Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Программная архитектура i80х86
Одним из наиболее распространенных процессоров общего назначения на данный момент являются процессоры с архитектурой x86 (Intel IA-32). Родоначальником семейства этих процессоров явился ЦП i8086. И по сей день современные x86-совместимые процессоры могут исполнять код, который мог выполняться на ЦП i8086. Обеспечивается это за счёт обратной совместимости на ровне программной модели. Совокупность архитектурных решений, архитектуру команд и правила написания программ на низкоуровневом языке принято называть программной моделью процессора. Поскольку, написание в машинных командах представляется крайне трудоёмкой задачей, вместо машинного языка при написании программ используют язык ассемблера. Команды языка ассемблера один в один соответствуют командам процессора и, фактически, представляют собой удобную символьную форму записи (мнемокод) команд и их аргументов. Также язык ассемблера обеспечивает базовые программные абстракции: связывание частей программы и данныx через метки с символьными именами (при ассемблировании для каждой метки высчитывается адрес, после чего каждое вхождение метки заменяется на этот адрес) и директивы. Каждая модель процессора, в принципе, имеет свой набор команд и соответствующий ему язык (или диалект) ассемблера. В дальнейшем условимся язык ассемблера также рассматривать как часть программной модели ЦП. При выполнении любой программы в любой момент времени можно выделить несколько участков памяти (сегментов), с которыми происходит работа микропроцессора. Использование сегментов является отличительной особенностью микропроцессоров семейства I80х86 и преследовало несколько целей. Во-первых, использование сегментов является попыткой защитить или, по крайней мере, изолировать несвязные участки памяти в самой программе или между программами. Во-вторых, программа будет выполняться, если изменить только адрес начала сегмента (перенося его в памяти в другое место) и не менять относительное смещение в нем. Это позволяет, при необходимости, переносить программу в памяти даже в процессе ее выполнения. Возможности сегментации памяти существенно превышают возможный размер физической памяти, используемой в микропроцессоре. В некоторых ситуациях использовать сегментацию памяти нецелесообразно, поэтому в старших моделях микропроцессора (начиная с I80386) можно работать с сегментами памяти длиной до 4 Гбайт, т.е. вся доступная физическая память рассматривается как один сегмент. В реальном режиме работы микропроцессора любая программа, оперирует с четырьмя сегментами:
1. Сегмент кода. 2. Сегмент данных. 3. Сегмент стека. 4. Сегмент дополнительных данных. Эти сегменты могут располагаться в памяти по отношению друг к другу как угодно, никаких ограничений на их расположение не вводятся. Например, все сегменты могут начинаться с одного и того же адреса, и таким образом они перекрываются друг с другом. Сегменты могут располагаться непосредственно друг за другом в памяти без перекрытия или же между ними могут быть пустые промежутки. Сегмент кода.
В сегменте кода обычно записываются команды микропроцессора, которые выполняются последовательно друг за другом. Для определения адреса следующей команды после выполнения предыдущей используются два регистра – CS (регистр сегмента кода, содержит начальный адрес этого сегмента) и IР (регистр указателя команд, содержит смещение текущей команды относительно начала этого сегмента). Начальные значения регистров CS и IP загружаются операционной системой в начале выполнения программы, в процессе выполнения команд содержимое IP автоматически изменяется. Если изменить содержимое CS и/или IP, то выполнение программы продолжится с нового адреса. Однако изменить эти регистры явным образом невозможно, это можно сделать при выполнении некоторых команд (например, команды безусловного перехода или вызова подпрограммы). В сегменте кода можно также описывать данные, однако это целесообразно делать в обоснованных случаях, например, в программах обработки прерываний. Переменные в программе.
Во всех остальных сегментах выделяется место для переменных, используемых в программе. Разделение на сегменты данных, сегмент стека и сегмент дополнительных данных связано с тем, что в таких сегментах хранятся переменные, имеющие различные свойства. Переменные в программе можно разбить на две большие группы. Во-первых, переменные, явно применяемые в программе исходя из ее логики, обычно такие переменные имеют имена и предназначены для хранения данных, имеющих предопределенный смысл (например, переменная для хранения кода нажатой клавиши при организации диалога с пользователем). Во-вторых, в программе очень часто необходимо иметь место для хранения временных данных (например, для хранения адреса возврата из подпрограммы, для хранения параметров некоторой процедуры или локальных переменных, используемых в подпрограммах). Можно, конечно, выделять таким переменным память так же, как и обычным, однако это приводит к существенному усложнению логики выполнения программы. Поэтому во всех микропроцессорах есть средства для хранения временных данных (во всяком случае для хранения временных переменных, нужных для организации работы подпрограмм). В микропроцессорах семейства i80х86 для хранения данных выделяется два сегмента – сегмент данных и сегмент стека.
Сегмент данных.
Сегмент данных предназначен для хранения переменных, определяемых программистом. Для определения адреса начала сегмента данных используется сегментный регистр DS. Для определения другой компоненты адреса (относительного смещения в данном сегменте) в языке ассемблера предполагается несколько способов, количество которых больше, чем количество способов для определения адреса команды, что обеспечивает большую гибкость при написании программ. Сегмент стека.
Для хранения временных значений, для которых нецелесообразно выделять переменные, предназначена специальная область памяти, называемая стеком. Для адресации такой области служит сегментный регистр SS (в котором хранится начальный адрес этого сегмента памяти) и регистр указателя стека SP (для хранения смещения по отношению к началу этого сегмента). В отличие от сегмента данных и кода, в которых можно явно адресовать любую ячейку памяти (например, используя метки или имена переменных – т.е. их адреса), в сегменте стека обычно регистры SS и SP используются неявно, автоматически изменяя свои значения при выполнении тех или иных команд. Стек обычно используется для временного хранения адресов возврата из подпрограмм или прерываний (для того, чтобы можно было продолжить выполнение программы с прерванной точки). Кроме того, в стеке удобно сохранять, а потом из стека восстанавливать значения некоторых регистров, если они могут измениться при выполнении некоторых действий (например, перед вызовом функций операционной системы или в начале программы обработки прерываний). И, наконец, используя стек, можно легко передавать аргументы подпрограммам и в стеке можно организовывать локальные переменные (такой подход используется во всех языках высокого уровня). Микропроцессор i8086
С точки зрения программиста микропроцессор представляется в виде набора регистров. Регистры предназначены для хранения некоторых данных и поэтому, в некотором смысле, они соответствует ячейкам памяти. Однако между ними есть несколько различий. Во-первых, доступ к регистрам осуществляется гораздо быстрее, чем к ячейкам памяти, поэтому в регистрах целесообразно хранить или временные данные, или такие, к которым необходим быстрый доступ (например, счетчики циклов). Во-вторых, у регистров, в отличии от ячеек памяти, нет адресов, а доступ к ним осуществляется по их имени. В-третьих, в зависимости от типа микропроцессора, размерность регистров может быть разной, а размерность ячеек памяти всегда постоянна и остается равной одному байту. Рассмотрим состав внутренних регистров микропроцессоров семейства i80х86.
Все внутренние регистры микропроцессоров являются шестнадцатиразрядными и позволяют хранить 2 байта. Они подразделяются на: 1. Регистры данных. 2. Регистры указателей и индексов. 3. Сегментные регистры. 4. Регистр флагов. Регистры данных предназначены для временного хранения переменных и результатов различных операций над ними. В состав регистров данных входят следующие регистры: 1. АХ – Регистр-аккумулятор. 2. ВХ – Базовый регистр. 3. СХ – Регистр-счетчик. 4. DX – Регистр дополнительных данных. Такое название регистры данных получили потому, что, кроме функций хранения данных, они имеют дополнительные функции при выполнении тех или иных команд. Регистр-аккумулятор представляет собой регистр, в котором хранится один из операндов перед некоторой операцией и в который попадает результат такой операции. Базовый регистр может использоваться дня формирования адреса (базы) любых переменных в памяти. Регистр-счетчик в командах организации цикла неявно (по умолчанию) используется как счетчик циклов. Регистр дополнительных данных в некоторых операциях, в которых результат операции может превысить 2 байта, хранит старшие разряды результата, которые не помещаются в аккумулятор. Кроме того, в командах ввода/вывода этот регистр содержит адрес соответствующего внешнего порта. В отличие от всех других регистров все регистры АХ, ВХ, СХ, DX могут быть разбиты на два однобайтных регистра: АХ – АН и АL ВХ – ВН и ВL СХ – СН и СL DX – DH и DL Символ Н (сокращение слова High) означает старшую половину (старший байт) шестнадцатиразрядного числа, символ L (сокращение слова Low - младшую часть (младший байт). Некоторые из этих восьмиразрядных регистров также неявно используются в некоторых командах микропроцессора.
Группу индексных регистров образуют следующие регистры: 1. ВР – Указатель базы (Вase pointer). 2. SI – Индекс источника (Source index). 3. DI – Индекс приемника (Destination index). 4. SP – Указатель стека (Stack pointer).
Размерность всех регистров – 2 байта, 16 бит, причем в таких регистрах невозможно иметь доступ к только старшему или только младшему байту. Первые три регистра используются или при формировании адресов переменных, или как регистры для хранения временных данных. Стек обычно неявно используется в командах передачи управления например, при вызове или возврате из подпрограммы или прерываниях микропроцессора для временного хранения адресов, по которым необходимо вернутся после того, как выполнится процедура обработки прерывания или вызова подпрограммы. Кроме того, с помощью стека можно обеспечить временное хранение значения любого из регистров (например, если при вызове некоторой стандартной подпрограммы известно, что его содержимое может измениться). И, наконец, с помощью стека легко организуется передача параметров в вызываемую функцию и организация локальных переменных внутри подпрограммы (такой подход используется практически во всех языках программирования высокого уровня и его необходимо поэтому обязательно применять при написании программ на смешанных языках). Как уже отмечалось, все программы состоят из нескольких сегментов (частей), поэтому в состав микропроцессора входят специальные регистры для хранения информации о начальных адресах этих сегментов. Состав этой группы 16-разрядных регистров следующий: 1. CS – регистр сегмента команд (сегмент кода программы). 2. SS – регистр сегмента стека. 3. DS – регистр сегмента данных. 4. ES – регистр сегмента дополнительных данных. Регистр CS совместно с регистром указателя команд используется для вычисления адреса следующей исполняемой команды в программе. В этом сегменте хранится код программы. Регистр SS совместно с указателем стека SP используется для определения адреса области памяти для хранения временных данных. При вычислении адресов параметров и локальных переменных подпрограмм обычно совместно с регистром SS используется регистр указателя базы ВР. В сегмент данных, определяемый регистром DS, обычно помещаются переменные, используемые в программе. Адрес этих переменных определяется с использованием регистров ВХ, SI и DI. Сегмент дополнительных данных используется как еще один сегмент при операциях над строками. Его можно использовать не только для формирования дополнительного сегмента при доступе к некоторым областям памяти компьютера, но и как еще один регистр для хранения некоторых значений. В обычных микропроцессорах всегда есть регистр, называемый Счетчиком Команд (РС, Program Counter), определяющий, какую команду выполнять следующей. После чтения текущей команды и всех ее параметров содержимое Счетчика Команд автоматически увеличивается для того, что бы он указывал на следующую команду в программе. Однако во всех микропроцессорах семейства i80х86 роль такого регистра выполняет регистр с другим названием – регистр Указателя Команд (IP,Instruction pointer).В системе команд микропроцессора отсутствуют команды явного (непосредственного) изменения значения такого регистра (его значения изменяется автоматически в зависимости от логики выполнения программы). Размерность Указателя Команд – 2 байта, 16 бит.
Так как в формировании адреса следующей выполняемой команды совместно с сегментным регистром CS (начальный адрес сегмента) участвует регистр IР (смещение в сегменте), то размерности этих регистров определяют максимальный размер сегмента кода. Максимально возможное смещение в сегменте кода может быть 216 байт, т.е. максимальная длина сегмента кода равна 64 Кбайт. Для написания программ, принимающих решения в зависимости от тех или иных условий, необходимо знать результат выполнения предыдущих команд (например, при сравнении двух переменных, при арифметических или логических командах и т.д.). Традиционно во всех микропроцессорах для этого используется так называемый регистр флагов, сохраняющий информацию о результате выполнения некоторой команды). Этот регистр представляет собой набор из 16 битов (не все из 16 битов в данном регистре используются), показывающий текущее состояние результата команды программы и текущее состояние микропроцессора. Доступ к ячейкам памяти
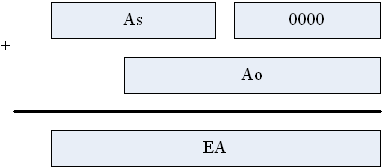
Как уже отмечалось, в состав любой микропроцессорной системы обязательно должна входить память, в которой располагаются программы и необходимые для их работы данные. Физическая и логическая организации памяти могут существенно отличаться. При программировании на языке ассемблера память можно рассматривать как массив ячеек, каждая из которых имеет размерность, равную одному байту. При выполнении некоторых команд микропроцессора некоторые участки памяти можно рассматривать как массив из слов, двойных слов и т.п. В отличии от регистров микропроцессора доступ к ячейкам памяти осуществляется с помощью чисел (адресов), а не имен. В программах языка ассемблера оперирует с адресом, состоящим из адреса начала сегмента и смещения относительно начала этого сегмента. Смещение называется исполнительным адресом (effective address). По определенным правилам адрес преобразуется. к логическому адресу. Правила преобразование зависят от режима работы микропроцессора – реального и защищенного. В реальном режиме работы микропроцессора логический адрес непосредственно подается на шину адреса т.е. совпадает с физическим адресом. В защищенном режиме правила получения логического адреса отличаются от реального режима, а при использовании страничной организации логические адреса могут отличаются от физического. В микропроцессоре i8086 шина адреса состоит из 20 линий, следовательно этот микропроцессор может адресовать 220 байт. Однако размерности регистров, с помощью которых они адресуются, ограничена 16 битами. Поэтому при формировании адреса из двух частей (сегмента и смещения внутри этого сегмента) используется следующая формула: ЕА = As * 16 + Ао, где ЕА – логический адрес ячейки памяти, As – адрес начала сегмента (содержимое одного из сегментных регистров – с для сегмента кода, SS для сегмента стека, DS и ES для сегментов данных), Ао – смещение относительно начала сегмента (содержимое регистра IP для сегмента кода, SP для сегмента стека и смещение адреса переменной, расположенной в сегменте данных). Умножение 16-разрядного регистра на.16 означает его сдвиг на 4 разряда влево, причем 4 младшие разряда получающегося 20-разрядного числа заполняются нулями. Тогда эту формулу можно проиллюстрировать на рис. 33.
Рис. 33. Формирование исполнительного адреса в реальном режиме.
Так как при вычислении адреса к сегментному адресу добавляется 4 нулевых разряда, это значит, что начало любого сегмента (т.е. при нулевом смещении) может находится только по адресу, кратному 24 = 16 байт. Область памяти в 16 байт называется параграфом поэтому, сегменты в программе всегда начинаются с начала (выровнены на границе) параграфа. Исходя из того, что адрес образуется из двух компонент, для записи его будет использоваться следующая форма – As:Ao – сегментный адрес и смешение, разделенные двоеточием. Например, запись 400:20 определяет следующий логический адрес (As = 400h, Ао = 20h): EA = 400h * 16 + 20h = 4000h+ 20h =4020h. В подавляющем большинстве случаев число всегда можно представить в виде суммы разных пар чисел, поэтому возможно несколько вариантов определения одного и того же адреса. Например, адрес 4020h соответствует вариантам 401:10, 402:0 и т.д. Так как в программах начальный адрес сегмента всегда определяется содержимым одного из сегментных регистров, то в некоторых случая адреса будут записываться в виде, например, DS:10. В этом случае адрес составляют текучее значение регистра сегмента данных DS и смещение в 10h байт по отношению к началу сегмента данных. Кроме того, так как в программах на языке ассемблера может использоваться косвенная адресация, то допустима также и запись адреса, например, в таком вида – SS:BP (содержимое сегментного регистра SS определяет компоненту As, а регистра ВР – компоненту Ао адреса). Так как при определении адреса используются две компоненты, то при определении некоторого адреса в программе можно использовать или одну часть адреса (оставляя другую неизменной – обычно используется смещение внутри сегмента), или обе компоненты. В первом случае адрес называется ближним (near adress), во втором – дальним (far address).. При определении ближнего адреса удобно использовать компоненту адреса, задаваемую смещением, оставляя сегментный адрес неизменным. В этом случае можно легко организовать доступ к любой ячейке памяти, лежащей внутри соответствующего сегмента (например, использовать все переменные, находящиеся в сегменте данных, зная только смещения этих переменных). Так как максимальное значение смещения может быть 216 = 65536 = 64 Кбайт, то именно эта величина и определяет максимальную длину любого сегмента в реальном режиме работы микропроцессора. При дальнейшем увеличении смещения значение этой компоненты станет равной 0 (0FFFFh + 1 = 10000h, но переполнение не сохраняется в шестнадцатиразрядном регистре, поэтому результат будет равен 0000h) и, следовательно, с помощью ближнего адреса невозможно получить доступ к элементу памяти, лежащему за пределами 64 Кбайт от начала сегмента (с помощью ближней адресации невозможно работать с массивом данных, превышающим 64 Кбайт). При адресации с помощью дальнего адреса изменяются обе компоненты адреса сегмент и смещение, поэтому с помощью такой адресации принципиально можно обратиться к любой ячейке памяти во всем диапазоне адресов микропроцессорной системы. Дальний адрес, у которого смещение не превышает 15 байт (т.е. находится в пределах одного параграфа), называется "громадным" адресом (huge address). Такая нормализация дальнего адреса при которой может измениться и значение начала сегмента, позволяет организовать доступ к элементам памяти, занимающим размер более 64 Кбайт. Следует отметить, что использование ближнего адреса для доступа к некоторой ячейке памяти происходит быстрее, чем с помощью дальней адресации, так как изменяется только одна из компонент адреса.
Команды микропроцессора
Программа, работающая в микропроцессорной системе, в конечном виде представляет собой набор байтов, воспринимаемый микропроцессором как код той или иной команды вместе с соответствующими данными для этой команды. Поэтому принципиально можно формировать программы как набор байтов с соответствующими двоичными значениями. Понятно, что писать, отлаживать и модифицировать такие программы очень сложно, если не невозможно.
Инструкция микропроцессора может содержать следующие поля (рис. 34):
Рис. 34. Формат команды микропроцессора архитектуры IA-32.
Префикс – необязательная часть инструкции, которая позволяет изменить некоторые особенности ее выполнения. В команде может быть использовано сразу несколько префиксов разного типа. Типы префиксов: командные префиксы (префиксы повторения) REP, REPE/REPZ, REPNE/REPNZ; префикс блокировки шины LOCK; префиксы размера; префиксы замены сегмента. КОП – код операции. Байт "Mod R/M" определяет режим адресации, а также иногда дополнительный код операции. Необходимость байта "Mod R/M" зависит от типа инструкции. Байт SIB (Scale-Index-Base) определяет способ адресации при обращении к памяти в 32-битном режиме. Необходимость байта SIB зависит от режима адресации, задаваемого полем "Mod R/M". Кроме того, инструкция может содержать непосредственный операнд и/или смещение операнда в сегменте данных. На размер инструкции накладывается ограничение в 15 байт. Инструкция большего размера может получиться при некорректном использовании большого количества префиксов. i80x86 в таком случае генерируют исключение #13. Если инструкция микропроцессора требует операнды, то они могут задаваться следующими способами: непосредственно в коде инструкции (только операнд-источник); в одном из регистров; через порт ввода-вывода; в памяти. Для совместимости с 16-битными процессорами архитектура i80x86 использует одинаковые коды для инструкций, оперирующих как с 16-битными, так и 32-битными операндами. Более новый вариант архитектуры предусматривает также новые возможности определения адресов памяти. Как процессор будет воспринимать операнд или его адрес, зависит от эффективного размера операнда и эффективного размера адреса для данной команды. Эти значения определяются на основе текущего режима работы процессора, значения дескриптора используемого сегмента памяти и наличия в инструкции определенных префиксов. Непосредственный режим адресации подразумевает включение операнда-источника в код инструкции. Операнд может быть 8-битовым или 16-битовым, если значение эффективного размера операнда - 16. Операнд может быть 8-битовым или 32-битовым, если значение эффективного размера операнда - 32. Обычно непосредственные операнды используются в арифметических инструкциях. Регистровый режим адресации определят операнд-источник или операнд-приемник в одном из регистров процессора или сопроцессора. В некоторых случаях, (например, в инструкциях DIV и MUL) могут использоваться пары 32-битных регистров (например, EDX:EAX), образуя 64-битный операнд. Адресация через порт ввода-вывода подразумевает получение операнда или сохранение операнда через пространство портов ввода-вывода. Адрес порта ввода-вывода либо непосредственно включается в код инструкции, либо берется из регистра DX.
|
|||||||||
|
|
Последнее изменение этой страницы: 2016-09-18; просмотров: 1221; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.223.196.171 (0.063 с.) |