
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Мнк в случае линейной модели
Пусть регрессионная зависимость является линейной:
Пусть y — вектор-столбец наблюдений объясняемой переменной, а
Тогда вектор оценок объясняемой переменной и вектор остатков регрессии будут равны
соответственно сумма квадратов остатков регрессии будет равна
Дифференцируя эту функцию по вектору параметров и приравняв производные к нулю, получим систему уравнений (в матричной форме):
Решение этой системы уравнений и дает общую формулу МНК-оценок для линейной модели:
Для аналитических целей оказывается полезным последнее представление этой формулы. Если в регрессионной модели данные центрированы, то в этом представлении первая матрица имеет смысл выборочной ковариационной матрицы факторов, а вторая — вектор ковариаций факторов с зависимой переменной. Если кроме того данные ещё и нормированы на СКО (то есть в конечном итоге стандартизированы), то первая матрица имеет смысл выборочной корреляционной матрицы факторов, второй вектор — вектора выборочных корреляций факторов с зависимой переменной. Немаловажное свойство МНК-оценок для моделей с константой — линия построенной регрессии проходит через центр тяжести выборочных данных, то есть выполняется равенство:
В частности, в крайнем случае, когда единственным регрессором является константа, получаем, что МНК-оценка единственного параметра (собственно константы) равна среднему значению объясняемой переменной. То есть среднее арифметическое, известное своими хорошими свойствами из законов больших чисел, также является МНК-оценкой — удовлетворяет критерию минимума суммы квадратов отклонений от неё. Пример: простейшая (парная) регрессия В случае парной линейной регрессии
Свойства МНК-оценок В первую очередь, отметим, что для линейных моделей МНК-оценки являются линейными оценками, как это следует из вышеприведённой формулы. Для несмещенности МНК-оценок необходимо и достаточно выполнения важнейшего условия регрессионного анализа: условное по факторам математическое ожидание случайной ошибки должно быть равно нулю. Данное условие, в частности, выполнено, если
Первое условие можно считать выполненным всегда для моделей с константой, так как константа берёт на себя ненулевое математическое ожидание ошибок (поэтому модели с константой в общем случае предпочтительнее). Второе условие — условие экзогенности факторов — принципиальное. Если это свойство не выполнено, то можно считать, что практически любые оценки будут крайне неудовлетворительными: они не будут даже состоятельными (то есть даже очень большой объём данных не позволяет получить качественные оценки в этом случае). В классическом случае делается более сильное предположение о детерминированности факторов, в отличие от случайной ошибки, что автоматически означает выполнение условия экзогенности. В общем случае для состоятельности оценок достаточно выполнения условия экзогенности вместе со сходимостью матрицы Для того, чтобы кроме состоятельности и несмещенности, оценки (обычного) МНК были ещё и эффективными (наилучшими в классе линейных несмещенных оценок) необходимо выполнение дополнительных свойств случайной ошибки:
Данные предположения можно сформулировать для ковариационной матрицы вектора случайных ошибок Линейная модель, удовлетворяющая таким условиям, называется классической. МНК-оценки для классической линейной регрессии являются несмещёнными, состоятельными и наиболее эффективными оценками в классе всех линейных несмещённых оценок (в англоязычной литературе иногда употребляют аббревиатуру BLUE (Best Linear Unbaised Estimator) — наилучшая линейная несмещённая оценка; в отечественной литературе чаще приводится теорема Гаусса — Маркова). Как нетрудно показать, ковариационная матрица вектора оценок коэффициентов будет равна:
Эффективность означает, что эта ковариационная матрица является «минимальной» (любая линейная комбинация коэффициентов, и в частности сами коэффициенты, имеют минимальную дисперсию), то есть в классе линейных несмещенных оценок оценки МНК-наилучшие. Диагональные элементы этой матрицы — дисперсии оценок коэффициентов — важные параметры качества полученных оценок. Однако рассчитать ковариационную матрицу невозможно, поскольку дисперсия случайных ошибок неизвестна. Можно доказать, что несмещённой и состоятельной (для классической линейной модели) оценкой дисперсии случайных ошибок является величина:
Подставив данное значение в формулу для ковариационной матрицы и получим оценку ковариационной матрицы. Полученные оценки также являются несмещёнными и состоятельными. Важно также то, что оценка дисперсии ошибок (а значит и дисперсий коэффициентов) и оценки параметров модели являются независимыми случайными величинами, что позволяет получить тестовые статистики для проверки гипотез о коэффициентах модели. Необходимо отметить, что если классические предположения не выполнены, МНК-оценки параметров не являются наиболее эффективными оценками (оставаясь несмещёнными и состоятельными). Однако, ещё более ухудшается оценка ковариационной матрицы — она становится смещённой и несостоятельной. Это означает, что статистические выводы о качестве построенной модели в таком случае могут быть крайне недостоверными. Одним из вариантов решения последней проблемы является применение специальных оценок ковариационной матрицы, которые являются состоятельными при нарушениях классических предположений (стандартные ошибки в форме Уайта и стандартные ошибки в форме Ньюи-Уеста). Другой подход заключается в применении так называемого обобщённого МНК. Обобщенный МНК Основная статья: Обобщенный метод наименьших квадратов Метод наименьших квадратов допускает широкое обобщение. Вместо минимизации суммы квадратов остатков можно минимизировать некоторую положительно определенную квадратичную форму от вектора остатков Доказано (теорема Айткена), что для обобщенной линейной регрессионной модели (в которой на ковариационную матрицу случайных ошибок не налагается никаких ограничений) наиболее эффективными (в классе линейных несмещенных оценок) являются оценки т. н. обобщенного МНК (ОМНК, GLS — Generalized Least Squares) — LS-метода с весовой матрицей, равной обратной ковариационной матрице случайных ошибок:
Можно показать, что формула ОМНК-оценок параметров линейной модели имеет вид
Ковариационная матрица этих оценок соответственно будет равна
Фактически сущность ОМНК заключается в определенном (линейном) преобразовании (P) исходных данных и применении обычного МНК к преобразованным данным. Цель этого преобразования — для преобразованных данных случайные ошибки уже удовлетворяют классическим предположениям. Взвешенный МНК В случае диагональной весовой матрицы (а значит и ковариационной матрицы случайных ошибок) имеем так называемый взвешенный МНК (WLS — Weighted Least Squares). В данном случае минимизируется взвешенная сумма квадратов остатков модели, то есть каждое наблюдение получает «вес», обратно пропорциональный дисперсии случайной ошибки в данном наблюдении:
|
|||||||
|
|
Последнее изменение этой страницы: 2017-01-19; просмотров: 191; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.218.234.83 (0.008 с.) |

 — матрица наблюдений факторов (строки матрицы — векторы значений факторов в данном наблюдении, по столбцам — вектор значений данного фактора во всех наблюдениях). Матричное представление линейной модели имеет вид:
— матрица наблюдений факторов (строки матрицы — векторы значений факторов в данном наблюдении, по столбцам — вектор значений данного фактора во всех наблюдениях). Матричное представление линейной модели имеет вид:


 .
.

 формулы расчета упрощаются (можно обойтись без матричной алгебры):
формулы расчета упрощаются (можно обойтись без матричной алгебры):
 к некоторой невырожденной матрице при увеличении объёма выборки до бесконечности.
к некоторой невырожденной матрице при увеличении объёма выборки до бесконечности.



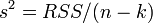
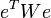 , где
, где  — некоторая симметрическая положительно определенная весовая матрица. Обычный МНК является частным случаем данного подхода, когда весовая матрица пропорциональна единичной матрице. Как известно из теории симметрических матриц (или операторов) для таких матриц существует разложение
— некоторая симметрическая положительно определенная весовая матрица. Обычный МНК является частным случаем данного подхода, когда весовая матрица пропорциональна единичной матрице. Как известно из теории симметрических матриц (или операторов) для таких матриц существует разложение  . Следовательно, указанный функционал можно представить следующим образом
. Следовательно, указанный функционал можно представить следующим образом  , то есть этот функционал можно представить как сумму квадратов некоторых преобразованных «остатков». Таким образом, можно выделить класс методов наименьших квадратов — LS-методы (Least Squares).
, то есть этот функционал можно представить как сумму квадратов некоторых преобразованных «остатков». Таким образом, можно выделить класс методов наименьших квадратов — LS-методы (Least Squares). .
.

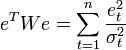 . Фактически данные преобразуются взвешиванием наблюдений (делением на величину, пропорциональную предполагаемому стандартному отклонению случайных ошибок), а к взвешенным данным применяется обычный МНК.
. Фактически данные преобразуются взвешиванием наблюдений (делением на величину, пропорциональную предполагаемому стандартному отклонению случайных ошибок), а к взвешенным данным применяется обычный МНК.


