Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Понятие распределенной информационной системы. Распределенные базы данных. Принципы создания и функционирования распределенных баз данных.Стр 1 из 15Следующая ⇒
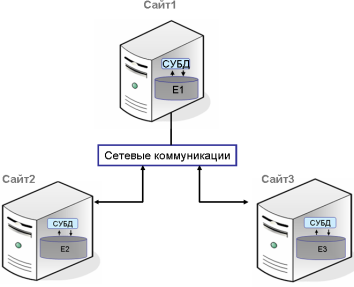
Понятие распределенной информационной системы. Распределенные базы данных. Принципы создания и функционирования распределенных баз данных. Распределенная база данных (Distributed Database – DDB) – это совокупность логически взаимосвязанных баз данных, распределенных в компьютерной сети. В распределенных системах база данных состоит из нескольких частей, которые называются фрагментами базы данных. Пример конфигурации распределенной базы данных представлен на рис.
Распределенная база данных предполагает физическое разделение на фрагменты и распределение их по локальным узлам сети данных. Главный критерий распределения данных в сети состоит в следующем: данные должны находиться там, где существует наибольшая частота обращения к ним. Такой подход обеспечивает быстрый и эффективный доступ к данным. Каждый фрагмент базы данных сохраняется на одном или нескольких узлах, соединенных между собой линиями связи, и каждый из них работает под управлением отдельной СУБД. Будучи фрагментом общего пространства данных, часть базы данных функционирует как полноценная локальная база данных. Управление выполняется локально и независимо от других узлов системы. Пользователи взаимодействуют с распределенной базой данных через приложения. Принципы создания и функционирования распределенных баз данных Принципы построения РБД. · Минимизация интенсивности обмена данными (сетевого трафика) · Оптимальное размещение серверных и клиентских приложений в сети · Декомпозиция данных на часто и редко используемые сегменты (для правильной настройки репликации - размещение наиболее часто используемых данных на АРМ конечных пользователей) · Периодическое сохранение копий данных и выполнение действий по поддержке целостности распределенной информационной системы. К. Дейт сформулировал 12 требований к распределенной базе данных: 1. Локальная автономия. Означает, что управление данными на каждом из узлов распределенной системы выполняется локально. 2. Независимость узлов. Предполагает, что все узлы равноправны и независимы, а расположенные на них базы являются равноправными поставщиками данных в общее пространство данных. База данных на каждом из узлов включает полный собственный словарь данных и полностью защищена от несанкционированного доступа.
3. Непрерывность операций. Это возможность непрерывного доступа к данным в рамках распределенной базы данных вне зависимости от их расположения и вне зависимости от операций, выполняемых на локальных узлах. 4. Прозрачность расположения. Пользователь, обращающийся к базе данных, ничего не должен знать о реальном, физическом размещении данных в узлах информационной системы. 5. Прозрачная фрагментация. Это требование определяется как возможность распределенного (то есть на различных узлах) размещения данных, логически представляющих собой единое целое. 6. Независимое тиражирование. Предполагает перенос изменений объектов исходной базы данных в базы, расположенные на других узлах распределенной системы. 7. Обработка распределенных запросов. Заключается в возможности выполнения операций выборки данных из распределенной базы данных, посредством запросов на языке SQL. 8. Обработка распределенных транзакций. Предполагает выполнение операций обновления распределенной базы данных, не нарушающих целостность и согласованность данных. 9. Независимость от оборудования. Означает, что в качестве узлов распределенной системы могут выступать компьютеры любых моделей и производителей. Система должна выполняться на любой аппаратной платформе. 10. Независимость от операционных систем. Допускает многообразие операционных систем, управляющих узлами распределенной системы. 11. Прозрачность сети. Трактуется как возможность использования в распределенной системе любых сетевых протоколов.
Типы СУРаБД Гомогенная распределенная система баз данных – это такая система, в которой каждый узел имеет СУБД одного и того же типа. Гетерогенная распределенная система баз данных – это система, объединяющая несколько различных типов баз данных. Распределенные базы данных характеризуются следующими преимуществами: · разделяемость и локальная автономия. · быстрый доступ к данным. · управление распределенными данными на разных уровнях прозрачности;
· увеличение производительности системы. · увеличение гибкости реорганизации за счет модульности системы. Однако распределенные базы данных не лишены и некоторых недостатков: повышение сложности. усложнение контроля за целостностью данных; Компоненты клиента · компоненты оборудования (компьютер, процессор, жесткий диск, видео, сетевая плата и т.д.). Процессы клиента требуют значительных аппаратных ресурсов. Поэтому, они должны размещаться на компьютере, обладающем достаточной мощностью. Такие мощности облегчают создание систем с мультимедийными возможностями; · Компоненты программного обеспечения · Операционная система с возможностью многозадачной обработки информации; · развитый графический интерфейс пользователя (GUI). Для создания интерфейсных прикладных программ используются языки программирования 3-го и 4-го поколений. · коммуникационные возможности. Связка оборудование плюс операционная система должна обеспечить возможность связи с несколькими сетевыми операционными системами. Компоненты сервера Сервер, как и клиент, также имеет компоненты оборудования и ПО. Компьютер, на котором располагается процесс сервера, должен быть более мощным, т.к. серверный процесс должен уметь одновременно обрабатывать запросы от нескольких клиентов. Но сервисному процессу не нужен графический интерфейс. Характеристика серверного оборудования зависит от уровня предоставляемого сервиса: · файловые сервисы. Файловый сервер предназначен для хранения файлов общего использования; · сервер приложений позволяет с рабочих станций запускать сетевые приложения, записанные на сервере; · сервисы печати. Сервер печати печатает на подключенных к нему принтерах файлы, отправляемые на печать с рабочих станций. Клиент получает доступ к любому из принтеров так, словно он напрямую подключен к его собственному компьютеру; · сервисы факсимильной связи. Факс-сервер хранит, получает и рассылает факсимильные сообщения; · сервисы передачи данных. Позволяют клиентским ПК подключаться к серверу передачи данных, чтобы получить доступ к другим компьютерам или сервисам, к которым клиент не может подключиться непосредственно. Например, к электронным доскам объявлений, к удаленной локальной сети и т.д. · сервисы баз данных. Клиенту необходимо иметь только интерфейсную программу для получения доступа к серверу базы данных. Клиент посылает SQL-запросы на сервер. Сервер получает SQL-код, проверяет его, выполняет, а клиенту отсылает только результат; · сервисы транзакций; Сервер транзакций содержит код транзакции базы данных или процедуры, которые манипулируют информацией в БД. Интерфейсная программа на клиентском ПК посылает запрос на сервер транзакций для выполнения специфической процедуры, хранящейся на сервере БД. При этом по сети не передается никакой SQL-код. Сервер транзакций снижает нагрузку сети и обеспечивает лучшую производительность. · другие сервисы, включая обслуживание устройств CD-ROM, видео, резервное копирование и т.д. RDA-модель В модели доступа к удаленным данным на компьютере-клиенте располагаются презентационная логика и бизнес-логика приложений. На сервере находится ядро СУБД. Функции сервера определяются управлением данными и обработкой запросов со стороны клиентов. Клиент обращается к серверу с запросами на языке SQL. В ответ на запрос клиент получает только данные, соответствующие запросу.
Основное достоинство данной модели состоит в том что, во-первых, взаимодействие пользователя с сервером осуществляется с помощью стандартного языка запросов SQL. Во-вторых, это наличие большого числа готовых СУБД и других инструментальных средств, обеспечивающих быстрое создание программ клиентской части. Недостатки RDA-модели: · высокая загрузка системы передачи данных; · неудобны с точки зрения разработки, модификации и сопровождения. Так как в этой модели на клиенте располагается и презент. логика, и бизнес-логика приложений, то при повторении аналогичных функций в различных приложениях код соответствующей бизнес-логики должен быть повторен для каждого клиентского приложения. Это вызывает излишнее дублирование кода приложений. DBS-модель В модели сервера баз данных на компьютере-клиенте располагаются части приложения, реализующие только функции представления, а прикладные функции, определяющие основные алгоритмы решения задач приложения и включающие обеспечение целостности, безопасности и секретности, реализуются на стороне сервера. Работа приложения основана на механизме хранимых процедур и триггеров. Хранимые процедуры – это специальные программные модули, которые используются для извлечения или изменения данных. Существует два вида хранимых процедур: системные и пользовательские. Системные хранимые процедуры предназначены для получения информации из системных таблиц и выполнения различных служебных операций. Чаще всего такие процедуры используются при администрировании базы данных. Пользовательские хранимые процедуры создаются непосредственно разработчиками или администраторами базы данных. Обычно процедуры хранятся в словаре базы данных и могут разделяться между несколькими клиентами. Выполняются хранимые процедуры на том же компьютере, где функционирует SQL-сервер. Хранимые процедуры пишутся на процедурном языке, который зависит от конкретной СУБД. Клиентское приложение обращается к серверу с командой запуска хранимой процедуры, а сервер выполняет ее и возвращает клиенту требуемые данные. Механизм триггеров позволяет выполнять централизованный контроль целостности базы данных. Триггер – это особый тип хранимой процедуры, автоматически выполняющейся при каждой попытке изменить данные. Триггер, как и хранимая процедура, хранится в словаре базы данных. Если триггер вызывает ошибку в запросе, обновление информации не производится, а в приложение возвращается сообщение об ошибке.
Достоинства модели сервера баз данных: возможность централизованного администрирования приложений и обеспечения целостности, а также эффективное использование вычислительных и коммуникационных ресурсов. Недостатки DBS-модели: ограниченность действий, выполняемых с помощью хранимых процедур и триггеров и очень большая загрузка сервера. AS-модель Модель сервера приложений является трехзвенной моделью. На компьютере пользователя расположены приложения клиентов, обеспечивающие пользовательский интерфейс. Это нижний уровень модели. Между клиентом и сервером вводится дополнительный промежуточный уровен – сервер приложений, обеспечивающий управление данными и реализующий несколько прикладных функций. Серверов приложений может быть несколько, в зависимости от вида предоставляемого сервиса. Любая программа, запрашивающая услугу у сервера приложений, является для него клиентом. На верхнем, третьем уровне располагается удаленный сервер баз данных, выполняющий функции управления информационными ресурсами базы данных. Трехзвенная модель эффективна в тех случаях, когда требуется выполнить сложные аналитические расчеты над базой данных. К достоинствам AS-модели относят разгрузку сервера базы данных, к недостаткам – увеличение нагрузки на сеть.
7. Технологии COM\DCOM, CORBA, MIDAS, EJB. COM\DCOM Технология COM (Component Object Model) и ее вариант для распределенных систем DCOM(Distributed Component Object Model) была разработана компанией Microsoft. DCOM является расширением COM и включает в себя среду распределенных вычислений и механизм удаленного вызова процедур. Технология СОМ предоставляет модель связи и взаимодействия между компонентами и приложениями, а также реализация клиент-серверных взаимодействий при помощи интерфейсов. Технология СОМ применяется при описании API и двоичного стандарта для связи объектов различных языков и сред программирования. Технология СОМ работает с так называемыми СОМ-объектами. СОМ-объект представляет собой двоичный код, который выполняет какую-либо функцию и имеет один или более интерфейс. Все СОМ-объекты обычно содержатся в файлах с расширением DLL или OCX. Один такой файл может содержать как одиночный СОМ-объект, так и несколько СОМ-объектов. СОМ-объекты похожи на обычные объекты визуальной библиотеки компонентов Delphi. В отличие от объектов VCL Delphi, СОМ-объекты содержат свойства, методы и интерфейсы. Суть COM Программа-клиент использует при своей работе объект (объекты) некоторой другой программы (сервера) так, словно эти объекты являются частью самого клиента. Основную роль при этом играет интерфейс объектов. Клиенты СОМ связываются с объектами при помощи СОМ-интерфейсов. Обычный СОМ-объект включает в себя один или несколько интерфейсов. Каждый из этих интерфейсов имеет собственный указатель.
Интерфейсы – это группы логически или семантически связанных процедур, которые обеспечивают связь между поставщиком услуги (сервером) и его клиентом. Клиент получает именно интерфейс затребованного объекта. Интерфейсы не являются самостоятельными объектами, они лишь обеспечивают доступ к объектам. Таким образом, клиенты не могут напрямую обращаться к данным, доступ осуществляется при помощи указателей интерфейсов. Каждый интерфейс имеет свой уникальный идентификатор, который называется глобальный уникальный идентификатор (Globally Unique Identifier, GUID). Уникальные идентификаторы интерфейсов называют идентификаторами интерфейсов (Interface Identifiers, IIDs). Данные идентификаторы обеспечивают устранение конфликтов имен различных версий приложения или разных приложений. Технология СОМ имеет два явных преимущества: 1. создание СОМ-объектов не зависит от языка программирования. Таким образом, СОМ-объекты могут быть написаны на различных языках; 2. СОМ-объекты могут быть использованы в любой среде программирования под Windows. В число этих сред входят Delphi, Visual C++, C++Builder, Visual Basic, и многие другие. Хотя технология СОМ обладает явными плюсами, она имеет также и минусы, среди которых зависимость от платформы. Данная технология применима только в операционной системе Windows и на платформе Intel. CORBA CORBA (Common Request Broker Architecture) – архитектура для построения распределенных объектных приложений. Была предложена некоммерческой организацией – консорциумом OMG (Object Management Group). Технология основана на использовании брокера объектных запросов (Object Request Broker, ORB) для прозрачной отправки и получения объектами запросов в распределенном окружении. Технология позволяет строить приложения из распределенных объектов, реализованных на различных языках программирования. Как и DCOM, CORBA основывается на коммуникации типа клиент-сервер. CORBA-технология также использует интерфейс объекта. Но в этом случае схема взаимодействия объектов включает промежуточное звено (Smart agent), реализующее доступ к удаленным объектам. Smart agent моделирует сетевой каталог известных ему серверов объектов. На машине клиента создаются два объекта-посредника: Stab и ORB (Object Request Broker – брокер вызываемого объекта). ORB отвечает за все механизмы, необходимые для поиска подходящей для запроса реализации объекта, подготовки реализации к получению запроса и передачи данных в процессе выполнения запроса. Stub передает вызов брокеру, который посылает сообщение в сеть. Smart agent, получив сообщение, отыскивает сетевой адрес сервиса и передает запрос брокеру, размещенному на машине сервера. Вызов требуемого объекта производится через специальный адаптер (BOA). MIDAS MIDAS (Multi-tier Application Server Suite) представляет собой технологию создания распределенных систем, состоящих из сервера баз данных, сервера доступа к данным (который, в свою очередь, является клиентом сервера баз данных) и так называемого тонкого клиентского приложения, являющегося, соответственно, клиентом сервера доступа к данным (рис.).
Фактически два последних звена делят между собой функциональность, характерную для клиентского приложения, используемого в «классических» двухзвенных клиент-серверных системах. «Тонкий» клиент обычно является приложением, с которым работает конечный пользователь, и поэтому предназначен главным образом для предоставления пользовательского интерфейса (то есть тех форм и интерфейсных элементов, с помощью которых пользователь редактирует данные). Естественно, подобное приложение должно «знать», на каком компьютере локальной или глобальной сети находится сервер доступа к данным, каково имя (или иной идентификатор) предоставляемого им сервиса и с помощью каких средств (имеются в виду сервисы операционной системы, сетевые протоколы и т.д.) с ним можно этими данными обмениваться. Это и есть те немногочисленные параметры, которые требуют настройки. Что касается сервера доступа к данным, то обычно он недоступен конечным пользователям, и поэтому хотя у него может быть пользовательский интерфейс в традиционном понимании (формы, кнопки, поля для ввода данных), но не обязательно. Иными словами, сервер доступа к данным может представлять собой как обычное Windows-приложение с формами, так и приложение без форм, а также консольное приложение либо сервис операционной системы, пишущий сообщения для администратора системы в log-файл. Его задача — обмениваться данными с «тонким» клиентом и обращаться к серверу баз данных с собственными запросами (обычно инициированными этим обменом). Поэтому сервер доступа к данным должен, с одной стороны, предоставлять клиентам интерфейсы, позволяющие получать от него данные, а с другой стороны, быть полноценным клиентом сервера баз данных, то есть содержащий его компьютер должен иметь как минимум установленную клиентскую часть серверной СУБД. Нередко такой компьютер имеет и другие библиотеки доступа к данным, например, в прежних двух версиях MIDAS обязательной составляющей его частью была библиотека Borland Database Engine. В текущей версии MIDAS могут быть использованы и другие библиотеки, например библиотеки ADO (или исключительно те библиотеки, что содержат клиентский API и поставляются с сервером баз данных). EJB Основная идея, лежавшая в разработке технологии EJB (Enterprise JavaBeans) – создать такую инфраструктуру для компонент, чтобы они могли бы легко ``вставляться'' (``plug in'') и удаляться из серверов, тем самым увеличивая или снижая функциональность сервера. Существует подход построения информационной системы EJB (Enterprise JavaBeans) – разделение ее на три уровня. Каждый уровень имеет свои обязанности и функциональные возможности. На первом уровне находится клиентское приложение, которое занимается в основном презентационным слоем системы. Второй уровень отвечает за бизнес-логику системы и взаимодействует с презентационным слоем, отвечая на его запросы – уровень сервера приложений. Еще одним преимуществом является возможность групповой работы над системой, в которой каждый из уровней разрабатывается независимо. Кто-то проектирует структуры баз данных, кто-то "рисует" презентационные слои, а кто-то пишет оптимальные алгоритмы. Компонентная технология EJB ориентирована на возможность распределения второго уровня, т.е. если Ваш сервер приложений не справляется с нагрузкой, то есть возможность без единого изменения кода сервера приложений, разнести его на несколько вычислительных машин. А компоненты, из которых состоит второй уровень, не будут чувствовать разницы между работой на одной вычислительной машине и на нескольких машинах. Минусом таких систем является их направленность на крупные корпоративные решения.
Горизонтальная фрагментация При горизонтальной фрагментации разбиение таблицы (отношения) происходит за счет помещения в отдельные таблицы с одинаковой структурой не перекрывающихся (уникальных) групп строк (кортежей). Фактически осуществляется хранение строк одной логической таблицы в нескольких идентичных физических таблицах на различных узлах. · Каждый фрагмент хранится на отдельном узле. · Каждый фрагмент имеет уникальные строки. · Все уникальные строки имеют одинаковые атрибуты (столбцы). · Каждый фрагмент эквивалентен оператору SELECT с модифицирующим выражением WHERE по единственному атрибуту. Вертикальная фрагментация При вертикальной фрагментации разбиение таблицы (отношения) происходит по столбцам. Одни столбцы формируют одну таблицу, другие – другую. · Каждый фрагмент хранится на отдельном узле. · Каждый фрагмент имеет уникальные столбцы – за исключением ключевого столбца, который имеется во всех фрагментах. · Это эквивалентно применению оператора PROJECT. Смешанная фрагментация Эта фрагментация представляет собой комбинацию вертикальной и горизонтальной фрагментаций. Таблица может разделяться на несколько горизонтальных множеств (строк), каждая из которых разделяется на множество атрибутов (столбцов). Пример. Предположим, что имеется таблица EMP (сотрудники), в которой есть следующие атрибуты: EMP_NUM EMP_SURNAME EMP_DATA EMP_ADDRESS EMP_DEPARTMENT EMP_SALARY Горизонтальная фрагментация Руководству компании необходима информация о сотрудниках по каждому подразделению (DEPARTMENT) компании: Минск, Киев, Москва. Но каждому подразделению компании необходима информация только по своим локальным сотрудникам. На основе этого было принято решение распределить данные по подразделениям. Поэтому для реализации структуры выбрали горизонтальную фрагментацию. Вертикальная фрагментация У компании есть два отдела: отдел обслуживания и отдел приема платежей. Каждый отдел расположен в отдельном здании и каждому отделу необходима информация только по нескольким атрибутам таблицы. Отделу обслуживания – по атрибутам EMP_SURNAME, EMP_DATA, EMP_ADDRESS, EMP_DEPARTMENT Отделу приема платежей – по атрибуту EMP_SALARY. Каждый вертикальный фрагмент имеет одинаковое число строк, но включает в себя различные атрибуты, зависящие от ключевого столбца. Ключевой столбец EMP_NUM является общим для двух фрагментов.
Репликация. Понятие согласованного распределенного набора данных. Варианты репликации. Протокол репликации ROWA. Репликация (тиражирование) данных (Data Replication – DR) – это хранение одних и тех же данных (копий) в нескольких узлах. Репликацию применяют из соображений производительности, доступности, уменьшения времени доступа и безопасности. Если отдельным узлам придется постоянно получать доступ к удаленно хранящимся данным, то производительность неизбежно снизится. Решение этой задачи – использование репликации данных. Функции репликации выполняет специальный модуль СУБД – сервер тиражирования данных, называемый репликатором (replicator). Его задача – поддержка идентичности данных в принимающих базах данных (target database) данным в исходной БД. Основное понятие – понятие согласованного распределенного набора данных (consistent distributed data set – CDDS). Это набор данных, идентичность которого поддерживается репликатором во всех узлах, вовлеченных в процесс тиражирования. § CDDS должен подчиняться правилу взаимной непротиворечивости, которое требует, чтобы все копии фрагментов данных были идентичны Возможны три варианта репликации БД. БД может быть: 1. полностью реплицированной – если копии одного и того же фрагмента данных располагаются на всех узлах сети; все фрагменты реплицированы. 2. частично реплицированной – если копии одного и того же фрагмента данных располагаются на нескольких узлах сети. Большинстов СУРаБД допускают работу именно с частично-реплицированными БД. 3. нереплицированной – каждый фрагмент хранится на отдельном узле. Дублированные фрагменты отсутствуют. На репликацию влияет несколько факторов: 1. размер БД; 2. частота использования БД; 3. затраты, связанные с синхронизацией транзакций и их частей. Тиражировать можно: 1. всю БД; 2. избранные объекты БД: таблицы или представления; 3. вертикальные проекции объектов БД: избранные столбцы таблиц и/или представлений; 4. горизонтальные проекции объектов БД: избранные строки таблиц и/или представлений; 5. сочетания наборов 2-4. Где тиражируют? Основные схемы тиражирования: · "Центр – филиалы", изменения в базах данных филиалов переносятся в центральную БД, и/или наоборот; · равноправное, несколько БД разделяют общий набор изменяемых и тиражируемых данных; · каскадное, изменения в одной БД переносятся в другую БД, откуда в свою очередь в третью БД и т.д.; · через шлюзы изменения в БД могут переноситься в БД другой СУБД (неоднородная БД); · различные комбинации всех вышеперечисленных схем. Протоколы репликации Наиболее известным теоретическим критерием согласованности является критерий полной эквивалентности копий, который требует, чтобы по завершении транзакции все копии логического элемента данных были идентичны. Типичный протокол тиражирования, обеспечивающий сериализуемость по критерию полной эквивалентности копий, известен под названием ROWA (Read-Once/Write-All – одно чтение, запись во все копии). Задача протокола тиражирования – отобразить операции доступа к некоторому элементу х на множества операций над физическими копиями x (x1, x2,..., xn). Протокол ROWA отображает чтение x Read(x) на операцию чтения какой-либо из копий x Read(xi). Из какой именно копии будет производиться чтение, неважно – этот вопрос может решаться из соображений эффективности. Каждая операция записи в логический элемент данных x отображается на множество операций записи во все физические копии x. Протокол ROWA прост и прямолинеен (достоинство), но он требует доступности всех копий элемента данных, для того чтобы транзакция была завершена (недостатки). Сбой на одном из узлов приведет к блокированию транзакции, что снижает доступность базы данных.
ODBC ODBC (Open Database Connectivity) – открытый интерфейс баз данных. ODBC предназначена для обеспечения возможности взаимосвязи между различными SQL-совместимыми БД. Технология ODBC предусматривает создание дополнительного уровня между приложением и используемой СУБД. В архитектуре ODBC используется один ODBC Driver Manager и несколько ODBC-драйверов, отвечающих за реализацию особенностей доступа к каждой отдельной СУБД. Преимущества: · простота разработки приложения; · технология ODBC позволяет создавать распределенные гетерогенные приложения без учета конкретных СУБД, т.е. приложение становится независимым от СУБД. Недостатки: · снижение скорости доступа к данным, что связано с необходимостью трансляции запросов; · увеличение время обработки запросов, что связано с введением дополнительного программного слоя; · необходимы предварительная инсталляция и настройка ODBC-драйвера (указание драйвера СУБД, сетевого пути к серверу, базы данных и т.д.) на каждом рабочем месте. Параметры этой настройки являются статическими, т.е. приложение изменить их самостоятельно не может; · предоставляет доступ только к реляционным SQL-ориентированным БД. OLE DB Но данные в БД могут быть представлены в любом виде и формате (электронные таблицы, документы в rtf-формате, почтовые системы и т.д.). Возникает потребность или создать единый формат хранения данных, что дорого и неэффективно, либо нарастить имеющиеся технологии интерфейсами доступа к любым типам данных. Это требование и реализует технология OLE DB. OLE DB (Object Linking and Embedding Data Base) – технология, предоставляющее решение обеспечения COM-приложениям доступ данным независимо от типа источника данных. В технологии OLE DB используется механизм провайдеров, под которыми понимают поставщиков данных. Кроме поставщика данных имеются также сервис провайдеры, реализующие самые различные сервисные функции.
ADO, DAO Технологии ODBC и OLE DB считаются хорошими интерфейсами передачи данных, но как программные интерфейсы имеют много ограничений, поскольку являются низкоуровневыми. Для снятия этих ограничений были предложены технологии DAO и ADO. Данные технологии представляют собой высокоуровневые объектные модели (библиотеки функций) и создают еще один уровень абстракции между приложением и функциями ODBC и OLE DB. Технология ADO представляет иерархическую модель объектов для доступа к различным OLE DB-провайдерам данных. Объектная модель ADO включает объекты, обеспечивающие соединение с провайдером данных, создание SQL-запросов к данным и т.д. В целом технологию ADO можно охарактеризовать как наиболее современную технологию разработки приложений для работы с распределенными БД по технологии клиент-сервер.
BDE BDE (Borland Data Engine) – технология фирмы Borland. Данная технология реализована в виде динамически подключаемых библиотек и имеет достаточно развитый интерфейс прикладных программ, названный IDAPI (Integrated Database Application Program Interface). Этот интерфейс представляет собой набор функций для работы с базами данных
JDBC JDBC (Java Data Base Connectivity) – мобильный интерфейс к базам данных на платформе Java. Это интерфейс прикладного программирования для выполнения SQL-запросов к базам данных из программ, написанных на платформенно-независимом языке Java, позволяющем создавать как самостоятельные приложения, так и аплеты, встраиваемые в Web-страницы.
Блокировка Блокировка гарантирует уникальность доступа транзакции к элементу данных и предотвращает использование данных одной транзакцией во время их использования другой. Другими словами, транзакция Т2 не получит доступа к данным, которые в настоящий момент используются в транзакции Т1. Например, при копировании таблицы она блокируется от изменения, хотя и разрешено просматривать ее содержимое. Блокировка может выполняться на уровне: § Базы данных. На этом уровне блокируется вся база данных. Пока выполняется транзакция Т1, блокируется использование любых таблиц транзакцией Т2. Транзакции Т1 и Т2 не могут получать доступ к базе данных одновременно, даже если они используют разные таблицы. Блокировка снимается после завершения транзакции Т1. Данный уровень используется для пакетных процедур, но плохо пригоден для работы многопользовательских СУБД, поскольку возникают проблемы с производительностью, когда множество транзакций ждут доступ к одной таблице. § Таблицы. На этом уровне блокируется отдельная таблица базы данных, предотвращая доступ транзакции Т2 к любой строке, пока транзакция Т1 использует данную таблицу. Транзакции Т1 и Т2 не могут получить доступ к одной и той же таблице, даже если они используют разные строки. Транзакция Т2 должна ждать, пока транзакция Т1 разблокирует таблицу. Блокировка на уровне таблицы также мало пригодна для многопользовательских СУБД, поскольку многим транзакциям требуется доступ к разным частям одной и той же таблицы. § Страницы. При блокировке на уровне страницы СУБД будет блокировать дисковую страницу. Дисковая страница имеет фиксированный размер, например, 4 Кбайт, 8 Кбайт, 16 Кбайт и т.д. Таблица может охватывать несколько страниц. Транзакции Т1 и Т2 получают доступ к одной и той же таблице при блокировке разных дисковых страниц. Если транзакции Т2 потребуется использование строки, расположенной на странице, заблокированной транзакцией Т1, то Т2 придется ждать, пока Т1 ее разблокирует. Данный уровень блокировки наиболее часто применяется в многопользовательских СУБД. § Строки. СУБД позволяет параллельным транзакциям получать доступ к различным строкам одной и той же таблицы, даже если строки размещены на одной дисковой странице. Транзакция Т2 будет ожидать завершения транзакции Т1 только в том случае, если они обращаются к одной и той же строке. Управление такой блокировкой приводит к большим накладным расходам, т.к. блокировка требуется для каждой строки в каждой таблице БД. § Поля. Данный уровень блокировки позволяет параллельным транзакциям получать доступ к одной и той же строке, если они используют в этой строке разные поля. Этот уровень блокировки предоставляет наиболее гибкий доступ к данным в многопользовательских средах, но применяется редко, т.к. требует неоправданно больших накладных расходов. В СУБД могут применяться следующие типы блокировок: § Двоичная. Двоичная блокировка имеет только два состояния: 1 (заблокировано) и 0 (разблокировано). Если некоторый объект БД блокируется транзакцией, то ни одна другая транзакция не сможет получить доступ к этому объекту. § Разделяемая/исключающая. Исключающая блокировка устанавливается, когда транзакции необходимо обновить данные в БД и при этом на эти данные не установлена никакая другая блокировка. Исключающая блокировка должна использоваться, когда есть вероятность конфликта. Разделяемая блокировка применяется, когда одна транзакция считывает данные из БД и нет других транзакций, обновляющих те же данные. Выделяют следующие виды блокировок: 1. Полная блокировка. Означает полное завершение любых операций над основными объектами БД (таблицами, отчетами и формами). Этот вид блокировки обычно применяется при изменении структуры объектов. 2. Блокировка от записи. Накладывается в случаях, когда можно читать данные, но не изменять их. Изменение структуры также запрещается. 3. Предохраняющая блокировка от записи. Предохраняет объект от наложения на него со стороны других операций полной блокировки либо блокировки от записи. Этот вид блокировки позволяет тому, кто раньше захватил объект, успешно завершить модификацию объекта. Примером необходимости использования этой блокировки является режим совместного редактирования таблицы несколькими пользователями. 4. Предохраняющая полная блокировка. Предохраняет объект от наложения на него со стороны других операций полной блокировки. Обеспечивает максимальный уровень совместного использования объектов. Такая блокировка может использоваться, например, для обеспечения одновременного просмотра несколькими пользователями одной таблицы. В группе пользователей, работающих с одной таблицей, эта блокировка не позволит никому изменить структуру общей таблицы. В отношении перечисленных выше блокировок действуют следующие правила совмещения: · при наличии полной блокировки над объектом нельзя производить операции, приводящие хотя бы к одному из видов блокировок (полная блокировка несовместима ни с какой другой блокировкой); · блокировка от записи совместима с аналогичной блокировкой и предохраняющей полной блокировкой; · предохраняющая блокировка от записи совместима с обоими видами предохраняющей блокировок;
|
|||||||||
|
|
Последнее изменение этой страницы: 2017-01-19; просмотров: 1707; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.191.216.163 (0.138 с.) |