
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
История и причины создания СУБД. Отношения и их свойства, ключи отношений.Стр 1 из 8Следующая ⇒
БАЗЫ ДАННЫХ История и причины создания СУБД. Отношения и их свойства, ключи отношений. История и причины создания СУБД. Тогда для участия в проекте Apollo правительством США была привлечена компания Rockwell. Для того, чтобы построить космический корабль, как многие, наверное, догадываются, нужно собрать несколько миллионов деталей. И в те далекие времена была создана система управления файлами, которая отслеживала информацию о каждой детали. Но когда решили проверить эту систему, то обнаружили, что данные в ней повторяются по нескольку раз. Налицо была огромная избыточность. Следующий большой шаг в истории развития баз данных сделал доктор Эдгар Кодд (Edgar Codd) - научный сотрудник все той же самой небезызвестной IBM. В 1970 году он опубликовал свою работу "Реляционная модель для больших банков совместно используемых данных", которая в корне изменила теорию баз данных. Первыми СУБД с реализацией реляционного модуля стали System R от уже неоднократно известной IBM и Ingres от Калифорнийского университета. В истории развития баз данных можно выделить следующие этапы: 1) Файлы и файловые системы (70 годы ХХ века); 2) Базы данных на больших ЭВМ. Первые СУБД (80-е года XX века); 3) Эпоха персональных компьютеров. Настольные СУБД (90-е годы ХХ века); 4) Распределенные базы данных. Отношения и их свойства.
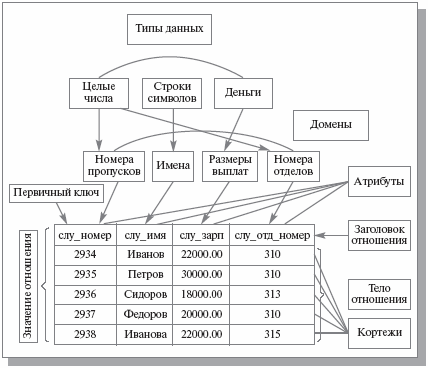
Понятие отношения является наиболее фундаментальным в реляционном подходе к организации баз данных, поскольку n-арное отношение является единственной родовой структурой данных, хранящихся в реляционной базе данных. Это отражено и в общем названии подхода – термин реляционный (relational) происходит от relation (отношение). Для уточнения термина отношение выделяются понятия: · заголовка отношения. Итак, заголовком (или схемой) отношения r (Hr) называется конечное множество упорядоченных пар вида <A, T>, где A называется именем атрибута, а T обозначает имя некоторого базового типа или ранее определенного домена.
· понятие кортежа. Кортежем tr, соответствующим заголовку Hr, называется множество упорядоченных триплетов вида<A, T, v>, по одному такому триплету для каждого атрибута в Hr. Третий элемент – v – триплета <A, T, v> должен являться допустимым значением типа данных или домена T. · Телом Br отношения r называется произвольное множество кортежей tr. · значения отношения. Значением Vr отношения r называется пара множеств Hr и Br. · переменной отношения. Переменной VARr называется именованный контейнер, который может содержать любое допустимое значение Vr. Свойства отношений: · Отсутствие кортежей-дубликатов · Отсутствие упорядоченности кортежей · Отсутствие упорядоченности атрибутов. Атрибуты отношений не упорядочены, поскольку по определению заголовок отношения есть множество пар <имя атрибута, имя домена>. · Атомарность значений атрибутов, первая нормальная форма отношения. Значения всех атрибутов являются атомарными (вернее, скалярными). Это следует из определения домена как потенциального множества значений скалярного типа данных, т. е. среди значений домена не могут содержаться значения с видимой структурой, в том числе множества значений (отношения). Ключи отношений: Понятие первичного ключа является исключительно важным в связи с понятием целостности баз данных. Заметим, что хотя формально существование первичного ключа значения отношения является следствием того, что тело отношения – это множество, на практике первичные (и возможные) ключи переменных отношений появляются в результате явных указаний проектировщика отношения. Дело в том, что в результате СУБД получает информацию, которая в дальнейшем будет использоваться как ограничения целостности. СУБД никогда не допустит появления в переменной отношения значения-отношения, содержащего два кортежа с одинаковым значением атрибута. Объединение
Результатом объединения отношений A и B будет отношение с тем же заголовком, что и у совместимых по типу отношений A и B, и телом, состоящим из кортежей, принадлежащих или A, или B, или обоим отношениям.
Пример Пусть даны следующие соотношения: Персоны
Персонажи
Результат объединения:
Эквивалентный SQL-запрос: SELECT Имя, Возраст, Вес FROM Персоны UNION SELECT Имя, Возраст, Вес FROM Персонажи Пересечение
Результатом пересечения отношений A и B будет отношение с тем же заголовком, что и у отношений A и B, и телом, состоящим из кортежей, принадлежащих одновременно обоим отношениям A и B. Пример Пусть даны следующие соотношения: Персоны
Персонажи
Результат пересечения:
Эквивалентный SQL-запрос: SELECT Имя, Возраст, Вес FROM ПерсоныINTERSECTSELECT Имя, Возраст, Вес FROM Персонажи
Разность
Результатом разности отношений A и B будет отношение с тем же заголовком, что и у совместимых по типу отношений A и B, и телом, состоящим из кортежей, принадлежащих отношению A и не принадлежащих отношению B. Пример Пусть даны следующие соотношения: Персоны
Персонажи
Результат разности:
Эквивалентный SQL-запрос: SELECT Имя, Возраст, Вес FROM ПерсоныEXCEPTSELECT Имя, Возраст, Вес FROM ПерсонажиВыборка Операция выборки — унарный оператор, записываемый как σaθb(R) или σaθv(R), где:
Выборка σaθb(R) (или σaθv(R)) выбирает все наборы значений R, для которых функция a θ b (или a θ v) будет истинна. Пример Пусть даны следующие соотношения: Персоны
Тогда результаты выборок будут следующими: σВозраст ≥ 34(Персоны)
Эквивалентный SQL-запрос: SELECT * FROM Персоны WHERE Возраст >= 34σВозраст = Вес(Персоны)
Эквивалентный SQL-запрос: SELECT * FROM Персоны WHERE Возраст = Вес Проекция является операцией, при которой из отношения выделяются атрибуты только из указанных доменов, то есть из таблицы выбираются только нужные столбцы, при этом, если получится несколько одинаковых кортежей, то в результирующем отношении остается только по одному экземпляру подобного кортежа.Соединение
Операция соединения есть результат последовательного применения операций декартового произведения и выборки. Если в отношениях и имеются атрибуты с одинаковыми наименованиями, то перед выполнением соединения такие атрибуты необходимо переименовать. Пример Мульфильмы
Каналы
Соединим их с выборкой σНазвание_канала = Код_канала(Произведение)
Второй этап, выборка σНазвание_канала = Код_канала(Произведение):
Эквивалентный SQL-запрос: SELECT * FROM Мультфильмы, Каналы WHERE Название_канала = Код_каналаИлиSELECT * FROM МультфильмыINNER JOIN Каналы ON Мультфильмы.Название_канала = Каналы.Код_каналаДеление Реляционное деление достаточно нетривиально описать, но на примере его смысл нагляден. В целом, из таблицы A берутся значения строк, для которых присутствуют все комбинации значений из таблицы B. Пример Пусть даны следующие соотношения: Мульфильмы
Тогда при делении на таблицу каналов: Каналы
Результатом будет:
Family Guy и The Simpsons — мультфильмы, которые показывались и на RenTV и на 2x2 (условие во второй таблице). При этом Duck Tales не показывалось по RenTV, потому был исключён из результирующей таблицы. Операция переименования Пусть s обозначает результат операции r <RENAME> (A, B). Для обеспечения возможности выполнения операции требуется, чтобы существовал некоторый тип T, такой, что <A, T>
Операция <RENAME> производит отношение s, которое отличается от заданного отношения r только именем одного его атрибута, которое изменяется с A на B. Заголовок s такой же, как заголовок r, за исключением того, что пара <B, T> заменяет пару <A, T>. Тело s включает все кортежи тела r, но в каждом из этих кортежей триплет <B, T, v> заменяет триплет <A, T, v>.
Эквисоединение Обозначается эквисоединение, как нетрудно догадаться, так:
Выборкой (ограничением, селекцией) на отношении В простейшем случае условие Синтаксис операции выборки:
или
Пример 6. Пусть дано отношение
Таблица 9 Отношение A Результат выборки
Удаление таблицы. Для удаления таблицы служит команда DROP TABLE. DROP TABLE [IF EXISTS] tbl_name [, tbl_name,...] [RESTRICT | CASCADE] tbl_name - Имя удаляемой таблицы. IF EXISTS – Если указан этот параметр, то при попытке удаления несущестующей таблицы ошибки не возникнет. В противном случае возникнет ошибка выполнения команды. RESTRICT и CASCADE Не несут никакой функциональности. Оставлены для упрощения переноса программы. Пример. Drop table Station Go Модификация таблиц. Для модификации служит команда Alter Table. Синтаксис: ALTER TABLE TableName1ADD | ALTER [COLUMN] FieldName1FieldType [(nFieldWidth [, nPrecision])][NULL | NOT NULL] [CHECK lExpression1 [ERROR cMessageText1]][DEFAULT eExpression1][PRIMARY KEY | UNIQUE][REFERENCES TableName2 [TAG TagName1]][NOCPTRANS] |[DROP [COLUMN] FieldName]Команда ALTER TABLE изменяет определение таблицы одним из следующих способов: -добавляет столбец -добавляет ограничение целостности -переопределяет столбец (тип данных, размер, умалчиваемое значение) -удаляет столбец -модифицирует характеристики памяти или иные параметры -включает, выключает или удаляет ограничение целостности или триггер.
Пример. alter table Station add unique(id_Water_Area, name) go alter table Station add constraint fk_Station_Relation_Water_Area foreign key (id_Water_Area) references Water_Area (id) on delete cascade
Команда Select. SELECT [ALL | DISTINCT] в_выражение,... FROM имя_табл [син_табл],... [WHERE сложн_условие] [GROUP BY полн_имя_столбца|ном_столбца,...] [ORDER BY полн_имя_столбца|ном_столбца [ASC|DESC],...] [HAVING сложн_условие]; ORDER BY. Эта команда упорядочивает вывод запроса согласно значениям в том или ином количестве выбранных столбцов. Многочисленные столбцы упорядочиваются один внутри другого, также как с GROUP BY, и вы можете определять возрастание (ASC) или убывание (DESC) для каждого столбца. По умолчанию установлено - возрастание. SELECT * FROM Orders ORDER BY cnum DESC; Мы можем также упорядочивать таблицу с помощью другого столбца, например с помощью пол amt, внутри упорядочения пол cnum. SELECT * FROM Orders ORDER BY cnum DESC, amt DESC; Агрегатые функции. Запросы могут производить обобщенное групповое значение полей точно также как и значение одного пол. Это делает с помощью агрегатных функций. Агрегатные функции производят одиночное значение для всей группы таблицы. Имеется список этих функций: * COUNT - производит номера строк или не-NULL значения полей которые выбрал запрос. * SUM - производит арифметическую сумму всех выбранных значений данного пол. * AVG - производит усреднение всех выбранных значений данного пол. * MAX - производит наибольшее из всех выбранных значений данного пол. * MIN - производит наименьшее из всех выбранных значений данного пол.
Примеры SELECT COUNT (DISTINCT name) FROM Orders; Результат, например, 5 Distinct для того, чтобы посчитать количество только уникальных по имени - (неповторяющихся) name. SELECT COUNT (*) FROM Orders; Может вывести, к примеру, 7. SELECT id, MAX (Cost) FROM Orders; Нахождения заказа с максимальной ценой. GROUP BY Предложение GROUP BY позволяет вам определять подмножество значений в особом поле в терминах другого поля, и применять функцию агрегата к подмножеству. Это дает вам возможность объединять поля и агрегатные функции в едином предложении SELECT. Например, предположим что вы хотите найти наибольшую сумму приобретений полученную каждым продавцом. Вы можете сделать раздельный запрос для каждого из них, выбрав MAX (amt) из таблицы Порядков для каждого значения пол snum. GROUP BY, однако, позволит Вам поместить их все в одну команду: SELECT snum, MAX (amt) FROM Orders GROUP BY snum;Вывод для этого запроса показывается в Рисунке 6.5. =============== SQL Execution Log ============== | | | SELECT snum, MAX (amt) | | FROM Orders | | GROUP BY snum; | | =============================================== | | snum | | ------ -------- | | 1001 767.19 | | 1002 1713.23 | | 1003 75.75 | | 1014 1309.95 | | 1007 1098.16 | | | ================================================Совершенству вышеупомянутый пример далее, предположим что вы хотите увидеть наибольшую сумму приобретений получаемую каждым продавцом каждый день. Чтобы сделать это, вы должны сгруппировать таблицу Порядков по датам продавцов, и применить функцию MAX к каждой такой группе, подобно этому:
SELECT snum, odate, MAX ((amt)) FROM Orders GROUP BY snum, odate; Вывод для этого запроса показывается в Рисунке 6.6.
=============== SQL Execution Log ============== | | | SELECT snum, odate, MAX (amt) | | FROM Orders | | GROUP BY snum, odate; | | =============================================== | | snum odate | | ------ ---------- -------- | | 1001 10/03/1990 767.19 | | 1001 10/05/1990 4723.00 | | 1001 10/06/1990 9891.88 | | 1002 10/03/1990 5160.45 | | 1002 10/04/1990 75.75 | | 1002 10/06/1990 1309.95 | | 1003 10/04/1990 1713.23 | | 1014 10/03/1990 1900.10 | | 1007 10/03/1990 1098.16 | | | ================================================ Having Если предложение WHERE определяет предикат для фильтрации строк, то предложение HAVING применяется после группировки для определения аналогичного предиката, фильтрующего группы по значениям агрегатных функций. Это предложение необходимо для проверки значений, которые получены с помощью агрегатной функции не из отдельных строк источника записей, определенного в предложении FROM, а из групп таких строк. Поэтому такая проверка не может содержаться в предложении WHERE Чтобы увидеть максимальную стоимость приобретений свыше $3000.00, вы можете использовать предложение HAVING. Предложение HAVING определяет критерии используемые чтобы удалять определенные группы из вывода, точно также как предложение WHERE делает это для индивидуальных строк. Правильной командой будет следующая:
SELECT snum, odate, MAX ((amt)) FROM Orders GROUP BY snum, odate HAVING MAX ((amt)) > 3000.00; Вывод для этого запроса показывается в Рисунке 6. 7. =============== SQL Execution Log ============== | | | SELECT snum, odate, MAX (amt) | | FROM Orders | | GROUP BY snum, odate | | HAVING MAX (amt) > 3000.00; | | =============================================== | | snum odate | | ------ ---------- -------- | | 1001 10/05/1990 4723.00 | | 1001 10/06/1990 9891.88 | | 1002 10/03/1990 5160.45 | | | ================================================
UNION. INTERSECT Как и команда UNION, INTERSECT также работает от двух заявлений SQL. Разница в том, что, хотя UNION по существу действует как оператор ИЛИ (значение выбирается, если он появляется в первый или второй оператор), INTERSECT действует команда, как оператор И (значение выбирается, только если она появляется в обоих заявлениях). Синтаксис выглядит следующим образом: [ SQL Заявление 1] INTERSECT [ SQL Заявление 2] EXCEPTEXCEPT используется для того, чтобы объединять результаты двух или более команд SELECT, при этом в результат включаются только строки, содержащиеся в первой команде SELECT и не содержащиеся во второй. Поля всех результирующих таблиц должны быть совместимыми. Если ALL не использовано, то дупликаты исключаются из объединения результатов. Экзистенциальные запросы. EXISTS - это оператор, который производит верное или неверное значение, другими словами, выражение bool. Это означает что он может работать автономно в предикате или в комбинации с другими выражениями Бул использующими Булевые операторы AND, OR, и NOT. Он берет подзапрос как аргумент и оценивает его как верный если тот производит любой вывод или как неверный если тот не делает этого. Например, мы можем решить, извлекать ли нам некоторые данные из таблицы Заказчиков если, и только если, один или более заказчиков в этой таблице находятся в San Jose
SELECT cnum, cname, city FROM Customers WHERE EXISTS (SELECT * FROM Customers WHERE city = " San Jose'); Внутренний запрос выбирает все данные для всех заказчиков в San Jose. Оператор EXISTS во внешнем предикате отмечает, что некоторый вывод был произведен подзапросом, и поскольку выражение EXISTS было полным предикатом, делает предикат верным. Подзапрос(не соотнесенный) был выполнен только один раз для всего внешнего запроса, и следова-
=============== SQL Execution Log ============ | | | SELECT snum, sname, city | | FROM Customers | | WHERE EXISTS | | (SELECT * | | FROM Customers | | WHERE city = 'San Jose'); | | ============================================= | | cnum cname city | | ----- -------- ---- | | 2001 Hoffman London | | 2002 Giovanni Rome | | 2003 Liu San Jose | | 2004 Grass Berlin | | 2006 Clemens London | | 2008 Cisneros San Jose | | 2007 Pereira Rome | ============================================= Варианты соединения в языке SQL, трехзначная логика и обработка NULL-значений. Варианты соединений.
Управляющие конструкции SQL Язык SQL является непроцедурным, но тем не менее в среде SQL Server предусмотрен ряд различных управляющих конструкций, без которых невозможно написание эффективных алгоритмов. Группировка двух и более команд в единый блок осуществляется с использованием ключевых слов BEGIN и END: <блок_операторов>::= BEGIN { sql_оператор | блок_операторов } END Сгруппированные команды воспринимаются интерпретатором SQL как одна команда. Подобная группировка требуется для конструкций поливариантных ветвлений,условных и циклических конструкций. Блоки BEGIN...END могут быть вложенными. Некоторые команды SQL не должны выполняться вместе с другими командами (речь идет о командах резервного копирования, изменения структуры таблиц, хранимых процедур и им подобных), поэтому их совместное включение в конструкцию BEGIN...END не допускается. Нередко определенная часть программы должна выполняться только при реализации некоторого логического условия. Синтаксис условного оператора показан ниже: <условный_оператор>::= IF лог_выражение { sql_оператор | блок_операторов } [ ELSE {sql_оператор | блок_операторов } ] Циклы организуются с помощью следующей конструкции: <оператор_цикла>::= WHILE лог_выражение { sql_оператор | блок_операторов } [ BREAK ] { sql_оператор | блок_операторов } [ CONTINUE ] Цикл можно принудительно остановить, если в его теле выполнить команду BREAK. Если же нужно начать цикл заново, не дожидаясь выполнения всех команд в теле, необходимо выполнить команду CONTINUE. Для замены множества одиночных или вложенных условных операторов используется следующая конструкция: <оператор_поливариантных_ветвлений>::= CASE входное_значение WHEN {значение_для_сравнения | лог_выражение } THEN вых_выражение [,...n] [ ELSE иначе_вых_значение ] END Хранимые процедуры. Хранимые процедуры представляют собой группы связанных между собой операторов SQL Выполнение в базе данных хранимых процедур вместо отдельных операторов SQL дает пользователю следующие преимущества:
Хранение процедур в том же месте, где они исполняются, обеспечивает уменьшение объема передаваемых по сети данных и повышает общую производительность системы. Создание новой и изменение имеющейся хранимой процедуры осуществляется с помощью следующей команды: <определение_процедуры>::= {CREATE | ALTER } [PROCEDURE] имя_процедуры [;номер] [{@имя_параметра тип_данных } [VARYING ] [=default][OUTPUT] ][,...n] [WITH { RECOMPILE | ENCRYPTION | RECOMPILE, ENCRYPTION }] [FOR REPLICATION] AS Ключевое слово AS размещается в начале собственно тела хранимой процедуры, т.е. набора команд SQL, с помощью которых и будет реализовываться то или иное действие. В теле процедуры могут применяться практически все команды SQL, объявляться транзакции, устанавливаться блокировки и вызываться другие хранимые процедуры. Выход из хранимой процедуры можно осуществить посредством команды RETURN. Удаление хранимой процедуры осуществляется командой: DROP PROCEDURE {имя_процедуры} [,...n] Триггеры. Триггеры являются одной из разновидностей хранимых процедур. Их исполнение происходит при выполнении для таблицы какого-либо оператора языка манипулирования данными (DML). Триггеры используются для проверки целостности данных, а также для отката транзакций. Триггер – это откомпилированная SQL-процедура, исполнение которой обусловлено наступлением определенных событий внутри реляционной базы данных. С помощью триггеров достигаются следующие цели:
Основной формат команды CREATE TRIGGER показан ниже: <Определение_триггера>::={CREATE | ALTER} TRIGGER имя_триггераON {имя_таблицы | имя_представления }[WITH ENCRYPTION ]{{ { FOR | AFTER | INSTEAD OF }{ [ DELETE] [,] [ INSERT] [,] [ UPDATE] }[ WITH APPEND ][ NOT FOR REPLICATION ]AS sql_оператор[...n]} |{ {FOR | AFTER | INSTEAD OF } { [INSERT] [,] [UPDATE] }[ WITH APPEND][ NOT FOR REPLICATION]AS{ IF UPDATE(имя_столбца)[ {AND | OR} UPDATE(имя_столбца)] [...n]|IF (COLUMNS_UPDATES(){оператор_бит_обработки} бит_маска_изменения){оператор_бит_сравнения }бит_маска [...n]}sql_оператор [...n]}}Тем не менее следует упомянуть и о присущих триггеру недостатках:
В SQL Server существует два параметра, определяющих поведение триггеров:
Триггеры различают по типу команд, на которые они реагируют. Существует три типа триггеров:
Конструкции [ DELETE] [,] [ INSERT] [,] [ UPDATE] и FOR | AFTER | INSTEAD OF } { [INSERT] [,] [UPDATE] определяют, на какую команду будет реагировать триггер. Программирование триггера При выполнении команд добавления, изменения и удаления записей сервер создает две специальные таблицы: inserted и deleted. В них содержатся списки строк, которые будут вставлены или удалены по завершении транзакции. Структура таблиц inserted и deleted идентична структуре таблиц, для которой определяется триггер. Для каждого триггера создается свой комплект таблицinserted и deleted, поэтому никакой другой триггер не сможет получить к ним доступ. В зависимости от типа операции, вызвавшей выполнение триггера, содержимое таблиц inserted и deletedможет быть разным:
БАЗЫ ДАННЫХ История и причины создания СУБД. Отношения и их свойства, ключи отношений. История и причины создания СУБД. Тогда для участия в проекте Apollo правительством США была привлечена компания Rockwell. Для того, чтобы построить космический корабль, как многие, наверное, догадываются, нужно собрать несколько миллионов деталей. И в те далекие времена была создана система управления файлами, которая отслеживала информацию о каждой детали. Но когда решили проверить эту систему, то обнаружили, что данные в ней повторяются по нескольку раз. Налицо была огромная избыточность. Следующий большой шаг в истории развития баз данных сделал доктор Эдгар Кодд (Edgar Codd) - научный сотрудник все той же самой небезызвестной IBM. В 1970 году он опубликовал свою работу "Реляционная модель для больших банков совместно используемых данных", которая в корне изменила теорию баз данных. Первыми СУБД с реализацией реляционного модуля стали System R от уже неоднократно известной IBM и Ingres от Калифорнийского университета. В истории развития баз данных можно выделить следующие этапы: 1) Файлы и файловые системы (70 годы ХХ века); 2) Базы данных на больших ЭВМ. Первые СУБД (80-е года XX века); 3) Эпоха персональных компьютеров. Настольные СУБД (90-е годы ХХ века); 4) Распределенные базы данных. Отношения и их свойства.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2017-01-25; просмотров: 733; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.144.172.115 (0.234 с.) |



 Hr, и чтобы не существовал такой тип T, что <B, T>
Hr, и чтобы не существовал такой тип T, что <B, T> 
 с условием
с условием  называется отношение с тем же заголовком, что и у отношения
называется отношение с тем же заголовком, что и у отношения  , где
, где  - один из операторов сравнения (
- один из операторов сравнения ( и т.д.), а
и т.д.), а  и
и  - атрибуты отношения
- атрибуты отношения  ,
,
 будет иметь вид:
будет иметь вид:



