Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Подсистема обработки запросов и представления данныхСтр 1 из 10Следующая ⇒
I. Понятие хранилище данных
В основе концепции хранилища данных лежат две основные идеи - интеграция разъединенных детализированных данных (детализированных в том смысле, что они описывают некоторые конкретные факты, свойства, события и т.д.) в едином хранилище и разделение наборов данных и приложений, используемых для оперативной обработки и применяемых для решения задач анализа. Определение понятия «хранилище данных» первым дал Уильям Г. Инмон. В ней он определил хранилище данных как «предметно-ориентированную, интегрированную, содержащую исторические данные, не разрушаемую совокупность данных, предназначенную для поддержки принятия управленческих решений». Хранилище данных - это пассивный объект в составе ДПД, в котором данные сохраняются для последующего доступа. Хранилище данных допускает доступ к хранимым в нем данным в порядке, отличном от того, в котором они были туда помещены. Агрегатные хранилища данных, как например, списки и таблицы, обеспечивают доступ к данным в порядке их поступления, либо по ключам.
Диаграммы потоков данных
Функциональная модель представляет собой набор диаграмм потоков данных (далее - ДПД), которые описывают смысл операций и ограничений. ДПД отражает функциональные зависимости значений, вычисляемых в системе, включая входные значения, выходные значения и внутренние хранилища данных. ДПД - это граф, на котором показано движение значений данных от их источников через преобразующие их процессы к их потребителям в других объектах. ДПД содержит процессы, которые преобразуют данные, потоки данных, которые переносят данные, активные объекты, которые производят и потребляют данные, и хранилища данных, которые пассивно хранят данные. Процессы Процесс преобразует значения данных. Процессы самого нижнего уровня представляют собой функции без побочных эффектов (примерами таких функций являются вычисление суммы двух чисел, вычисление комиссионного сбора за выполнение проводки с помощью банковской карточки и т.п.). Весь граф потока данных тоже представляет собой процесс (высокого уровня). Процесс может иметь побочные эффекты, если он содержит нефункциональные компоненты, такие как хранилища данных или внешние объекты.
На ДПД процесс изображается в виде эллипса, внутри которого помещается имя процесса; каждый процесс имеет фиксированное число входных и выходных данных, изображаемых стрелками (см. Рис. 1).
Рис. 1. Примеры процессов
Процессы реализуются в виде методов (или их частей) и соответствуют операциям конкретных классов. Потоки данных Поток данных соединяет выход объекта (или процесса) с входом другого объекта (или процесса). Он представляет промежуточные данные вычислений. Поток данных изображается в виде стрелки между производителем и потребителем данных, помеченной именами соответствующих данных; примеры стрелок, изображающих потоки данных, представлены на рисунке. На первом примере изображено копирование данных при передаче одних и тех же значений двум объектам, на втором - расщепление структуры на ее поля при передаче разных полей структуры разным объектам.
Рис. 2. Потоки данных Активные объекты Активным называется объект, который обеспечивает движение данных, поставляя или потребляя их. Активные объекты обычно бывают присоединены к входам и выходам ДПД. Примеры активных объектов показаны на рисунке. На ДПД активные объекты обозначаются прямоугольниками.
Рис. 3. Активные объекты (экторы)
Пример хранилища данных
Рис. 4. Хранилища данных
Идея хранилищ данных обязана своим развитием многим людям. Хотя эту идею предвосхищали в своих работах многие исследователи, можно смело утверждать, что первой публикацией, посвященной именно хранилищам данных, была статья Девлина (Devlin) и Мэрфи(Murphy), вышедшая в 1988 году. В 1992 году Уильям Г.Инмон(William H. Inmon) написал монументальную монографию Building the Data Warehouse (Построение хранилищ данных), в которой определил хранилище данных, как «»предметно-ориентированную, интегрированную, вариантную по времени, не разрушаемую совокупность данных, предназначенную для поддержки принятия управленческих решений». Предметная ориентация означает, что хранилище данных предназначено для предоставления данных, связанных с одним организационным процессом. В качестве примера можно рассмотреть данные, хранимые практически любым учебным заведением в разных унаследованных системах. В ВУЗе скорее всего, есть подсистемы учета дебиторской и кредитной задолженности, заработной платы, финансовой помощи и регистрационная система. Последняя обычно хранит весьма ограниченный объем исторических данных и данных о студентах, обучающихся в группах, а также преподавателях, ведущих занятия в этих группах. Предметная область посещения групп может включать исторические данные о записи студентов в группы и преподавателях, обучающих эти группы. В то время как оперативная система регистрации должна включать данные о выпускной оценке, полученной студентом, предметная область посещения групп, скорее всего, не касается этих подробностей.
При перенесении данных из оперативной системы в хранилище перед загрузкой они преобразуются. Различного рода несоответствия в кодировании, типах данных и других «свойствах», присущих исходной системе, устраняются. Это также отличный повод для анализа данных исходной системы и приведения в соответствие всех расхождений реального состояния данных с их типами и кодами, представленными в документации. Вообще говоря, построение хранилища данных открывает возможность избавиться от нежелательных «свойств» оперативной системы. Другим важным свойством, отличающим хранилище данных от оперативной системы, является то, что оно не разрушается. В то время как оперативная система выполняет над хранимыми данными операции обновления, удаления и вставки, в хранилище помещается большой объем данных, которые, будучи раз загруженными, уже никогда более не подвергаются каким-либо изменениям. (Конечно, редкие исключения из этого правила бывают) Характерной особенностью хранилища данных является то, что два разных корпоративных пользователя, выполняющие один и тот же запрос к хранилищу данных в разное время, получат один и тот же результат. Это исключает ситуации, при которых незапланированное извлечение данных и генерация отчетов приводят к различным результатам. Еще одна особенность хранилища данных – независимость от времени. Если оперативная система содержит только текущие данные, то системы хранилищ данных содержат как исторические данные, так и данные, которые имели статус текущих при последней загрузке хранилища. Временные рамки данных, содержащихся в хранилище, изменяются в широких пределах в зависимости от типа системы. Однако обычно временные рамки данных, находящихся в хранилище, лежат в пределах от 15-ти месяцев до пяти лет. Данные большей давности, как правило, переносятся в архив на магнитной ленте или CDROM, если, конечно, их присутствие в хранилище данных больше не требуется. Системы оперативных данных и информационные системы на основе хранилищ данных обладают рядом противоположных характеристик, которые лучше всего сравнивать непосредственно одну с другой. В таблице 1 приведен краткий перечень основных свойств систем каждого типа.
Таблица 1. Сравнительные характеристики хранилищ данных и оперативных систем
В настоящее время хранилища данных построены для столь большого числа предметных областей, что их невозможно здесь перечислить. Масштабы и способ использования этих хранилищ данных изменяются в широких пределах в зависимости от типа организации и вида деловой информации, для поддержки которых они разрабатывались. Вот некоторые из наиболее распространенных областей применения хранилищ данных.
Общие свойства
Хранилище данных создается с целью: · Интеграции в одном месте, согласования и, возможно, агрегации ранее разъединенных детализированных данных: o Исторических архивов o Данных из оперативных систем o Данных из внешних источников · Разделения наборов данных, используемых для оперативной обработки, и наборов данных, используемых для решения задач поддержки принятия решений. · Обеспечения всесторонней информационной поддержки максимальному кругу пользователей. Хранилище данных играет в первую очередь роль интегратора и аккумулятора исторических данных. Структура организации хранилища ориентирована на предметные области. Предметно-ориентированное хранилище содержит данные, поступающие из различных оперативных БД и внешних источников. Хранилище представляет собой совокупность данных, отвечающую следующим характеристикам: · ориентированность на предметную область или ряд предметных областей, · интегрированность, · зависимость от времени (поддержка хронологии), · постоянство.
Первая особенность хранилища данных заключается в его ориентированности на предметный аспект. Предметная направленность контрастирует с классической ориентированностью прикладных приложений на функциональность и процессы. Приложения всегда оперируют функциями, такими, например, как открытие сделки, кредитование, выписка накладной, зачисление на счет и т.д. Хранилище данных организовано вокруг фактов и предметов, таких, как сделка, сумма кредита, покупатель, поставщик, продукт.
Интегрированность
Наиболее важный аспект хранилища данных состоит в том, что данные, находящиеся в хранилище, интегрированы. Интегрированность проявляется во многих аспектах: · в согласованности имен, · в согласованности единиц измерения переменных, · в согласованности структур данных, · в согласованности физических атрибутов данных и др. Контраст между интеграцией данных в хранилище данных и в прикладном окружении иллюстрируется следующим образом. Первая причина возможного рассогласования приложений заключается в наличии множества средств разработки. Каждое средство разработки диктует определенные правила, часть из которых индивидуальна для данного средства. Не секрет, что каждый разработчик предпочитает одни средства разработки другим. Если два разработчика используют различные средства разработки, они, как правило, применяют индивидуальные особенности средств, а значит, возникает вероятность несогласованности между создаваемыми системами. Вторая причина возможного рассогласования приложений заключается в существовании множества способов построения приложения. Способ построения конкретного приложения зависит от стиля разработчика, от времени, когда это приложение разрабатывалось, а также от ряда факторов, характеризующих конкретные условия разработки приложения. Все это отражается на используемых способах задания ключевых структур, способах кодирования, обозначения данных, физических характеристиках данных и т.д. Таким образом, если два разработчика создают различные способы построения приложений, имеется высокая вероятность того, что полной согласованности между системами не будет. Интеграция данных по единицам измерения атрибутов состоит в следующем. Разработчики приложений к вопросу о способе задания размеров продукции могут подходить несколькими путями. Размеры могут задаваться в сантиметрах, дюймах, ядрах и т.д. Каков бы ни был источник данных, если информация поступит в хранилище, она должна быть приведена к одним и тем же единицам измерения, принятым в качестве стандарта в хранилище.
Зависимость от времени
Все данные в хранилище в определенный момент времени совместны (непротиворечивы). Для оперативных систем эта базовая характеристика данных соответствует совместности данных в момент доступа. Когда в оперативной среде осуществляется доступ к данным, ожидается, что данные имеют совместные значения только в момент доступа к ним. Зависимость от времени хранилища данных проявляется в следующем. Данные в хранилище представлены за временной промежуток от года до 10 лет. В оперативной среде представление данных осуществляется в промежутке от текущего значения до нескольких десятков дней. Приложения с высокой производительностью для обеспечения эффективного процесса транзакций должны работать с минимальным количеством данных. Следовательно, оперативные приложения ориентированны на короткий временной промежуток.
Другое проявление зависимости хранилища данных от времени заключается в его структуре. Каждая структура хранилища включает – явно или неявно – элемент времени. Третье проявление зависимости хранилища данных от времени состоит в неукоснительном выполнении правила, что данные, однажды корректно в хранилище записанные, не могут быть обновлены. Хранилище данных с точки зрения практического использования представляет собой большую серию моментальных снимков. Естественно, если моментальный снимок данных был сделан некорректно, он может быть изменен. Но если был получен корректный моментальный снимок, то, однажды сделанный, он в последующем изменению не подлежит. Оперативные данные, будучи корректны в момент доступа к ним, могут обновляться по мере необходимости. Постоянство
Четвертая определяющая характеристика хранилища данных – это постоянство. В оперативной среде операции обновления, добавления, удаления и изменения производятся над записями регулярно. Базовые манипуляции с данными хранилища ограничены начальной загрузкой данных и доступом к ним. В хранилище данных обновление данных не производится. Исходные (исторические) данные, после того как они были согласованны, верифицированы и внесены в хранилище данных, остаются неизменными и используются исключительно в режиме чтения. Существуют важные последствия различия обработки данных в оперативной среде и обработки в хранилище данных. На уровне проектирования хранилища данных необходимость в поддержке механизмов, обеспечивающих корректность обновлений, отпадает – обновления в хранилище данных не производятся. Это означает, что на физическом уровне проектирования при решении проблемы нормализации и физической денормализации доступ к данным может оптимизироваться без каких-либо ограничений. Другое последствие простоты работы с данными хранилища касается технологии работы с данными. Технология работы с данными в оперативной среде отличается большей сложностью. Она поддерживает функции оперативного резервного копирования и восстановления, обеспечивает целостность данных, включает механизмы разрешения конфликтов и тупиковых ситуаций. Для обработки информации в хранилище данных указанные функции не столь критичны. Характеристики хранилища данных – ориентированность на предметную область при проектировании, интегрированность данных, зависимость от времени и простота управления данными – определяют среду, которая существенно отличается от классической транзакционной среды. Источником почти всех данных среды хранилища данных являются оперативные среды. Может возникнуть ощущение, что существует огромная избыточность данных в обеих средах. Однако на практике избыточность данных в средах минимальна, поскольку: · При передаче данных из оперативной среды в хранилище данных эти данные фильтруются. Многие данные вообще никогда не выгружаются из оперативной среды. В хранилище данных передается только информация, используемая для обработки в системе поддержки принятия решений. · Временной горизонт в средах существенно различается. Данные в оперативной среде всегда являются текущими. Данные в хранилище имеют хронологию. С точки зрения временного горизонта пересечение между оперативной средой и средой хранилища данных минимально. · Хранилище данных содержит агрегированные (итоговые) данные, которые никогда не включаются в оперативную среду. · Передача данных из оперативной среды в хранилище данных сопровождается фундаментальными преобразованиями. Большинство данных при поступлении в хранилище видоизменяется.
Хранилище на самом верхнем уровне состоит, как правило, из трех подсистем: · подсистемы загрузки данных, · подсистемы обработки запросов и представления данных, · подсистемы администрирования хранилища. Подсистема загрузки данных Данная подсистема представляет собой ПО, которое в соответствии с определенным регламентом извлекает данные из источников и приводит их к единому формату, определенному для хранилища. Данная подсистема отвечает за формализованную логическую согласованность, качество и интеграцию данных, которые загружаются из источников в оперативный склад данных. Каждый источник данных требует разработки собственного загрузочного модуля. Каждый модуль должен решать два класса задач: · Начальной загрузки ретроспективных данных, · Регламентного пополнения хранилища данными из источников. Данная подсистема также по регламенту извлекает детальные данные из оперативного склада, производит их агрегирование, консолидацию, трансформацию и помещает данные в хранилище и витрины данных. Именно в данной подсистеме должны быть определены все бизнес модели консолидации данных по иерархическим измерениям и вычисления зависимых бизнес-показателей по независимым исходным данным. Реализация хранилищ данных Основным требованием аналитика, является даже не столько оперативность, сколько достоверность ответа. Но достоверность, в конечном счете, и определяется согласованностью. Пока не проведена работа по взаимному согласованию значений данных из различных источников, сложно говорить об их достоверности. Реализация ИХ может быть осуществлена несколькими способами: Рис. 5. Единое централизованное хранилище
Вся поступающая в ИХ информация должна быть преобразована в принятую в данномИХ структуру. Передача данных из операционных БД в ИХ, которая сопровождается доработкой, может быть организована по заданному временному графику и правилам доработки Рис. 6. Распределенное хранилище данных
Не исключается и наличие центрального хранилища, но в такой структуре требования к его размерности значительно облегчаются. Автономные витрины данных Одним из вариантов организации централизованного хранения и представления информации является концепция витрин данных. При таком подходе информация, относящаяся к крупной предметной области – например, информационному пространству крупной корпоративной системы, имеющей несколько достаточно самостоятельных направлений деятельности, группируется по этим направлениям в специально организованных базах данных, которые называют витринами данных. Этот подход является развитием концепции распределенного ИХ в части придания функций предметной ориентированности некоторым локальным ИХ. Такой подход позволяет обойтись сравнительно менее ресурсоемкими аппаратными и программными средствами, обеспечивает повышение адаптируемости системы к изменяющимся условиям, расширяет доступность для внедрения. Пользователь предприятия или другого подразделения корпорации получает своё ИХ, обслуживающее местные потребности. Структура хранилищ данных
ИХ представляет собой базу обобщенной информации, формируемую из множества внешних и внутренних источников, на основе которой выполняются статистические группировки и интеллектуальный анализ данных. В основе ИХ лежит понятие многомерного информационного пространства или гиперкуба, в ячейках которого хранятся анализируемые числовые показатели (например: объемы продаж, инвестиций, оборота и др.) Измерениями (осями) гиперкуба являются признаки анализа (например: время, группа продукции, регион и др.) При хранении признаки анализа отделяются от фактических данных. Основными составляющими структуры хранилищ данных являются таблица фактов (fact table) и таблицы измерений (dimension tables). Таблица фактов Таблица фактов является основной таблицей хранилища данных. Как правило, она содержит сведения об объектах или событиях, совокупность которых будет в дальнейшем анализироваться. Обычно говорят о четырех наиболее часто встречающихся типах фактов. К ним относятся: · факты, связанные с транзакциями (Transaction facts). Они основаны на отдельных событиях (типичными примерами которых являются телефонный звонок или снятие денег со счета с помощью банкомата); · факты, связанные с «моментальными снимками» (Snapshot facts). Основаны на состоянии объекта (например, банковского счета) в определенные моменты времени, например на конец дня или месяца. Типичными примерами таких фактов являются объем продаж за день или дневная выручка; · факты, связанные с элементами документа (Line-item facts). Основаны на том или ином документе (например, счете за товар или услуги) и содержат подробную информацию об элементах этого документа (например, количестве, цене, проценте скидки); · факты, связанные с событиями или состоянием объекта (Event or state facts). Представляют возникновение события без подробностей о нем (например, просто факт продажи или факт отсутствия таковой без иных подробностей).
Таблица фактов, как правило, содержит уникальный составной ключ, объединяющий первичные ключи таблиц измерений. Чаще всего это целочисленные значения либо значения типа «дата/время» — ведь таблица фактов может содержать сотни тысяч или даже миллионы записей, и хранить в ней повторяющиеся текстовые описания, как правило, невыгодно — лучше поместить их в меньшие по объему таблицы измерений. При этом как ключевые, так и некоторые неключевые поля должны соответствовать будущим измерениям OLAP-куба. Помимо этого таблица фактов содержит одно или несколько числовых полей, на основании которых в дальнейшем будут получены агрегатные данные. Пример таблицы фактов, которая может быть построена на основе базы данных Northwind, приведен на рис. 7.
Рис. 7. Пример таблицы фактов
В данном примере измерениям будущего куба соответствуют первые шесть полей, а агрегатным данным — последние четыре. Отметим, что для многомерного анализа пригодны таблицы фактов, содержащие как можно более подробные данные (то есть соответствующие членам нижних уровней иерархии соответствующих измерений). В данном случае предпочтительнее взять за основу факты продажи товаров отдельным заказчикам, а не суммы продаж для разных стран — последние все равно будут вычислены OLAP-средством. Исключение можно сделать, пожалуй, только для клиентских OLAP-средств, поскольку в силу ряда ограничений они не могут манипулировать большими объемами данных. Отметим, что в таблице фактов нет никаких сведений о том, как группировать записи при вычислении агрегатных данных. Например, в ней есть идентификаторы продуктов или клиентов, но отсутствует информация о том, к какой категории относится данный продукт или в каком городе находится данный клиент. Эти сведения, в дальнейшем используемые для построения иерархий в измерениях куба, содержатся в таблицах измерений. Таблицы измерений Таблицы измерений содержат неизменяемые либо редко изменяемые данные. В подавляющем большинстве случаев эти данные представляют собой по одной записи для каждого члена нижнего уровня иерархии в измерении. Таблицы измерений также содержат как минимум одно описательное поле (обычно с именем члена измерения) и, как правило, целочисленное ключевое поле для однозначной идентификации члена измерения. Если будущее измерение, основанное на данной таблице измерений, содержит иерархию, то таблица измерений также может содержать поля, указывающие на «родителя» данного члена в этой иерархии. Нередко (но не всегда) таблица измерений может содержать и поля, указывающие на «прародителей», и иных «предков» в данной иерархии (это обычно характерно для сбалансированных иерархий), а также дополнительные атрибуты членов измерений, содержавшиеся в исходной оперативной базе данных (например, адреса и телефоны клиентов). Каждая таблица измерений должна находиться в отношении «один ко многим» с таблицей фактов. Отметим, что скорость роста таблиц измерений должна быть незначительной по сравнению со скоростью роста таблицы фактов; например, добавление новой записи в таблицу измерений, характеризующую товары, производится только при появлении нового товара, не продававшегося ранее. Структура таблицы измерений приведена на рисунке 8.
Рис. 8. Таблица измерений
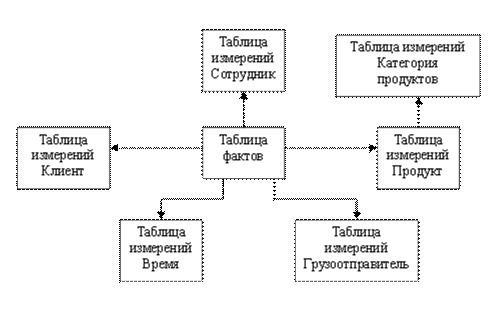
Одно измерение куба может содержаться как в одной таблице (в том числе и при наличии нескольких уровней иерархии), так и в нескольких связанных таблицах, соответствующих различным уровням иерархии в измерении. Если каждое измерение содержится в одной таблице, такая схема хранилища данных носит название «звезда» (star schema). Пример такой схемы приведен на рис. 9.
Рис. 9. Пример схемы «звезда»
Если же хотя бы одно измерение содержится в нескольких связанных таблицах, такая схема хранилища данных носит название «снежинка» (snowflake schema). Дополнительные таблицы измерений в такой схеме, обычно соответствующие верхним уровням иерархии измерения, находятся в соотношении «один ко многим» с главной таблицей измерений, соответствующей нижнему уровню иерархии. Пример схемы «снежинка» приведен на рис.10.
Рис. 10.Пример схемы «снежинка»
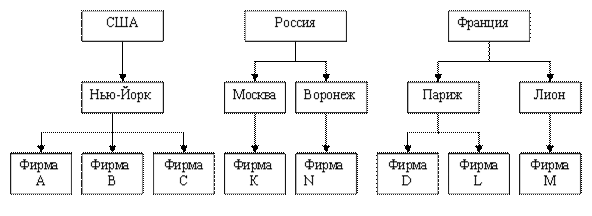
Отметим, что даже при наличии иерархических измерений с целью повышения скорости выполнения запросов к хранилищу данных нередко предпочтение отдается схеме «звезда». Говоря об измерениях, следует упомянуть о том, что значения, могут иметь различные уровни детализации. Например, нас может интересовать суммарная стоимость заказов, сделанных клиентами в разных странах, либо суммарная стоимость заказов, сделанных иногородними клиентами или даже отдельными клиентами. Естественно, результирующий набор агрегатных данных во втором и третьем случаях будет более детальным, чем в первом. Заметим, что возможность получения агрегатных данных с различной степенью детализации соответствует одному из требований, предъявляемых к хранилищам данных, — требованию доступности различных срезов данных для сравнения и анализа. Поскольку в рассмотренном примере в общем случае в каждой стране может быть несколько городов, а в городе — несколько клиентов, можно говорить об иерархиях значений в измерениях. В этом случае на первом уровне иерархии располагаются страны, на втором — города, а на третьем — клиенты рис. 11.
Рис. 11. Иерархия в измерении, связанная с географическим положением клиентов
Отметим, что иерархии могут быть сбалансированными (balanced), как, например, иерархия, представленная на рис. 3, а также иерархии, основанные на данных типа "дата—время", и несбалансированными (unbalanced). Типичный пример несбалансированной иерархии — иерархия типа "начальник—подчиненный" (рис. 12).
Рис. 12.Несбалансированная иерархия
Существуют также иерархии, занимающие промежуточное положение между сбалансированными и несбалансированными (они обозначаются термином ragged — "неровный"). Обычно они содержат такие члены, логические "родители" которых находятся не на непосредственно вышестоящем уровне. Например, в географической иерархии есть уровни Страна, Города и Штаты, но при этом в наборе данных имеются страны, не имеющие штатов или регионов между уровнями Страна и Города.
V. Вопросы реализации Хранилищ Данных
Аналитические системы предъявляют высокие требования к аппаратному и программному обеспечению. И, приступая к построению аналитической системы, следует понимать, что её реализация практически невозможна без разрешения таких вопросов как: Неоднородность программной среды. Распределенность. Защиты данных от несанкционированного доступа. Построения и ведения многоуровневых справочников метаданных. Эффективное хранение и обработка очень больших объемов данных. Распределенность. Хранилища Данных уже по своей природе являются распределенным решением. В основе концепции Хранилищ Данных, лежит физическое разделение узлов, в которых выполняется операционная обработка, от узлов в которых выполняется анализ данных. И хотя, при реализации такой системы, нет необходимости в строгой синхронизации данных в различных узлах, средства асинхронной асимметричной репликации данных являются неотъемлемой частью практически любого решения. Метаданные Наличие метаданных и средств их представления конечным пользователям является одним из основополагающих факторов успешной реализации Хранилища Данных. Более того, без наличия актуальных, максимально полных и легко понимаемых пользователем описаний данных, Хранилище Данных превращается в обычный, но очень дорогостоящий электронный архив. Первой же задачей, с которой сталкиваешься при проектировании и реализации системы Хранилищ Данных, является необходимость одновременной работы с самыми разнородными внешними источниками данных, несогласованностью их структур и форматов, масштабами и количеством архивов, которые должны быть переработаны и загружены. И при построении такой системы, разработчику сложно обойтись без высокоуровневых средств описания информационной модели системы. Причем, эта модель должна содержать описания не только целевых структур данных в БД Хранилища, но и структур данных в источниках их получения (различных информационных системах, архивах, электронных справочниках и т.д.), правила, процедуры и периодичность их выборки и выгрузки, процедуры и места согласования и агрегации. Здесь следует сделать несколько замечаний относительно выбора конкретных средств проектирования. Как уже было сказано выше, характерными свойствами аналитической системы, является: o Разнородность компонент. o Ориентированность на нерегламентированную работу с данными. Рассмотрим, как это влияет на выбор и требования к средствам проектирования. С одной стороны, из-за разнородности программных и системных компонент образующих Хранилища и малой доли регламентированных пользовательских приложений, чаще всего результатом проектирования системы будет не готовый к исполнению программный продукт, а база метаданных, содержащая всестороннее многоуровневое описание целевой информационной системы. С другой стороны в аналитических системах, именно вопросы полноты, актуальности, простоты использования и понимания метаданных приобретают особую актуальность. Таблица 2. Уровни метаданных в Хранилище Данных
Вопросы защиты данных Собрав в одном месте всю информацию об истории развития организации, ее успехах и неудачах, о взаимоотношениях с поставщиками и заказчиками, об истории развития и состоянии рынка, менеджеры получают уникальную возможность для анализа прошлой деятельности, сегодняшнего дня и построения обоснованных прогнозов на будущее. Однако не следует забывать и о том, что если не обеспечены надлежащие средства защиты и ограничения прав доступа, вы можете снабдить этой информацией и ваших конкурентов. Одним из первых же вопросов, встающих при обсуждении проекта Хранилища Данных, является вопрос защиты данных. Чисто психологически, многих пугают не столько затраты на реализацию системы Хранилищ Данных, а то, что доступ к критически значимой информации может получить кто-либо, не имеющий на это права. В таких системах, часто оказывается недостаточно защиты обеспечиваемой в стандартных конфигурациях коммерческих СУБД. Региональный менеджер должен видеть только те данные, которые относятся к его региону, а менеджер подразделения не должен видеть данные, относящиеся ко всей фирме. Но, для повышения эффективности доступа к данным, в целевой БД Хранилища Данных, все эти данные, как правило, хранятся в виде единой фактологической таблицы. Следствием этого, является то, что средства реализации должны поддерживать ограничения доступа не только на уровне отдельных таблиц и их колонок, но и отдельных строк в таблице. Не менее остро стоят и вопросы авторизации и идентификации пользователей, защиты данных в местах их преобразования и согласования, в процессе их передачи по сети (шифрование паролей, текстов запросов, данных). Задачи Хранилища данных В классическом представлении под целью создания Хранилища данных понимается поддержка принятия решений, другим словами обеспечение всех менеджеров предприятия полной, достоверной, согласованной и своевременной информацией из единого источника. Для реализации этой цели Хранилище данных должно выполнять ряд задач: Консолидация данных Интеграция данных 3. Агрегация данных 4. Расчеты производных показателей 5. Предоставление данных для поддержки принятия решений (DSS) Консолидация данных Консолидация данных – это сбор в единую базу данных из удаленных филиалов многофилиального предприятия, или предприятий, входящих в холдинг (рис. 9). Консолидированные данные необходимы центральному руководству, чтобы осуществлять глобальное управление бизнесом, внедрять единую политику в филиалах и осуществлять контроль над их деятельностью.
|
|||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-12-30; просмотров: 723; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.145.173.112 (0.147 с.) |