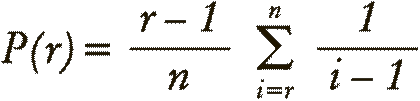Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Формула, которая нас объединяетСодержание книги
Поиск на нашем сайте
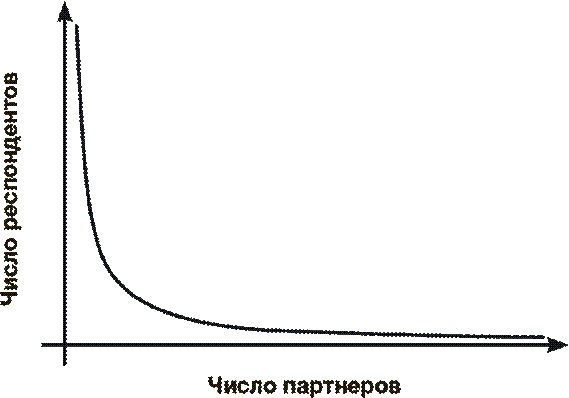
В 1999 году руководитель исследования Фредрик Лильерос и его коллеги-математики из Стокгольмского университета представили полученную ими статистику в виде графика и обнаружили поразительно простую зависимость. Почти все 2810 ответов расположились на практически идеальной кривой, как показано на рисунке ниже, продемонстрировав тем самым очевидную закономерность в распределении участников по количеству партнеров. У подавляющего большинства опрошенных число сексуальных партнеров совсем невелико – вот почему левая часть кривой поднимается высоко вверх. Но среди респондентов было также некоторое количество людей, которые назвали необычно высокое число “побед”, поэтому правая часть кривой плавно приближается к нулевым значениям, но никогда их не достигает. Если шведский опрос репрезентативно представляет население в целом, то такой вид кривой говорит о том, что всегда есть шанс найти кого-то, у кого было сколь угодно большое число сексуальных партнеров. Понятно, что в мире не так уж много людей, у которых было, скажем, десять тысяч или даже “всего” тысяча партнеров, однако график предсказывает, что хотя бы один такой всегда может найтись. Все это легко сворачивается в одну-единственную формулу, которая позволит предсказать, с каким количеством партнеров переспал каждый из нас. Для произвольно выбранного жителя Земли вероятность иметь больше, чем x партнеров, составляет x –α.
Параметр α рассчитывается по данным опросов. Например, исследователи определили, что для шведской женщины величина α составляет 2,1. Если это значение экстраполировать на весь мир, то вероятность того, что у кого-то было более сотни партнеров, составит 0,006 % – иными словами, это будет всего один человек из 15 800. Вероятность резко уменьшается с увеличением числа предполагаемых партнеров, тем не менее шанс найти кого-то, у кого было более тысячи партнеров, составляет 0,00005 %, то есть это один из двух миллионов человек. Прежде чем меня окончательно захлестнет волна восторга перед элегантностью математики, стоит остановиться на секунду, чтобы осознать всю важность этих открытий. Пусть мы обладаем свободной волей, пусть наши сексуальные контакты обусловлены довольно сложной совокупностью объективных обстоятельств – и все же, если говорить обо всем человечестве в целом, оказывается, что все наши действия описываются поразительно простой формулой. Эта формула говорит, что число наших сексуальных партнеров – не совсем случайная величина. Кроме того, эта величина не подчиняется закону нормального распределения – колоколообразной кривой, которая обычно описывает распределение любых средних параметров человека: роста, IQ и так далее. Совсем наоборот: из формулы следует, что число наших сексуальных партнеров описывается так называемой “степенной зависимостью”. Когда речь идет о росте, почти все мы попадаем в относительно узкий интервал от 150 до 190 см. Конечно, бывают некоторые резкие отклонения, но в целом разница между низкими и высокими людьми не так уж велика. В то же время степенная зависимость охватывает гораздо больший интервал. Если бы число сексуальных партнеров подчинялось тому же самому закону, что и распределение по росту, то вероятность существования героя-любовника, у которого было свыше тысячи партнеров, была бы равна вероятности встретить человека ростом с Эйфелеву башню. Отчасти вдохновленные этим исследованием, ученые в последние десять лет начали искать – и находить – зависимости, описываемые степенным законом, в самых разных необычных областях. Так, например, картина, аналогичная распределению сексуальных контактов, обнаруживается также в системе перекрестных ссылок между сайтами в интернете, в том, как построены социальные сети в Twitter и Facebook, в том, как расположены слова в предложениях и даже в том, насколько часто и в каких количествах используются в рецептах различные ингредиенты. Все эти разнообразные явления описываются простой формулой x −α. Причина этого станет понятнее, если мы вернемся к рассмотрению связей в сети. Количество этих связей и отражается в распределении. Степенное распределение создается связями в сети строго определенной формы, известной в математике как безмасштабная сеть[8]. Пример того, как выглядит безмасштабная сеть, представлен на рисунке:
У большинства людей приблизительно одинаковое число связей, однако есть некоторые – темный кружок в середине – у которых связей гораздо больше. Таких людей можно считать “хабами” (узлами) сети, и именно “хабы” делают это распределение похожим на ряд других степенных распределений, на первый взгляд не имеющих ничего общего. Певица Кэти Перри, у которой 57 миллионов фолловеров (по состоянию на сентябрь 2014 года), – крупнейший “хаб” сети Twitter, “Википедия” – крупнейший узел Всемирной паутины, а обычный лук – узел сети рецептов и кулинарных ингредиентов. Во всех этих случаях узлы развиваются согласно правилу “деньги к деньгам”. Чем больше фолловеров у Кэти Перри, тем больше шансов, что новые поклонники пополнят их ряды. Аналогично обстоит дело и с сетью сексуальных контактов: чем больше побед одерживают “люди-хабы”, тем выше вероятность, что они сумеют затащить в постель еще большее количество партнеров. Именно “хабы” являются причиной того, что заболевания, передающиеся половым путем, распространяются так быстро и их так трудно контролировать. Если “узел” не принимает соответствующих мер предосторожности, то он сам становится первым кандидатом на заражение, а также, скорее всего, передаст инфекцию дальше по сети. Если вы представите себе, как вирус распространяется по безмасштабной сети, то поймете, какую драматическую роль могут играть “узлы”.
Под колпаком
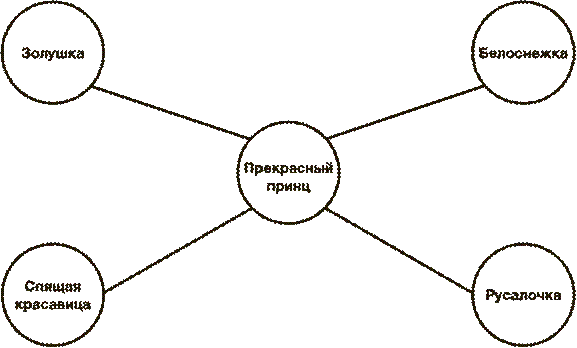
“Люди-хабы”, подвергающие риску и себя, и своих партнеров, – главные разносчики половых инфекций, однако существует математический прием, позволяющий использовать их самих и структуру сети, чтобы попытаться остановить распространение болезни. Идея станет понятна, если мы представим себе упрощенную сеть:
Допустим, у нас есть четыре юные принцессы: Золушка, Белоснежка, Русалочка и Спящая красавица. Все они предаются любви с одним и тем же весьма сексуальным Прекрасным принцем и соответственно образуют сеть сексуальных контактов. При этом между дамами никаких сексуальных контактов нет (мы не будем учитывать то, что пишут на некоторых весьма смелых диснеевских фансайтах, и я настоятельно советую вам не посещать такие места, если вы хотите сохранить в чистоте свои невинные детские воспоминания). Теперь представим, что среди членов группы завелась какая-то неприятная инфекция. Если вакцинация или просвещение каждого члена группы обойдется слишком дорого, мы можем сосредоточиться только на “узле”, как ключевом элементе сети. Однако, не видя скрытых связей внутри сети, мы сможем понять, что этот человек – Прекрасный принц, только когда опросим всех участников, сколько у каждого из них сексуальных партнеров. Таким образом, задача состоит в том, чтобы, не зная всех участников сети, с наибольшей вероятностью выявить скрытый “узел”. Если мы выберем кого-то наугад, то шансы, что мы сразу угадаем “хаб”, составляют один к пяти. Но представьте, что вместо этого мы выберем первого попавшегося участника, скажем, Русалочку, и попросим ее помочь нам сделать прививку своему партнеру. Русалочка приведет нас к Прекрасному принцу. Точно так же, если мы случайным образом выберем Золушку и обратимся с той же просьбой, она тоже выведет нас на Принца. Так же поступят Спящая красавица и Белоснежка. Иными словами, добавив к нашему алгоритму один простой шаг, мы увеличим наши шансы обнаружить “узел” сразу в четыре раза: до четырех шансов из пяти. Гораздо лучше, не так ли? То же самое относится и к гораздо более обширным сетям. Представьте, что, мы, не имея доступа к статистике Twitter, попытаемся отыскать Кэти Перри – самый большой “хаб” этой социальной сети (на момент написания данной главы). Если мы возьмем наугад одного из 500 миллионов пользователей Twitter, то наш шанс найти Кэти составит один на 500 миллионов. Если мы столь же случайным образом выберем пользователя и попросим его назвать нам самого популярного человека, на которого он подписан, то таких может набраться уже 57 миллионов. Внезапно наши шансы найти Кэти подскакивают до 10 % и выше, что очень впечатляет, особенно учитывая, насколько прост алгоритм. Подобная методика используется для прогнозирования и остановки эпидемий, избавляя медиков от необходимости проводить сложное и дорогое выявление всей сети заболевших. А кроме того, такие расчеты, как мне кажется, рассказывают нам что-то очень важное о том, как просто устроена обширная сеть, которая соединяет всех нас. Так что в следующий раз, занося новый трофей в свой донжуанский список, подумайте об огромной разветвленной сети, частью которой вы становитесь. Математики не в состоянии помочь вам повысить качество секса, но мы пытаемся – и нам это удается – сократить число инфекционных заболеваний, которые вы можете подхватить. И разве это само по себе уже не секси?
Не пора ли остепениться?
Когда речь идет о любви, долгосрочные решения – рискованное дело. Рано или поздно все мы решаем, наконец, сказать “прощай” беззаботной холостяцкой жизни и остепениться. Грехи юности, если таковые были, пора оставить в прошлом, пришло время для партнерства на всю жизнь. Но как понять, что мы действительно нашли свою вторую половинку? Любой человек с математическим складом ума скажет вам, что это сложный и тонкий выбор: то ли терпеливо ждать подходящего человека, то ли поторопиться, чтобы не упустить свой шанс, пока не расхватали всех подходящих кандидатов. Спросите у любого, кто попал в ловушку “парадокса доступных холостяков”. Если же вы решите никогда не заводить семью, то может случиться так, что в конце жизни вам останется лишь сидеть в одиночестве и перебирать по пальцам тех, с кем вы когда-то встречались, прикидывая, каким прекрасным спутником жизни мог бы стать тот или иной из них. По всей видимости, к тому моменту все это копание в прошлом будет уже совершенно бесплодным, но если бы вы занялись подобными размышлениями раньше, то значительно облегчили бы себе выбор спутника жизни. Подходящие именно для вас “половинки” существуют, и они ждут, чтобы вы их нашли. То есть имеется некий список, пусть и воображаемый. Но остается большой вопрос: как выбрать из этого воображаемого списка лучшего кандидата для долгой совместной жизни, если вы не знаете, что вас ждет впереди? Давайте на минуту предположим, что правила игры очень просты: после того, как вы сделали выбор, вы уже не можете заглянуть вперед и увидеть там новых возможных кандидатов. И наоборот: если вы кого-то отвергли, вы уже не можете спустя некоторое время передумать и вернуться к этому кандидату. Во всяком случае, мой опыт говорит, что люди весьма негативно реагируют, когда через несколько лет им вдруг звонит человек, который их когда-то отверг, и звонит только потому, что за это время не нашел никого получше. Если поставить себе такие ограничения, то область математики, которая называется “теория оптимальной остановки случайного процесса”, может предложить наилучшую стратегию поиска того самого “кандидата номер один”, несравненного Прекрасного принца (или Принцессы). Ход рассуждений тут самый простой и логичный: пока вы молоды, играйте в свое удовольствие, не рассматривая никого в качестве спутника жизни, пока окончательно не освоитесь на этой “игровой площадке”. Когда этот этап (назовем его “фазой отвержения”) будет пройден, выбирайте первого, кто ответит на ваши чувства и кто при этом будет лучше, чем любой из ваших предыдущих партнеров. Однако теория оптимальной остановки идет дальше. Оказывается, что вероятность того, что вы остановитесь, остепенитесь и останетесь с лучшим из возможных партнером (эта вероятность обозначена в уравнении буквой P), зависит от числа ваших потенциальных спутников жизни (n) и от того, скольким из них вы уже отказали (r), и эта зависимость описывается довольно элегантной формулой:
Эта формула, на вид вполне невинная, в состоянии объяснить, сколько претендентов вы должны отвергнуть, прежде чем ваши шансы обрести идеального партнера станут максимальными. Например, если вам на роду написаны десять партнеров за всю жизнь, то наибольшая вероятность найти вашего Единственного и Неповторимого возникает после того, как вы отвергли первых четырех поклонников (и эта вероятность составляет 39,87 %). Если вам суждено встретиться с двадцатью потенциальными спутниками, вы должны отказать первым восьми (и в 38,42 % случаев следующим будет мистер или мисс Совершенство). И, наконец, если ваша судьба – бесконечное число партнеров, вы должны отклонить первые 37 % – и тогда ваши шансы на успех будут чуть больше, чем один к трем[9]. Я математик, и поэтому, конечно, человек предвзятый, но, признаюсь, от этого результата у меня буквально срывает крышу. Если вы отвергнете эту стратегию и решите просто остановиться на случайно выбранном партнере из своего списка, то шанс, что это окажется ваша истинная любовь, составляет 1/n, то есть 5 % (в случае, если вам за всю жизнь предназначено вступить в отношения с двадцатью партнерами). Однако, просто отвергнув 37 % из своих двадцати партнеров, вы можете коренным образом изменить судьбу, увеличив свои шансы до впечатляющих 38,42 %! Хорошо-хорошо, пока меня окончательно не занесло: конечно, вы могли заметить, что если попытаться приложить этот план к настоящим человеческим отношениям, в нем обнаружатся определенные изъяны. Если вы не член английской королевской семьи XVI века, то ваши потенциальные женихи или невесты не будут заранее выстраиваться в длинную очередь. Кроме того, нет ни малейшей возможности узнать, со сколькими людьми вы могли бы завязать отношения в течение всей своей жизни. И если вас зовут не Хью Хефнер, вы, вероятно, не планируете иметь бесконечно большое число сексуальных партнеров. К счастью, есть и другой вариант этой задачи, который гораздо больше подходит для простых смертных, таких, как вы и я, и позволяет получить столь же впечатляющий результат. В этом варианте вам совершенно не обязательно гадать, сколько партнеров вы могли бы встретить за всю свою жизнь – достаточно знать, как долго вы планируете вести свободный образ жизни, прежде чем решите остепениться. Расчеты в этом случае намного сложнее[10], хотя в конце вновь всплывает тот же результат – 37 %. Только на этот раз он относится не к количеству претендентов, а ко времени. Допустим, вы начали бегать на свидания в пятнадцать лет и в идеале хотели бы остепениться и завести семью к сорока. Назовем эти двадцать пять лет “окном свиданий”. В течение первых 37 % этого срока (то есть примерно пока вам не стукнет двадцать четыре) вы должны отказывать всем, кто предлагает вам любовь до гроба. Используйте это время, чтобы понять, что к чему и, главное, разобраться, чего, в сущности, вы хотите от будущего спутника жизни. Когда этот этап закончится, выбирайте первого, кто окажется лучше всех предыдущих.
Эта стратегия даст вам наилучший шанс найти партнера номер один из вашего воображаемого списка. Но предупреждаю: даже этот вариант имеет свои недостатки. Представьте себе, что на начальном этапе “окна свиданий” вы начинаете встречаться с каким-то безумно обаятельным, убийственно красивым и необыкновенно приятным во всех отношениях партнером – короче говоря, он настоящий идеал! Но, не перебрав пока еще свои 37 %, вы не можете быть уверены, что это и есть лучший претендент из вашего списка. Если вы решите строго следовать алгоритму, то, согласно правилам фазы отторжения, с этим человеком следует расстаться. К несчастью, когда этот этап завершится и вы начнете более серьезно подходить к поиску спутника жизни, выяснится, что никого из них и сравнить нельзя с той вашей давней любовью. Если буквально следовать алгоритму, то вам придется всю жизнь отвергать всех кандидатов, пока вы не состаритесь в одиночестве. А умирая, вы, вероятно, будете проклинать ненавистные математические формулы. Теперь представьте себе прямо противоположную ситуацию: вам ужасно не везло, и все, с кем вы встречались в течение первой трети “окна свиданий”, были невыносимыми занудами. К счастью, вы пребывали в фазе отторжения, и поэтому не связали свою жизнь ни с одним из них. А теперь представьте, что вы только что перебрали свои 37 % – и первый же встретившийся вам после этого человек оказался… тоже занудой (хотя и чуть менее занудным, чем предыдущие кандидаты)! Если вы, опять-таки, будете следовать правилам, то, боюсь, обречете себя на довольно скучный брак. Тем не менее, с учетом всех рисков, а также оговоренных нами допущений и упрощений, это лучшая из возможных стратегий. Я считаю, что она остается актуальной и подтверждается реальным поведением многих людей в реальной жизни. Мы и в самом деле часто решаем сначала пройти через ряд романов и только потом, примерно после двадцати пяти, всерьез задумываемся о поиске спутника жизни. В Европе женщины выходят замуж в среднем в возрасте двадцати семи с половиной лет, что вполне укладывается в теорию. Я допускаю, что мужчины более вольно устанавливают для себя верхний предел возраста, когда пора остепениться, поэтому в Европе они вступают в брак в среднем в тридцать лет. Помимо выбора партнера, аналогичная стратегия применима также в целом ряде других ситуаций, когда люди что-то ищут и хотят знать, когда наступит оптимальный момент для того, чтобы прекратить поиск. У вас есть три месяца, чтобы найти новую квартиру? Отвергайте все предложения, поступившие в течение первого месяца, а потом соглашайтесь на первый же вариант, который понравится вам больше, чем любой из уже отвергнутых. Хотите нанять ассистента? Откажите первым 37 % соискателей, а потом возьмите на работу первого, кто окажется лучше, чем любой из предыдущих. Собственно говоря, поиск сотрудника и является самым известным приложением этого метода, и поэтому его часто так и называют – “проблема секретаря”. Несмотря на разнообразие областей применения метода и отчасти вопреки моим собственным словам, я, возможно, все-таки слегка перегибаю палку, советуя отвергнуть первые 37 % соискателей. Дело в том, что у этой стратегии есть один недостаток, о котором я еще не упоминала. До сих пор мы (и наши расчеты) исходили из того, что вы обязательно хотите найти лучшего из списка возможных партнеров. Но ситуация слегка изменится, если вы немного трансформируете свои критерии. В реальной жизни многие из нас предпочли бы провести жизнь с “просто хорошим” партнером, чем остаться у разбитого корыта, так и не встретив свой “номер один”. Может быть, не стоит упрямо следовать принципу “все или ничего”, а попытаться найти счастье с человеком, который входит хотя бы в верхние 5 % (или даже 15 %) вашего списка? И в этом случае математика может кое-что вам предложить. Давайте попробуем определить наилучшую стратегию для каждого из этих сценариев, воспользовавшись так называемым “методом Монте-Карло”. Идея заключается в том, чтобы создать своего рода математической “день сурка” внутри компьютерной программы, что позволяет перебрать десятки тысяч различных сценариев вашей судьбы, играя со случайным образом выбранными партнерами и степенями совместимости. Программа, действуя как виртуальный симулятор поиска партнера, моделирует ситуации, которые могут возникнуть, если ваша “фаза отторжения” отличается от описанной выше (то есть включает не 37 %, а иное число). В конце каждого цикла программа “оглядывается назад”, снова оценивает всех ваших потенциальных партнеров и определяет, была ли выбранная стратегия успешной. Если повторить эту процедуру для всех возможных вариантов “фазы отторжения” и для каждого из трех критериев в каждом варианте (только идеальный партнер, один из лучших 5 %, один из лучших 15 %), то у нас получится примерно такой график:
Красная кривая – вероятность решения нашей изначальной задачи (то есть согласие только на “кандидата номер один”). Как мы уже говорили, в этом случае максимальные шансы на успех возникают после того, как вы откажете 37 % кандидатов. В результате вероятность найти ваш идеал также будет равна 37 %. Но если вы слегка смягчите критерии и согласитесь обрести счастье с кандидатом, входящим в лучшие 5 % (из всех, с кем вы встретитесь за всю свою жизнь), то ваша кривая – желтая. Здесь наилучшие шансы на успех возникают после того, как вы отвергнете всех кандидатов, появившихся в течение первых 22 %, от вашего “окна свиданий” и выберете того из последующих, который окажется лучше всех предыдущих. Следуйте этой стратегии – и вероятность того, что вам удастся связать свою судьбу с одним из лучших 5 %, составит внушительные 57 %. Но если вы еще менее привередливы и готовы удовольствоваться кем-то из верхних 15 %, то, как показывает голубая кривая, вам достаточно будет провести в свободном поиске 19 % времени “окна свиданий”, чтобы разобраться, чего именно вы хотите. Используйте эту стратегию, и ваши шансы на успех подскочат до грандиозных 78 % – это гораздо менее рискованный вариант, чем традиционный подход “все или ничего”. Конечно, и эти теории не идеальны. Спутник жизни – это все-таки не квартира и не секретарь, которые могут легко стать вашими, если у вас достаточно средств. Тем не менее, мне кажется, что это элегантное и простое решение предлагает интересный взгляд на реальную ситуацию, даже если вы не готовы полностью принять его как руководство к действию. В конце концов, вся суть математики заключается в том, что эта наука – инструмент абстрагирования от реального мира, помогающий понять его скрытые закономерности и связи, которые в противном случае остались бы погребенными внутри бесформенной и запутанной субстанции, которую мы называем эмоциями.
Как оптимизировать свадьбу?
Теперь, когда мы знаем, как охотиться за идеальным партнером, будем надеяться, что у каждого из нас появился шанс на долгосрочные и надежные отношения. Тем же, кто решит скрепить этот союз официальным браком, придется преодолеть еще одно препятствие на пути к тому, чтобы наконец начать “жить долго и счастливо”: как только уляжется эйфория от помолвки, вы окажетесь лицом к лицу с необходимостью спланировать свадьбу. Ни одно из юных застенчивых романтических созданий не представляет себе, что в один прекрасный день превратится в чудовище, которое считает собственную свадьбу важнейшим событием в истории человечества. Ни один будущий жених никогда бы не поверил, что он однажды устроит истерику из-за того, что две скатерти не сочетаются одна с другой по цвету. Но когда на вас наваливается сразу столько забот – приглашение новых родственников, бюджет, наряды, место проведения торжества, подружки невесты, – немудрено сойти с ума (поверьте мне, я знаю это по собственному горькому опыту). И прежде чем вы окончательно обезумеете, выбирая каллиграфический шрифт для приглашений или ленты из органзы для украшения стульев, я попытаюсь показать вам, как математика может облегчить этот великий день.
Математика приглашений
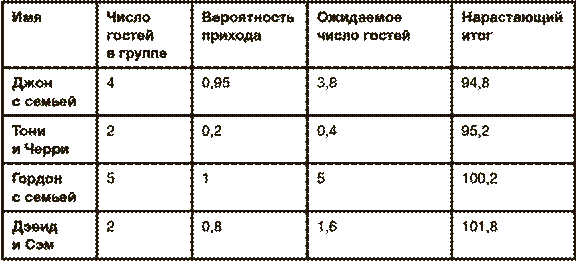
Одна из первых проблем, с которыми вы столкнетесь, – это устрашающий список гостей, и его составление всегда оказывается гораздо сложнее, чем казалось на первый взгляд. В идеале вы готовы пригласить вообще всех своих знакомых, но реальность бюджета и площадь помещения быстро заставят вас приступить к трудному процессу отбора из массы достойных людей, которые, казалось бы, все имеют равное право быть приглашенными. Друзья, которых вы приглашаете, часто приходят со своими партнерами (это зависит от того, насколько жесткие правила вы установили[11]) и членами семьи, и в конце концов семейных гостей окажется больше, чем одиночек. Учтите также, что не все, кого вы в конце концов позовете, действительно придут. Решение, сколько всего гостей вы хотите пригласить, – это всегда сложнейший компромисс. Слишком узкий круг – и вы рискуете обидеть нескольких важных для вас людей; слишком много народа – получится слишком дорого и при этом очень тесно. В большинстве случаев мы решаем эту проблему следующим образом: рассылаем приглашения, а затем корректируем список по мере того, как приходят ответы с подтверждением или отказом и извинениями. Но можно ли считать такой подход безопасным в наш век, когда люди считают, что их завтрак – вполне достаточный повод обновить статус в Facebook? Весть о том, что вы рассылаете приглашения, мгновенно разнесется среди знакомых, и друзья и родственники “второго ряда” обидятся, что не были включены в почетный “ближний круг”. В качестве альтернативного метода вы можете просто пригласить меньшее число гостей или отложить аренду зала для торжества до того момента, когда вы будете знать точное число участников. А можно, как делают многие, просто попытаться угадать вслепую. Однако есть один математический способ, который позволит вам обрести почву под ногами, пока не начались ссоры с будущими тещами и свекрами. Начнем с того, что составим список всех потенциальных гостей, сгруппируем его по парам или семьям, а затем отсортируем эти группы по степени значимости их присутствия на свадьбе. Эта задача может показаться неразрешимой, но если вы сами не знаете, кто из ваших друзей нравится вам больше, а кто меньше, то тут и математика не поможет. Итак, превращаем наш список в электронную таблицу, где в первой колонке будут названия групп гостей, во второй – число людей в группе. Теперь по каждой группе нужно оценить вероятность того, что эти ваши друзья действительно появятся, если вы их пригласите. Как далеко они живут? Что сейчас происходит в их жизни? А может быть, в глубине души они вас терпеть не могут? В общем, разбирайтесь. Мысленно давайте оценку в процентах, но в таблицу записывайте вероятность в десятичной дроби. Например, если ваша близкая подруга со своим бойфрендом придут с вероятностью 95 %, то в таблицу напротив их имен вы записываете число 0,95. Умножив цифру из второй колонки (число людей в каждой группе) на вероятность появления группы (третья колонка), вы получите четвертую колонку – ожидаемое количество гостей на свадьбе. Двигаясь по списку сверху вниз, от VIP -персон к вечным аутсайдерам, записывайте в пятой колонке число гостей (каждый раз прибавляя результат из соответствующей строки колонки № 4). Самый простой способ завершить подсчет – отсечь ту часть списка, которая останется, когда число в пятой колонке превысит число мест за столами в зале, который вы арендуете для мероприятия. Примером того, как может выглядеть нижняя часть списка, может служить эта таблица:
Если вы планируете принять сто гостей, то можете пригласить всех, включая Гордона с семьей (у вас получится чуть больше сотни приглашенных, но в среднем можно ожидать, что придут как раз сто). К сожалению, на этот раз Дэвид и Сэм не вышли в финал (может быть, это и к лучшему). Внимательный читатель, конечно, уже заметил недостаток этого метода. Поскольку мы имеем дело с вероятностями, не исключено, что согласием ответят как больше ста человек, так и меньше. Во втором случае у вас появится возможность в последнюю минуту пригласить тех, кто остался за бортом (а также тех, о ком вы просто забыли, составляя список), но вот если придет больше людей, чем вы рассчитывали, это может стать катастрофой. Поэтому неплохо было бы сразу же рассчитать этот катастрофический сценарий, а затем ограничить список таким образом, чтобы свести к минимуму вероятность того, что мест не хватит. Но как рассчитать вероятность катастрофы? Допустим, что для того чтобы к вам пришли сто гостей, вам нужно разослать сто пятьдесят приглашений. На самом деле число принявших приглашение может оказаться любым в интервале от 0 до 150, но вероятность обоих экстремальных значений крайне низка. На самом деле рассчитать вероятность того, что придут все 150 приглашенных, довольно легко: нужно просто перемножить все вероятности из третьей колонки. Например, вероятность того, что придут и Джон, и Тони, и Гордон с семьями, составляет: 0,95 × 0,2 × 1,0 = 0,19, или 19 %. Теоретически можно рассчитать вероятность прихода любого количества гостей, просто перебрав все возможные комбинации “да” и “нет”[12]. Если поместить рассчитанные вероятности для каждого числа гостей в график, то он будет выглядеть примерно так:
Вероятность того, что придет определенное количество гостей, резко возрастает в середине интервала, и в среднем вы можете ожидать, что придет сто человек. Теперь нам гораздо легче разумно обозначить безопасную буферную зону. Если вы пригласите 150 человек, то можете быть более или менее уверены, что количество пришедших будет близко к пику кривой – в данном примере от 85 до 110 гостей. Вы можете поработать с графиком, чтобы посмотреть, как изменится кривая, а вместе с ней нижний и верхний пределы: например, что изменится, если пригласите не 150, а 120 или 130 человек? В результате вы определите для себя буферную зону, которая устроит вас даже при наихудшем сценарии. Этот метод уже был опробован в реальной жизни. В 2013 году пара молодоженов с математическим складом ума, Дамьян Вукчевич и Джоан Ко, планируя свою свадьбу, использовали именно этот алгоритм. Они разделили своих потенциальных гостей на четыре категории и рассчитали вероятность для каждой категории. Дамьян и Джоан разослали 139 приглашений, и, согласно их модели, следовало ожидать, что на самом деле придут 106 гостей, поскольку с вероятностью 95 % число последних должно было составить от 102 до 113. Оказалось, что пришли 105 человек, хотя приглашений было разослано лишь 97. Дамьяну и Джоан удалось правильно оценить число гостей, несмотря на то, что они совершили две ошибки (которые компенсировали одна другую): они переоценили вероятность того, что все живущие в том же городе друзья обязательно придут, но недооценили число тех, кто до последнего ждал приглашения, но в результате явился без него. Как мы уже видели в главе 1, при статистической оценке то и дело возникает тема взаимной компенсации ошибок, и это одна из причин в пользу того, чтобы оценивать вероятность по отдельности для каждой группы в вашем списке гостей. Нет сомнений, что вы будете слишком оптимистичны в отношении одних своих знакомых, зато недооцените других. Вы можете слегка промахнуться, но в конце концов в целом все будет в порядке. Невозможно придумать метод, в котором вообще нет риска. Но метод, который предлагаем мы, дает вам полезную отправную точку, оттолкнувшись от которой, вы сможете корректировать свой список приглашенных.
|
||||
|
|
Последнее изменение этой страницы: 2016-12-11; просмотров: 391; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.217.39 (0.015 с.) |