Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Многомерные хранилища данных
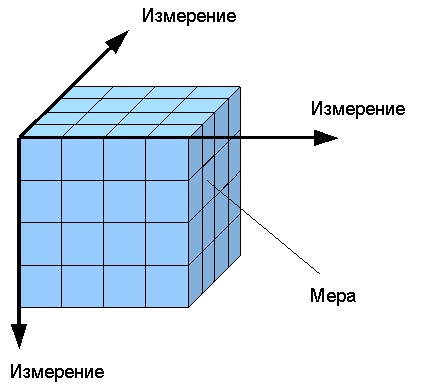
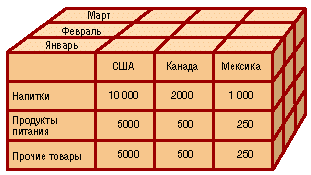
Основное назначение многомерных хранилищ данных (МХД) — поддержка систем, ориентированных на аналитическую обработку данных, поскольку такие хранилища лучше справляются с выполнением сложных нерегламентированных запросов. Сущность многомерного представления данных состоит в следующем. Большинство реальных бизнес-процессов описывается множеством показателей, свойств, атрибутов и т.д. Например, для описания процесса продаж могут понадобиться сведения о наименованиях товаров или их групп, о поставщике и покупателе, о городе, где производились продажи, а также о ценах, количествах проданных товаров и общих суммах. Кроме того, для отслеживания процесса во времени должен быть введен в рассмотрение такой атрибут, как дата. Если собрать всю эту информацию в таблицу, то она окажется сложной для визуального анализа и осмысления. Более того, она может оказаться избыточной (аномалии РБД). Все это способно окончательно запутать любого, кто попытается извлечь из такой таблицы полезную информацию с целью анализа текущего состояния продаж и поиска путей оптимизации процесса торговли. Указанные проблемы возникают по одной простой причине: в плоской таблице хранятся многомерные данные. Многомерный куб можно рассматривать как систему координат, осями которой являются измерения, например Дата, Товар, Покупатель. По осям будут откладываться значения измерений — даты, наименования товаров, названия фирм-покупателей, ФИО физических лиц и т.д. В такой системе каждому набору значений измерений (например, «дата — товар — покупатель») будет соответствовать ячейка, в которой можно разместить числовые показатели (то есть факты), связанные с данным набором. Таким образом, между объектами бизнес-процесса и их числовыми характеристиками будет установлена однозначная связь.
Преимущества многомерного подхода. · Представление данных в виде многомерных кубов более наглядно, чем совокупность нормализованных таблиц реляционной модели, структуру которой представляет только администратор БД. · Возможности построения аналитических запросов к системе более широки. · В некоторых случаях использование многомерной модели позволяет значительно уменьшить продолжительность поиска, обеспечивая выполнение аналитических запросов практически в режиме реального времени. Это связано с тем, что агрегированные данные вычисляются предварительно и хранятся в многомерных кубах вместе с детализированными, поэтому тратить время на вычисление агрегатов при выполнении запроса уже не нужно.
Недостатки. · Для ее реализации требуется больший объем памяти. (объем данных, который может поддерживаться МХД, обычно не превышает нескольких десятков гигабайт). · Многомерная структура труднее поддается модификации; при необходимости встроить еще одно измерение требуется выполнить физическую перестройку всего многомерного куба. Таким образом, применение МХД целесообразно только в тех случаях, когда объем используемых данных сравнительно невелик, а сама многомерная модель имеет стабильный набор измерений. Достаточно очевидно, что даже при небольших объемах данных отчет, представленный в виде двухмерной таблицы (Модели компьютеров по оси Y и Время по оси X), нагляднее и информативнее отчета с реляционной построчной формой организации.
Но в любом магазине имеется не три модели товара, а значительно больше (например, 30), и анализ проводится не за три, а за 12 месяцев. В случае построчного (реляционного) представления будет получен отчет в 360 строк (30х12). Гибридные хранилища данных Многомерная и реляционная модели ХД имеют свои преимущества и недостатки. Например, многомерная модель позволяет быстрее получить ответ на запрос, но не дает возможности эффективно управлять такими же большими объемами данных, как реляционная модель. Логично было бы использовать такую модель ХД, которая представляла бы собой комбинацию реляционной и многомерной моделей и позволяла бы сочетать высокую производительность, характерную для многомерной модели, и возможность хранить сколь угодно большие массивы данных, присущую реляционной модели. Такая модель, сочетающая в себе принципы реляционной и многомерной моделей, получила название гибридной, или HOLAP (Hybrid OLAP).
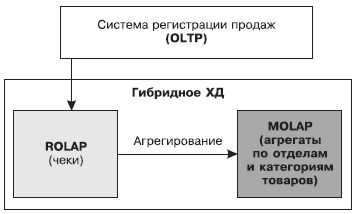
Хранилища данных, построенные на основе HOLAP, называются гибридными хранилищами данных (ГХД).
Главным принципом построения ГХД является то, что детализированные данные хранятся в реляционной структуре (ROLAP), которая позволяет хранить большие объемы данных, а агрегированные — в многомерной (MOLAP), которая позволяет увеличить скорость выполнения запросов (поскольку при выполнении аналитических запросов уже не требуется вычислять агрегаты). Пример В супермаркете, ежедневно обслуживающем десятки тысяч покупателей, установлена регистрирующая OLTP-система. При этом максимальному уровню детализации регистрируемых данных соответствует покупка по одному чеку, в котором указываются общая сумма покупки, наименования или коды приобретенных товаров и стоимость каждого товара. Оперативная информация, состоящая из детализированных данных, консолидируется в реляционной структуре ХД. С точки зрения анализа представляют интерес обобщенные данные, например, по группам товаров, отделам или некоторым интервалам дат. Поэтому исходные детализированные данные агрегируются, и вычисленные агрегаты сохраняются в многомерной структуре гибридного ХД.
Если данные, поступающие из OLTP-системы, имеют большой объем (несколько десятков тысяч записей в день и более) и высокую степень детализации, а для анализа используются в основном обобщенные данные, гибридная архитектура хранилища оказывается наиболее подходящей. Недостатком гибридной модели является усложнение администрирования ХД из-за более сложного регламента его пополнения, поскольку при этом необходимо согласовывать изменения в реляционной и многомерной структурах. Преимущества: Построение OLAP-куба выполняется по запросу OLAP-средства на основе реляционных и многомерных данных. Такой подход позволяет избежать взрывного роста данных. При этом можно достичь оптимального времени исполнения клиентских запросов. Анализ данных ВВЕДЕНИЕ В OLAP
Любая транзакционная система, как правило, содержит два типа таблиц. Один из них отвечает за быстрые транзакции. Например, при продаже билетов необходимо обеспечить работу большого числа кассиров, которые обмениваются с системой короткими сообщениями. Вводимая и распечатываемая информация, касающаяся фамилии пассажира, даты вылета, рейса, места, пункта назначения, может быть оценена в 1000 байт. Таким образом, для обслуживания пассажиров необходима быстрая обработка коротких записей. Другой тип таблиц содержит итоговые данные о продажах за указанный срок, по направлениям, по категориям пассажиров. Эти таблицы используются аналитиками и финансовыми специалистами раз в месяц, или в конце года, когда необходимо подвести итоги деятельности компании. И если количество аналитиков в десятки раз меньше числа кассиров, то объемы данных, необходимых для анализа, превышают размер средней транзакции на несколько порядков величины. Естественно, что во время выполнения аналитических работ время отклика системы на запрос о наличии билета увеличивается.
Вторым фактором, приведшим к разделению аналитических и транзакционных систем, являются разные требования, которые предъявляют аналитические и транзакционные системы к вычислительным комплексам. Технология OLAP (Online Analytical Processing) представляет собой методику оперативного извлечения нужной информации из больших массивов данных и формирования соответствующих отчетов. История OLAP начинается в 1993. Первоначально казалось, что разделения транзакционных и аналитических систем (OLTP – OLAP) вполне достаточно. Однако вскоре выяснилось, что OLAP–системы очень плохо справляются с ролью посредника между различными транзакционными системами - источниками данных и клиентскими приложениями. Стало ясно, что необходима среда хранения аналитических данных. И поначалу на эту роль претендовали единые базы данных, в которые предлагалось копировать исходную информацию из источников данных. Эта идея оказалась не вполне жизнеспособной, поскольку транзакционные системы разрабатывались, как правило, без единого плана, и содержали противоречивую и несогласованную информацию.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2016-12-30; просмотров: 522; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.189.2.122 (0.011 с.) |