Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Организация и оптимизация доступа к данным⇐ ПредыдущаяСтр 23 из 23
Вследствие объективно существующей разницы в скорости работы процессоров и оперативной памяти с одной стороны, и устройств внешней памяти, с другой — буферизация страниц базы данных в оперативной памяти — единственно реальный способ достижения удовлетворительной эффективности СУБД. Кроме этого используется механизм распределенного хранения информации — расщепления данных между файлами и файловыми группами, физически размещаемыми на разных устройствах или RAID-массивах. Логически такое устройство представляется как единое целое, но на самом деле состоит из нескольких физических дисков. Данные на дисках размещаются блоками одной длины и, таким образом, легко могут быть распределены по всем дискам. Стратегия буферизации, применяемая в операционных средах, не соответствует целям и задачам СУБД,поэтому для оптимизации обработки данных одной из главных задач СУБДявляется создание эффективной системы управления процессом буферизации. Память, управляемая СУБД,состоит из нескольких типов буферов: • буфера страниц данных, с которыми работает СУБД; • буфера страниц журнала транзакций, которые отражают процесс выполнения транзакции — последовательности операций над БД, переводящей БД из одного непротиворечивого состояния в другое непротиворечивое состояние; • системные буферы, которые содержат общую информацию о БД,о пользователях, о физической структуре БД, о базе метаданных. Еслибы запись об изменении базы данных реально немедленно записывалась во внешнюю память, это привело бы к существенному замедлению работы системы. Поэтому записи в журнал тоже буферизуются: при нормальной работе очередная страница выталкивается во внешнюю память журнала только при полном наполнении записями. Нопоскольку имеются два вида буферов, содержащих взаимосвязанную информацию, — буфер журнала и буфер страниц оперативной памяти, которые могут выталкиваться во внешнюю память, буферы выделяются не для каждого пользовательского процесса, а для всех процессов сервера. Это позволяет увеличить степень параллелизма при исполнении клиентских процессов. 59. Документальная информационно-поисковая система? Организация данных и механизмы поиска в базах данных документальных информационных систем построены на тех же принципах, что и фактографические системы. Однако в физической реализации есть и существенные отличия, которые обусловлены в первую очередь информационной природой элементов данных:
1. Запись базы данных — документ, который задается как набор в общем случае необязательных полей, для каждого из которых определены имя и тип. Допустимы большинство стандартных типов, а также текстовые. Текстовые поля имеют переменную длину и композиционную структуру, не имеющую прямых аналогов среди стандартных типов языков программирования: текстовое поле состоит из параграфов; параграф — из предложений; предложение — из слов. При этом идентифицируемым элементом данных с точки зрения хранения будет поле, а с точки зрения поиска— слово. Вследствие этого поисковые структуры строятся в виде инвертированных файлов. 2. Семантическая природа текстовых полей, представляющих смысл в основном на естественном языке, определяет необходимость учитывать важнейшие свойства используемых терминов: синонимию, полисемию, омонимию, контекстную обусловленность смысла отдельного слова и возможность выразить один смысл многими способами. Вследствие этого поисковые индексы могут быть отличны от соответствующих словоформ поля. На рис. п.1 приведена принципиальная схема организации данных для представления и поиска информации диалоговой системы поиска документов STAIRS, разработанной фирмой IBM в 70-х гг. Данная структура характерна и для большинства современных ГИПС.
Физическая структура БД рассматриваемой системы включает в себя четыре файла операционной системы: • файл частотного словаря, устанавливающий соответствие между словом, встречающимся в БД, его кодом и частотой, используется при текстовом поиске; • инверсный список, содержащий для каждого слова БД список документов, его содержащих, используется при текстовом поиске; • текстовый файл, содержащий собственно документы, используется при выдаче документов; • прямой, последовательный файл, содержащий «собранные» в одну строку фиксированной длины форматные поля и список двухбайтовых кодов слов, находящихся в тексте данного документа. При необходимости в соответствующих местах находятся разделители сегментов и/или предложений. Файл используется при форматном поиске и при наличии в запросах конструкций SENT, SEGN, СТХ
На рис. п.2 детально представлен словарь слов, в котором содержится перечень слов, встречающихся в документах. Ввиду значительных размеров словаря его организация должна предусматривать наличие специального индекса, представленного матрицей пар знаков. Каждой паре знаков поставлен в соответствие указатель на блок словаря, содержащий группу слов, начинающихся с этих знаков. Знаками могут быть буквы, цифры, а также специальные символы. Второй знак может быть пробелом. Группы слов в словаре имеют переменную длину. Первые два знака слов, содержащихся в словаре, отсутствуют, но они показаны на рисунке, чтобы облегчить понимание структуры файла. Некоторые слова в словаре могут иметь одинаковый смысл; такие слова связаны с помощью специального указателя «синоним». Каждому слову поставлен в соответствие указатель на списки экземпляров, являющихся перечнем документов, в которых встречается данное слово. Каждый список экземпляров содержит заголовок, из которого можно узнать число экземпляров слова во всем файле документов, а также число документов, в которых это слово встречается. Система присваивает каждому документу уникальный номер. Этот номер является внутрисистемным и не связан с номерами, по которым пользователь может получить данный документ где-нибудь вне системы, В списке экземпляров, соответствующем какому-либо слову, содержатся внутрисистемные номера всех документов, в которых оно встречается. Поисковый критерий может включать
требование поиска всех документов, содержащих одновременно два специфических слова. Например, можно осуществлять поиск документа, в котором содержится как слово ORANGUTANG, так и слово OSTRICH. В этом случае система находит множество документов, содержащих первое слово, а затем множество документов, содержащих второе слово, и путем их пересечения определяет множество документов, содержащих как первое, так и второе слово. На рис. п.3 показан файл документов, каждому из которых система сама. присваивает внутренний порядковый номер. Документы состоят из параграфов и текстов, причем тексты также пронумерованы. Каждому параграфу присвоен специальный код, определяющий его тип
Внутрисистемный номер документа является ключом к индексу документов. Этот индекс содержит адреса соответствующих документов в памяти. В принципе можно хранить эти адресные указатели непосредственно в списке экземпляров, но это нецелесообразно, так как объем памяти, необходимый для хранения адреса, больше объема памяти, необходимого для хранения номера документа. Индекс документов содержит не только адреса, но также некоторые вспомогательные сведения о документах. К этим сведениям относятся внешний номер документа, признак удаления документа, указывающий, какие параграфы документа исключены из файла, а также уровень секретности. В состав документов могут входить параграфы различных типов, поэтому пользователь может потребовать, чтобы заданное слово содержалось в названии документа, аннотации, введении или каком либо конкретном параграфе. В критерии отбора можно указывать автора, место издания документа и дату издания. Независимо от содержания критерия отбора поиск документа осуществляется на уровне списка экземпляров без необходимости входа в файл документов.
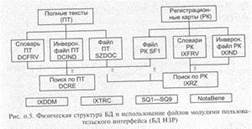
60.Интегральный блок юридической информации ЮРИКУС? С логической точки зрения банк имеет «стандартную» структуру и включает две компоненты: регистрационные карты и полные тексты. РК представляют собой форматированные записи, содержащие относительно стандартный набор библиографических данных, а также ссылку на соответствующий полный текст.
Полные тексты документов состоят из страниц двух типов: • логических, т. е. структурных единиц текста — пункт, параграф, статья; • физических — принудительное разбиение длинного неструктурированного текста на фрагменты одинаковой длины. Кроме этого имеется возможность отнесения документа к тому или иному тому Свода законов. Это связано с традицией выпуска Свода законов в форме десятитомного печатного издания. Физическая структура БД ЮРИУС является примером реализации документальной системы в среде реляционной СУБД.
Файл текстовой части БД — один или несколько файлов, в которых содержатся полные тексты актов. На логическом уровне образует представленную на рис. иерархическую структуру: БД документ, страница. Словарный файл текстовой части — представляет собой список слов и стандартных словосочетаний, извлеченных из текста, сопровождаемых частотами появления в данной БД. Практика выделения словосочетаний при индексировании с целью включения их в словарь и инверсный список является достаточно известной. Инверсный файл текстовой части — список кодов слов и словосочетаний, сопровождаемых номерами страниц. Словарный и инверсный файлы используются для сквозного полнотекстового поиска. Справочно-поисковые файлы Стандартным является файл регистрационных карт нормативных актов, запись которого содержит наименование, дату, номер, вид, ссылки на страницы БД и другие поля, перечень которых может изменяться для конкретной БД. Словарь справочно-поисковых файлов содержит значения и коды полей совместно с частотой появления и ссылкой на номер файла СПФ. Инверсный файл СПФ содержит коды слов и словосочетаний. Словарный и инверсный файлы используются для поиска записей СПФ с доступом к странице БД.
Файл синонимов служит для расшифровки кодов или для обеспечения двуязычного поиска в словарных файлах. Файл описания СПФ — содержит данные ополных, сокращенных и внутренних именах полей каждого СПФ, типах данных, разделителях слов, методах обработки числовых кодов и т. д. Используется при поиске через СПФ и при построении словарных и инверсных файлов. Файлы хранимых запросов содержат запросы к СПФ БД, отлаженные и сохраненные пользователем. Файл заметок позволяет пользователю дополнить СПФ собственными именованными прямыми ссылками на страницы БД. 61. Технология индексирования текстовой информации? В рассмотренной выше документальной ГИПС STAIRS используется стратегия свободного индексирования. Каждое слово загружаемого в базу данных документа может использоваться в качестве индекса — ключа поиска этого документа. Индексирование по ключевым словам является наиболее простой и экономичной в отношении дискового пространства технологией. Суть ее заключается в том, что для каждого вводимого или сохраняемого документа заполняются соответствующие поля в индексном файле. Заполнение осуществляется как вручную, так и с помощью программы, выделяющей в документе по какому-либо признаку значения ключей/атрибутов. Эта технология позволяет индексировать как текстовые документы, так и изображения. В простейшем случае ключевыми словами служат название и/или имя автора документа. В более сложных ситуациях необходимо использовать независимого эксперта для чтения документа и выделения ключевых слов. Серьезные ограничения при использовании этих систем связаны со следующими обстоятельствами: • определение ключевых слов — достаточно субъективный процесс; даже при участии самого независимого эксперта трудно избежать односторонности при выборе ключевых слов; • определение ключевых слов — достаточно дорогостоящая процедура из-за невозможности автоматической индексации и низкой производительности при определении ключевых слов вручную; • предполагается, что пользователи будут осуществлять поиск информации предсказуемым способом, используя предопределенные ключевые слова; • поиск по ключевым словам — это четкий поиск, когда пользователь должен точно знать, что он ищет. Если сделана ошибка при написании ключевого слова в запросе для поиска, система; никогда не найдет нужную информацию; • ключевые слова могут со временем меняться. Поиск информации в таких системах происходит с использованием механизмов полнотекстового поиска, который реализуется с помощью технологии индексирования на основе инвертированных структур: при создании индексного файла в него вносятся все значимые слова из всех документов в алфавитном порядке. Эти слова затем объединяются в пары с указателями на документы, содержащие эти слова. Цель индексирования документов — возможность их быстрого поиска. Индекс — это набор слов документа или о документе, по которым этот поиск производится. Основными критериями качества индексирующее поисковых подсистем являются качество поиска, размер индекса по отношению к размеру документа и скорость поиска по нему.
Развитие индексирования в документальных системах происходило от ручного заполнения списка ключевых слов в системах первого поколения до автоматического полнотекстового индексирования сегодня, подразумевающего сохранение всех слов текста. Несмотря на большой пройденный путь говорить о полном решении проблемы, наверное, пока рано. Индексирование документа обычно организуется через автоматическую обработку его текста и заполнение метаданных. Автоматическая обработка — полнотекстовое индексирование — заключается в преобразовании текста документа в набор слов. Причем обычно для слов сохраняется их позиция в документе, что обеспечивает возможность поиска по словосочетаниям. Существуют два принципиально различных метода такого индексирования с учетом применяемых в дальнейшем методов поиска: • бинарное индексирование — не зависит от языка документа по причине бинарной или словарной индексации; • морфологическое индексирование — производится с учетом морфологии и семантики языка. При бинарном индексировании поиск ведется на основе алгоритмов «нечеткого поиска», т. е. поиска с ошибками. В этом случае допускается неполное совпадение слов с шаблоном. При втором методе индексации слова преобразуются в словоформы с отсечением суффиксов и окончаний, что позволяет искать склонения и спряжения шаблонов. Заметим, что несмотря на несомненные плюсы, полнотекстовое индексирование в любом своем виде имеет и существенный минус: большое количество «мусора» в индексе, т. е. слов, никак не характеризующих документ, а связывающих «ключевые» слова. Эти недостатки обусловлены самой концепцией такого индексирования — сохранением всего текста за исключением «стоп слов», под которыми подразумеваются предлоги, союзы, местоимения и т. п. Действительно, с одной стороны наличие в индексе всех слов текста гарантирует его нахождение по любому из них, но с другой стороны встает вопрос: «А насколько это корректно?». Предположим, мы имеем текст о компьютерных технологиях, в котором приведена пословица: «За двумя зайцами погонишься, ни одного не поймаешь». При проведении поиска по слову «заяц» система выдаст этот документ, хотя он не будет иметь ни малейшего отношения к фауне. Безусловно, можно найти и сотни менее экзотичных примеров. Среди других «узких мест» можно назвать следующие. 1. Индекс, создаваемый такими системами, обычно составляет от 200 до 400 % от объема исходного текста, что означает увеличение времени поиска и ресурсов компьютера. 2. Из-за необходимости «очистки» текста стоимость обработки документов достаточно велика. 3. Механизм четкого поиска через инвертированный файл не позволит найти информацию, если были допущены ошибки при загрузке текста или при написании запроса. В начале 90-х гг. появились технологические разработки, связанные с индексацией и поиском документов и использующие результаты, полученные в области нейронных сетей и искусственного интеллекта. Они позволили сформулировать принципиально новые концепции построения систем управления неструктурированной информацией в электронном виде. Компания Excalibur Technologies разработала и представила на рынке технологию адаптивного распознавания образов APRP, которая была положена в основу программного продукта — систему управления документами Excalibur EFS [81. Технология APRP основана на нейронных сетях, что позволяет не только обойти проблемы ошибок распознавания текстов, но и предоставляет возможности автоматического индексирования и поиска различных типов неструктурированной информации. Ядро технологии APRP «выросло» из работ основателя компании Excalibur Technologies Джеймса Дау 111, посвященных изучению и разработке моделей нейронных сетей, способных идентифицировать, или, более точно, распознавать присутствие тех или иных образов в составе данных специального вида. Это позволило построить систему индексации общего назначения, которую можно применять к основным видам данных, включая устную речь (голос), сигналы, тексты и изображения. Был также создан комплекс алгоритмов, самостоятельно адаптирующихся к особенностям обрабатываемой информации и позволяющих осуществлять нечеткий поиск — поиск образов, составленных из двоичных символов. В технологии APRP под нечетким поиском понимается возможность найти достаточно близкое соответствие к запрошенному термину или фразе. Нечеткий поиск устраняет для пользователя необходимость знать правильное написание каждого термина, с которым он работает. Поскольку APRP работает не с ключевыми словами, а с образами, две-три ошибочные буквы в слове или фразе не могут существенно изменить базовую картину текста. Таким образом, автоматически становится исправимой ошибка как во входных данных, так и в терминах запроса. APRP всегда в состоянии найти ближайшее приближение к терминам и фразам, заданным в качестве объектов поиска. Поясним это на примере. Даже если мы напишем в запросе: ЦЦЦТЕРМАРГИАСАРИТАЭЭЭЭЭЭ, имея в виду название романа Михаила Булгакова, мы получим правильный ответ: «Мастер и Маргарита». Поиск происходит следующим образом: • запрос конвертируется в бинарную форму; • игнорируется шум, т. е. отбрасываются ЦЦЦ и ЭЭЭЭЭЭ; • проводится нечеткий поиск. Как реально происходит нечеткий поиск? Ранее упоминалось, что технология APRP оперирует информацией на уровне двоичных кодов, т. е. каждое слово для нее — это образ, состоящий из нулей и единиц. Например, слово «пень» для нее представляется двоичным образом 10101111 10100101 10101101 11101100; а слово «печь» имеет двоичный образ 10101111 10100101 11100111 11101100. Сравним двоичные образы обоих слов ПЕН – 10101111 10100101 10101101 11101100 ПЕЧЬ – 10101111 10100101 11100111 11101100 Из 32 позиций каждого двоичного образа не совпадают только комбинации из шести элементов, что составляет лишь около 20 % от длины двоичного образа. С точки зрения технологии APRP образы этих слов очень близки друг другу, и в качестве результата поиска вам могут быть предложены документы, содержащие оба слова, а вы укажете, которые из них вы имели в виду при поиске. Приведенный пример, однако, не означает, что вам будет предложен бесконечный список вариантов, в той или иной степени похожих на ваш запрос.
|
|||||||||
|
|
Последнее изменение этой страницы: 2016-12-16; просмотров: 185; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.221.13.173 (0.065 с.) |