
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Протокол коррекции ошиб V.42
Протоколы коррекции ошибок MNP4 (Microcom Networking Protocol Class 1-4) и V.42 позволяют передавать данные без ошибок даже по зашумленным телефонным каналам. Эффективность протокола V.42 выше, чем MNP-4, особенно при работе на сильно зашумленных линиях. Принцип работы протокола следующий: передаваемый поток данных разбивается на пакеты. Далее определенным образом вычисляются контрольные значения для каждого пакета, отправляемые вместе с пакетом. Если при передаче данных произошла ошибка и полученные контрольные значения не совпадают, происходит повторная передача пакета. Протокол передачи данных Передача данных организуется на основе набора протоколов, каждый из которых устанавливает правила взаимодействия связывающихся устройств. Протокол передачи данных - это правила, по которым происходит обмен данными между компьютерами. Протоколы, используемые в модемах, делятся на четыре основные группы: протоколы модуляции и передачи данных; протоколы коррекции ошибок; протоколы сжатия передаваемых данных; протоколы связи DTE (Data Terminal Equipment, терминальное оборудование) и DCE (Data Communication Equipment, оборудование передачи данных). Первые три группы относятся только к связи DCE-DCE (другими словами, модем - модем), последняя - только к связи DCE-DTE (модем - компьютер). О поддерживаемых протоколах обязательно указывается в документации на модем. Теоретически, чем "новее" протокол передачи данных, тем больше скорость обмена. Практически же на скоростях выше 56 кбит/с. могут работать только модемы, поддерживающие протокол V.90 или V.92, а также более ранние x2 и K56Flex. Но приемлемое качество при работе с протоколом V.90 или V.92 обеспечивается только на цифровых АТС, которых не так уж много. Если модем поддерживает протоколы до V.34 включительно, это означает, что он может работать только на скоростях до 33.6 кбит/с. Скорость работы факса Этот параметр определяется соответствующими факсовыми протоколами. Модем должен уметь работать на скорости как минимум 9600 бит/с. (протокол V.29), а оптимальная скорость - 14400 (V.17). Желательно также, чтобы модем поддерживал различные системы команд факса. В документации они именуются Class 1, Class 1.0, Class 2 и Class 2.0. Этим достигается совместимость с большинством факс-программ для модемов.
Статическая маршрутизация Маршрутизация - это процесс выбора пути для передачи данных. Она бывает статической или динамической. При статической маршрутизации вся информация о маршрутизации хранится в статической таблице на каждом маршрутизаторе. Эту таблицу нужно составлять вручную. Чтобы любые два произвольных хоста в сети могли взаимодействовать между собой, каждый маршрутизатор должен иметь такую таблицу маршрутов. Статическая маршрутизация используется, как правило, в небольших сетях - например, на малых предприятиях или в филиалах. Факс Наличие возможности передавать и получать факсы с использованием модема. Факс-модем - это модем со встроенными факсовыми протоколами установления связи, модуляции и передачи изображений. Такое устройство может работать как с обычными модемами (посредством протоколов передачи данных), так и с факс-машинами (через протоколы передачи изображений). Как правило, все современные модемы одинаково хорошо умеют передавать факсимильные сообщения, но вот принимать их не хуже обычных факсов могут далеко не все. О дополнительных настройках модема в режиме факса можно узнать из прилагающейся к нему документации. Формат ExpressCard ExpressCard - это новый стандарт карт расширения, который приходит на замену PCMCIA (PC Card). Есть два формата ExpressCard, которые отличаются размерами - ExpressCard/34 (шириной 34 мм) и ExpressCard/54 (шириной 54 мм). Карты обоих форматов имеют одинаковый разъем, поэтому если у вас в компьютере есть слот для ExpressCard/54, то вы сможете использовать и 34 мм, и 54 мм карты. Число VPN-туннелей Количество одновременно поддерживаемых VPN-туннелей между удаленной локальной сетью и сетью главного офиса. Подробнее о VPN см. в разделе "Поддержка VPN (VPN pass through)", "Поддержка VPN-туннелей (VPN Endpoint)". Каждый туннель связывает одного пользователя или часть локальной сети с определенной частью удаленной сети. При выборе модема с встроенным сетевым устройством следует учитывать предполагаемое количество пользователей с индивидуальными настройками VPN: чем их больше, тем больше должно быть число VPN-туннелей.
«Способы ввода экспериментальной информации в ПК»
Необходимость создания системы автоматического ввода
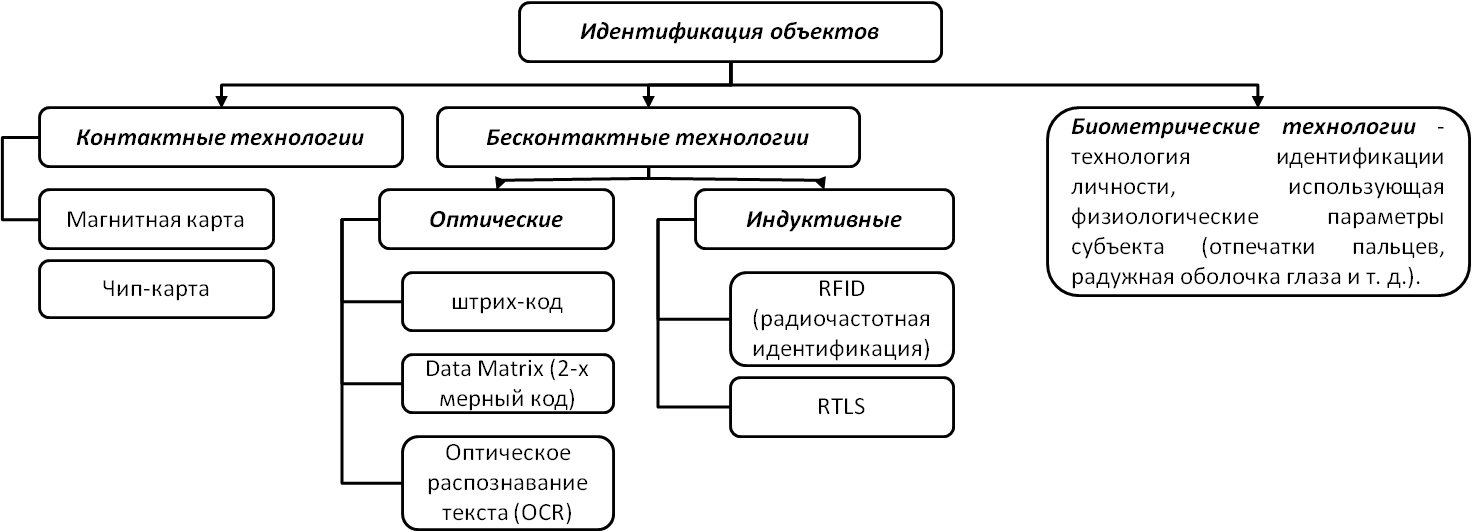
Cоздатели САПР помимо выявления множества задач, решаемых системой, и распределения их между человеком и ЭВМ должны также на основе анализа требования пользователя определить способы общения человека с машиной. Последнее предполагает выбор подходящих средств диалога и установление языков общения. Продуманный выбор языка играет существенную роль в создании творческой обстановки для человека в процессе автоматизированного проектирования. Желательно, чтобы оператор, находящийся за терминалами АРМа, общался с системой в привычной для него форме представления информации. Всякая замена привычных и удобных языков на менее удобные приводит к снижению производительности труда. В качестве языков общения естественно использовать языки изображений. Примерами подобных языков являются языки, образованные графическими документами (принципиальными, функциональными, электрическими схемами, схемами размещения элементов, эскизами топологии слоев печатного монтажа и др.). Другие способы описания того, что изображено на графическом документе, затрудняют процесс восприятия информации человеком. Очевидно, что и в случае, когда информация графического типа передается от человека к ЭВМ, этот процесс должен быть для человека столь же простым и легким. Автоидентификация Автоматическая идентификация и сбор данных (AIDC, от англ. Automatic Identification and Data Capture) общий термин для методов автоматической идентификации объектов, сбора данных о них и обработку данных автоматическими и автоматизированными системами. Обычно к AIDC относят следующие технологии:
Рисунок – Технологии идентификации объектов Автоматическая идентификация осуществляет автоматическое распознавание, расшифровку, обработку, передачу и запись информации, большей частью с помощью нанесения и считывания информации, закодированной в штрих-коде. Штрих-коды позволяют быстро, просто, и самое главное точно считывать и передавать информацию о тех предметах, которые нуждаются в прослеживании и контроле. Этикетки со штрих-кодами очень легко приклеиваются практически к любой поверхности, а также могут быть нанесены уже непосредственно на тюбики, конверты, коробки, бутылки, упаковки, книги, мебель, карточки и еще на многие предметы, которые нуждаются в идентификации. Появление систем автоматической идентификации значительно увеличило скорость, эффективность и точность обработки и сбора информации. Первые применения штрих-кодов, такие как точки розничной торговли, контроль за перемещением, проведение инвентаризаций, определили появление более широких отраслей применения, например учет времени посещения, контроль за рабочим процессом, за качеством, сортировкой, перемещением документов, получением и перевозкой грузов, за доступом к секретным участкам, а также многие другие применения. Штрихкодирование Штриховой код (штрихкод) — это последовательность чёрных и белых полос, представляющая некоторую информацию в удобном для считывания техническими средствами виде.
Символики штрихового кода Code 128 (Код 128) и Code 39 (Код 39), наряду с символиками EAN/UPC и Interleaved 2 of 5 (2 из 5 чередующийся) в настоящее время являются самыми распространенными в мире среди линейных символик, в которых символ представлен последовательностью знаков символа штрихового кода, выстроенных в одну линию. Но в отличие от EAN/UPC и Interleaved 2 of 5 эти символики позволяют кодировать не только цифровую информацию, но и данные, содержащие латинские буквы и специальные графические знаки. Штрих-коды, наверное, самая известная из всех технологий автоматической идентификации.
Новое растущее направление в мире штрих-кодов – это двумерные коды. Двухмерными называются символики, разработанные для кодирования большого объёма информации. Расшифровка такого кода проводится в двух измерениях (по горизонтали и по вертикали). Символ с многострочной символикой состоит из двух и более смежных по вертикали строк знаков символа штрихового кода. В отличие от традиционных линейных символик штрихового кода, которые позволяют представлять в символе штрихового кода короткую последовательность данных, являющуюся, как правило, ключом к записи во внешней базе данных, многострочные символики позволяют кодировать информацию в полном объеме. Кроме того, многострочные символики включают в себя специальные механизмы по сжатию данных (защите их от повреждения, связыванию информации), представленных в нескольких символах, в один большой файл; представлению различных наборов знаков в одном сообщении. Двухмерные коды подразделяются на многоуровневые (stacked) и матричные (matrix). Многоуровневые штрихкоды появились исторически ранее, и представляют собой поставленные друг на друга несколько обычных линейных кодов. Матричные же коды более плотно упаковывают информационные элементы по вертикали. Примерами таких кодов являются PDF 417, MaxiCode, Data Matrix, Aztec Code м др. Преимущества штрих-кодов. Со времени появления штрих-кодов ввод информации стал более точным и быстрым, и все процессы, связанные с обработкой информации, стали более быстрыми и точными. Потребуется достаточно много времени для того, чтобы выяснить назначение или текущий статус той или иной работы, инструментов, материалов, или любого перемещающегося предмета. Штрих-коды помогают отслеживать движения товаров и благодаря этому позволяют экономить время, оперативно отвечать на запросы и реагировать на любые изменения.
Система штрих-кодов открывает потрясающие преимущества для любого рода бизнеса. С помощью штрих-кодов сбор и запись информации становятся более быстрыми и точными процессами, что и позволяет снижать цены, сводить к нулю вероятность ошибок, а также упрощать все процессы товарооборота.
Экономия времени. В зависимости от применения штрих-кодов, экономия времени может быть самой различной. В большинстве случаев на складах торговых предприятий самым драматичным моментом являются инвентаризации. Одному торговцу понадобятся 25 работников, которые будут работать сутки напролет плюс выходные дни для того, чтобы провести инвентаризацию за полгода; с помощью штрих-кодов вам понадобятся всего 4 работника и 5 часов работы. Уменьшение ошибок. В некоторых ситуациях, ошибки ручного вода данных могут иметь и более драматичный исход: представьте себе важность точного вода данных в процессе работы банка данных крови. Типичным уровнем ошибок ручного ввода данных считается 1 ошибка на 300 ударов. Сканеры штрих-кодов в этом отношении более точные, уровень возможных ошибок при работе сканера сводится к одной ошибке на 36 триллионов, но это также зависит от типа сканера. Оптическое распознавание текста (англ. optical character recognition, OCR) — это механический или электронный перевод изображений рукописного, машинописного или печатного текста в последовательность кодов, использующихся для представления в текстовом редакторе. Распознавание широко используется для конвертации книг и документов в электронный вид, для автоматизации систем учета в бизнесе или для публикации текста на веб-странице. Оптическое распознавание текста позволяет редактировать текст, осуществлять поиск слова или фразы, хранить его в более компактной форме, демонстрировать или распечатывать материал, не теряя качества, анализировать информацию, а также применять к тесту электронный перевод, форматирование или преобразование в речь. Оптическое распознавание текста является исследуемой проблемой в областях распознавания образов, искусственного интеллекта и компьютерного зрения.
|
||||||||
|
|
Последнее изменение этой страницы: 2016-09-19; просмотров: 369; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 3.134.90.44 (0.011 с.) |
 Линейные штрих-коды. Линейными (обычными) называются штрихкоды, читаемые в одном направлении (по горизонтали). Линейные символики позволяют кодировать небольшой объём информации (до 20—30 символов, обычно цифр). Штриховой код символики EAN/UPC, представленный семейством символов EAN-8, EAN-13, UPC-A, UPC-E, предназначен для кодирования цифровой информации и является одним из основных машиночитаемых носителей данных в рамках международной системы EAN•UCC.
Линейные штрих-коды. Линейными (обычными) называются штрихкоды, читаемые в одном направлении (по горизонтали). Линейные символики позволяют кодировать небольшой объём информации (до 20—30 символов, обычно цифр). Штриховой код символики EAN/UPC, представленный семейством символов EAN-8, EAN-13, UPC-A, UPC-E, предназначен для кодирования цифровой информации и является одним из основных машиночитаемых носителей данных в рамках международной системы EAN•UCC. Двухмерные штрих-коды.
Двухмерные штрих-коды.


