отношения).
10. Даталогическое проектирование: исходные данные, результат проектирования даталогической модели, определение состава базы данных. Особенности даталогической модели. Этапы процесса получения реляционной схемы из ER-схемы. Исходные данные: На выбор проектных решений на этапе даталогического проектирования оказывают влияние следующие факторы:
Реляционные базы данных. Базовые понятия реляционного подхода к организации баз данных, домен, тип данных, атрибут, схема отношения, схема БД, кортеж, ключ, степень отношения и кардинальное число. Фундаментальные свойства отношений. Реляционная модель БД. Основные понятия. Реляционная база данных является организованной на машинном носителе совокупностью взаимосвязанных данных и содержит сведения о различных сущностях одной предметной области — реальных объектах, процессах, событиях или явлениях. Реляционная база данных представляет собой множество взаимосвязанных двумерных таблиц, в каждой из которых содержатся сведения об одной сущности. Структура реляционной таблицы определяется составом и последовательностью полей, соответствующих ее столбцам, с указанием типа элементарного данного, размещаемого в поле. Каждое поле отражает определенную характеристику сущности, а соответствующий столбец содержит данные одного типа. Содержание реляционной таблицы заключено в ее строках. Каждая строка таблицы содержит данные о конкретном экземпляре сущности и называется записью. для однозначного определения каждой записи таблица должна иметь уникальный ключ (первичный ключ). Этот ключ может состоять из одного или нескольких полей. По значению ключа отыскивается единственная запись. Связи между таблицами базы данных дают возможность совместно использовать данные из разных таблиц. В нормализованной реляционной базе данных связи характеризуются отношениями типа один-к-одному (1:1) или один-ко-многим (1:М). Связь каждой пары таблиц обеспечивается одинаковыми полями в них - ключом связи. Ключом связи всегда является уникальный ключ главной таблицы в связи. В подчиненной таблице он называется внешним ключом.
Понятие типа данных в реляционной модели данных полностью адекватно понятию типа данных в языках программирования. Обычно в современных реляционных БД допускается хранение символьных, числовых данных, битовых строк, специализированных числовых данных (таких как "деньги"), а также специальных "темпоральных" данных (дата, время, временной интервал).
Наименьшая единица данных реляционной модели – это отдельное атомарное (неразложимое) для данной модели значение данных. Доменом называется множество атомарных значений одного и того же типа. Наиболее правильной интуитивной трактовкой понятия домена является понимание домена как допустимого множества значений данного типа. Атрибут (колонка, столбец, поле) — представляет собой элемент данных. Схема отношения (заголовок отношения) — это именованное множество пар {имя атрибута, имя домена}. Схема БД — это набор именованных схем отношений. Кортеж (строка, запись), соответствующий данной схеме отношения, — это множество пар {имя атрибута, значение}, которое содержит одно вхождение каждого имени атрибута, принадлежащего схеме отношения. "Значение" является допустимым значением домена данного атрибута. Отношение (таблица, отношение-экземпляр, тело отношения) — множество кортежей. Имя схемы отношения всегда совпадает с именем соответствующего отношения-экземпляра. Ключ — это множество атрибутов отношения (полей таблицы), удовлетворяющих двум независимым от времени условиям: 1. Уникальность: никакие два различных кортежа (записи) не имеют одного и того же значения для всех атрибутов (полей), входящих в ключ. 2. Минимальность: ни один из атрибутов, входящих в ключ, не может быть исключен из него без нарушения уникальности. Степень отношения – это число его атрибутов. Отношение степени один называют унарным, степени два – бинарным, степени три – тернарным, а степени n – n-арным. Кардинальное число или мощность отношения – это число его кортежей. Кардинальное число отношения изменяется во времени в отличие от его степени. Связь — ассоциирование двух или более сущностей. Синтез отношений Два атрибута A и B могут иметь связь трех видов: A->B и B->A «один к одному» A->B, а B не ->A «многие к одному» A не ->B и B не ->A «многие ко многим»
Связь «один к одному»
Связь «многие к одному»
Связь «многие ко многим»
Суррогатные ключи Суррогатный ключ (surrogate key) — это уникальный идентификатор, используемый в качестве первичного ключа отношения. Значения суррогатного ключа не имеют смысла для пользователей, поэтому в формах и отчетах они обычно скрываются. Причины для использования суррогатных ключей
Причины использования Неизменность. Главное достоинство суррогатного ключа состоит в том, что он практически никогда не меняется, поскольку не несёт никакой информации из предметной области и, следовательно, в минимальной степени зависит от изменений, происходящих в ней. Для изменения суррогатного ключа обычно требуются экстраординарные обстоятельства (см. ниже причину «гибкость»). Атрибуты естественного ключа время от времени могут меняться — например, человек может изменить имя или фамилию, получить новый паспорт взамен потерянного. В этом случае возникает необходимость так называемых «каскадных изменений» — при изменении значения естественного ключа для сохранения ссылочной целостности система должна внести соответствующие изменения во все значения внешних ключей, ссылающихся на изменяемый. В больших базах данных это может приводить к существенным накладным расходам. Гарантированная уникальность. Далеко не всегда можно гарантировать то, что уникальность естественного ключа не будет скомпрометирована с течением времени. Различные внешние факторы могут приводить к тому, что естественный ключ, ранее уникальный, в новых обстоятельствах может уникальность утратить. Суррогатный ключ свободен от этого недостатка. Гибкость. Поскольку суррогатный ключ неинформативен, его можно свободно заменять. Допустим, сливаются две фирмы со сходной структурой БД; сотрудник идентифицируется сетевым логином. Чтобы в полученной БД ключ оставался уникальным, приходится добавлять в него дополнительное поле — «из какой фирмы пришёл». В случае с суррогатными кл
|
|||||||||
|
|
Последнее изменение этой страницы: 2017-01-25; просмотров: 312; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.137.161.222 (0.141 с.) |