
Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Различие между понятиями «информация» и «данные»Содержание книги
Поиск на нашем сайте
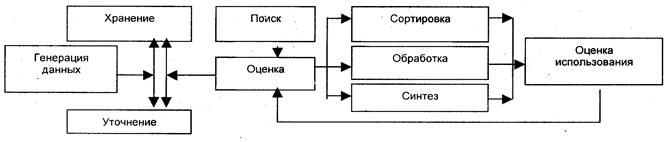
Данные - это тоже знания, однако знания совершенно особого рода. В первом приближении данные -это результат языковой фиксации единичного наблюдения, эксперимента, факта или ситуации [78]. Примерами данных могут быть: а) «такого-то числа, такого-то года, в момент t в определенной местности шел дождь» (метеорологическое данное)'; б) «цена деловой древесины в такой-то день такого-то года, по сведениям такой-то биржи, составляла столько-то долларов за тонну» (торговое данное); в) «дефицит государственного бюджета в такой-то стране составлял в таком-то году столько-то миллиардов долларов» (финансовое данное); г) «в такой-то момент времени автоматическая лаборатория, направляющаяся к Юпитеру, отклонилась от расчетной траектории на столько-то градусов, столько-то тысяч километров в таком-то направлении» (данные из сферы космической технологии). С технологической точки зрения некоторые специалисты понятие «данные», как правило, определяют как информацию, которая хранится в базах данных и обрабатывается прикладными программами, или информация, представленная в виде последовательности символов и предназначенная для обработки в ЭВМ [67], т.е. данные включают только ту часть знаний, которые формализованы в такой степени, что над ними могут осуществляться процедуры формализованной обработки с помощью различных технических средств. Данные - это информация, представленная в формализованном виде, пригодном для автоматической обработки при возможном участии человека [116]. Данные - это информация, записанная (закодированная) на языке машины [66]. Данные - это отдельные факты, характеризующие объекты, процессы и явления в предметной области, а также их свойства [40]. Между информацией и данными существует различие; Данные могут рассматриваться как признаки или записанные наблюдения, которые по каким-то причинам не используются, а только хранятся. Следовательно, в данный момент времени они не оказывают воздействия на поведение, на принятие решений. Однако данные превращаются в информацию, если такое воздействие существует. Например, основной массив данных для ЭВМ состоит из таких признаков, которые не воздействуют на поведение. Пока эти данные не организованы соответствующим образом и не отражаются в виде выходного результата, чтобы руководитель действовал в соответствии с ними, они не являются информацией. Они остаются данными до тех пор, пока сотрудник не обратился к ним в связи с осуществлением тех или иных действий или в связи с некоторым решением, которое он обязан принять. Данные превращаются в информацию, когда осознается их значение. Можно также сказать, что в том случае, когда появляется возможность использовать данные для уменьшения неопределенности о чем-либо, данные превращаются в информацию. Циклы жизни данных Подобно веществу и энергии, данные можно собирать, обрабатывать, хранить, изменять их формы. Однако у них есть некоторые особенности. Прежде всего, данные могут создаваться и исчезать. Так, например, данные о некотором вымершем животном могут исчезнуть, когда сжигается кусок угля с его отпечатками. Данные могут стираться, терять точность и т.д. Данные могут быть охарактеризованы циклом жизни (рис. 1.9), в котором основное значение имеют три аспекта - зарождение, обработка, хранение и поиск [56]. Воспроизведение и использование данных может осуществляться в различные моменты их цикла жизни и поэтому на схеме не показаны.
Рис. 1.9. Цикл «жизни» данных При обработке на ЭВМ данные трансформируются, условно проходя следующие этапы: 1) данные как результат измерений и наблюдений: 2) данные на материальных носителях информации (таблицы, протоколы, справочники); 3) модели (структуры) данных в виде диаграмм, графиков, функций; 4) данные в компьютере на языке описания данных; 5) базы данных на машинных носителях. Модели данных Модель данных является ядром любой базы данных. Появление этого термина в начале 70-х годов двадцатого столетия связывается с работами американского кибернетика Э.Ф. Кодда, в которых отражался математический аспект модели данных, употребляемой в смысле структуры данных. В связи с потребностями развития технологии обработки данных в теории автоматизированных банков информации (АБИ) во второй половине 70-х годов появился инструментальный аспект модели данных, в содержание этого термина были включены ограничения, налагаемые на структуры данных и операции с ними. В современной трактовке модель данных определяется как совокупность правил порождения структур данных в базах данных, операций над ними, а также ограничений целостности, определяющей допустимые связи и значения данных, последовательности их изменения [76]. Таким образом, модель данных представляет собой множество структур данных, ограничений целостности и операций манипулирования данными. Исходя из этого, можно сформулировать следующее рабочее определение: модель данных – это совокупность структур данных и операций их обработки. В настоящее время различают' три основных типа моделей данных: иерархическая, сетевая и реляционная. Иерархическая модель данных организует данные в виде древовидной структуры и является реализацией логических связей: родовидовых отношений или отношений «целое - часть». Например, структура высшего учебного заведения - это многоуровневая иерархия (см. рис. 1.10).
Рис. 1.10. Пример иерархической структуры Иерархическая (древовидная) БД состоит из упорядоченного набора деревьев; более точно, из упорядоченного набора нескольких экземпляров одного типа дерева. В этой модели исходные элементы порождают другие элементы, причем эти элементы в свою очередь порождают следующие элементы. Каждый порожденный элемент имеет только один порождающий элемент. Организационные структуры, списки материалов, оглавление в книгах, планы проектов, расписание встреч и многие другие совокупности данных могут быть представлены в иерархическом виде. Основными недостатком данной модели является: а) сложность отображения связи между объектами типа «многие ко многим»; б) необходимость использования той иерархии, которая была заложена в основу БД при проектировании. Потребность в постоянной реорганизации данных (а часто невозможность этой реорганизации) привели к созданию более общей модели – сетевой. Сетевой подход к организации данных является расширением иерархического подхода. Данная модель отличается от иерархической тем, что каждый порожденный элемент может иметь более одного порождающего элемента. Пример сетевой модели данных приведен на рис 1.11.
Рис. 1.11. Пример сетевой структуры Одним из недостатков рассмотренных выше моделей данных является то, что в некоторых случаях при иерархическом и сетевом представлении рост базы данных может привести к нарушению логического представления данных. Такие ситуации возникают при появлении новых пользователей, новых приложений и видов запросов, при учете других логических связей между элементами данных. Эти недостатки позволяет избежать реляционная модель данных. Реляционной считается такая база данных, в которой все данные представлены для пользователя в виде прямоугольных таблиц значений данных, и все операции над базой данных сводятся к манипуляциям с таблицами. Таблица состоит из столбцов (полей) и строк (записей); имеет имя, уникальное внутри базы данных. Таблица отражает тип объекта реального мира (сущность), а каждая ее строка - конкретный объект. Так, таблица Спортивная секция содержит сведения обо всех детях, занимающихся в данной -спортивной секции, а ее строки представляют собой набор значений атрибутов каждого конкретного ребёнка. Каждый столбец таблицы - это совокупность значений конкретного атрибута объекта. Столбец Вес, например, представляет собой совокупность всех весовых категорий детей, занимающихся в секции. В столбце Пол могут содержаться только два различных значения: «муж.» и «жен.». Эти значения выбираются из множества всех возможных значений атрибута объекта, которое называется доменом. Так, значения в столбце Вес выбираются из множества всех возможных весов детей. Каждый столбец имеет имя, которое обычно записывается в верхней части таблицы. Эти столбцы называются полями таблицы. При проектировании таблиц в рамках конкретной СУБД имеется возможность выбрать для каждого поля его тип, т.е. определить для него набор правил по его отображению, а также определить те операции, которые можно, выполнять над данными, хранящимися в этом поле. Наборы типов могут различаться у разных СУБД. Имя поля должно быть уникальным в таблице, однако различные таблицы могут иметь поля с одинаковыми именами. Любая таблица должна иметь, по крайней мере, одно поле; поля расположены в таблице в соответствии с порядком следования их имен при ее создании. В отличие от полей, строки не имеют имен; порядок их следования в таблице не определен, а количество логически не ограничено. Строки называются записями таблицы. Так как строки в таблице не упорядочены, невозможно выбрать строку по ее позиции - среди них не существует "первой", "второй", "последней". Любая таблица имеет один или несколько столбцов, значения в которых однозначно идентифицируют каждую ее строку. Такой столбец (или комбинация столбцов) называется первичным ключом. В таблице Спортивная секция первичный ключ - это столбец Ф.И.О. (рис. 1.12). Такой выбор первичного ключа имеет существенный недостаток: невозможно записать в секцию двух детей с одним и тем же значением поля Ф.И.О., что на практике встречается не так уж редко. Именно поэтому, часто вводят искусственное поле для нумерации записей в таблице. Таким полем, например, может быть номер в журнале для каждого ребёнка, который сможет обеспечить уникальность каждой записи в таблице. Если таб.лица удовлетворяет этому требованию, она называется отношением (relation).
Рис. 1.12. Реляционная модель данных Реляционные модели данных обычно могут поддерживать четыре типа связей между таблицами: 1) Один к Одному (пример: в одной таблице хранятся сведения о школьниках, в другой сведения о прохождении школьниками прививок). 2) Один ко Многим (пример: в одной таблице хранятся сведения об учителях, в другой сведения о школьниках, у которых эти учителя являются классными руководителями). 3) Много к Одному (в качестве примера можно предложить предыдущий случай, рассматривая его с другой стороны, а именно со стороны таблицы, в которой хранятся сведения о школьниках). 4) Много ко Многим (пример: в одной таблице хранятся заказы на поставку товаров, а в другой - фирмы, исполняющие эти заказы, причем для выполнения одного заказа могут объединяться несколько фирм/ Реляционное представление данных имеет целый ряд преимуществ. Оно понятно пользователю, не являющемуся специалистом в области программирования, позволяет легко добавлять новые описания объектов и их характеристики, обладает большой гибкостью при обработке запросов. Вопросы и задания 1. Дайте определение понятию «данные». 2. Что называется циклом жизни данных? 3. Какие модели данных вы знаете? 4. Укажите преимущества и недостатки каждой модели данных. ИНФОРМАЦИОННЫЕ ПРОЦЕССЫ
|
||||
|
|
Последнее изменение этой страницы: 2016-08-26; просмотров: 1685; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 18.119.125.240 (0.01 с.) |

 Поскольку сетевая БД может представлять непосредственно все виды связей, присущих данным соответствующей организации, по этим данным можно перемещаться, исследовать и запрашивать их всевозможными способами, т.е. сетевая модель не связана всего лишь одной иерархией. Однако для того, чтобы составить запрос к сетевой БД, необходимо достаточно глубоко вникнуть в её структуру (иметь под рукой схему этой БД) и выработать свой механизм навигации по базе данных, что является существенным недостатком этой модели БД.
Поскольку сетевая БД может представлять непосредственно все виды связей, присущих данным соответствующей организации, по этим данным можно перемещаться, исследовать и запрашивать их всевозможными способами, т.е. сетевая модель не связана всего лишь одной иерархией. Однако для того, чтобы составить запрос к сетевой БД, необходимо достаточно глубоко вникнуть в её структуру (иметь под рукой схему этой БД) и выработать свой механизм навигации по базе данных, что является существенным недостатком этой модели БД.



